ローカルで動かす Gemma 3 12b を VSCode から呼んでみる
0,Copilot はロマンを感じないのでスルー
「VSCode のAIアシスタントなら、Copilot があるじゃん!」という話はある。
「いやいや、ローカルで賢いAIを使い倒すのがロマンじゃろ?」
「情報漏えいやら、課金やら、気にせず、己の CPUとGPU でガンガン行こうぜ!!」
「そういえば、Gemma 3 12b ってローカルで動くし、かなり賢いじゃん」
行けるんじゃね?そんな話。
1,まず、Ollama を入れる
Ollama とはなにか?を ChatGPT-4o に聞いてみた。
Ollama とは?
Ollama(オラマ) は、ローカル環境で LLM(大規模言語モデル)を動かせるオープンソースの AI ランタイム です。
💡 簡単に言うと、自分のPCで ChatGPT のような AI を動かせるツール!
🛠 Ollama の特徴
✅ ローカル実行: インターネット不要で動作
✅ 軽量&最適化: gguf フォーマットを使い、VRAMを節約
✅ シンプルな CLI: ollama run gemma3:12b のような簡単コマンド
✅ モデル管理: ollama pull で自由に LLM をダウンロード
✅ API 提供: http://127.0.0.1:11434 でローカル API を利用可能
✅ クロスプラットフォーム: Windows / Mac / Linux で動作
Ollama で使える LLM
公式モデルは Ollama モデルページ で確認可能!

Gemma 3 以外にもいろいろあるみたい。あとで、余裕があったら、動くかどうか試してみます。
ということで、まずは Ollama をインストール



2,次に Gemma3 を入れる(VSCodeにContinueを入れたら、ここの動作確認はスキップできるかもしれない。未確認)
ollama がインストールできたのか、バージョンを確認して、
> ollama --version
gemma3:12b を入れてみる。(gemma3:3b は存在しない←間違い)
> ollama pull gemma3:12b


動作確認、gemma3 起動
> ollama run gemma3:12b
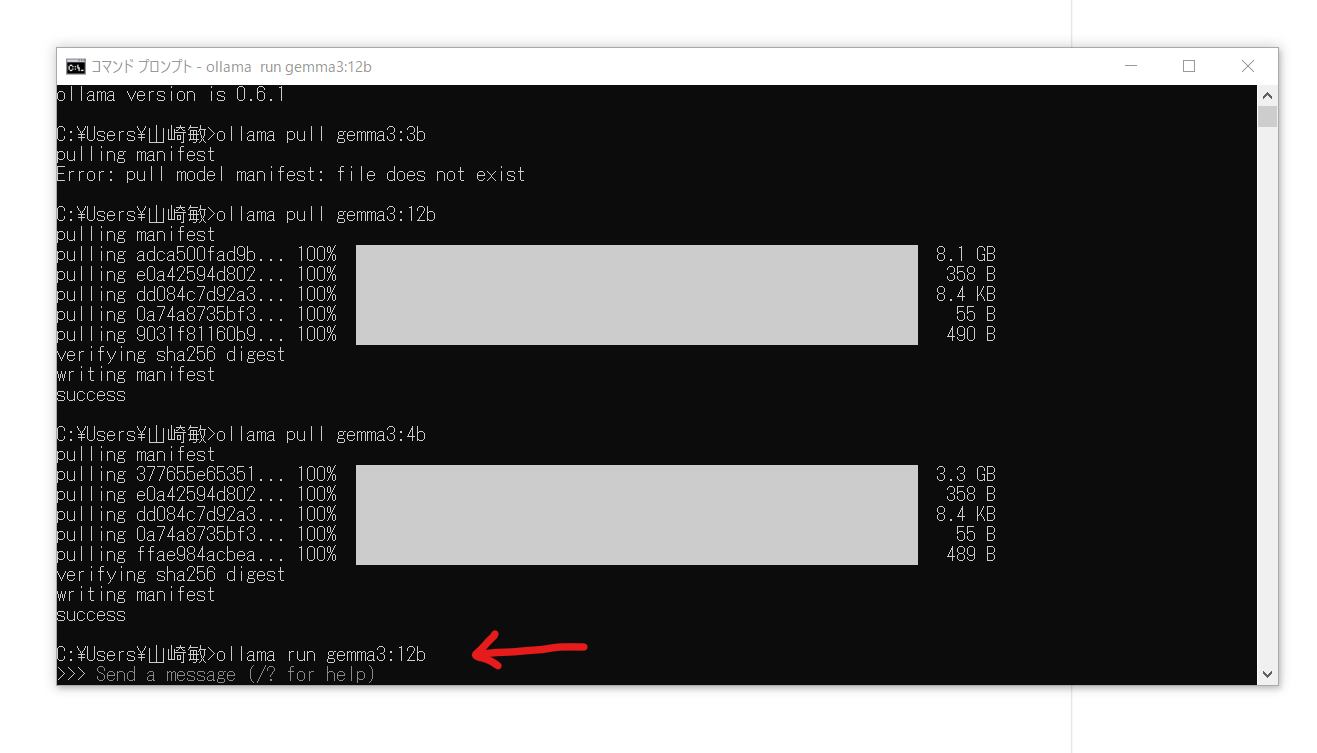
う、動くぞ!
動作確認、プロンプトを入れてみる。
HTMLとJavaScriptを使って、アーケードゲーム「パックマン」に似たゲームを作ってください。
すげー!あっさり動いた。
GPUを使っていないきがするけど、CPU (50%以下)だけでこの生成速度はすごい。
(注意:↓動画は長いので、生成途中をカットしています)

ちなみに、生成されたコードの実行結果はこちら↓。エラーは無いけど、ゲームにはなっていないかな。

2.5,CUDA を入れる(すでに入っているひとはスキップ)
なんかGPUを全然使っていないように見えるから、ChatGPT-4o さんに聞いた。そしたら「CUDA が入ってないでしょ」と言われた。確かに入っていないので入れてみる。

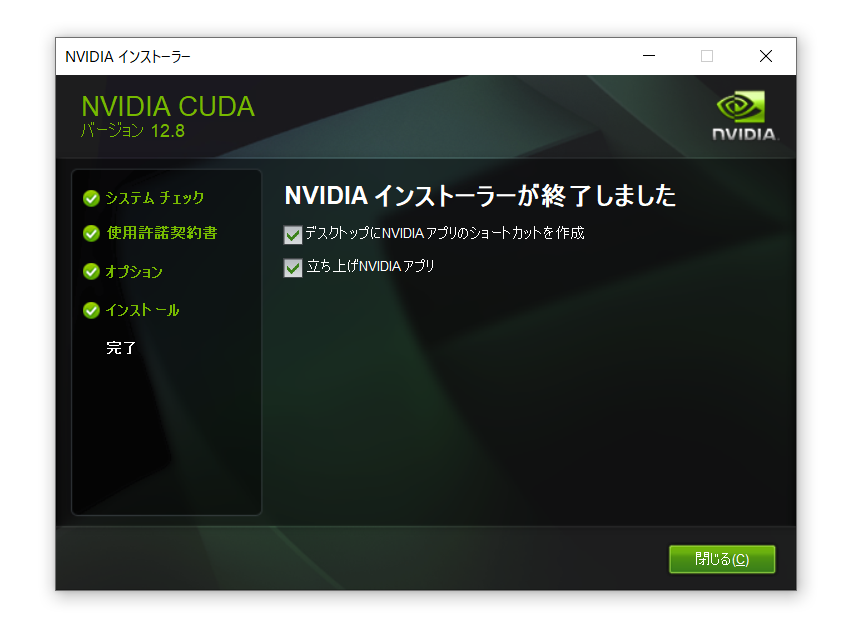
確認↓、入った。

もう一度、試す。
HTMLとJavaScriptを使って、アーケードゲーム「パックマン」に似たゲームを作ってください。
気持ち早くなった気もするけど、そんなに変化は無いかな。

CUDAの項目が上がってました。
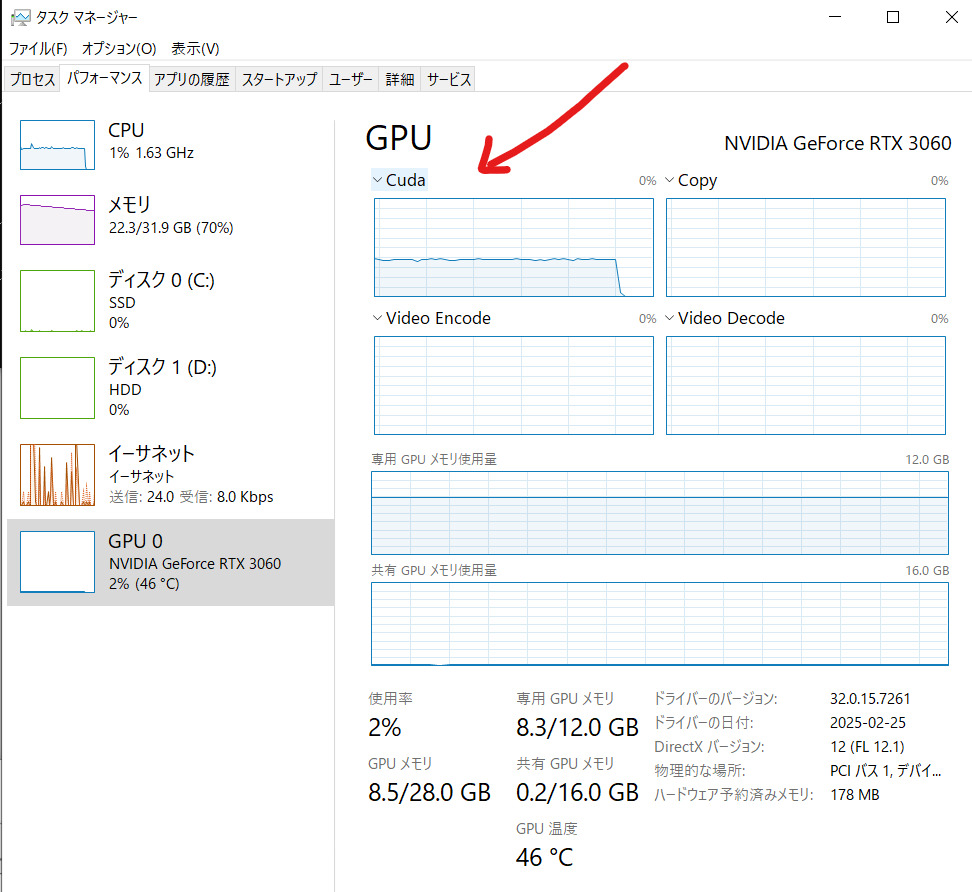
今度は、動いた。一発でこれが出るのは結構すごい。

3,VSCode に Cline を入れる(→入れませんでした→行けるルートがありました)


だけど、Sign in しないと先に進めない。
ので、「ローカルで使いたいのにアカウント作るのイヤなんだけど」とChatGPT-4o さんに聞くと「Continue」なら Sign in はいらないはず。と言われたので、 Cline は Uninstall。
追記:
その後、アカウントを取らなくても行けるルートが見つかったので、↓の Continue でなくても大丈夫でした。
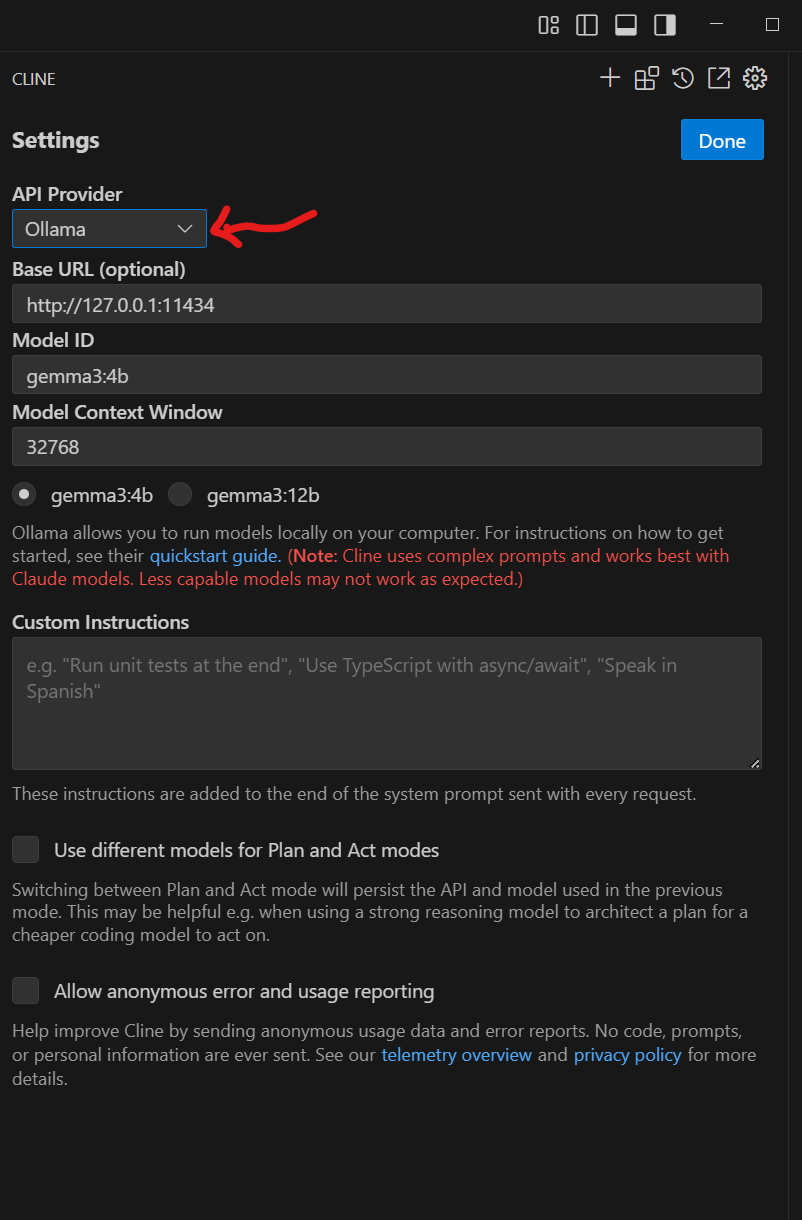
API Provider で Ollama を選択すれば、アカウント無しで、ローカルエージェントが行ける!!
(ただ、私の環境では 12b との連携は無理みたい→単体なら動くけど、VSCode+Clineから12bは、なぜか動きません。みなさんの環境ではいかがでしょう??)
さらに追記:
4b であれば動いている。動いてはいるのだが、Cline が裏で要求するプロンプトをうまく処理できないようだ。Cline は Claude に最適化されているので、ちょっと今の段階で Gemma3 に置き換えるのは難しいという判断に至りました。
3.1,VSCode に Continue を入れる
気を取り直してContinueをインストール

Continueのアイコンが追加されるので、選択して、表示される↓プルダウンから「Add Chat model」を選んで Chat model を追加する

なんか Sign in しなければ行けない雰囲気を感じながらも、動じずに、いったん「Gemma 2」を設定。ここに Gemma 3 があれば、話は簡単なんだけど、まだ入っていないみたい。(待っていれば、すぐに入る気もする)
Provider: Ollama
Model: Gemma 2 2b IT
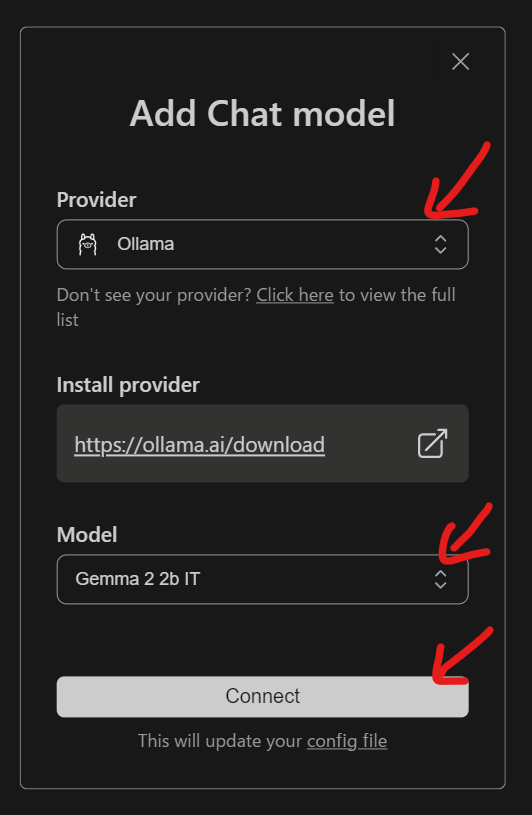
この状態で、ローカルな Gemma 2 が使えるはず。
ここで、Config.json が作られるので、開いて

Gemma 3 (以下のJSON)を強引に追記!!!(この書き方は ChatGPT-4oさんに聞いた。)
{
"title": "Gemma 3 12b",
"model": "gemma3:12b",
"provider": "ollama",
"serverUrl": "http://127.0.0.1:11434"
},
{
"title": "Gemma 3 4b",
"model": "gemma3:4b",
"provider": "ollama",
"serverUrl": "http://127.0.0.1:11434"
}

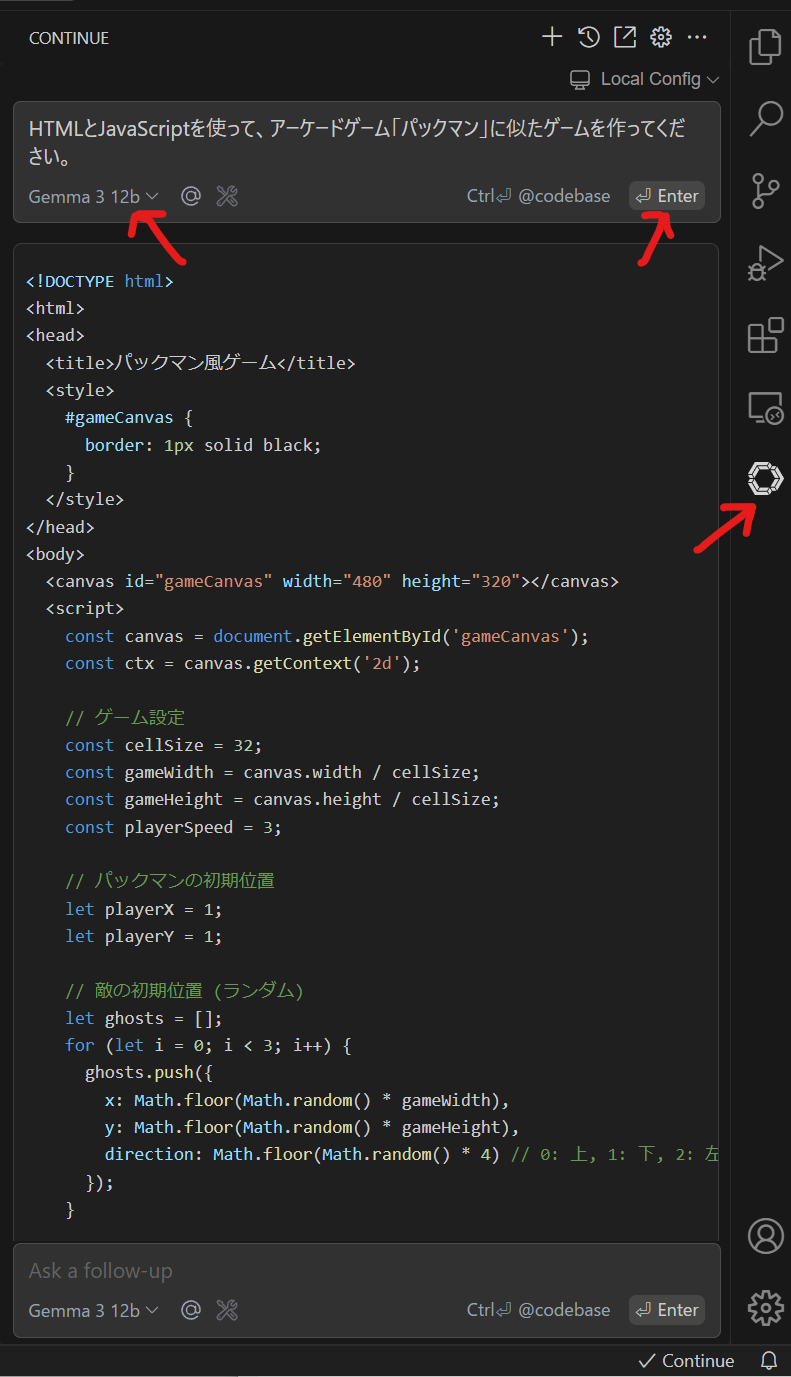
ここまで、で動いたように見えるのだか、動かしていると原因不明でPCが落ちるようになった。まじかー!あと少しなのに。Ollama か Gemma 3 か Continue か VSCode か、どこかの相性なのか、理由はわからない、、、、まさか、熱暴走??うそーん。
って、わたしだけ??みなさまのコメントをお待ちしています。
追記:
その後、なんとなくですが、落ちる理由がわかった気がします。おそらく 12b を動かすにはメモリが足りない、というか、VSCode+Continue の組み合わせで 12b を動かそうとすると、私のPCでは限界を超える模様。
なので、4b を使っていれば大丈夫そう。もう少し、様子を見ます。
それから、Cline でもアカウントを取らずに行けました。(なぜ、そのルートが見つけられなかったのか、今となっては謎ですが。Clineの項目↑に追記しておきました)
というわけで、私のPCでは、4b が限界っぽいことがわかったところで、新しいPCを物色するときが来たんじゃないですかね。
これはもしかして、PC買い替えブームがやってきて、そのままAI半導体ブーム更に加速??
いやぁ、おもしろくなってきました。
それではみなさま、楽しいプログラミングライフをお過ごしくださいませ。