はじめに、この記事の目的
少し前にAmplifyとGraphQLを使って、少人数で完全サーバレスなWebアプリを開発する機会がありました。
誰かの参考になるか分かりませんが、既に消えかけている当時の記憶が完全に消えないうちに、慣れ親しんでいるRESTではなく、Amplify/GraphQLを使ってみて感じた技術・チーム開発観点での気付き をメモしておこうと思います。
いろいろと特殊な制約があり、最終的には少し複雑な構成になりましたが、そこは割愛して、ざっくりTODOアプリ的なものだと思って、読んでいただければと思います。
ざっくり構成
だいたいこのような構成のWebアプリを作りました。極めて標準的な構成です。
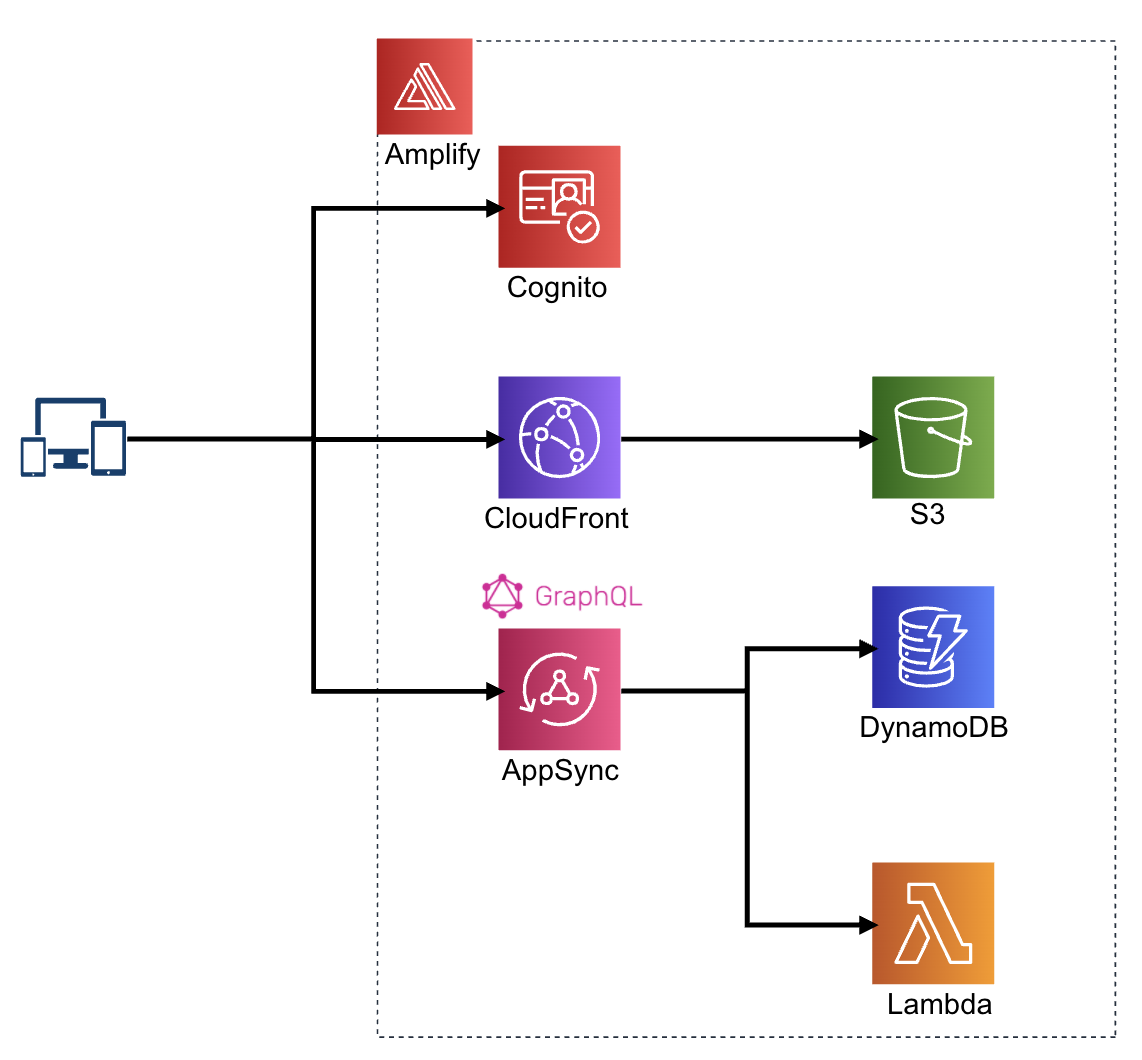
そもそも、なんでAmplify?
いろいろな選択肢がある中で、当時なぜAmplifyを使うことになったのかですが、
短納期リリース かつ 少人数開発 という制約があったので、以下の観点を意識していました。
※ とりあえず使ってみたい!というのも大きかったかも。
- 期待1: ユーザーに価値を届ける機能開発に時間を使いたい
- 認証, WebSocket, バックエンドAPI, データベース, ... 等の機能開発をする上で必要なベースが比較的簡単に作れる。
- 期待2: スケーラビリティ、運用/保守のしやすさ
- マネージドサービスをうまく利用することでユーザー数の増加や、運用/保守の手間を軽減できる。
- 期待3: 複数環境を簡単に作りたい
- 開発/テスト/商用環境といったように用途別の環境を簡単に作れる。
結論としては、Amplifyの機能をうまく使うことで、 上記の三つの期待は実現できました![]()
なので、個人的にはおすすめ! です。
これ以降は、開発の中で感じた便利なこと、困ったことを中心に書いていこうと思います。
実際やってみての気付き、Tips
自動的にフルスタックエンジニアになれます
schema.graphqlに以下のような記述をして、amplify pushすると、DynamoDBのテーブルやresolverやAPIが作成されます。同時にAPIの呼び出しに使う標準的なQueryも作成されるので、Query/Mutation/Subscriptionがすぐに実行できます。簡単ですね。
type Blog @model {
id: ID!
name: String!
posts: [Post] @connection(name: "BlogPosts")
}
type Post @model {
id: ID!
title: String!
blog: Blog @connection(name: "BlogPosts")
comments: [Comment] @connection(name: "PostComments")
}
type Comment @model {
id: ID!
content: String
post: Post @connection(name: "PostComments")
}
また、@model, @connection, @auth, @function, @key, ... といったDirectiveが用意されているので、バックエンド側の基本的な設定もこのSchema.graphqlの中で完結することができます。
※ただし、細かい設定は記述できないので、CloudFormation側で頑張る必要があります。
つまり、このschemaを書くことが、認証設定やデータベース作成やAPI作成をしていることと同じになります。
あとは、フロントエンドの開発をしてしまえば、フルスタックエンジニアの出来上がりです。
他にも、DynamoDB StreamにLambdaを紐付けるのも amplify add functionを実行した時に以下のように設定するだけで済みます。
? What event source do you want to associate with Lambda trigger? Amazon DynamoDB Stream
? Choose the graphql @model(s) Blog
フロントエンド、バックエンド共に TypeScriptで開発できる
少人数チームという制約もあり、できる限り利用する言語/技術は限定したいと思っていました。
そのため、今回はフロントもバックもTypeScriptで統一しました。
上記のフルスタックエンジニアの話にも関わりますが、誰でもどのレイヤーでも触れると
ユーザーストーリーを上から順番に着手していけることもあり、メンバーの意識が自然とユーザー価値に向けられるのも良い点でした!
あと、amplify pushしてできる src/API.tsやsrc/graphql/xxx.ts等のファイルをフロントだけでなくamplify add function で追加したLambdaでも型を参照したくなると思います。
その時は.graphqlconfig.ymlを下記のように修正してあげると、Lambda側でも利用できるようになります。そうすることで、Lambda側も生成された型を使って開発できるようになるので、補完も効いて、開発効率が向上すると思います。
projects:
xxx:
schemaPath: src/graphql/schema.json
includes:
- src/graphql/**/*.ts
excludes:
- ./amplify/**
extensions:
amplify:
codeGenTarget: typescript
generatedFileName: src/API.ts
docsFilePath: src/graphql
yyy(←関数名):
schemaPath: src/graphql/schema.json
includes:
- src/graphql/**/*.ts
excludes:
- ./amplify/**
extensions:
amplify:
codeGenTarget: typescript
generatedFileName: amplify/backend/function/yyy/ts/API.ts # 任意のパスを設定してください
docsFilePath: amplify/backend/function/yyy/ts/graphql # 任意のパスを設定してください
Multiple Environmentで開発者ごとに専用環境を作成できる
Amplifyには、複数の環境を管理するためのMultiple Environmentという機能があります。
公式ドキュメントにも記載されているように、開発/テスト/本番環境ごとに環境を作ることができます。
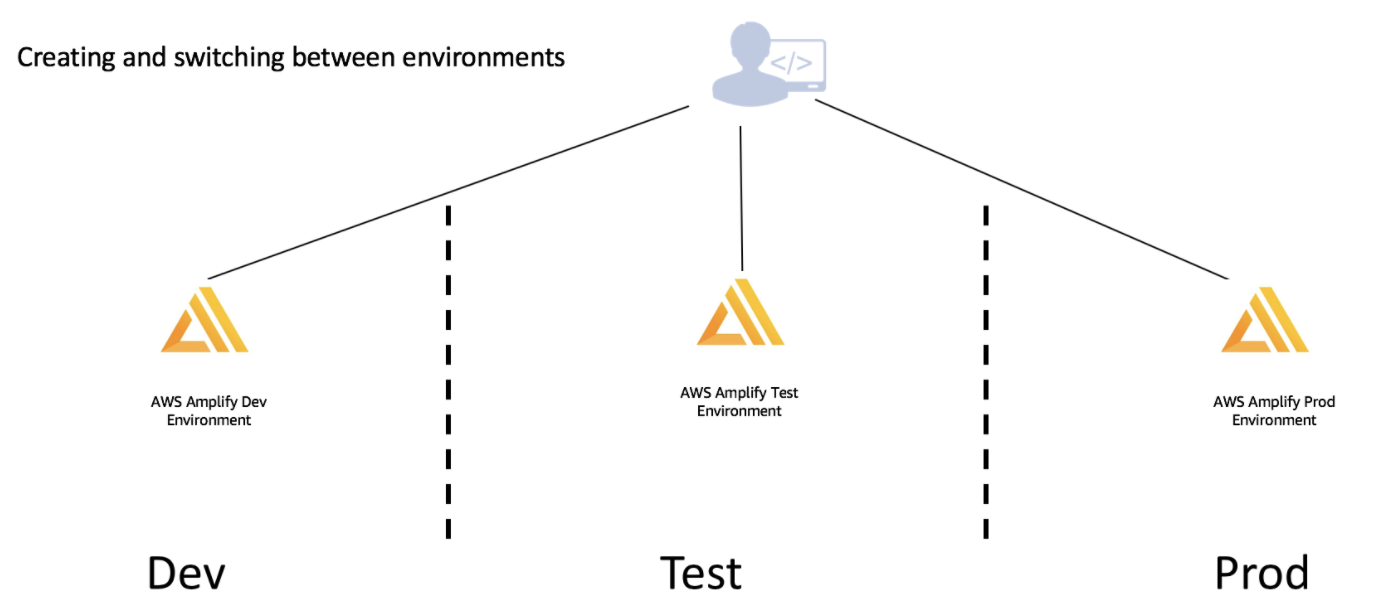
Dev環境の中でも、Dev1,Dev2,...といったように、エンジニアごとに独自の環境を用意して利用できるため、
気軽にいろいろ試せて、環境が壊れても他のエンジニアに影響も与えないため、自由に開発できました。
環境を切り替える場合も、amplify env checkout 環境名を実行するだけで、簡単です。
CI/CDではAmplify Headlessモードを使う!
amplify はコマンドラインの実行が対話式であるため、CI/CD上で自動実行する時に困ります。
そのような場合には、Amplify Headlessモードを使いましょう。
--yes flag
The --yes flag, or its alias -y, suppresses command line prompts if defaults are available, and uses the defaults in command execution.
ドキュメントに記載されている通り、--yesをつけることで、全てデフォルトで進めることができます。
ただし、ここで気をつけておかないといけないことは、--yesをつけると、バックエンド側の変更処理が強制的に実行されるということです。例えば、amplify pull --yesを実行した場合でも、強制的にCloudFormationスタックの変更処理が実行されるということです。その場合は、以下のように実行することで対話式で聞かれる内容をコマンドに渡すことができます。
AMPLIFY="{\
\"projectName\":\"app\",\
\"envName\":\"環境名\",\
\"appId\":\"アプリケーションID\",\
\"defaultEditor\":\"code\"\
}"
AWSCLOUDFORMATIONCONFIG="{\
\"configLevel\":\"project\",\
\"useProfile\":true,\
\"profileName\":\"default\"\
}"
PROVIDERS="{\
\"awscloudformation\":$AWSCLOUDFORMATIONCONFIG\
}"
FRONTENDCONFIG="{\
\"SourceDir\":\"src\",\
\"DistributionDir\":\"dist\",\
\"BuildCommand\":\"yarn generate\",\
\"StartCommand\":\"yarn start\"\
}"
FRONTEND="{\
\"frontend\":\"javascript\",\
\"framework\":\"vue\",\
\"config\":$FRONTENDCONFIG\
}"
amplify pull \
--amplify $AMPLIFY \
--frontend "$FRONTEND" \
--providers $PROVIDERS
この設定でも、対話を0にすることができなかった(2020年9月時点)ので、expectコマンドを利用して回避しました。
最終的には、CodeBuildで複数のAWSアカウントへCI/CDできるようになりました。
結局CloudFormation
今まではAmplifyを使うことで、今まではコードを頑張って書かないといけなかったことがコマンドラインでいくつか設定するだけで
簡単になって便利!という話をしてきましたが、一度触ったことがある人は知っている通り、実際は裏でCloudFormationテンプレートが作成されています。
そのため、対話式のコマンドラインで設定できなかったり、schema.graphqlで表現しきれない部分は、CloudFormationテンプレートを編集して、細かい設定をすることになります。一つ例を書いてみます。
LambdaをVPC内に入れたい
例えば、以下のようにteam-provider-info.jsonやCloudFormationテンプレートを編集することで、実現できます。
"Env名": {
...
"categories": {
"function": {
"関数名": {
"vpcSecurityGroupIds": [
"セキュリティグループID"
],
"vpcSubnetIds": [
"サブネットID",
"サブネットID"
]
},
},
...
}
}
"LambdaFunction": {
...
"Properties": {
...
"VpcConfig": {
"SecurityGroupIds": {
"Ref": "vpcSecurityGroupIds"
},
"SubnetIds": {
"Ref": "vpcSubnetIds"
}
},
...
},
他にもDynamoDBテーブルのバックアップの設定をしたい場合も、"DynamoDBEnablePointInTimeRecovery": "true"のような設定を入れることで実現できます。基本的には同じ方針で、ほとんどのことは設定できました。
チーム開発をしてみて
冒頭の ユーザーに価値を届ける機能開発に時間を使いたい に関わることですが、Amplifyの利用で、バックエンド側の構築にかける時間が減ったこともあり、一つのユーザーストーリー(機能)を一人で開発することのハードルが下がったと思います。それによって、フロントエンドエンジニアとバックエンドエンジニアに分けた場合に生じていたコミュニケーションコストが減り、比較はできていないですが、結果としてベロシティも向上したのではと思います。
また、マネージドサービスかつサーバレスな構成になっているため、運用/保守について、リリース前もそうですがリリース後に必要な作業も減り、機能開発に集中できている感覚はあります。
ただ、フロントエンド、バックエンドのコードの密結合化が進むため、プロジェクトが大規模になったり、人数が増えた場合は、違った工夫が必要になりそうだなーと感じています。
終わりに
- 基本的にはAmplifyの良いところベースで書いてきました。ただ、フレームワークというのは使い始めは、細かいところでつまづくことも多いと思います。ただ、もし興味があるのなら、軽めの開発で試してみるのが良いのではと思います。
- GraphQLについても書きたいことがあったのですが、
疲れた長くなってきたので、また次回にしようと思います。