はじめに
Azure Synapse AnalyticsのサーバーSQLプールが日本リージョンで利用可能になっていたので本サービスの概要と最低限利用できるところまでまとめました。
Azure Synapse Analyticsのプールについて
Azure Synapse Analyticsで利用な可能なプールは以下の3つです。
- 専用SQLプール
- Sparkプール
- サーバレスSQLプール
専用SLQプールとSparkプール
これらのうち__専用SLQプール__と__Sparkプール__ではホットスタンバイが必須で、1か月起動したままにすると一番低いスペックでも約¥15万/月(2020/11/29現在)かかってしまうため利用するためには運用に注意が必要です。
サーバレスSQLプール
本題のサーバレスSQLプールでは課金体系が他2つとは大きく異なり、読み込んだデータサイズによって課金額がきまるらしいです。価格は¥672/1TB(2020/11/29現在)であり、他2つと比較すると手軽に利用できます。
構築手順
Azure CLIを使って構築していきます。
利用するサブスクリプションを指定
az login
az account set --subscription 00000000-0000-0000-0000-000000000000
リソースグループを作成
az group create -l japaneast -n test
ストレージアカウントとファイルシステムを作成
デフォルトで利用するストレージ アカウントのファイルシステムを指定する必要があります。
(注意)ストレージアカウントのパフォーマンス上限を見て既存のストレージアカウントを利用するか決める必要があります。1
az storage account create -n sttestsynapse -g test -l japaneast
az storage container create -n synapse --account-name sttestsynapse
Azure Synapse Analyticsのワークスペースを作成
az synapse workspace create --name syn-test --resource-group test \
--storage-account sttestsynapse --file-system synapse \
--sql-admin-login-user cliuser --sql-admin-login-password Password123! --location japaneast
ファイアウォールを設定
この設定をしていないと外部からの接続ができないです。
IPアドレスは適切に設定してください。
az synapse workspace firewall-rule create --name allowAll --workspace-name syn-test \
--resource-group test --start-ip-address 0.0.0.0 --end-ip-address 255.255.255.255
コスト管理の設定
大量のクエリを無自覚に実行してしまうと翌月に多額の請求が来るため、予防策としてデータ読み込みの上限を設定します。
こちらはAzure CLIで設定する方法が見つからなかったのでコンソール画面上で設定する方法を共有するのに留めておきます。
Synapse Studio におけるサーバーレス SQL プールのコスト管理の構成
利用手順
今回はストレージアカウントに格納したcsvファイルを読み取るところまでしたいと思います。実際にはcsvだけでなくparqeutファイルも読み取れたり、その他多岐にわたるコネクターがサポートされています。
サンプルデータを格納
国税調査のデータをダウンロードして作成したストレージに格納します。
az storage blob upload-batch -d synapse -s .\DB2015_TyoA00_csv_13112 --account-name sttestsynapse
Azure Data Studioを使ってクエリを実行
こちらからAzure Data Studioをインストールします。
以下のコマンドでサーバ名を取得
az synapse workspace show --name syn-test --resource-group test --query connectivityEndpoints.sqlOnDemand
表示されたサーバ名を使ってAzure Data Studioでコネクションを作成
(注意)ログインしたアカウントの権限を使ってストレージへアクセスするため、格納したデータへのread権限があるアカウントでログインします。
クエリの実行
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://sttestsynapse.dfs.core.windows.net/synapse/DB2015_TyoA00-01_2000_13112.csv',
FORMAT = 'CSV',
PARSER_VERSION='2.0'
) AS [result]
結果
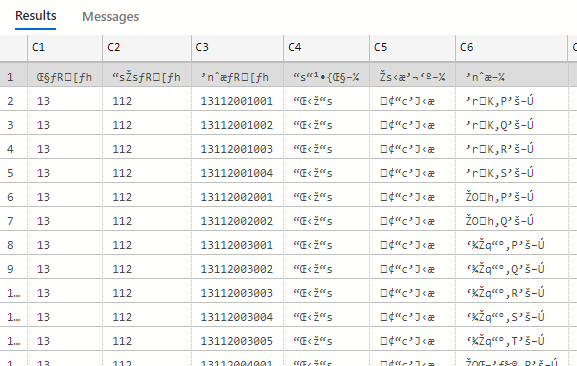
みごとに文字化けしてます。
こちらを参考にして照会順序の設定による解決方法を試します。
-- 国勢調査のファイルがshift-jisなためJapaneseを指定
CREATE DATABASE test COLLATE Japanese_CS_AI_KS_WS
Databaseをtestに変更して再度クエリを実行します。

日本語表示されました。
しかし、カラム名が正しく反映されていないです。
HEADER_ROW=TRUEを追加して再実行してみます。
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://sttestsynapse.dfs.core.windows.net/synapse/DB2015_TyoA00-01_2000_13112.csv',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
HEADER_ROW=TRUE
) AS [result]
以下のエラーメッセージが表示されてしまいました。
調べてもよくわからず、UTF8じゃないと対応してないのかもしれないです。
Potential conversion error while reading VARCHAR column '�s���{����' from UTF8 encoded text. Change database collation to a UTF8 collation or specify explicit column schema in WITH clause and assign UTF8 collation to VARCHAR columns.
Potential conversion error while reading VARCHAR column '�s�撬����' from UTF8 encoded text. Change database collation to a UTF8 collation or specify explicit column schema in WITH clause and assign UTF8 collation to VARCHAR columns.
Potential conversion error while reading VARCHAR column '�n�於' from UTF8 encoded text. Change database collation to a UTF8 collation or specify explicit column schema in WITH clause and assign UTF8 collation to VARCHAR columns.
原因はわからないですが、自分で扱うファイルは基本的にUTF-8なので気にしないことにしました。(わかる方はコメントで教えてください。)
注意点
ファイルを読み込んだ時にスキーマの自動検出をしてくれます。しかし、リンク先にある通り最初の100行を使って推定をしており、varcharの最大値が足りず文字化けしてしまうことがあります。
そういった場合はwith句で型を明示して読み込むと解消されるため文字化けしたときの対処法として覚えておくといいかもしれないです。
最後に
リソースのクリーンアップをします。
az group delete -n test
参考
[Azure Synapse Analytics の SQL Serverless (SQL on-demand) で 日本語が文字化けした時の対応例]
(https://qiita.com/dahatake/items/3c0486faa901b387106e)
Synapse Studio におけるサーバーレス SQL プールのコスト管理の構成
OPENROWSETスキーマの自動検出
OPENROWSETの構文