1. このページについて
最近,株価の変動が激しいすね.
なので,AIでテスラの未来の株価を予測してみました.
2. プログラム
早速プログラムを紹介していく.
必要なライブラリのインポート
まず最初は,必要なライブラリをインポートします.
# 必要なライブラリのインポート
import numpy as np # 数値計算用のライブラリ
from sklearn.metrics import r2_score # モデル評価用の関数
import yfinance as yf # Yahoo Financeからデータを取得するためのライブラリ
from datetime import datetime # 日付と時間を扱うためのライブラリ
from sklearn.preprocessing import MinMaxScaler # データの正規化用の関数
from keras.models import Sequential # ニューラルネットワークモデルを構築するためのクラス
from keras.layers import Dense, LSTM, Dropout # ニューラルネットワークの層を構築するためのクラス
import matplotlib.pyplot as plt # グラフを描画するためのライブラリ
import pandas as pd # データ操作用のライブラリ
テスラの株価データの取得
ヤフーファイナンスからテスラの株価データを取得します.
# テスラの株価データを取得する
s_target = 'TSLA' # テスラのティッカーシンボル
df = yf.download(s_target, start='2014-01-01', end=datetime.now()) # 2014年から現在までのデータを取得
print(df.head()) # データの最初の5行を表示
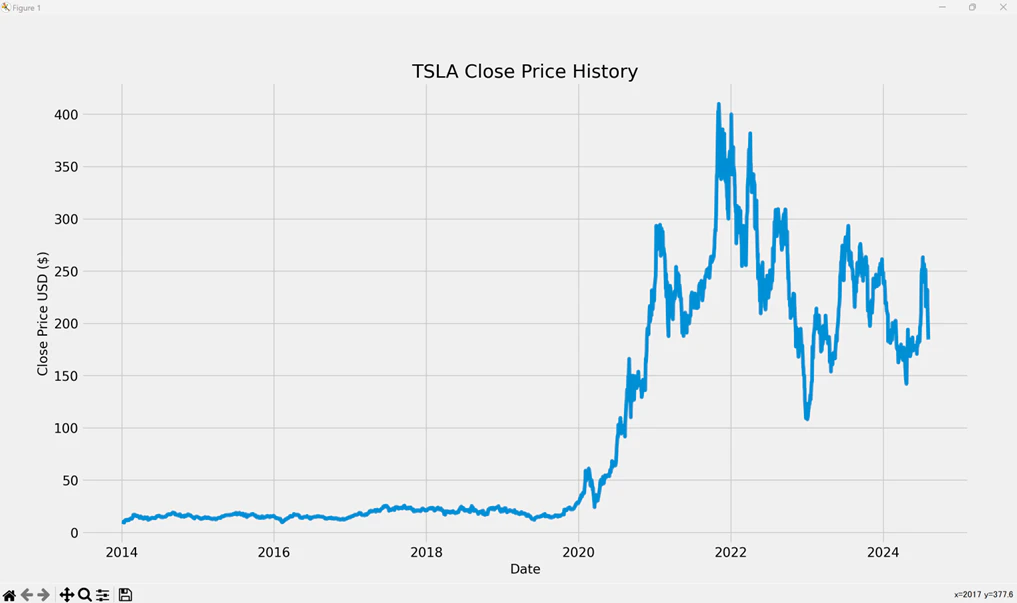
株価データのプロット
取得した株価データをプロットします.
ここまでは難しくないですね.
# グラフのスタイルを設定(見やすくする)
plt.style.use("fivethirtyeight")
# 株価の終値をプロットする
plt.figure(figsize=(16, 6)) # グラフのサイズを設定
plt.title(s_target + ' Close Price History') # グラフのタイトルを設定
plt.plot(df['Close']) # 終値をプロット
plt.xlabel('Date', fontsize=14) # x軸のラベルを設定
plt.ylabel('Close Price USD ($)', fontsize=14) # y軸のラベルを設定
plt.show() # グラフを表示
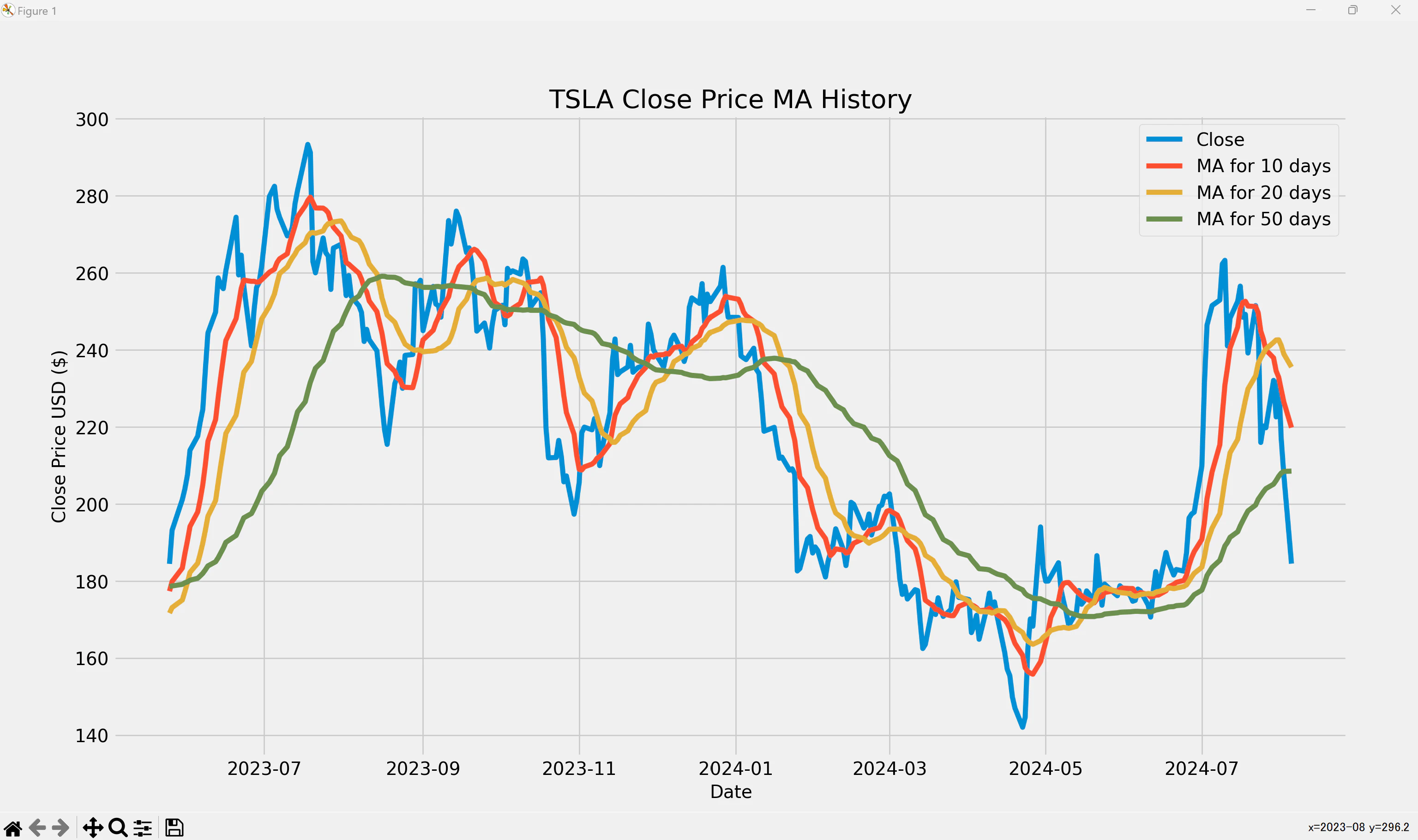
移動平均を算出してプロット
今度は,移動平均を算出してプロットします.
# 移動平均を計算する日数
ma_day = [10, 20, 50] # 10日、20日、50日の移動平均を計算
for ma in ma_day:
column_name = f"MA for {ma} days" # 列名を設定
df[column_name] = df['Adj Close'].rolling(ma).mean() # 移動平均を計算して新しい列に追加
# 移動平均をプロットする
plt.figure(figsize=(16, 6)) # グラフのサイズを設定
plt.title(s_target + ' Close Price MA History') # グラフのタイトルを設定
plt.plot(df['Close'][-300:]) # 終値をプロット(直近300日分)
plt.plot(df['MA for 10 days'][-300:]) # 10日の移動平均をプロット
plt.plot(df['MA for 20 days'][-300:]) # 20日の移動平均をプロット
plt.plot(df['MA for 50 days'][-300:]) # 50日の移動平均をプロット
plt.xlabel('Date', fontsize=14) # x軸のラベルを設定
plt.ylabel('Close Price USD ($)', fontsize=14) # y軸のラベルを設定
plt.legend(['Close', 'MA for 10 days', 'MA for 20 days', 'MA for 50 days'], loc='upper right') # 凡例を設定
plt.show() # グラフを表示
df[column_name] = df['Adj Close'].rolling(ma).mean() について少し解説すると,
これは新しい列を追加する処理になります.
df['Adj Close'] は,データフレーム df の「Adj Close」列を選択しているという意味です.この列に終値が入っています.
.rolling(ma) は,ma で指定された期間(例えば10日、20日、50日)の移動ウィンドウを作成するという意味です.
.mean()は,移動ウィンドウ内のデータの平均を計算するという意味になります.
つまり,まとめると「移動平均を計算して新しい列に追加」ということになります.
ちなみに↑を実行すると,以下のようなグラフが表示されます.
LSTMモデルの構築の準備
LSTMモデルを構築するための準備をします.
# 終値データを抽出
data = df.filter(['Close']) # 終値のみを抽出
dataset = data.values # numpy配列に変換
# データを0〜1の範囲に正規化
scaler = MinMaxScaler(feature_range=(0, 1)) # 正規化の範囲を0〜1に設定
scaled_data = scaler.fit_transform(dataset) # データを正規化
# データの80%をトレーニングデータとして使用
training_data_len = int(np.ceil(len(dataset) * .8)) # トレーニングデータの長さを計算.(データセットの80%の長さを求めているだけ.)
# 予測に使用する期間
window_size = 60 # 60日分のデータを使用して予測
# トレーニングデータを作成
train_data = scaled_data[0:int(training_data_len), :] # トレーニングデータを抽出
# トレーニングデータをx_trainとy_trainに分割
x_train, y_train = [], []
for i in range(window_size, len(train_data)):
x_train.append(train_data[i - window_size:i, 0]) # 過去60日分のデータをx_trainに追加
y_train.append(train_data[i, 0]) # 61日目のデータをy_trainに追加
# numpy arrayに変換
x_train, y_train = np.array(x_train), np.array(y_train) # リストをnumpy配列に変換
# LSTMモデルに入力するためにデータの形状を変更
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1)) # データの形状を変更
少し補足します.
scaled_data[0:int(training_data_len), :]は、scaled_data の最初の training_data_len 行をすべての列(:)と共に選択するという意味です.つまり、この行のコードは、scaled_data の最初の training_data_len 行を train_data に格納するということっす.
また,x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
は,LSTMモデルに入力するためにデータの形状を変更する処理になります.
LSTMは3次元の入力データを期待するため、データを (サンプル数, 特徴量の数, 1) の形状に変換する必要があるため,この処理をやっているということです.
LSTMモデルの構築
さて,LSTMモデルを構築してみます.
# LSTMモデルを構築
model = Sequential() # モデルを初期化
model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1], 1))) # LSTM層を追加
model.add(Dropout(0.2)) # ドロップアウト層を追加
model.add(LSTM(units=50, return_sequences=True)) # LSTM層を追加
model.add(Dropout(0.2)) # ドロップアウト層を追加
model.add(LSTM(units=50, return_sequences=True)) # LSTM層を追加
model.add(Dropout(0.2)) # ドロップアウト層を追加
model.add(LSTM(units=50)) # LSTM層を追加
model.add(Dropout(0.2)) # ドロップアウト層を追加
model.add(Dense(units=1)) # 出力層を追加
# モデルをコンパイル
model.compile(optimizer='adam', loss='mean_squared_error') # モデルをコンパイル
LSTMモデルの学習
構築したLSTMモデルを学習させます.
# モデルをトレーニング
history = model.fit(x_train, y_train, batch_size=32, epochs=100) # モデルをトレーニング
# モデルの概要を表示
model.summary() # モデルの概要を表示
# テストデータを作成
test_data = scaled_data[training_data_len - window_size: , :] # テストデータを抽出
x_test = []
y_test = dataset[training_data_len:, :] # テストデータの実際の値を抽出
for i in range(window_size, len(test_data)):
x_test.append(test_data[i-window_size:i, 0]) # 過去60日分のデータをx_testに追加
# numpy arrayに変換
x_test = np.array(x_test) # リストをnumpy配列に変換
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1 )) # データの形状を変更
補足すると,
test_data = scaled_data[training_data_len - window_size: , :]については,
scaled_dataの後ろ80%の位置からウインドウサイズ(60日分)を引いた位置から、データセットの最後までを抽出しています.
予測の実行
予測してみます.
# 予測を実行する
predictions = model.predict(x_test) # 予測を実行
predictions = scaler.inverse_transform(predictions) # 予測結果を元のスケールに戻す
# 二乗平均平方根誤差(RMSE): 0に近いほど良い
rmse = np.sqrt(np.mean(((predictions - y_test) ** 2))) # RMSEを計算
print(rmse) # RMSEを表示
# 決定係数(r2) : 1に近いほど良い
r2s = r2_score(y_test, predictions) # 決定係数を計算
print(r2s) # 決定係数を表示
# トレーニングデータと検証データをプロット
train = data[:training_data_len] # トレーニングデータを抽出
valid = data[training_data_len:].copy() # 検証データを抽出
valid['Predictions'] = predictions # 予測結果を検証データに追加
plt.figure(figsize=(16,6)) # グラフのサイズを設定
plt.title('Model') # グラフのタイトルを設定
plt.xlabel('Date', fontsize=14) # x軸のラベルを設定
plt.ylabel('Close Price USD ($)', fontsize=14) # y軸のラベルを設定
plt.plot(train['Close']) # トレーニングデータをプロット
plt.plot(valid[['Close', 'Predictions']]) # 検証データと予測結果をプロット
plt.legend(['Train', 'Val', 'Predictions'], loc='lower right') # 凡例を設定
plt.show() # グラフを表示
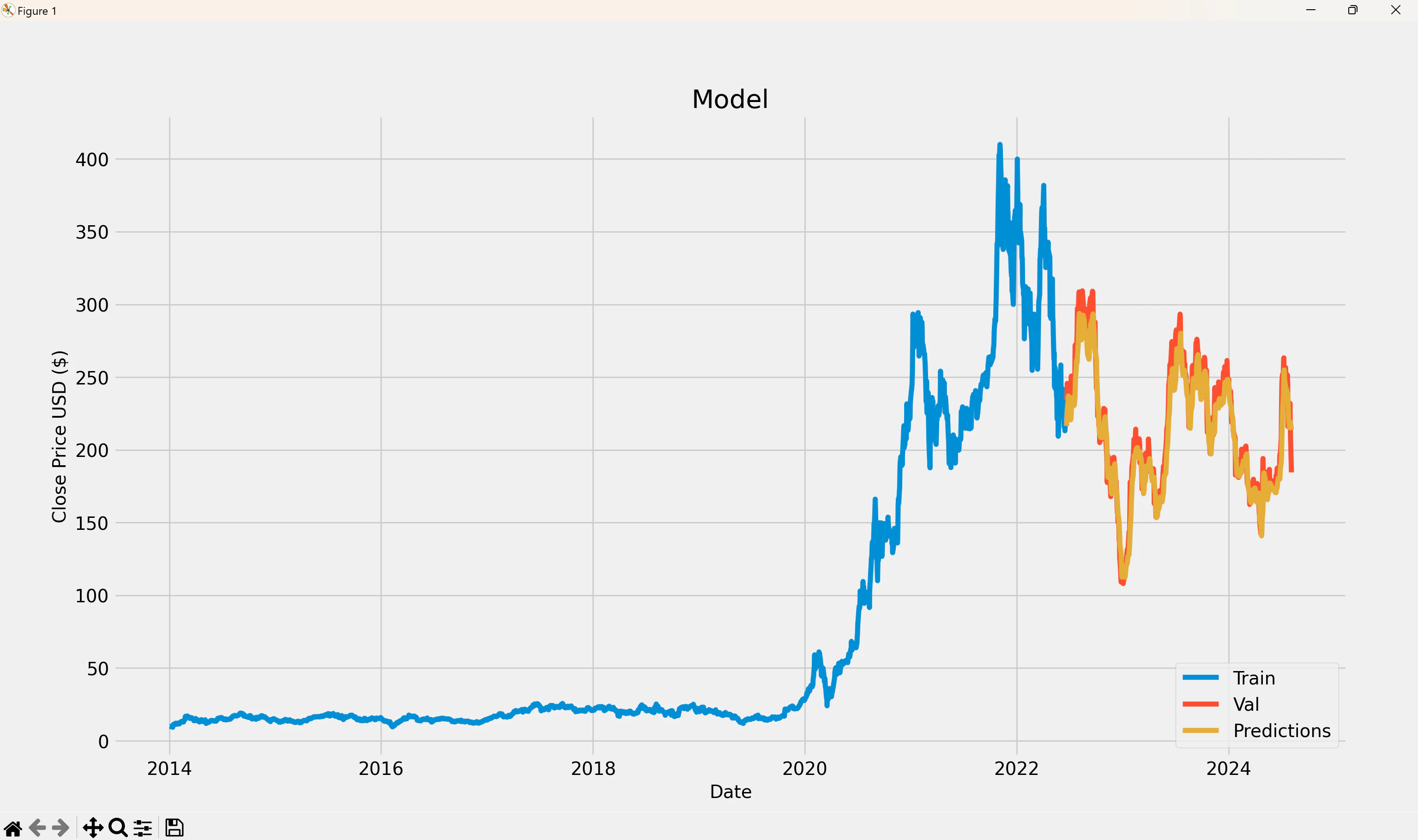
上記のグラフについて少し補足しますと,
Train:2014年~2022年2月くらいまでのテスラの株価
Val:2022年2月くらい~2024年7月くらいまでのテスラの株価
Predictions:過去60日のデータからAIで予測した株価
という感じですね.
あれ・・・?なんか検証データと予測結果が一致しすぎではないか・・・?
なんで・・・??
原因は単純です.
このプログラム内のLSTMモデルは,過去60日のデータを元に,その次の日の株価データを予測する というモデルになっております.
このプログラムだと,常に最新の実際の60日分のデータに基づいて予測を行うようなプログラムになってます.
たとえば,2024/8/1のデータを予測するために,2024年の6月と7月の実際の株価を使っちゃうようなプログラムになってます.そりゃ精度はよくなりますね・・・・
未来の株価予測
さらに2026年12月末までの株価を予測し、グラフにプロットしてみます.
# 未来の株価予測
# 2026年12月末までの株価を予測し、グラフにプロットします。
# 未来の日付を生成
future_dates = pd.date_range(start=df.index[-1], periods=365*2, freq='D') # 未来の日付を生成(2年間)
# 直近のデータを使用して予測を行う
future_data = df['Close'].values[-window_size:].reshape(-1, 1) # 直近60日分のデータを抽出
future_data = scaler.transform(future_data) # データを正規化
future_predictions = [] # 未来の予測結果を格納するリスト
for _ in range(len(future_dates)):
future_input = future_data[-window_size:] # 直近60日分のデータを使用
future_input = future_input.reshape((1, window_size, 1)) # データの形状を変更
future_pred = model.predict(future_input) # 予測を実行
future_data = np.append(future_data, future_pred) # 予測結果をデータに追加
future_predictions.append(future_pred[0, 0]) # 予測結果をリストに追加
future_predictions = scaler.inverse_transform(np.array(future_predictions).reshape(-1, 1)) # 予測結果を元のスケールに戻す
# 未来の予測結果をプロット
plt.figure(figsize=(16, 6)) # グラフのサイズを設定
plt.title('Future Predictions') # グラフのタイトルを設定
plt.xlabel('Date', fontsize=14) # x軸のラベルを設定
plt.ylabel('Close Price USD ($)', fontsize=14) # y軸のラベルを設定
plt.plot(df['Close']) # 過去の株価データをプロット
plt.plot(future_dates, future_predictions, color='red') # 未来の予測結果をプロット
plt.legend(['Historical', 'Future Predictions'], loc='upper left') # 凡例を設定
plt.show() # グラフを表示
ちょっと補足します.
上記でやってることとしましては,以下のような感じですね.
①: まず最初は,直近60日のデータ(実際の株価のデータ)から,その次の日のデータを予測.
②: “①で予測したデータを含めた直近60日のデータ”から,その次の日を予測する.
③: “②”をどんどん繰り返していく・・・
で,,,,,上記を実行した結果は,↓のような感じになりました.
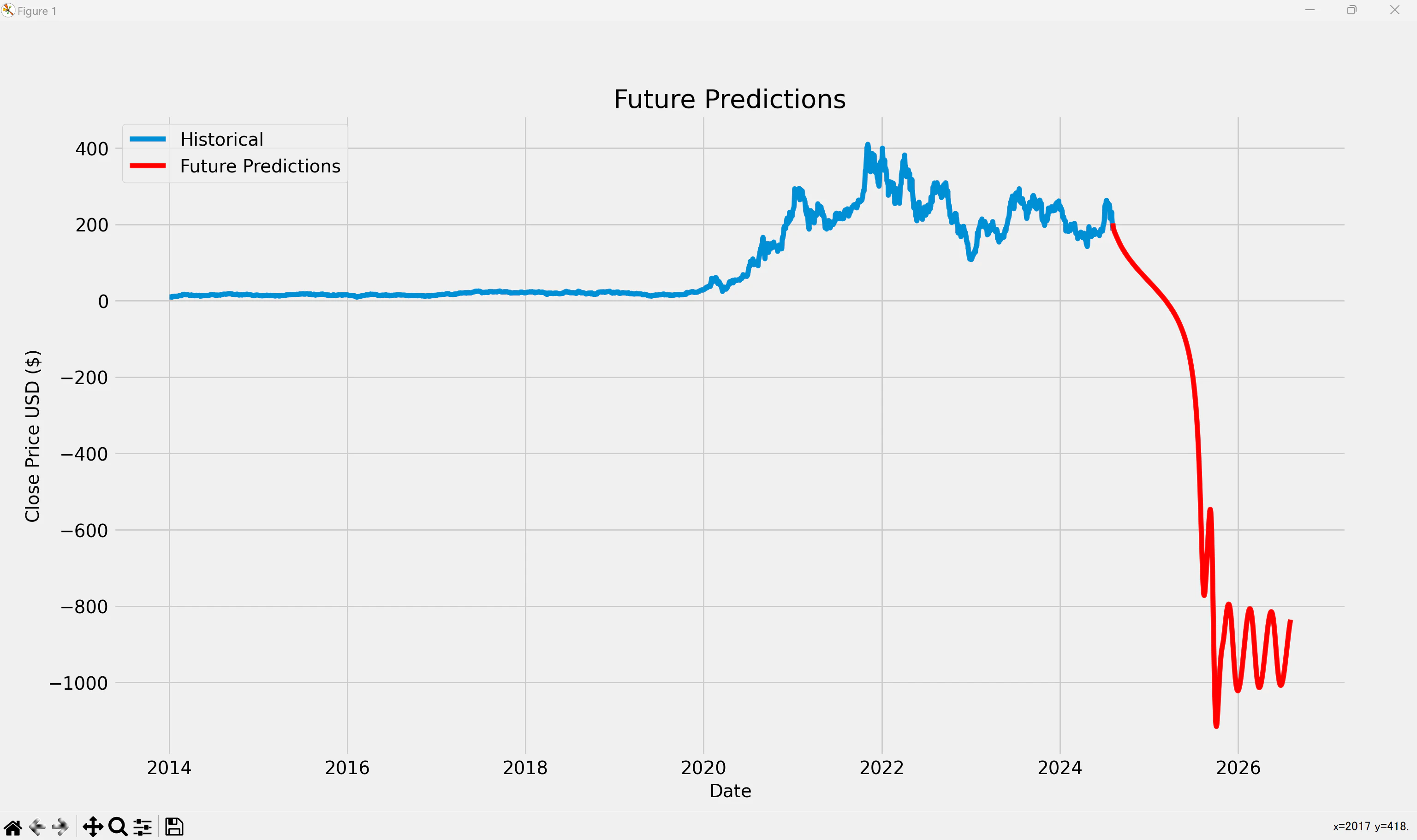
ワロスwwww
3.参考にさせてもらった記事