いきさつ
Windows10になってメモ帳の既定の文字コードがSJISからUTF-8に変更になりました。
このため、気づかずに業務上SJISであるべきファイルをUTF-8で作ってしまっているファイルが多くでてしまっているのではないかと思い、UTF-8なのかを識別する処理がほしいなと思い、以下の2つの関数を作りました。
SJIS (Shift JIS) ファイルとして解釈可能かを判断するVBS / VBA 関数
UTF-8ファイルとして解釈可能かを判断するVBS / VBA 関数
2つ目の関数では、指定したファイルのデータの並びがUTF-8のルールに則っているかを判断するのですが、そのコードを書いているうちに、さらに一歩進めて、ルールに則っているかを判断するのではなく、いっそ、自分でUTF-8を解読してみたいと思うようになりました。
それが今回作成した関数となります。
読み込んだファイルをUTF-8として解釈して、VBSのUnicode(UTF16-LE)で保持される文字列変数に変換します。
そもそもVBSの文字列の保持が仕組みを理解されてない場合は、この記事の一部は意味不明かもしれないので、以下を先にお読みいただけると幸いです。
VBS,VBAでの文字列データの持ち方 Unicodeからエンディアン,サロゲートペアまで
やること
VBSでは ADODB.Streamを使って、UTF-8のテキスト文書を読み込むことができます。
が、勉強のために敢えてADODB.Streamを使って、UTF-8のテキスト文書をUTF-8テキストとしてではなく、単なるバイナリファイルとして読み込んでから、自力でUTF-8を解読することを試みます。
ADODB.Streamは、そもそもUTF-8のテキストを読み込む機能があるので、ここで作った関数は実用上の意味はなく、非効率な車輪な再発明にすぎませんが、この関数を通して、UTF-8の仕組みとVBSにおけるビット演算が理解できるかと思います。
大前提となる考え方
UTF-8はすべての文字を1バイトから4バイトの可変長のバイトの組み合わせで表すエンコーディングの仕組みです。
各組合せが何バイトなのかは、各組合せの1バイト目で識別できます。
1バイト目が00~7Fであれば、その組み合わせは1バイトで構成されます。
1バイト目がC2~DFであれば、その組み合わせは2バイトで構成されます。
1バイト目がE0~EFであれば、その組み合わせは3バイトで構成されます。
1バイト目がF0~F4であれば、その組み合わせは4バイトで構成されます。
そして、各組合せの2バイト目以降は、80~BFの間のデータのみで構成されます。
各組合せのデータのUnicode文字コードへの復元方法
各組合せのデータのUnicode文字コードへの復元方法を考えます。 1バイト目が00~7Fで、1バイトで構成されるとき そのバイトで示される数値がUnicode文字コードそのもの。 ただし、Unicodeは2バイトで構成されるので、上位バイトには0を設定。 そして、Windowsはリトルエンディアンなので、Unicodeの2バイトの格納にあたって、下位バイト→上位バイトの順に格納します。これは後述するソースのこの部分になります。
OutputBytes(1) = 0
OutputBytes(0) = InputBytes(0)
この2バイトは2進数で表すと、110aaabb 10bbbbbb としてあらわされます。
そして、Unicode文字コードは、00000aaa bbbbbbbb です。
著作権記号 © (U+00A9)でどうなるかを見てみます。
© は UTF-8では C2 A9 となります。 ExcelのHex2Bin関数で2進数をみてみます。
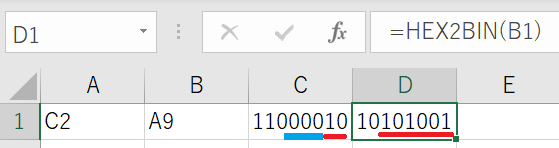
aaa 部分は水色部分で 000 となります。これは16進数で00です。
bbbbbbbb部分は2つの赤色部分をつなげたもので 10 101001 です。
これをExcelのBIN2HEXで16進数でみてみます。
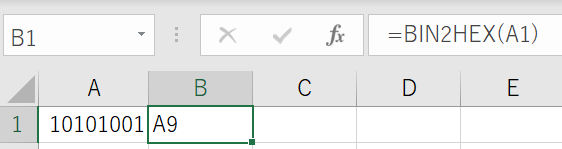
A9となります。したがってaaa bbbbbbbb は 00 A9です。
元のU+00A9 の©が復元されました。
しかし、VBSの文字管理はリトルエンディアンなので 上位バイトと下位バイトが入れ替わり、bbbbbbbb 00000aaa となります。
110aaabb から 00000aaa を作り出すには 110aaabb に 00011100 を And演算することで、000aaa00 を取り出してから、その値を 00000100 で割ることで、右に2ビットずらします。
これはソースのこの部分にあたります。
InputBytes(0) が 110aaabb部分 に相当する1バイト目部分です。
OutputBytes(1) = (InputBytes(0) And b00011100) / b00000100
And演算子は、And の前の数と後ろの数をそれぞれ二進数に変換して、どちらも1になる桁を1にした数を返します。この性質を利用して、後ろの数で1を指定した桁について、前の数から抜き出すということができます。これにより aaa や bb 部分を取り出せます。
たとえば 21 and 14 は 二進数で 10101 and 01110 と書けるので、10101の真ん中3桁を抜き出す形で00100 を取り出すことができます。
VBSでは2進数表現ができないので、予め求めておいた2進数の値をbで始まる変数に代入して2進数表現の代用にしています。
2進数の 00011100 が何の値なのかは ExcelでBin2Hex関数で調べられます。
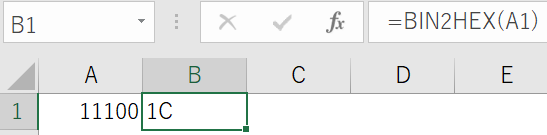
すべて16進数表現は、Integer型ではなくLong型で認識されるように語尾に&をつけています。Integer型で認識されると思いもよらないところで負数認識され面倒だからです。
Const b00011100 = &H1C&
中略
Const b00000100 = &H4&
110aaabb 10bbbbbb から bbbbbbbbを作り出すことは、この応用でさらにトリッキーです。
まず 110aaabb から bbを取り出すために、110aaabb に 00000011 をAnd演算することで、000000bb を取り出してから、01000000倍して、左に6ビットシフトして、bb000000を作ります。それに、10bbbbbb に 00111111 をAnd演算することで取り出した 00bbbbbb を足します。
これはソースのこの部分にあたります。
InputBytes(0) は 110aaabb に相当する1バイト目部分です。
InputBytes(1) は 10bbbbbb に相当する2バイト目部分です。
OutputBytes(0) = (InputBytes(0) And b00000011) * b01000000 + (InputBytes(1) And b00111111)
この3バイトは2進数で表すと、1110aaaa 10aaaabb 10bbbbbb としてあらわされます。
そして、Unicode文字コードは、aaaaaaaa bbbbbbbb です。
しかし、VBSの文字管理はリトルエンディアンなので 上位バイトと下位バイトが入れ替わり、bbbbbbbb aaaaaaaaa となります。
1110aaaa と 10aaaabbから aaaaaaaa を作り出すには 1110aaaa に 00001111 を And演算することで、0000aaaa を取り出してから、その値を 00010000 倍することで左に4ビットずらしてaaaa0000を取得し、そこに、 10aaaabb に 00111100 をAnd演算して得た00aaaa00を00000100で割ることで右に2ビットずらして得た0000aaaaを足します。
これはソースのこの部分にあたります。
InputBytes(0) は 1110aaaa に相当する1バイト目部分です。
InputBytes(1) は 10aaaabb に相当する2バイト目部分です。
OutputBytes(1) = (InputBytes(0) And b00001111) * b00010000 + (InputBytes(1) And b00111100) / b00000100
また、2バイト目からの 10aaaabb 10bbbbbb から bbbbbbbb を作り出すには 10aaaabb に 00000011 を And演算することで、000000bb を取り出してから、その値を01000000 倍することで左に6ビットずらし、その値に、10bbbbbb に 00111111 をAnd演算して取り出した 00bbbbbb を足します。
これはソースのこの部分にあたります。
InputBytes(1) は 10aaaabb に相当する2バイト目部分です。
InputBytes(2) は 10bbbbbb に相当する3バイト目部分です。
OutputBytes(0) = (InputBytes(1) And b00000011) * b01000000 + (InputBytes(2) And b00111111)
これはサロゲートペアと呼ばれるU+10000以上の文字コードです。
ここは複雑怪奇を極めます。
いきなりVBS上のバイトの値を求めることができません。
UTF-8上の4バイトの値は次のような内容になっています。
11110aaa 10aabbbb 10bbbbcc 10cccccc
ここから 000aaaaa bbbbbbbb cccccccc で表せる3バイトを取得し、この3バイトを文字コードとして認識します。
ここまででビット演算については、理解いただいたと思うので、いきなりソース部分を出します。まず000aaaaa bbbbbbbb cccccccc で表せる3バイトを取得する部分です。
Code1が000aaaaa のバイト
Code2がbbbbbbbb のバイト
COde3がcccccccc のバイトとなります。
Code1 = (InputBytes(0) And b00000111) * b00000100 + (InputBytes(1) And b00110000) / b00010000
Code2 = (InputBytes(1) And b00001111) * b00010000 + (InputBytes(2) And b00111100) / b00000100
Code3 = (InputBytes(2) And b00000011) * b01000000 + (InputBytes(3) And b00111111)
次にこの3バイトを文字コードとして認識する部分です。
Code = Code1 * &H10000 + Code2 * &H100& + Code3
これで表現されるCodeはU+10000以上の文字となります。
U+10000以上の文字はVBSのUnicode表現方法であるUTF16-LEでは、2文字のペアとなるサロゲート文字に分解されて表現されます。
分解してできた1文字目は 上位サロゲートと呼ばれ、D800~DBFFの1文字を使います。
分解してできた2文字目は 下位サロゲートと呼ばれ、DC00~DFFFの1文字を使います。
分解の仕方としては、文字コードから &h10000を引いて、サロゲートペア範囲内でのインデックスを求めて、そのインデックスの上位10ビットをD800~DBFFの範囲に割り当てます。さらに、同じそのインデックスの下位10ビットをDC00~DFFFに割り当てます。
コードとしてはこうなります。
IndexInSurrogates = Code - &H10000
'And演算子で、上位10ビットを取得し、2進数の10000000000で割ることで
'右に10ビットシフトします。
'さらにD800を加算することで、D800~DBFFの範囲にずらします。
High = (IndexInSurrogates And b11111111110000000000) _
/ b00000000010000000000 + &HD800&
'And演算子で、下位10ビットを取得し、DC00を加算することで
'DC00~DFFFの範囲にずらします。
Low = (IndexInSurrogates And b00000000001111111111) + &HDC00&
そして、VBSでUnicode管理方法であるUTF16-LEでは、それぞれの文字は リトルエンディアンで下位バイトから格納されるので、 Highの下位バイト→Highの上位バイト→Lowの下位バイト→Lowの上位バイトというバイト値の並びを作る必要があります。
OutputBytes(0) = High And &HFF 'Highの下位バイト
OutputBytes(1) = (High And &HFF00) / &H100 'Highの上位バイト
OutputBytes(2) = Low And &HFF 'Lowの下位バイト
OutputBytes(3) = (Low And &HFF00) / &H100 'Lowの上位バイト
コード全体
ここまで、各処理を抜粋して書いてきました。 コードの全体は次のようになります。Function UTF8ToUTF16(TestFilePath)
UTF8ToUTF16 = ""
'VBS/VBAでは二進数表現が使えません。
'しかし、UTF-8から変換ではビット操作をするので二進数表現でソースを表さないと
'なにをしているのかがよくわかりません。
'そこでbで始まる変数名を使って、疑似的に二進数表現を行います。
'そのための固定値宣言です。
Const b01000000 = &H40&
Const b00111111 = &H3F&
Const b00111100 = &H3C&
Const b00110000 = &H30&
Const b00011100 = &H1C&
Const b00010000 = &H10&
Const b00001111 = &HF&
Const b00000111 = &H7&
Const b00000100 = &H4&
Const b00000011 = &H3&
Const b11111111110000000000 = &HFFC00
Const b00000000001111111111 = &H3FF&
Const b00000000010000000000 = &H400&
'ファイルをバイナリデータとして読み取るために ADODB.Streamを用います。
'ADODB.StreamにはUTF-8を読み取る機能があるので、この関数がやることに
'実用的な意味はありません。
'UTF-8の理解のために、ADODB.Streamで普通にUTF-8を読みとれることを
'あえて、UTF-8ではなく、バイナリデータとして読み取って、自力で解析します。
Const adTypeBinary = 1
Set ADO = CreateObject("ADODB.Stream")
ADO.Type = adTypeBinary
ADO.Open
'バイトデータの並びを文字列型変数に読み取ります。
'読み取ったデータは、配列としてはアクセスできません。
'代わりにMidB を使って取得、代入ができます。
ADO.LoadFromFile TestFilePath
ByteArrayAsString = ADO.Read
ADO.Close
'1バイト目 2バイト目以降
'00..7F なし
'C2..DF 80..BF
'E0..EF 80..BF 80..BF
'F0..F4 80..BF 80..BF 80..BF
Dim InputBytes(3)
Dim OutputBytes(6)
'最初の3バイトがBOMと呼ばれる識別用のマークかを見ておきます。
'最初の3バイトがBOM(EF BB BF)だった場合は、読み飛ばします。
Start = 1
If LenB(ByteArrayAsString) >= 3 Then
If AscB(MidB(ByteArrayAsString,1,1)) = &hEF Then
If AscB(MidB(ByteArrayAsString,2,1)) = &hBB Then
If AscB(MidB(ByteArrayAsString,3,1)) = &hBF Then
Start = 4
End If
End If
End If
End If
'ByteArrayAsStringは文字列型の形式をとっていますが
'中に入っているのはUnicode文字列ではなくByteの並びなので
'その長さは、Lenではなく、LenBで判断します。
For i = Start To LenB(ByteArrayAsString)
'MidBで各バイトにアクセス可能です。 さらにAscBに代入して、数値として扱うことができます。
InputBytes(0) = AscB(MidB(ByteArrayAsString, i, 1))
'1バイト目の値によって、2バイト目以降が何バイトあるかが決まります。
If &H0 <= InputBytes(0) And InputBytes(0) <= &H7F Then
'00..7F 0aaaaaaa
'UTF-8で 0aaaaaaa と表せる文字は
'UTF16では 0aaaaaaa 00000000 です。
'サロゲートペアを除いて、1文字は2バイトで表されるますが、リトルエンディアンのため
'下位バイトaのあとに上位バイト0が配置されます。
OutputBytes(1) = 0
OutputBytes(0) = InputBytes(0)
OutputBytesCount = 2
ElseIf &HC2 <= InputBytes(0) And InputBytes(0) <= &HDF Then
FollowingBytesCount = 1
InputBytes(1) = AscB(MidB(ByteArrayAsString, i + 1, 1))
i = i + FollowingBytesCount
'MsgBox Hex(InputBytes(0)) & " " & Hex(InputBytes(1))
'C2..DF 110aaabb 10bbbbbb
'UTF-8で 110aaabb 10bbbbbb と表せる文字は
'UTF16-LEでは bbbbbbbb 00000aaa です。 リトルエンディアンのため、a,b のバイトが入れ替わります。
'110aaabb 10bbbbbb から 00000aaa を作り出します。 Andで真ん中3bitを取り出し、除算で右に2ビットシフトします。
OutputBytes(1) = (InputBytes(0) And b00011100) / b00000100
'110aaabb 10bbbbbb から bbbbbbbb を作り出します。 Andで右2ビットを取り出し、乗算で左に6ビットシフトし
'それに2バイト目から Andで右6ビットを取り出したものを加算します。
OutputBytes(0) = (InputBytes(0) And b00000011) * b01000000 + (InputBytes(1) And b00111111)
OutputBytesCount = 2
ElseIf &HE0 <= InputBytes(0) And InputBytes(0) <= &HEF Then
FollowingBytesCount = 2
InputBytes(1) = AscB(MidB(ByteArrayAsString, i + 1, 1))
InputBytes(2) = AscB(MidB(ByteArrayAsString, i + 2, 1))
i = i + FollowingBytesCount
'E0..EF 1110aaaa 10aaaabb 10bbbbbb
'UTF-8で 1110aaaa 10aaaabb 10bbbbbb と表せる文字は
'UTF16-LEでは bbbbbbbb aaaaaaa です。 リトルエンディアンのため、a,b のバイトが入れ替わります。
'1110aaaa 10aaaabb から aaaaaaaa を作り出します。
'1バイト目の右4ビットをAndで取り出し、乗算で左に4ビットシフトしたものに
'2バイト目の真ん中4ビットをAndで取り出し、除算で右に2ビットしたものを足します。
OutputBytes(1) = (InputBytes(0) And b00001111) * b00010000 + (InputBytes(1) And b00111100) / b00000100
'1110aaaa 10aaaabb 10bbbbbb から bbbbbbbb を作り出します。
'2バイト目の右2ビットをAndで取り出し、乗算で左に6ビットしたものに
'3バイト目の右6ビットをAndで取り出したものを足します。
OutputBytes(0) = (InputBytes(1) And b00000011) * b01000000 + (InputBytes(2) And b00111111)
OutputBytesCount = 2
ElseIf &HF0 <= InputBytes(0) And InputBytes(0) <= &HF4 Then
FollowingBytesCount = 3
InputBytes(1) = AscB(MidB(ByteArrayAsString, i + 1, 1))
InputBytes(2) = AscB(MidB(ByteArrayAsString, i + 2, 1))
InputBytes(3) = AscB(MidB(ByteArrayAsString, i + 3, 1))
i = i + FollowingBytesCount
'F0..F4 11110aaa 10aabbbb 10bbbbcc 10cccccc
'UTF-8で 11110aaa 10aabbbb 10bbbbcc 10cccccc と表せる文字は
'UTF16では サロゲートペアと呼ばれる特殊な扱いを受けます。
'abcで表される3バイトのUniode値を求め、そこからサロゲートペアを示す4バイトの組み合わせに変換します。
'まずabcを取り出して、順番にビットとして並べて、3バイトのUnicode値を求めます。
Code1 = (InputBytes(0) And b00000111) * b00000100 + (InputBytes(1) And b00110000) / b00010000
Code2 = (InputBytes(1) And b00001111) * b00010000 + (InputBytes(2) And b00111100) / b00000100
Code3 = (InputBytes(2) And b00000011) * b01000000 + (InputBytes(3) And b00111111)
Code = Code1 * &H10000 + Code2 * &H100& + Code3
'&h10000 (=65536)未満のUnicode値はサロゲートペアにしなくても普通に表現されています。
'そこでサロゲートペア内での0始まりの順番としてはUnicode値から&h10000 (65536)を引いたものと
IndexInSurrogates = Code - &H10000
'And演算子で、上位10ビットを取得し、2進数の10000000000で割ることで
'右に10ビットシフトします。
'さらにD800を加算することで、D800~DBFFの範囲にずらします。
High = (IndexInSurrogates And b11111111110000000000) _
/ b00000000010000000000 + &HD800&
'And演算子で、下位10ビットを取得し、DC00を加算することで
'DC00~DFFFの範囲にずらします。
Low = (IndexInSurrogates And b00000000001111111111) + &HDC00&
OutputBytes(3) = (Low And &HFF00) / &H100
OutputBytes(2) = Low And &HFF
OutputBytes(1) = (High And &HFF00) / &H100
OutputBytes(0) = High And &HFF
OutputBytesCount = 4
Else
'UTF-8として解釈可能ではありません。
Exit Function
End If
'ほんとうは1バイトづつ結合するのではなく、パフォーマンスを考慮した
'結合の仕方をすべきですが、学習のため、ややこしいことはしないで、1バイトづつ結合します。
For j = 1 To OutputBytesCount
UTF8ToUTF16 = UTF8ToUTF16 & ChrB(OutputBytes(j-1))
Next
Next
End Function
実験
では、実際にこの関数が正しくUTF-8のファイルを解釈できるかを試してみます。 次のようなVBSのテストコードを書きました。 サロゲートペアでないほぼすべての文字をUTF-8のファイルに書き出して、それを読み取れるかを実験するとともに、サロゲートペアの一部分も同様に実験します。
Main
Sub main()
'&h19までの制御文字を除いた、かつ、サロゲートペアでないすべてのUnicode文字を結合します。
For i = &h20& To &hFFFF&
If &hD800& <= i And i <= &hDBFF& Then
'サロゲートペアの一部です。除外します。
ElseIf &hDC00& <= i And i <= &hDFFF& Then
'サロゲートペアの一部です。除外します。
Else
s1 = s1 & ChrW(i)
End If
Next
'サロゲートペアに属するUnicode文字を
'全部結合するときりがないので、一部抜粋して結合します。
For i = &hD800& To &hDBFF Step &hF
For j = &hDC00 To &hDFFF Step &hF
s1 = s1 & ChrW(i) & Chrw(j)
Next
Next
'これを ADODB.Streamを使って、UTF-8で出力します。
Const adTypeText = 2
Const adSaveCreateOverWrite = 2
Set ADO = CreateObject("ADODB.Stream")
ADO.Type = adTypeText
ADO.Charset = "UTF-8"
ADO.Open
ADO.WriteText s1
ADO.SaveToFile "test.txt", adSaveCreateOverWrite
ADO.Close
'出力したUTF-8ファイルを自力で解析して復号して
'元の文字列と同じかを比較します。
s2 = UTF8ToUTF16("test.txt")
'元の文字列と同じなら Trueを表示し、異なれば、Falseを表示します。
'True/False と共に、復号した文字列も表示します。
MsgBox (s1 = s2) & vbCrLf & s2
End Sub