はじめに
こんにちは!SIer に勤めるヤマゾーです。普段は AI のシステム開発に携わっています。
2023/12/6 に Google が新たな生成 AI 「Gemini」を発表したのが大きな話題となっていますね。Google CEO のサンダー・ピチャイ氏は X (旧 Twitter) にて、これまでで最も高性能かつ汎用的な AI モデル と表現しています。
これまでテキストや画像を扱う生成 AI といえば ChatGPT (GPT-4) が頭一つ抜けていた印象ですが、今回新しく登場した Gemini は遂に ChatGPT の性能を超えた生成 AI として大きな注目を集めています。本記事ではこの Gemini について、AI にあまり詳しくない人にも分かるように解説してみようと思います。
ちなみに Gemini はラテン語で「双子」という意味です。
サマリ
本記事の目次
本記事の想定読者
- 最近流行りの生成 AI について大まかに理解したい人
- ChatGPT くらいは聞いたことがあるけど正直あまり詳しくない人
- Gemini について日本語で解説記事を読みたい人
Gemini とは
Gemini ってどんな AI?
詳細は公式のテクニカルレポート (全62ページ) に書かれていますが、端的に言えば
- テキストだけでなく、画像、音声、動画も同時に処理できて、
- AI の精度を測定する全 32 項目のテストのうち 30 項目で最高記録を更新した、
- 世界で初めて人間の専門家を超えた生成 AI モデル(MMLU というベンチマークに基づく)
です。飽くまで Google が実施したベンチマークのテストにおける範囲ですが、GPT-4 に総合的に勝った現時点で最強の生成 AI ということになります。生成 AI というのは平たく言えば、テキストや画像等をフリースタイルに出力できる AI のことです。
なお Gemini は以下の3種類があり、上記はその中でも最高性能の Gemini Ultra の話です。
| モデルサイズ | 説明 |
|---|---|
| Ultra | 非常に複雑なタスクも解ける最大サイズのモデル |
| Pro | 幅広いタスクに適用できる、性能とコストのバランスが取れたモデル |
| Nano | 数十億パラメータの比較的小さなサイズのモデル。オンデバイス向け |
32 項目のテストには例えば算数問題、機械翻訳、プログラミング、グラフの読み取りなどが含まれます。
Gemini の読み方はジェミナイ?ジェミニ?
少し本題から逸れますが、Gemini の読み方についても触れておきます。結論、公式 HP の動画では「ジェミナイ」と発音されているものの、ITmedia の記事には以下の記載があり、どうやら日本語読みは 「ジェミニ」が主流になりそうです。
ただ今回の場合は、Google日本法人にそのスタンスを聞くのが早いだろう。さっそくメールで問い合わせたところ「Geminiの日本語読みですが、ジェミニ、になります」というシンプルな回答を得た。
個人的にはネイティブに揃えてジェミナイと発音した方がいいと思いますが……。
Gemini って例えば何ができるの?
Gemini が実際にどんなことができるのか、テクニカルレポートの例を見てみましょう。
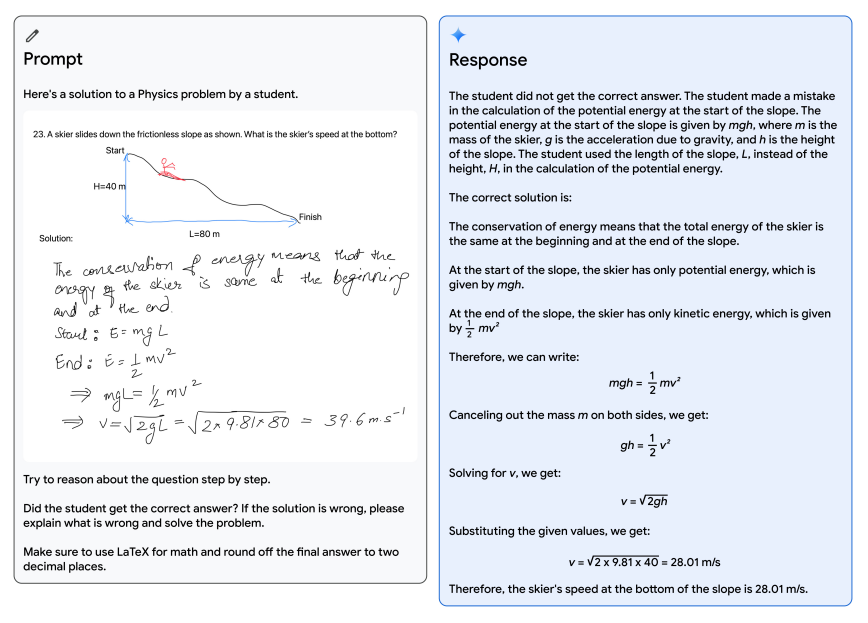
左が人間の入力、右が Gemini の出力です。
学生が解いた物理のテスト用紙を Gemini に読み込ませ、正しく解けているか判定させ、解けていない場合は模範解答を小数第 2 位で出力するように指示を出しています。すると Gemini はテスト用紙の手書きの文字を正しく読み取り、位置エネルギーの式が mgH ではなく mgL になっている間違いを訂正しています。
人間の指示を正しく守れていることは勿論、クセの強い手書き文字も正しく認識できていますし、一般に大規模言語モデルが苦手とされている計算も正しくできているのは素晴らしいですね。この例のように、Gemini はテキストと画像等の複数種類の情報を同時に扱えます。
複数種類の情報を扱える AI は「マルチモーダル AI」と呼ばれます。
もう一つの例も見てみましょう。

先ほどと同様に、左が人間の入力、右が Gemini (Ultra) の出力です。
二色の毛糸を使って何を作れるか Gemini にアイデアを出すように指示すると、Gemini は説明文だけでなくイメージ画像も一緒に生成してくれました。商品開発や広告の自動生成など、様々な応用先が考えられそうですね。
ここで改めて左の指示文をよく見ると、今回は出力サンプル (青と黄色の毛糸の例) を与えることで、Gemini がそのサンプルを踏襲して出力するように促しています。これは Few-shot prompting (または In-context learning) と呼ばれ、生成 AI を使いこなすうえで非常に強力なテクニックです。
出力例が 1 つ、2 つの指示文を One-shot prompting、Two-shot prompting と呼んだり、逆に出力例が無い指示文を Zero-shot prompting と呼んだりすることもあります。
Gemini の始め方
Gemini の始め方 (ブラウザ版)
Gemini を ChatGPT のようにブラウザ上で使いたい場合は Google Chrome で Bard にアクセスするだけで無料で使えます。
Google の公式ブログ によると Bard の裏側では現在 Gemini Pro が動いており、2024 年の初めには遂に最高性能の Gemini Ultra を搭載した Bard Advanced を提供開始する予定のようです。Bard Advanced の料金についてはまだ公表されていません。
また、巷では Bard で Gemini Pro を利用するためにはブラウザの言語設定を英語にする必要があるという噂も流れているようですが、こちらについては公式アナウンスが見当たらなかったため真相は分かりませんでした。試しにブラウザの設定を日本語と英語に切り替えて Bard 自身に何のモデルを使っているのか質問してみましたが、どちらも Gemini Pro を使用していると回答しました。
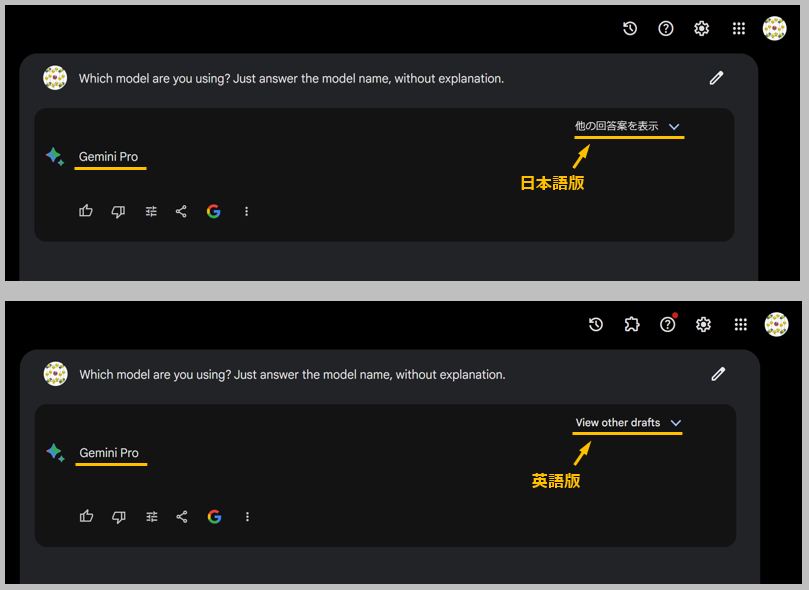
当然 AI が嘘をついている可能性もあるので、これだけだと確証は得られません。
念のため、以降ではブラウザの言語設定を英語にした状態で Bard を動かすことにします。
AI が尤もらしい嘘をつく現象のことを「ハルシネーション」と言います。
Google Chrome ブラウザの言語設定を変更する手順は公式ヘルプをご参照ください。
Gemini の始め方 (API版)
本記事執筆中 (2023/12/14) に Gemini API が提供開始されたので、早速動かして手順をまとめておきます。こちらは開発者向けの内容なので、Gemini の能力だけ知りたいという方は読み飛ばしていただいて構いません。
公式の Google Colab がかなり簡潔にまとめられているようなので、ここでは最低限の動かし方だけ載せることにします。事前準備として、API キーをこちらのサイトにて発行する必要があります。
それでは公式の Google Colab に沿って進めましょう。
まずは必要なライブラリをインストールします。
!pip install -q -U google-generativeai
次に必要なパッケージをインポートします。後でマークダウン形式に出力するための関数もここで定義しておきます。
import pathlib
import textwrap
import google.generativeai as genai
# Used to securely store your API key
from google.colab import userdata
from IPython.display import display
from IPython.display import Markdown
def to_markdown(text):
text = text.replace('•', ' *')
return Markdown(textwrap.indent(text, '> ', predicate=lambda _: True))
先ほど取得した API キーを以下の "GOOGLE_API_KEY" に代入します。
genai.configure(api_key="GOOGLE_API_KEY")
これだけで準備は完了です。それでは実際に Gemini API を呼び出してみましょう。
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("パンはパンでも食べられないパンは何ですか?")
to_markdown(response.text)
# フライパン
日本語を入力しても無事に出力が返ってきました。
なお、response.prompt_feedback や response.candidates を出力すればコンテンツフィルタリング結果や他の出力候補も取得できるようですが、ここでは長くなるため割愛します。画像の入力方法なども含め、詳しく知りたい方は公式の Google Colab をご参照ください。
Gemini の実力をテスト
それでは実際に Gemini の実力がどの程度なのかいくつかテストしてみましょう。残念ながら現時点では最高性能の Gemini Ultra は利用できないため、代わりに二番手である Gemini Pro でテストします。同じ問題を OpenAI の最高傑作である GPT-4 版 ChatGPT にも解かせて結果を比較してみます。 なお、本検証は厳密には Bard と ChatGPT の比較 (もしくは Gemini Pro と GPT-4 の比較) に当たるのですが、以下では便宜上単に Gemini と ChatGPT の比較 と表記します。
各テストの試行回数は 10 回程度行っていますが、特に断りのない限りは典型的な挙動の結果を選んで載せています。
Q1. 「稀によくある」の意味を説明してください
1 問目はイラストの意図を読み取る問題です。ネット上ではしばしば 「稀によくある」 という謎の表現を見かけますが、これを私が勝手に解釈してイラストにしたものが以下の画像です。
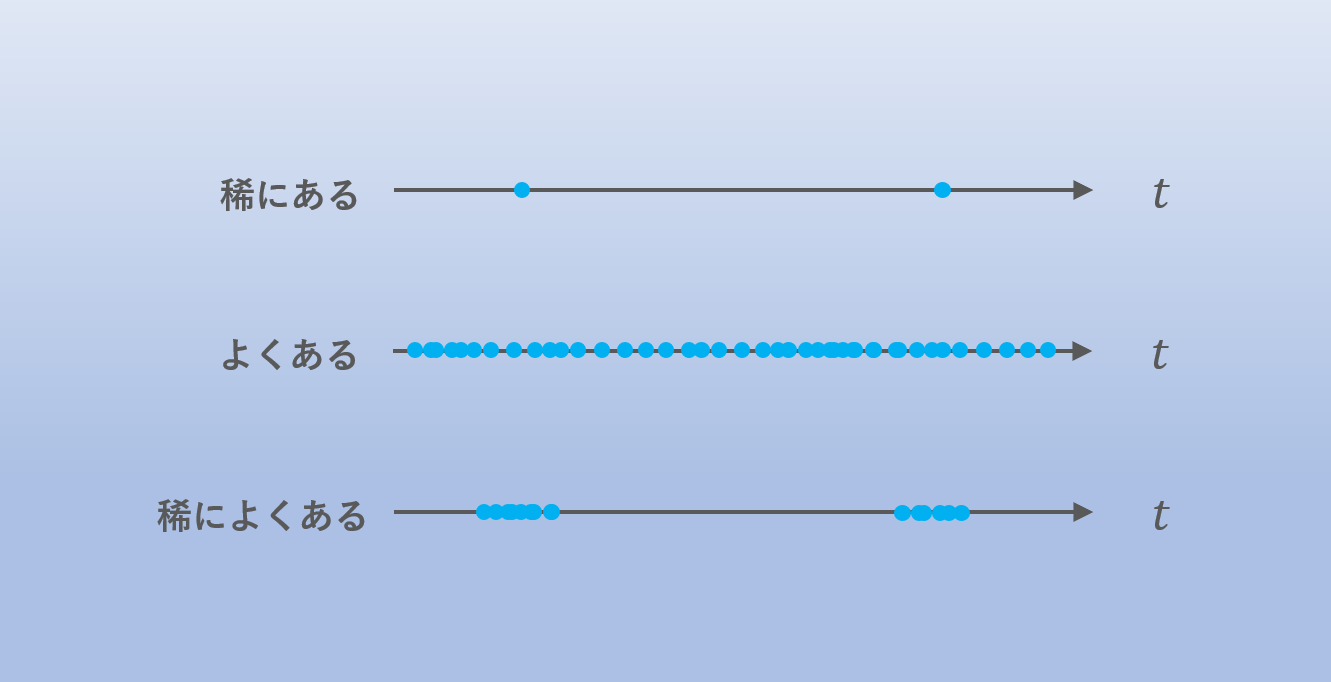
この私の解釈が正しいかは一旦置いておいて、これを Gemini に説明させてみましょう。
結果は以下のようになりました。
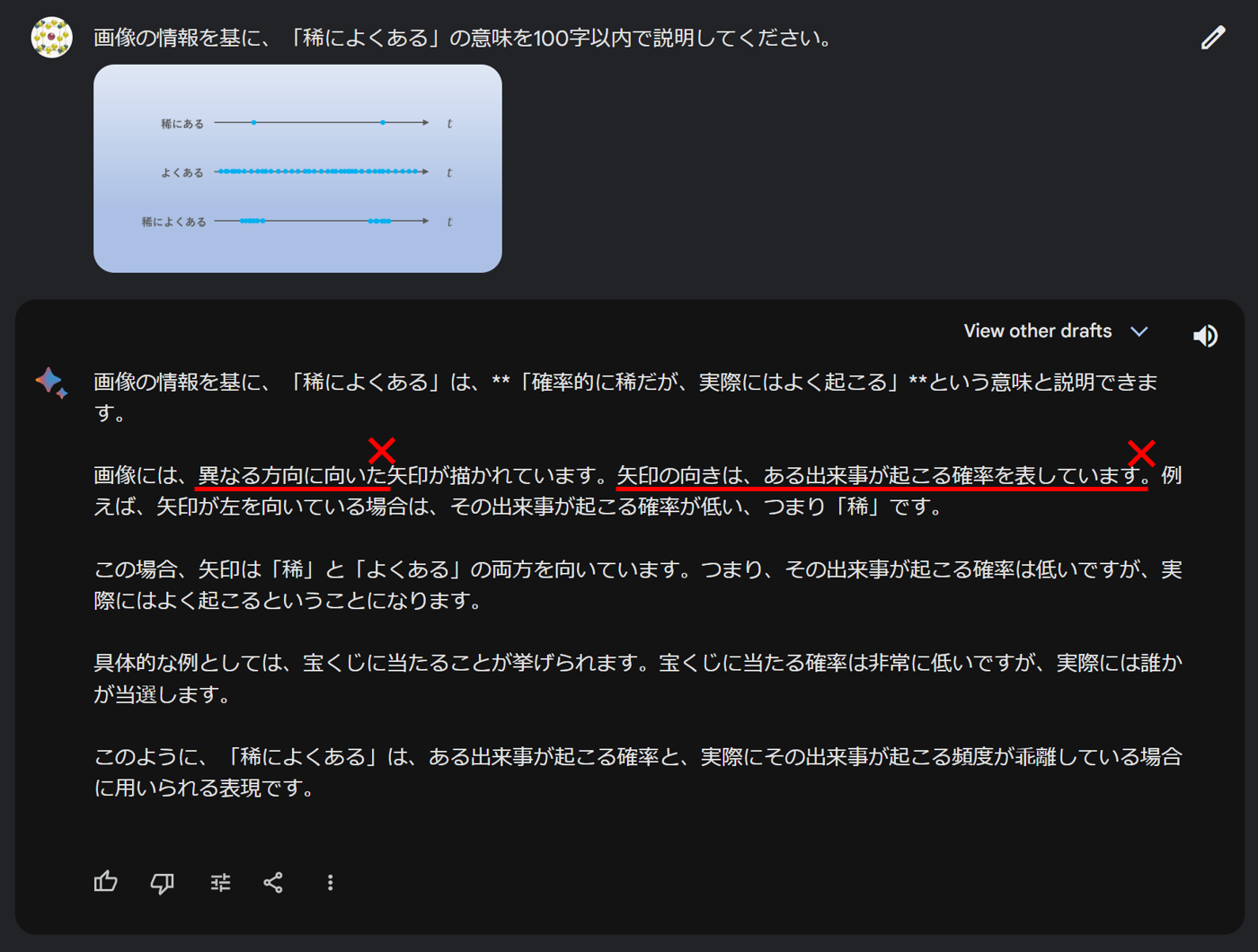
画像中に矢印があることは認識しているものの、「異なる方向に向いた」「矢印の向きは、ある出来事が起こる確率を表しています」というのは誤りです。100 字以内という制約も守れていないですが、そもそも生成 AI は文字数制限はあまり得意ではなく、日本語だとなおさら苦手なので想定の範囲内です。
それでは同じ問題を ChatGPT にも解かせてみましょう。結果は以下のようになりました。

Gemini 同様に 100 字以内の制約は守れていないですが、イラストに何が書かれているか正しく説明できており、その解釈も含めて完璧ですね。この問題については ChatGPT の圧勝という結果になりました。
Q2. 今年はあと何日か計算してください
2 問目は 12 月にふさわしい算数の問題です。本記事の執筆時点では 2023/12/14 で、今年もあと 17 日となりました。人間だと簡単に計算できますが、Gemini も計算できるか試してみましょう。
結果は以下のようになりました。
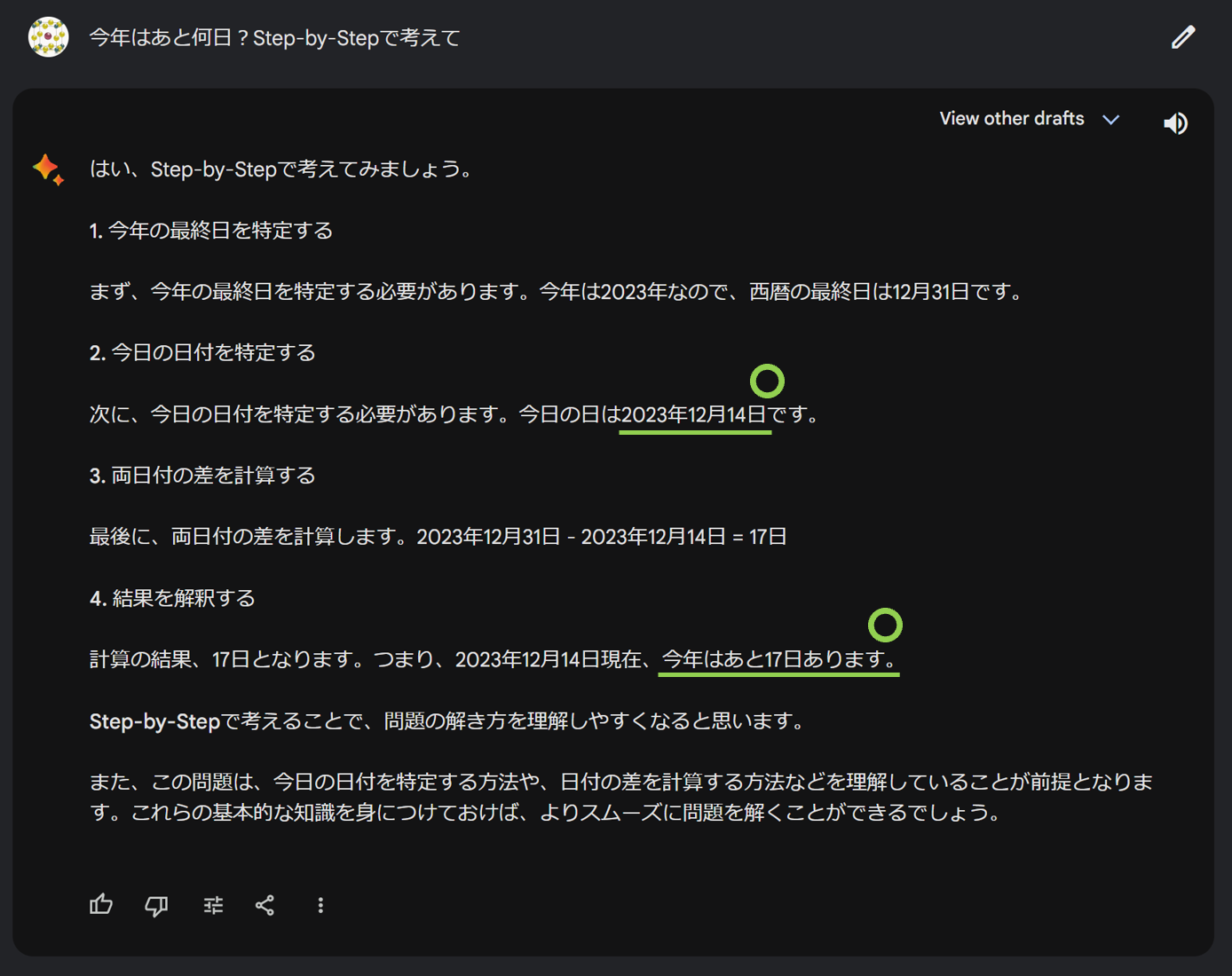
正しく本日の日付を取得し、残り日数も計算できました。日付を取得できている理由は Gemini が裏側で外部ツールを利用しているためと推察できます。例えば検索エンジンで「今日の日付」と検索したり、カレンダー API を実行したり等が考えられますが、検索に強みを持つ Google であれば恐らく前者でしょう。
また、今回指示文に「Step-by-Step で考えて」という注意書きを入れていますが、これは文字通り Step-by-Step と呼ばれるプロンプトテクニックです。生成 AI にいきなり回答を出させるのではなく、まず手順を出力させることで回答精度を上げるというものです。現にこの注意書きを入れないと Gemini は簡単に計算を間違えてしまいました。また、何度も試していると Step-by-Step でもしばしば計算を間違えてしまうこともあるようです。
それでは同じ問題を ChatGPT にも解かせてみましょう。結果は以下のようになりました。
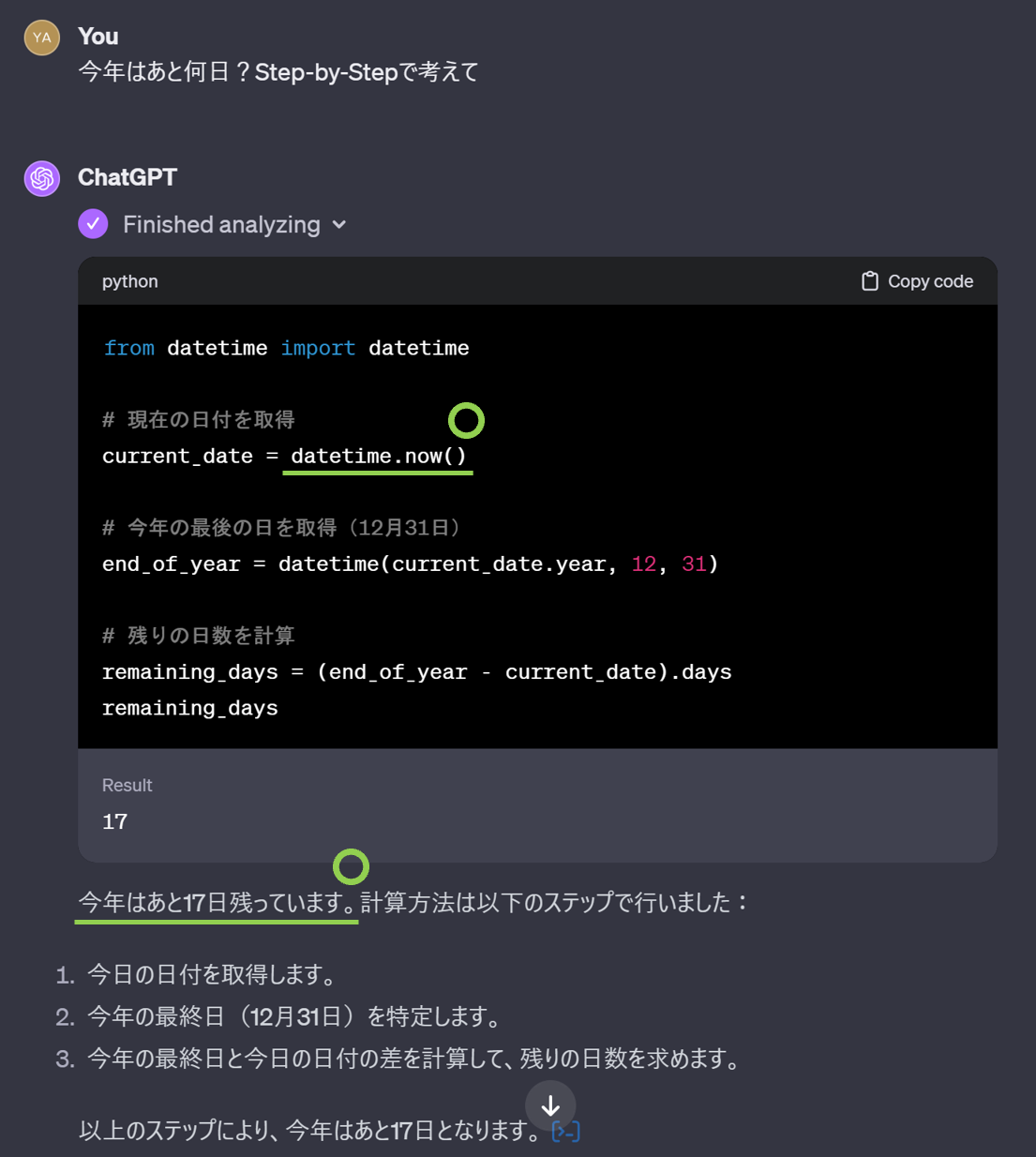
難なく日付の取得も計算もできていますね。ChatGPT は計算を行う際はプログラムを書き、実際に実行するアプローチを取るようです。これにより、何回試しても正確に回答できました。また、ChatGPT については Step-by-Step の指示文を入れなくても安定して正解できていたため、この問題も ChatGPT の勝ちと言えるでしょう。
Step-by-Step で精度が上がる原因は生成 AI が本質的に文章の続きを生成するモデルで、前の文章に続きを予想しやすい記述があったり、内容の飛躍が減ったりするほど続きの生成を間違えにくくなるからと考えられます。
Q3. 写真に何が写っているか、誰が投稿したものか答えてください
最後は少しトリッキーな問題を出してみます。
X (旧 Twitter) における、先月の私の投稿を使います。
このツイートに添付された写真を与えて、写真に何が写っているか、誰がツイートしたものかを両方答えてもらいましょう。まずは Gemini をテストしたところ、以下の結果になりました。
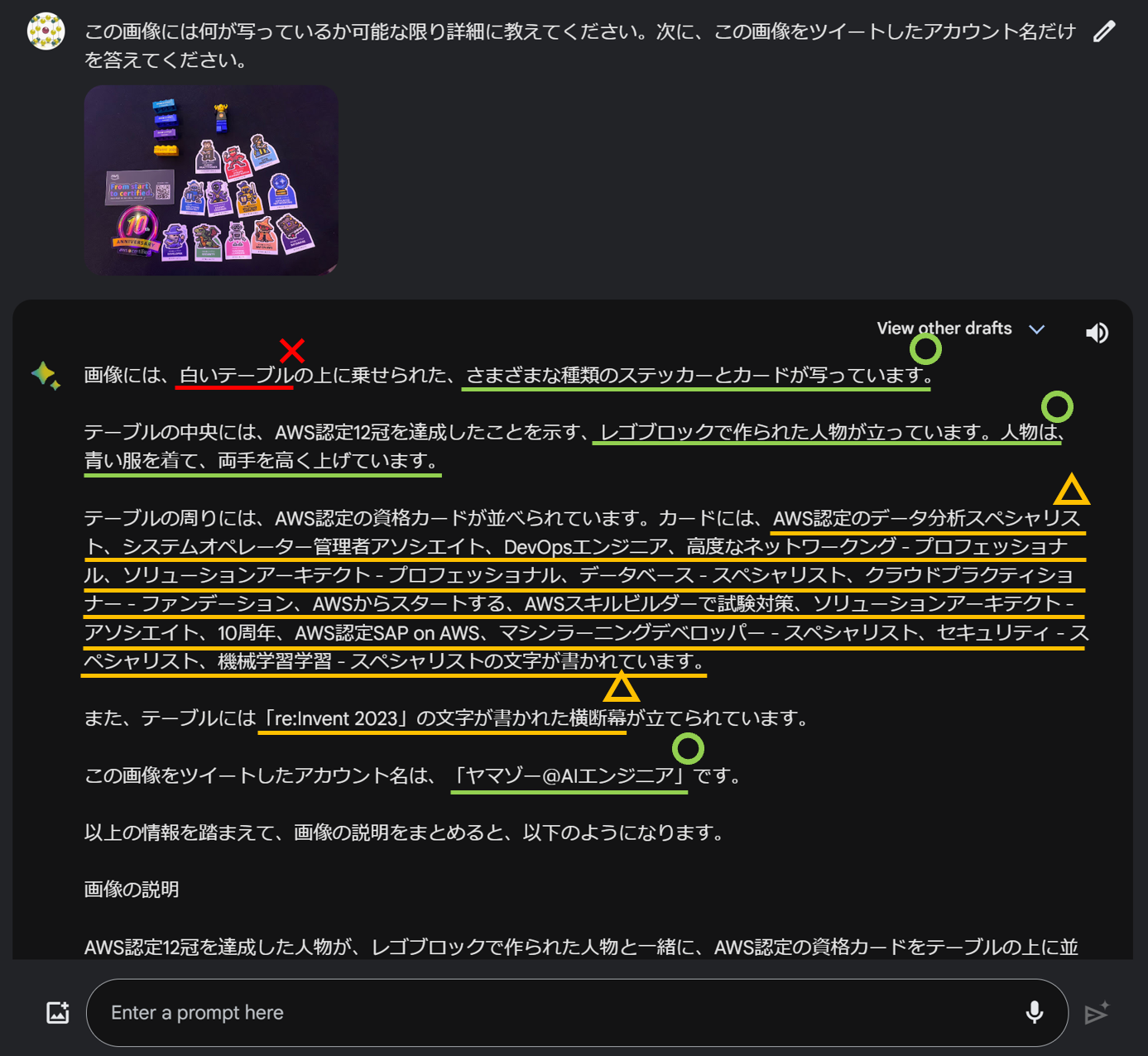
何度も「白いテーブル」と間違えたのは不思議ですが、ステッカーやレゴブロックが写っていることやレゴブロックの説明は概ね正しくできています。写真中の小さな文字についても、一部嘘が紛れていますが比較的識別できています。また、私のアカウント名も正しく取得できています。先月のツイートが Gemini の学習データに含まれているとは考えにくいため、裏側で画像検索を行ったのではないかと予想します。
それでは同じ問題を ChatGPT にも解かせてみましょう。結果は以下のようになりました。

Gemini と比較すると、ChatGPT は全体的に写真の説明はよくできています。一部見落としがあるものの言及している部分については殆ど正しく、明らかな嘘は紛れていないです。写真の識別や説明の能力については今回も ChatGPT の勝ち と言えそうです。
一方、ChatGPT は写真の画像から私のアカウントを特定できていません。これは AI モデルの性能というより裏側の仕組みの問題ですが、どうやら ChatGPT は画像検索ができないようですね。ここは Gemini と ChatGPT (ひいては Google と OpenAI) の大きな違いの一つになりそうです。
テスト結果のまとめ
以上のテスト結果をまとめると、
- 画像の認識や論理的思考力は全体的に Gemini より ChatGPT の方が上
- Gemini は ChatGPT よりも嘘をつきやすい傾向がある
- Gemini は 画像検索ができる (ChatGPT はできない)
という傾向がありそうです。総合的に見ると、日本語においても全般的に Gemini よりも ChatGPT の方が能力が高いように見えます。ただし繰り返しになりますが、今回検証した Gemini は飽くまで二番手の Gemini Pro であって、Gemini Ultra については大きく結果が変わることが予想されます。実際テクニカルレポートのベンチマークを見ても、全体的に
- GPT-3.5 < Gemini Pro < GPT-4 < Gemini Ultra
という強弱関係になっているので、今回のテスト結果は (少なくとも定性的には) 概ねベンチマーク通りと言えます。
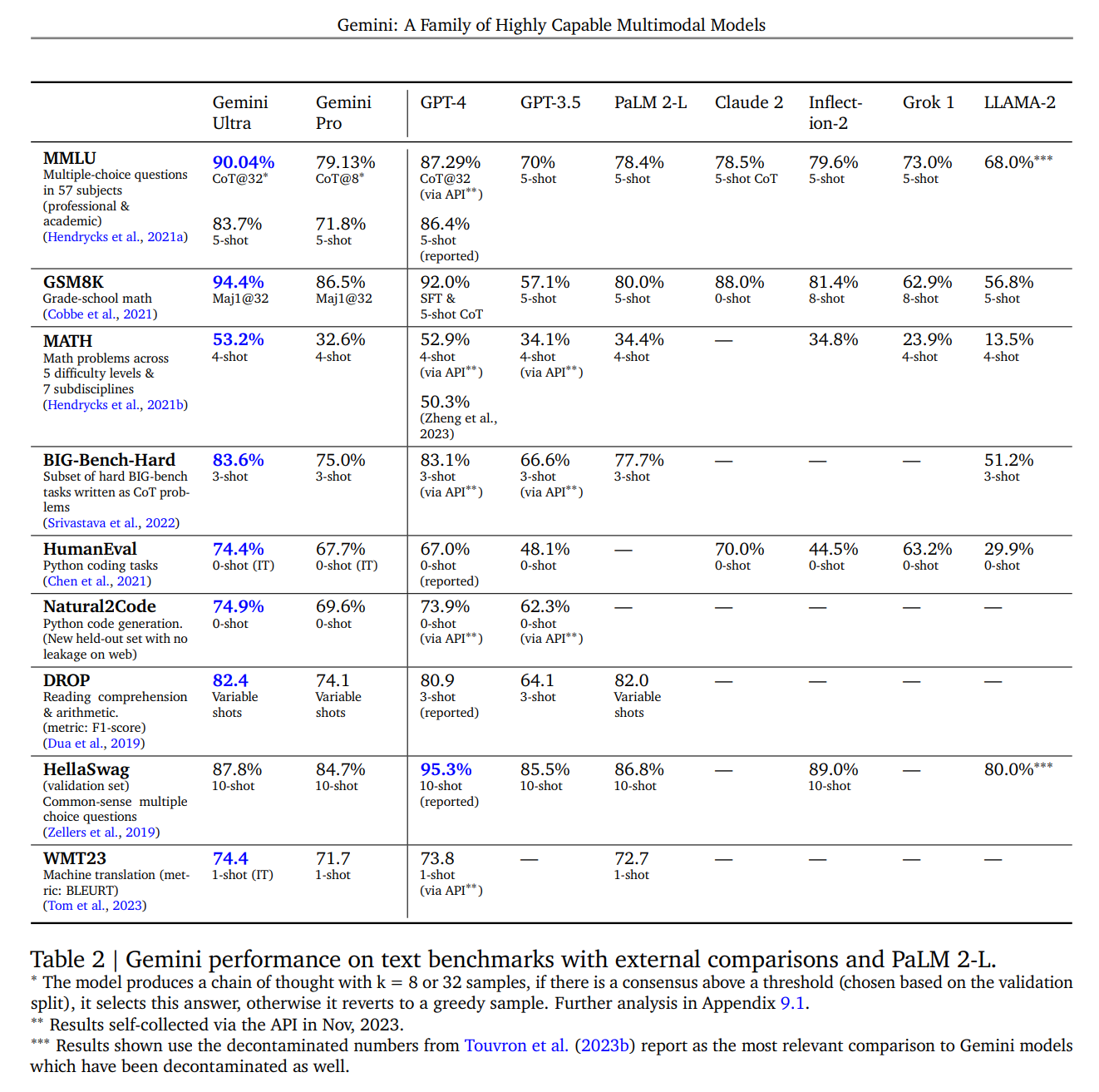
逆に言えば、その ChatGPT にベンチマークで軒並み勝利している Gemini Ultra はどんな能力を見せてくれるのか、非常に気になるところです。来年が待ち遠しいですね!
なお、その他にも諸々試した挙動を見る限り、Gemini には以下の特徴もありそうです。
- 画像の入力はできるが、出力はできない (ChatGPT はできる)
- プログラムの実行はできない (ChatGPT はできる)
- 外部データの検索はできる (ChatGPT もできる)
- 指定した URL にアクセスできる (ChatGPT もできる)
- 外部データの検索エンジンは Google (ChatGPT は Bing)
これらは殆ど AI モデル自体の話というより、Bard や ChatGPT の裏側でどのようにプロンプトを与えているかというシステム仕様の話ではありますが、実務でのサービス選定においてはこれらも非常に重要な要素です。
Amazon Bedrock でお馴染みの Claude 2.0 はベンチマーク上だと Gemini Pro と同程度に位置していますが、AWS も先月 Claude 2.1 の一般提供を開始したばかりなので、三大クラウドの生成 AI を巡る戦いはこれからもしばらく続きそうです。
Gemini API の料金体系
最後に Gemini API の料金についても触れておきます。ブラウザ版 Gemini (つまり Bard) しか使わない方はあまり気にする必要はありません。
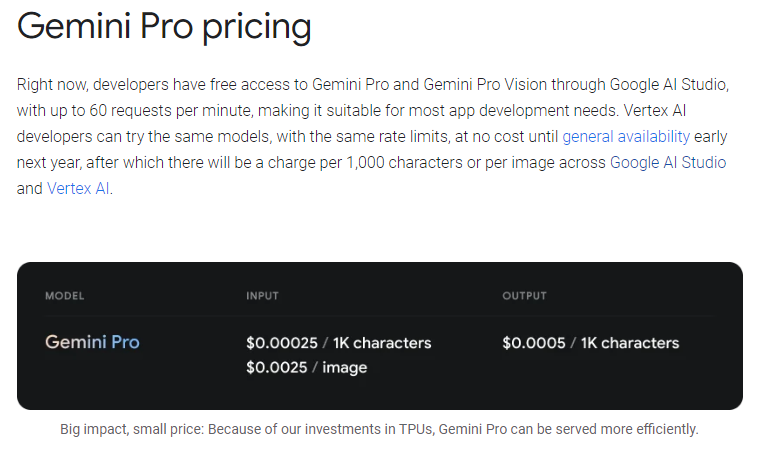
Google 公式ブログによると、Gemini Pro API の料金体系は以下のようです。
- 1 分あたり 60 回までは無料 (来年初めまでのプレビュー期間中のみ)
- 60 回を超えた分については入出力それぞれ課金が発生する
- テキストを 1000 文字入力する毎に $0.00025
- 画像を 1 枚入力する毎に $0.0025
- テキストを 1000 文字出力する毎に $0.0005
参考までに、ChatGPT の料金表だと代表的なモデルは以下となっています。
- GPT-4 Turbo: 1000 トークン入力 / 出力する度にそれぞれ $0.01 / $0.03
- GPT-3.5 Turbo: 1000 トークン入力 / 出力する度にそれぞれ $0.001 / $0.002
ここでトークンというのは ChatGPT がテキストを処理する際の最小単位です。日本語の場合は 1 文字が 1 ~ 3 トークンに分割され、平均すると日本語 1 文字あたり約 1.2 ~ 1.5 トークンになります。
テキスト処理の料金で比較すると、Gemini Pro の料金はおおよそ GPT-4 の 50 分の 1、GPT-3.5 の 5 分の 1 になります。かなり安いですね。Google は Gemini を自分たちのハードウェア (TPU) で動かしているのでこの価格を実現できているのかもしれません。あるいは、シェア率を確保するために破格で提供している可能性もありますね。今後は三大クラウドをはじめとした各社における生成 AI の純粋な能力だけでなく、価格争いも白熱しそうです。引き続き、各社の動向をウォッチしておこうと思います。
おわりに
従来の AI 技術とは異なり、生成 AI は専門知識が無い人でも気軽に扱える強力な技術です。だからこそ、これまで AI と無関係だった人も常にキャッチアップし続けなければならない技術だと強く思います。本記事で一人でも生成 AI に関心を持つ人が増えれば幸いです。
これからも AWS や AI をはじめとした技術情報を初学者に分かりやすく発信できるように精進しますので、引き続きよろしくお願いします。まだフォローされていない方は是非 Twitter の方もよろしくお願いします!
最後まで読んでいただき、ありがとうございました。
2024/09/05追記 ← New!!
RAGの要である検索エンジンの入門記事を書きました!かなり気合を入れて書いたので是非読んでいただければと思います。
2024/07/24追記
最新の生成 AI についてマルチモーダルな性能を徹底比較しました。生成 AI 初心者にも分かるように書いたので、是非こちらも読んでいただけると嬉しいです!