こんにちは,音楽情報処理の研究をしているしがない人間のひとりです.
今回はMERTという音楽音響信号に対する事前学習済みモデルの論文を読んでみたのでまとめます.
間違い等をもし見つけた場合は,お手数ですがご連絡お願いします.
MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training
(2024.02.15 追記:機械学習のトップカンファレンスとして名高いICLR 2024にアクセプトされたようです!
https://openreview.net/forum?id=w3YZ9MSlBu)
大規模事前学習済みモデルは,NLPで提案されたBERTを皮切りに,様々なドメインで研究が提案されてきました.
音声でもWav2Vec2.0やHuBERT,WavLMなどのモデルが提案され,少ないリソースでもこれらのモデルの転移学習を行うことによって,多くの研究で従来の教師あり学習で達成し得なかった性能を発揮しています.
ここで,音楽情報処理においてもついにこの波が来ます.
最初に訪れた大きな波は,本来は音楽生成に用いられるJukeBoxの中間特徴量を識別の特徴量として用いるJukeMIRです.
なんとJukeBoxの中間出力とシンプルなMLPを使うだけで,4種類の音楽識別タスクにおいてSoTAと同等の性能を達成することができました.
しかしJukeBoxは本来生成モデルである上に,膨大なパラメータ量を有しています(億超え).
これが音楽識別にベストチョイスであるかは怪しく,より特化した枠組みが作れるのではないか,
ということが問題意識として挙げられていました.
より一般的なGeneral purpose audio representation(COLA,AudioLM,NeuralCodec等)を使って音楽識別を解いた事例もありましたが,限られたタスクでしか検証されておらず,音楽情報処理特有の問題に適しているとも限りません.
そこで,音楽識別でこの大規模事前学習済みモデルを作ってしまおう!
というモチベーションで生まれたのがこのMERTです.
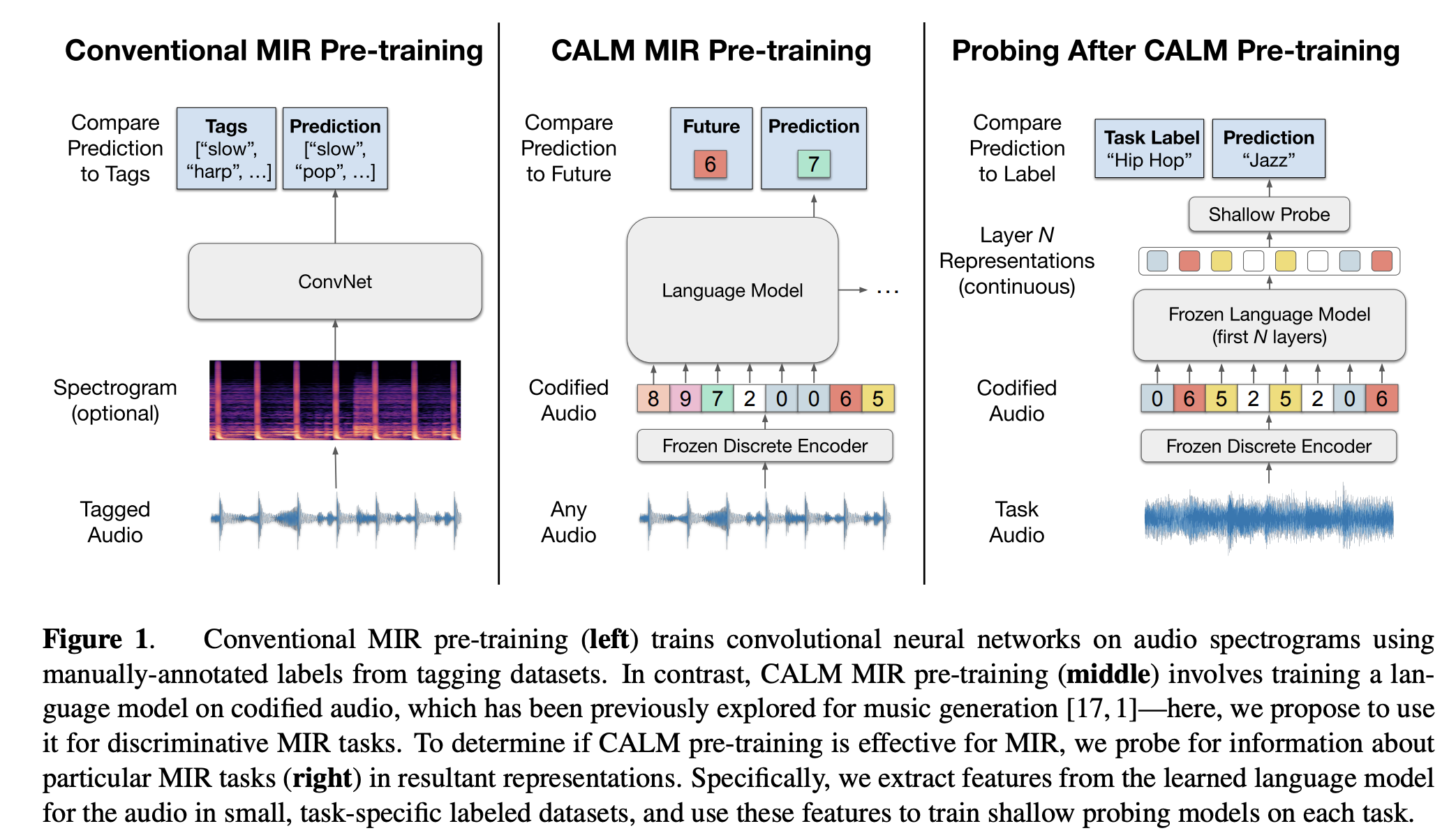
BERTやHuBERTが採用しているようなマスク部予測に基づき,
大量のデータをもとに,前後の文脈を考慮しつつ特徴を推定していくという戦略をとることで学習を行なっています.
(これが,大規模"言語"モデルともいわれる所以でもあるそう.)
ではその仕組みを詳細に紐解いていきたいと思います.
Masked Language Model (MLM)による事前学習
MERTの学習はBERTのMLMにインスパイアされた事前学習方法をとっています.
特に,音声の事前学習済みモデルであるHuBERTと同じ戦略をとっています.
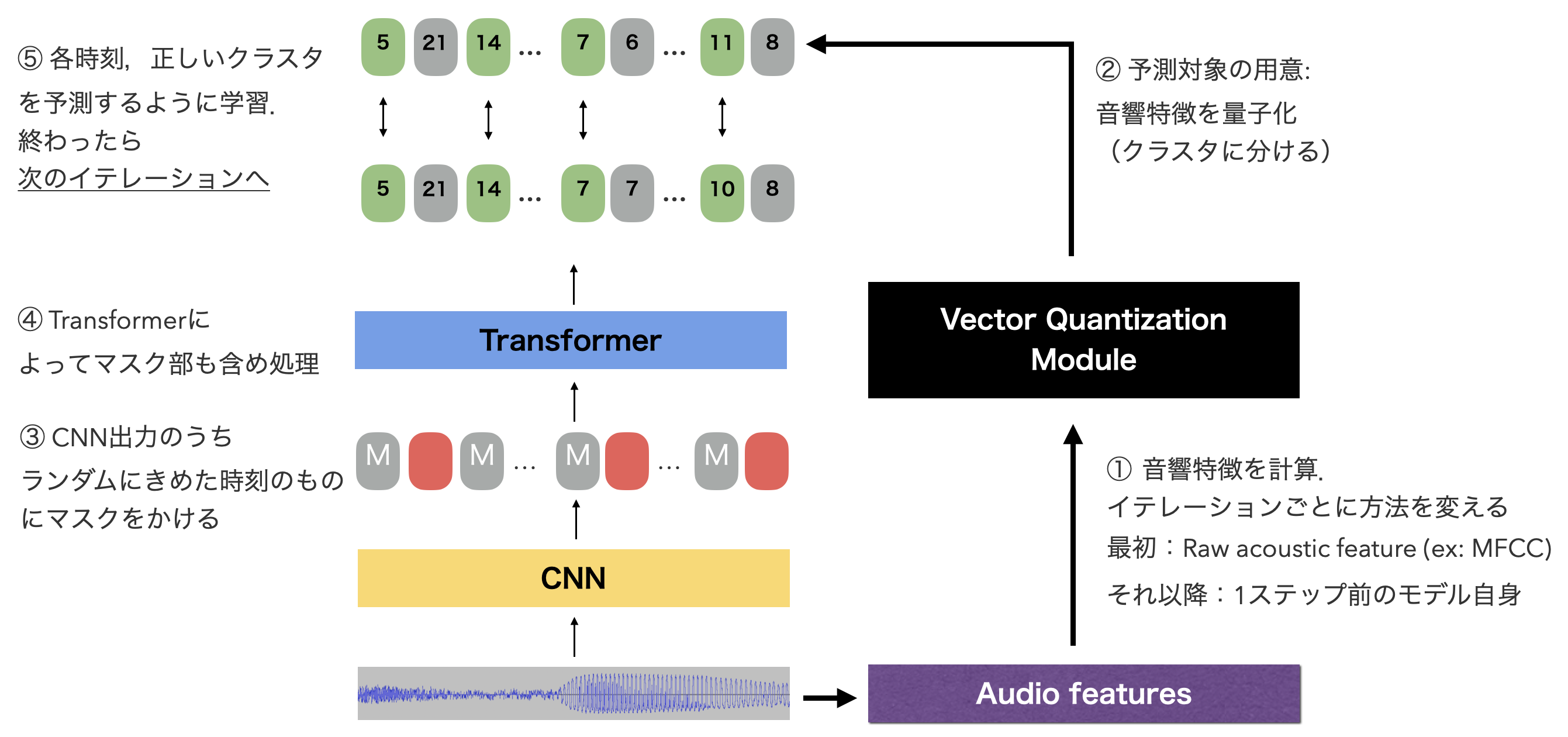
ざっくり言えば,モデルのTransformerに対してランダム時刻にマスクをかけた状態のものを入力し,出力のうちマスクをかけた時刻があらかじめ計算しておいた,k-means量子化後の音響特徴量(MFCC)のクラスタを予測するように学習を行う,というものです.
図の通りです.
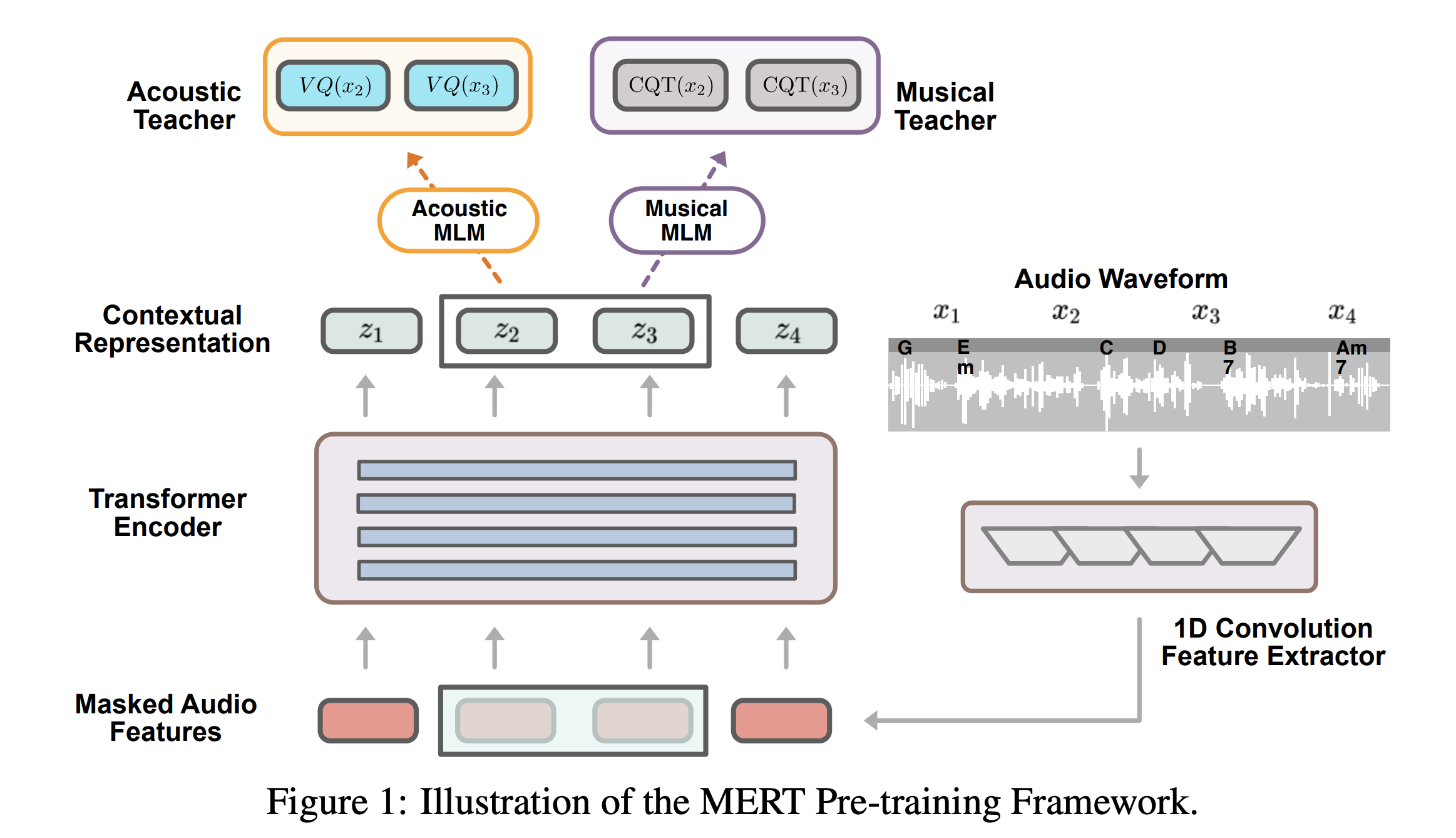
さらに,これに加えてMERTは,音楽音響信号特有の特徴を捉えるためにさらなる工夫を加えています.
1. 量子化する音響特徴量をMFCCから変更
MFCCは単音の音色のモデリングにおいてはよい特徴量であると言えますが,多くの音楽のように混合音の音色のモデリングには適していません1.
ここで代わりの方法として以下の二つを考えます
- MFCCのかわりに,もっと音楽に適した情報量の多い特徴量を用いる -> 対数メルスペクトル+クロマ特徴
- 深層学習ベースの特徴抽出器を用いる -> RVQ
k-means + 音響特徴強化 バージョン:
おそらくこれ とこれ
MFCCの代わりに,音色情報として229次元対数メルスペクトルと,ハーモニック情報としてクロマ特徴を用います.
クロマ特徴は音楽音響信号で特有に扱われる特徴で,12音階(C,C#,D,...,B)の各ピッチクラスの成分の強さを表すものです.
メルスペクトルには300個のセントロイド, クロマ特徴には200個のセントロイドを用意し,掛け合わせた60,000クラスタを用意します.
EnCodec バージョン:
おそらくこれ:BaseとLarge2
もう一つの方法が,EnCodecを用いる方法で, Residual Vector Quantization (RVQ)という手法にもとづいて量子化を行います.
RVQはスキップコネクションつきで階層的にベクトル量子化を行い,高表現力かつコンパクトな量子化を目指すものです.
RVQによって,時間長$L$の入力信号から$D^{L\times8}$の次元数をもつ2次元量子化コードブックが得られます.
これを予測のターゲットに用います.
2. 音楽情報特化のターゲットの追加
さらにこれに加え,音楽に欠かせないピッチの情報を保持するために,これ加え別のターゲットとしてConstant-Q Transform (CQT) スペクトログラムを加え,TransformerにはCQTスペクトログラムを復元するタスクも解かせます.
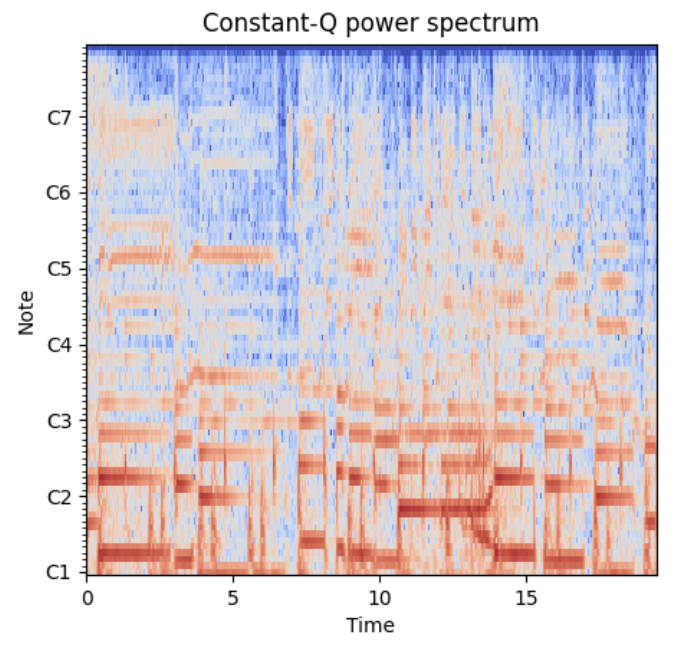
CQTは時間周波数分析の方法の一つで,その時刻ごとの計算結果の集積であるCQTスペクトログラムは,ピッチ関連の音楽情報処理タスクにおいては広く用いられてきました.
窓幅を全ての周波数で一定にするSTFTと異なり,CQTでは窓幅が周波数の値に比例しています.
各オクターブに同じ数だけビンが割り当てられ,低域の解像度をSTFTのそれより高くできるためピッチ解析に向いている,という感じです.
このCQTスペクトログラム復元の学習はMSEの最小化によって行います.
最終的にこの量子化音響特徴の予測 + CQTスペクトログラムの復元のそれぞれのロスは, ハイパーパラメータ$\alpha$を用いて,
$L = \alpha ・ L_{VQ} + L_{CQT}$
と表現されます.
3. In-batch noise mixup
さらにロバスト性の向上のために,データをmixしながら学習をします.
一定確率であるバッチのサンプルに同じバッチ内のサンプルをランダム位置に加えるというシンプルなものです.
総合すると,MERTの学習は以下のようになります.

学習データ
今回異なる条件を4つ用意します.
MERT-95M-kmeans, MERT-95M-public-kmeans, MERT-95M-RVQ(Base), MERT-330M-RVQ(Large)です.
それぞれ学習に用いたデータの量が異なります.
- Large
- 160,000時間の音楽データ(From internetとあり,詳細は不明)
- 95M
- 1000時間の音楽データ(同上)
- 95M-public
- 計910時間のmusic4all dataset
また学習時,入力信号から5秒をランダムクロップしてミニバッチを作り出しています.
バッチサイズはBase modelでは1080(1.5時間)でLarge modelでは3960(5.5時間),
学習率はBase modelでは5e-4でLarge modelでは1.5e-3に設定されていました.
実験
下流タスクでの実験
14個のタスクで実験を行います.これは,同時期著者らがリリースしたベンチマークセットであるMARBLEに基づきます.
それぞれのタスクの適用は,シンプルなMLPを用意したProbing(下流タスク学習時モデルパラメータはfix.特徴抽出器として扱う)によって行いました.
また,一番大きいLargeモデルでは学習が不安定になることを観測し,それを防ぐために種々の工夫が施されています.(詳しくはAppendix B.3を見てください)
比較モデルは以下の通り:
- MusiCNN: 互いに異なるカーネル形状をもつ5層のCNN.音楽タグの教師あり学習モデル
- CLMR: Contrastive learningによる教師なし学習
- JukeMIR: Jukeboxの中間出力を特徴量として利用
- MULE Contrastive learningによる教師なし学習
- HuBERT-Base music:HuBERTをMERTと同じデータセットで学習
- Data2Vec music:Data2VecをMERTと同じデータセットで学習
- 各タスクのSoTA 3
結果として,全ての平均をとったところ,MERTのLargeモデル(330M+RVQモデル)が一番性能がよいことがわかりました.
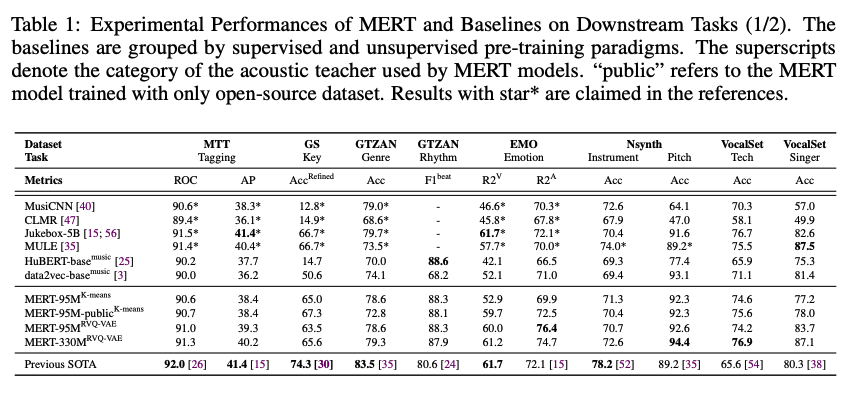
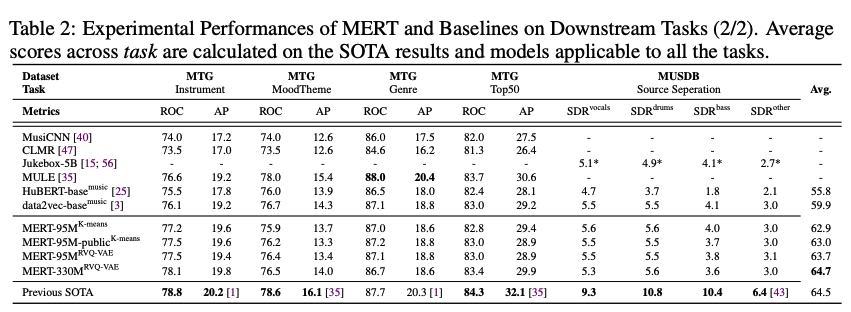
とくにMERTは他のモデルに比べ局所的な特徴が重要なタスク(ビート・ピッチ等)に強いということが述べられています.
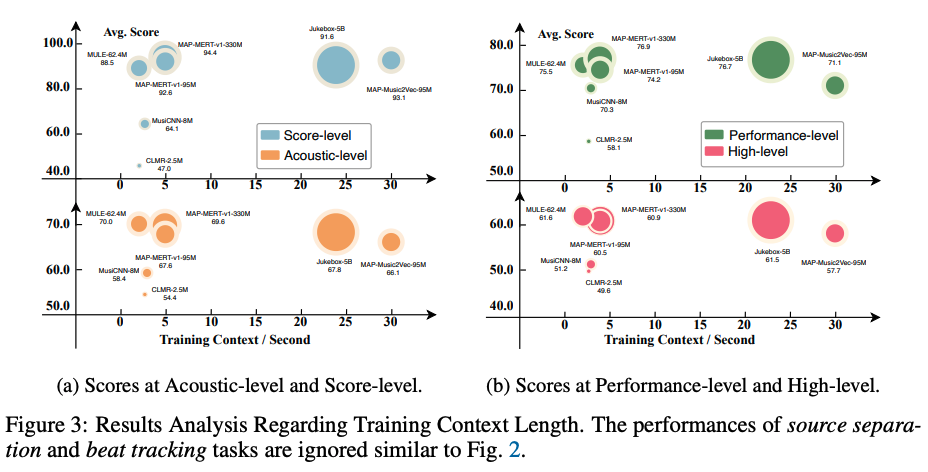
以下の図はMARBLEの論文からの引用ですが,パラメータに関しても,JukeMIRより少ないパラメータで同等の性能が得られていることがわかります.
Ablation study
さらにAblation Studyとして95Mのパラメータ量のモデルにおいて,MFCCをメルスペクトル+クロマ特徴に置き換えることと,CQTスペクトログラム復元の追加の有用性を示しました.
しかし,HuBERTのようにイテレーションによる改善は有意に見られないようでした.
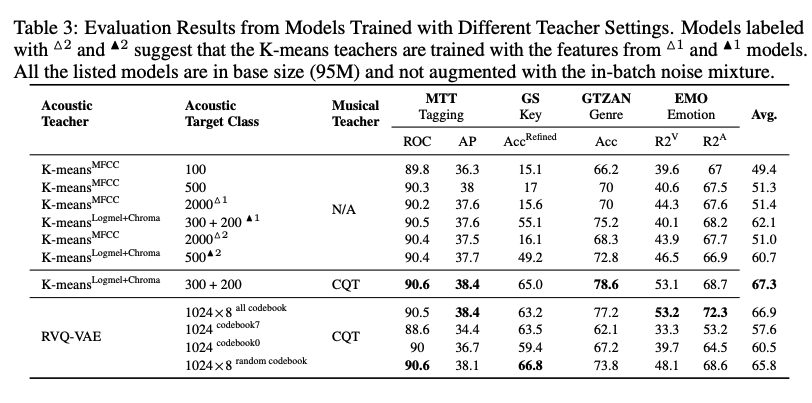
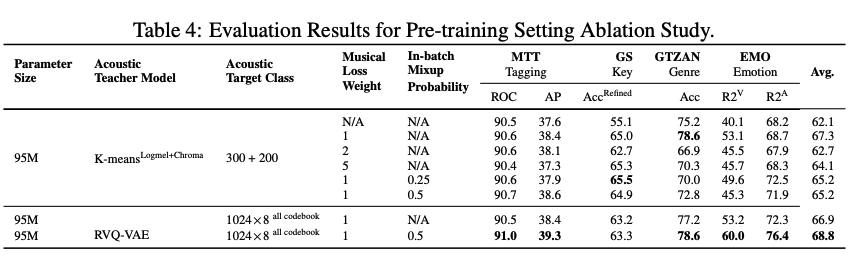
また,トレーニング方法のAblation study(VQロスの重み$\alpha$,mixupの確率,量子化手法)により,
RVQとmixupの組み合わせで精度が向上することを示しました.
(2024.02.15 追記)
ICLR2024のopenreviewにて,Encodecの潜在変数を特徴量を使うだけでもこの性能は得られるのではないか?という指摘がありました.
この指摘を受け,実際にいくつかのタスクで検証した結果がリバッタルで追加されていました.
95MのkmeansとRVQモデルとEncodec,そしてEncodecのEncoder出力(離散化前)を比較した結果が以下のテーブルです.
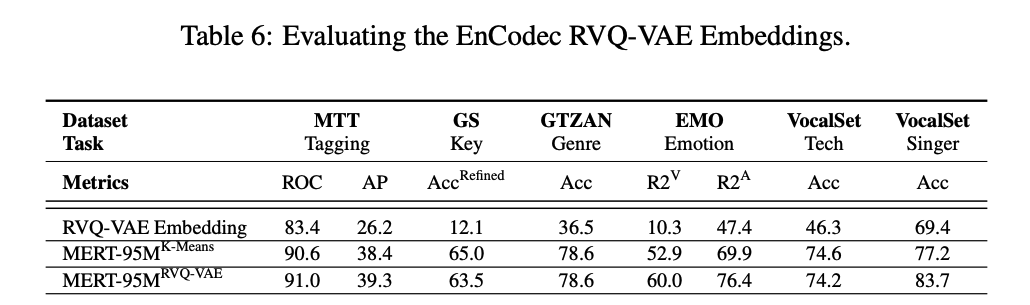
全てのタスクでMERTの両モデルがEncodecの性能を上回り,やはりEncodecのみでは不十分であることを示しています.
MERTを適用した研究 (2024.02.15 追記)
早くもMERTを適用した研究が出始めています.
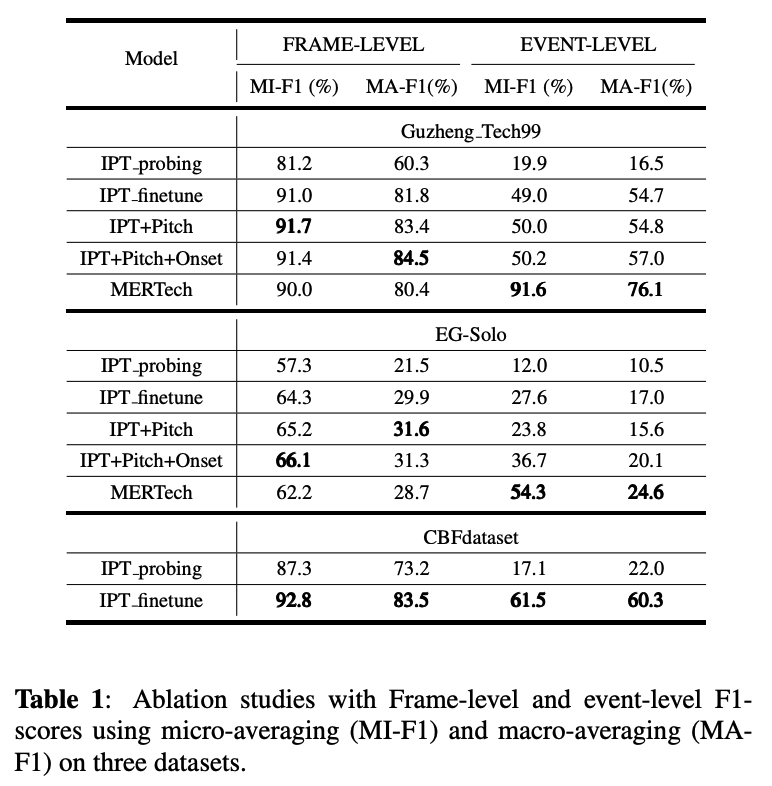
- MERTech
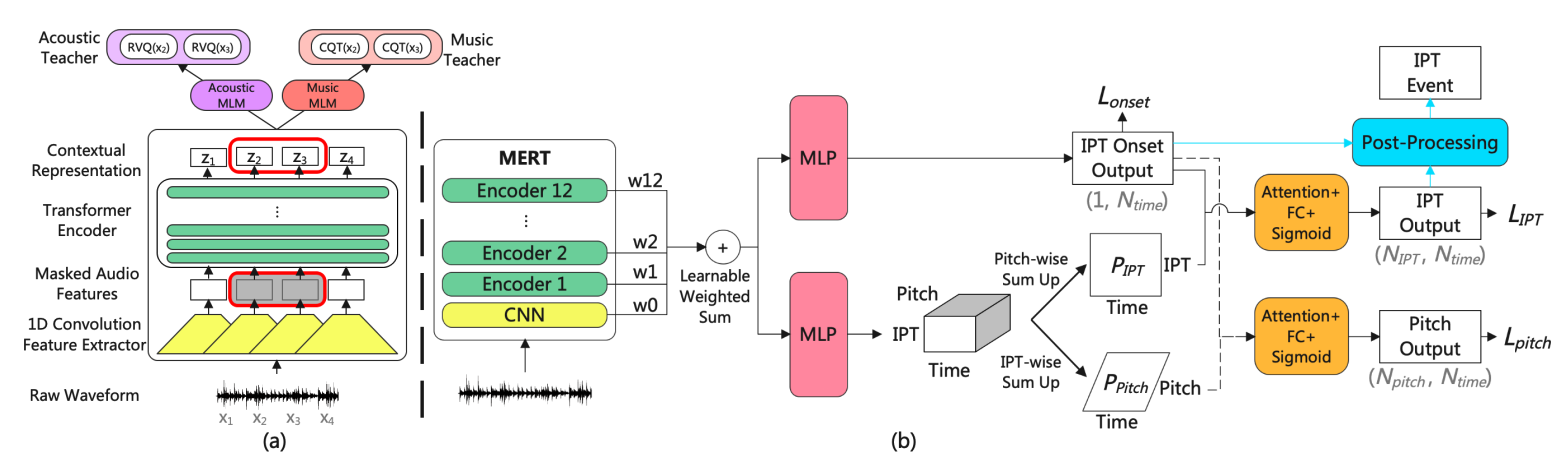
MERTが早くも効力を発揮したのは,データとアノテーションが集めにくいタスクでした. その代表例である,演奏音から演奏テクニック(スライド,ミュート等)の種類と区間を識別する演奏テクニック識別4に使われたのが,このMERTechです.
MERTechは楽器演奏テクニックの識別タスクにおいて,特徴量としてMERTの出力を利用するというものです.
さらに,1)層ごとの出力の重みづけ和をとる, 2)downstream-taskをマルチタスクにする,という2つの工夫が加えられていました.
1)について,MERTの元論文においては深く議論はされていませんでしたが,多くの音のSSLモデル(例えば,基となったHuBERTとか)は層ごとに異なる側面の特徴を捉える5ということが示唆されています.
実は私も歌声タスクにおいて初期的な検討を行っていましたが,見られた性質として入力に近い層では音色等のプリミティブな特徴,後半ではマスク部復元のために大いに関わるピッチ等の特徴を捉えていることが示唆されました.この異なる側面を持つ各層の特徴をフル活用するために,各層の出力に対してどれを重視するかの学習可能な重みを与えるという方法を適用しています.
2)について,テクニックだけではなく,音の立ち上がり(オンセット)とピッチのマルチタスク学習を目的タスクである演奏テクニック識別と併せて行います.
テクニックの場合は,普通のテクニックなしの演奏と区別するポイントとして,ピッチ(例えばトレモロ等だと音高の周期的な上下),オンセット(例えばオンセットのすぐ後にピッチが変わっていればベンドやスライド)の情報が役に立ちそうです.
そうした他の情報との関連性を仮定して同時に問題を解くマルチタスク学習を取り入れています.
実際にGuzheng(中国の琴),ギター,中国の横笛での演奏テクニックの識別の結果,それぞれのSoTAを上回る性能をあげています.
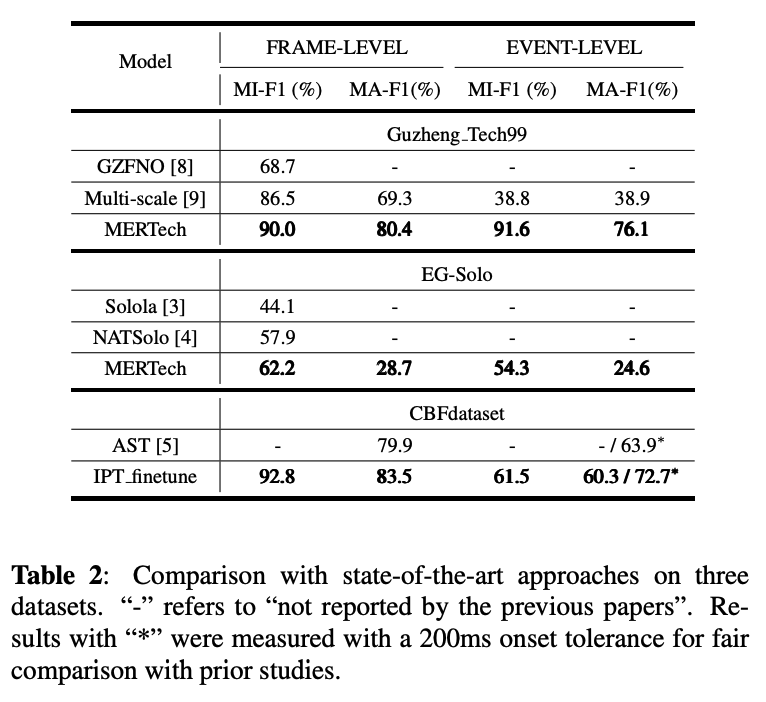
また,マルチタスク学習による下流タスクの学習も効果があるようです.
- Music Understanding LLaMA
画像でいうCLIP Encoderのような特定モダリティの特徴として利用し,他のモーダルと融合するマルチモーダル学習にMERTを利用した研究も出始めました.
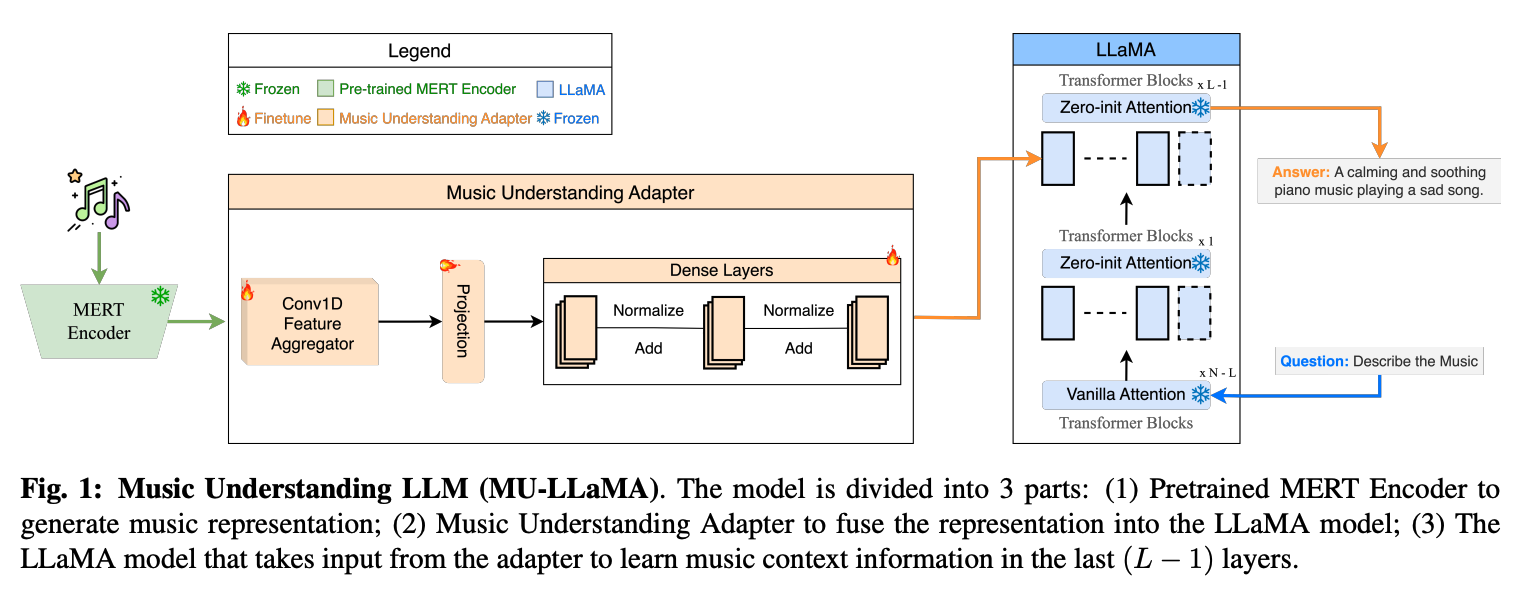
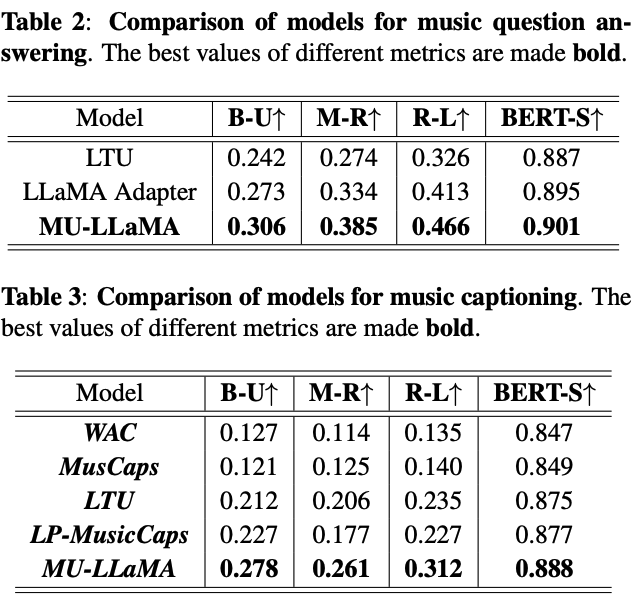
音楽に対する対話的なQ&A(Music Q&A)を行えるというモデルです.
こちらから試すことができますが,「この音楽についての説明を行ってください」,「何の楽器が鳴っていますか?」,「どんなジャンルですか?」等音楽に対する質問文を入力として与えると,答えを返してくれる,というものです.
MERTは音楽音響信号の情報を捉えるためのEncoderとして利用されています.
この情報は続けてMusic Understanding Adapterという機構に渡され,これが学習可能で,MERTの情報をうまくMusic Q&Aに適応させるために用います. AdapterはNLPにおいて大きな事前学習モデルをファインチューンする方法として確立されつつありますね.Parameter-Efficient Fine-Tuningが一般的な呼称でしょうか.
そしてこの情報は自然言語処理のLLMの一つであるLLaMAの最終層の入力に用いられます.
質問文がLLaMAの入力として用いられ,最終層でマルチヘッドアテンションのクエリとしてAdapterからの出力を利用し,回答文を生成します.
実際にQ&AやCaptioning双方で最良の性能を得られているようです.
まとめ
ついに音楽にもBERTのようなモデルがきました.
音楽情報処理はデータの性質上,タスクによっては特にデータも集めにくいので,恩恵を受ける研究者が多いのではないでしょうか.(私もそう)
個人的には,MERTはただ他のモダリティでの方法を適用するだけでなく,音声や他モダリティにない特有の問題にうまく着目したなぁと思います.
ただ,まだまだやれることはありそうな印象です.
MERT以上の性能を持つ事前学習モデルの提案もそうですし,Downstreamタスクへの適用方法やより多くのタスクでの検証等もこれからの課題になるかと思います.かくいう私もそれに取り組んでいる一人です.
ただ個人的な見解として,音楽情報処理というフィールドが小さい上に,このようなラージな研究ができるチームは限られていると思うので,NLPほどのレッドオーシャンにはならないとは思いますが,果たしてどうなるでしょうか? MERTを提案したグループ; MAPもどうやら色々な大学のチームが集まって研究を邁進中であると思うので,彼らの動向も注目したいところです.
リンクたち
論文:https://arxiv.org/abs/2306.00107
Github:https://github.com/yizhilll/MERT
Huggnig face:https://huggingface.co/m-a-p
MARBLE ベンチマークセット:https://marble-bm.shef.ac.uk/
-
論文中にはそうありましたが,私はこう言い切っていることには疑問を持っています.ある程度には,音色テクスチャの役割はMFCCでも担えるのでは ないかと思っています.エビデンスとなる文献も引用されていませんでした.採用した2つの音響特徴のほうがよさそう,というのは同意ですし,実際に性能も上がっているのですが,言い過ぎでは... ↩
-
Encodecに合わせているため,入力のサンプリングレートは音声やk-means MERTの16kHzではなく,24kHzになります. ↩
-
音声SSLモデルが層ごとに何を捉えているか?に関する一連の研究:https://github.com/ankitapasad/layerwise-analysis?tab=readme-ov-file ↩
-
演奏テクニックのデータの集めにくさは,テクニックが出るような演奏でデータセットを組まないといけない,アノテーションに専門性と手間を要する,テクニックは極めて局所的な出現となるためサンプルとして量を集めにくい,という三重苦. ↩