0. はじめに
NVIDIA/DCGMでUbuntuのGPUリソース使用状況を取得し、Azure Monitorでグラフ化してみました。
1. こんな時に役に立つかも
- AzureのNVIDIA製GPU搭載VMでGPUリソースをモニタリングしたい
- オンプレミスのNVIDIA製GPU搭載サーバでGPUリソースをモニタリングしたい
- GPUリソースをより詳しくモニタリングしたい
Azure Kubernetes Service (AKS) では Container insights が用意されていますが、Azure VMのLinuxにおいてGPUリソースをモニタリングできるメトリックは今のところ提供されていません。
2. NVIDIA/DCGM
Data Center GPU Manager (DCGM) はNVIDIA製GPUを管理運用するツールです。
よく使われる NVIDIA Management Library (NVML) の NVIDIA System Management Interface (nvidia-smi) よりも高度な管理を行うことができ、複数のGPUに対して詳細なメトリックをリアルタイムにモニタリングできます。
3. 環境
| 種類 | バージョン |
|---|---|
| OS | Ubuntu 20.04 LTS |
| GPU | A100 |
| DCGM | 3.3 |
4. 手順の流れ
オンプレミスのGPU搭載サーバで使うなど、ログだけ取得してLog Analyticsワークスペースへ送信したくない場合は、5. 6. 9. 10. の手順のみでOKです。
5. GPU搭載VMにDCGMをインストール
詳しい手順は NVIDIA DCGM Documentation を参照してください。
CUDA keyring パッケージをインストールします。
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
DCGMをインストールします。
sudo apt-get update
sudo apt-get install -y datacenter-gpu-manager
DCGMサービスを有効にし、起動します。
sudo systemctl --now enable nvidia-dcgm
動作確認します。
dcgmi group -l
+-------------------+----------------------------------------------------------+
| GROUPS |
| 2 groups found. |
+===================+==========================================================+
| Groups | |
| -> 0 | |
| -> Group ID | 0 |
| -> Group Name | DCGM_ALL_SUPPORTED_GPUS |
| -> Entities | GPU 0 |
| -> 1 | |
| -> Group ID | 1 |
| -> Group Name | DCGM_ALL_SUPPORTED_NVSWITCHES |
| -> Entities | None |
+-------------------+----------------------------------------------------------+
デフォルトでGroup ID 0にGPUが割り当てられています。DCGMコマンドはGroupに対して実行します。
6. DCGMのメトリックを確認
DCGMで取得できるメトリックは以下のコマンドで確認できます。
dcgmi dmon -l
___________________________________________________________________________________
Long Name Short Name Field Id
___________________________________________________________________________________
driver_version DRVER 1
nvml_version NVVER 2
process_name PRNAM 3
device_count DVCNT 4
cuda_driver_version CDVER 5
name DVNAM 50
brand DVBRN 51
nvml_index NVIDX 52
serial_number SRNUM 53
uuid UUID# 54
minor_number MNNUM 55
oem_inforom_version OEMVR 56
pci_busid PCBID 57
pci_combined_id PCCID 58
pci_subsys_id PCSID 59
etc
多様なメトリックを収集できます。詳細は DCGM Documentation を参照してください。
今回は以下のメトリックを取得することにしました。
| Field ID | メトリック名 | 内容 |
|---|---|---|
| 150 | DCGM_FI_DEV_GPU_TEMP | GPUの温度(℃) |
| 155 | DCGM_FI_DEV_POWER_USAGE | GPUの電力使用量(W) |
| 203 | DCGM_FI_DEV_GPU_UTIL | GPU使用率(0-100) |
| 204 | DCGM_FI_DEV_MEM_COPY_UTIL | GPUメモリ使用率(%) ※read/writeされた時間の割合 |
| 250 | DCGM_FI_DEV_FB_TOTAL | GPUの合計フレームバッファ(MB) |
| 251 | DCGM_FI_DEV_FB_FREE | GPUの空きフレームバッファ(MB) |
| 252 | DCGM_FI_DEV_FB_USED | GPUの使用中フレームバッファ(MB) |
| 253 | DCGM_FI_DEV_FB_RESERVED | GPUの予約済みフレームバッファ(MB) |
| 254 | DCGM_FI_DEV_FB_USED_PERCENT | GPUのフレームバッファの使用率 'USED/(TOTAL-RESERVED)'(0-1) |
| 1004 | DCGM_FI_PROF_PIPE_TENSOR_ACTIVE | テンソルコアがアクティブな割合(0-1) ※ワークロードが高密度の行列演算にどの程度バインドされているか |
| 1006 | DCGM_FI_PROF_PIPE_FP64_ACTIVE | FP64(倍精度)がアクティブな割合(0-1) ※科学的なアプリケーションではFP64計算に偏りやすい |
| 1007 | DCGM_FI_PROF_PIPE_FP32_ACTIVE | FP32(単精度)がアクティブな割合(0-1) |
| 1008 | DCGM_FI_PROF_PIPE_FP16_ACTIVE | FP16(半精度)がアクティブな割合(0-1) ※ML/AIワークロードではFP16に偏りやすい |
ディスク容量やAzureコストが気になる方は 203, 252, 1004 だけでもOKです。
7. Azure Log Analyticsワークスペースを作成
DCGMメトリックを収集するログを蓄積・分析するためのAzure Log Analytics ワークスペースを作成します。
Azure portal にサインインし、ナビゲーションバーでLog Analytics ワークスペースに移動します。
作成をクリックし、新しいLog Analyticsワークスペースを作成します。
サブスクリプション、リソース グループ、ワークスペース名、リージョンを入力し、確認と作成をクリックします。
8. GPU搭載VMに診断拡張機能をインストール
Log Analytics ワークスペースにメトリックを送信するための診断拡張機能をGPU搭載VMにインストールします。
診断拡張機能にはPython 2が必要なため、GPU搭載VMにPython 2をインストールします。
apt-get install -y python2
Azure portal にサインインし、ナビゲーションバーでVirtual Machinesに移動します。
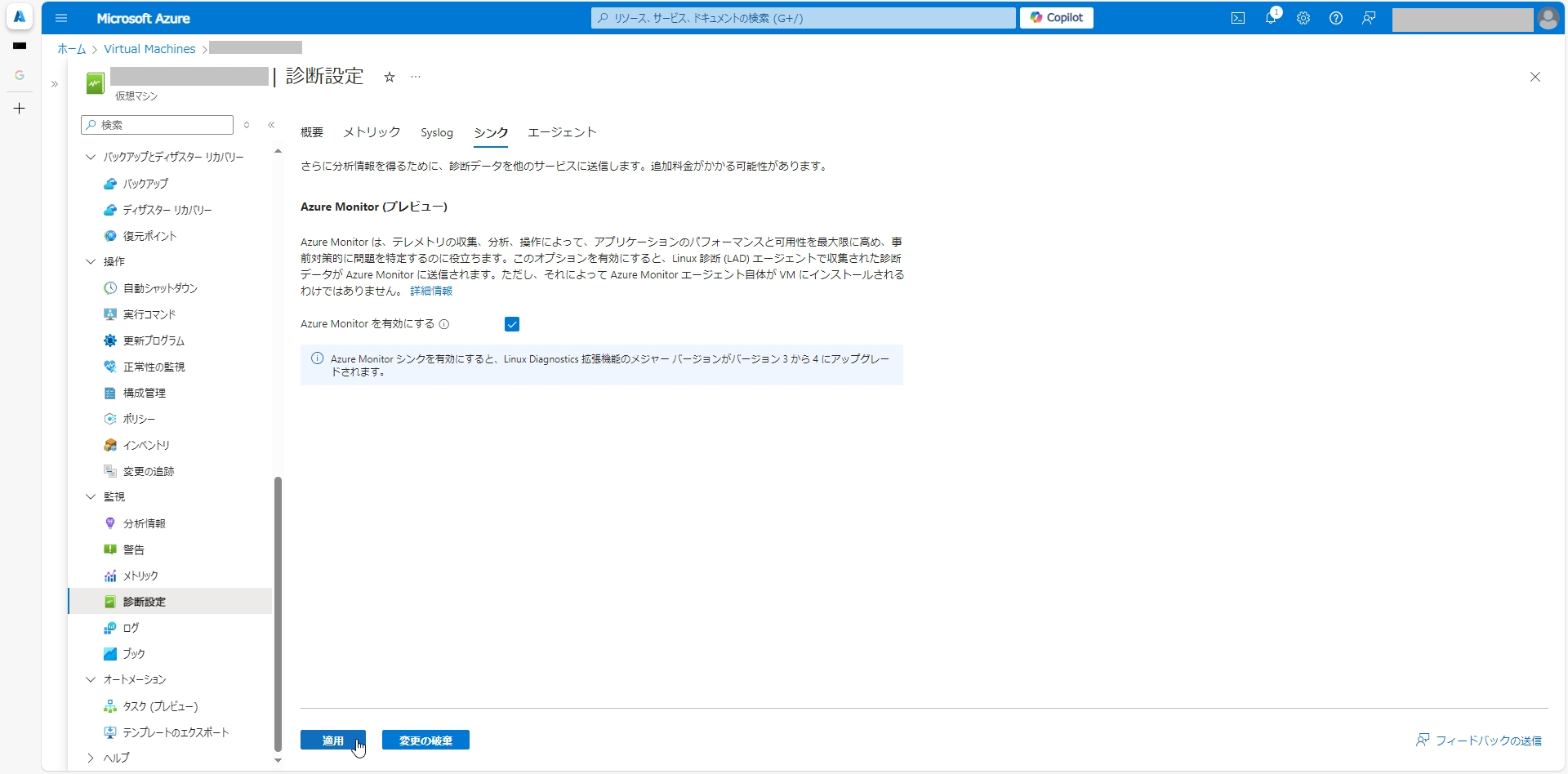
GPU搭載VMを選択し、監視>診断設定をクリックします。
診断拡張機能のインストールで診断ストレージ アカウントを選択し、ゲスト レべルの監視を有効にするをクリックします。

インストールが終わったら、監視>診断設定>シンクを選択し、Azure Monitor を有効にするチェックボックスを有効にして適用をクリックします。
9. GPU搭載VMにhpc_data_collectorを導入
DCGMメトリックをLog Analytics ワークスペースに送信するためのPythonスクリプトをMicrosoftが公開しています。
azurehpc レポジトリから hpc_data_collector を入手し、GPU搭載VM上に配置します。
sudo mkdir /opt/dcgm
# hpc_data_collectorを配置(略)
ls -l /opt/dcgm
-rwxr-xr-x 1 root root 27685 Month DD YY:MM hpc_data_collector.py
Azure portal にサインインし、ナビゲーションバーでLog Analytics ワークスペースに移動します。
ワークスペースを選択し、設定>エージェント>Linux サーバーをクリックして、ワークスペースIDと主キーを確認します。

確認したワークスペースIDと主キーをGPU搭載VMのhpc_data_collector.pyに記入します。
sudo vi /opt/dcgm/hpc_data_collector.py
# 以下の行のコメントアウトを外して記入
LOG_ANALYTICS_CUSTOMER_ID=<ワークスペースID>
LOG_ANALYTICS_SHARED_KEY=<主キー>
hpc_data_collectorの使い方は以下の通りです。
-dfiで取得するメトリックのField ID、-nleでLog Analytics テーブル名(任意)を指定します。
hpc_data_collector.py -h
usage: hpc_data_collector.py [-h] [-dfi DCGM_FIELD_IDS] [-nle NAME_LOG_EVENT]
[-fhm] [-gpum] [-ibm] [-ethm] [-nfsm] [-diskm]
[-dfm] [-cpum] [-cpu_memm] [-eventm] [-uc]
[-tis TIME_INTERVAL_SECONDS]
optional arguments:
-h, --help show this help message and exit
-dfi DCGM_FIELD_IDS, --dcgm_field_ids DCGM_FIELD_IDS
Select the DCGM field ids you would like to monitor
(if multiple field ids are desired then separate by
commas) [string] (default: 203,252,1004)
-nle NAME_LOG_EVENT, --name_log_event NAME_LOG_EVENT
Select a name for the log events you want to monitor
(default: MyGPUMonitor)
-fhm, --force_hpc_monitoring
Forces data to be sent to log analytics WS even if no
SLURM job is running on the node (default: False)
-gpum, --gpu_metrics Collect GPU metrics (default: False)
-ibm, --infiniband_metrics
Collect InfiniBand metrics (default: False)
-ethm, --ethernet_metrics
Collect Ethernet metrics (default: False)
-nfsm, --nfs_metrics Collect NFS client side metrics (default: False)
-diskm, --disk_metrics
Collect disk device metrics (default: False)
-dfm, --df_metrics Collect filesystem (usage and inode) metrics (default: False)
-cpum, --cpu_metrics Collects CPU metrics (e.g. user, sys, idle & iowait
time) (default: False)
-cpu_memm, --cpu_mem_metrics
Collects CPU memory metrics (Default: MemTotal,
MemFree) (default: False)
-eventm, --scheduled_event_metrics
Collects Azure/user scheduled events metrics (default:
False)
-uc, --use_crontab This script will be started by the system contab and
the time interval between each data collection will be
decided by the system crontab (if crontab is selected
then the -tis argument will be ignored). (default:
False)
-tis TIME_INTERVAL_SECONDS, --time_interval_seconds TIME_INTERVAL_SECONDS
The time interval in seconds between each data
collection (This option cannot be used with the -uc
argument) (default: 10)
10. DCGMメトリックをログ取得 + Log Analyticsへ送信
GPU搭載VMにログ取得用のディレクトリを作成します。
sudo mkdir /var/opt/dcgm
crontabにhpc_data_collectorを1分ごとに実行するエントリを追加します。
crontab -e
# 以下の行を追加
* * * * * /usr/bin/python3 /opt/dcgm/hpc_data_collector.py -dfi "150,155,203,204,250,251,252,253,254,1004,1006,1007,1008" -nle "DCGM" -fhm -gpum -ethm -diskm -dfm -cpum -cpu_memm -uc >> /var/opt/dcgm/hpc_data_collector.log 2>&1
取得するメトリック(-dfi)、送信先のLog Analyticsテーブル名(-nle)、GPU搭載VM上で取得するログ名(hpc_data_collector.log)は必要に応じて変更してください。ディスク容量やAzureコストが気になる方は、-dfiを指定しないデフォルトのメトリック(203,252,1004)だけでもOKです。
メトリックを常時取得するのではなく、学習/推論タスクのタイミングに合わせて取得する場合は、-ucオプションではなく-tis 取得間隔(秒)オプションを使用し、cronからではなく直接 hpc_data_collector を実行してください。
オンプレミスのGPU搭載サーバで使うなど、ログだけ取得してLog Analyticsワークスペースへ送信したくない場合は、hpc_data_collector.pyのpost_data()関数を実行する行をコメントアウトしてください。
post_data(customer_id, shared_key, body, name_log_event)
GPU搭載VM上でログを取得する場合は、肥大化してGPU搭載VMのディスクを圧迫しないよう、適宜logrotate等の処理を行ってください。
sudo vi /etc/logrotate.d/hpc_data_collector
/var/opt/dcgm/hpc_data_collector.log {
daily
missingok
rotate 7
compress
delaycompress
notifempty
create 0644 root root
}
11. Azure Monitorでダッシュボードを作成
Log Analytics ワークスペースに収集したログをグラフ化します。
Azure portal にサインインし、ナビゲーションバーでLog Analytics ワークスペースに移動します。
ワークスペースを選択し、ログをクリックします。
プルダウンメニューからKQLモードを選択し、GPU使用率を取得するクエリを入力します。
DCGM_CL
| where hostname_s == "GPU搭載VM名"
| where gpu_id_d in (0, 1, 2, 3) # GPU数に合わせて修正
| summarize avg(gpu_utilization_d) by tostring(toint(gpu_id_d)), bin(TimeGenerated, 1m)
| render areachart with (title="GPU使用率", ytitle="使用率(%)")
実行をクリックするとグラフが表示されます。

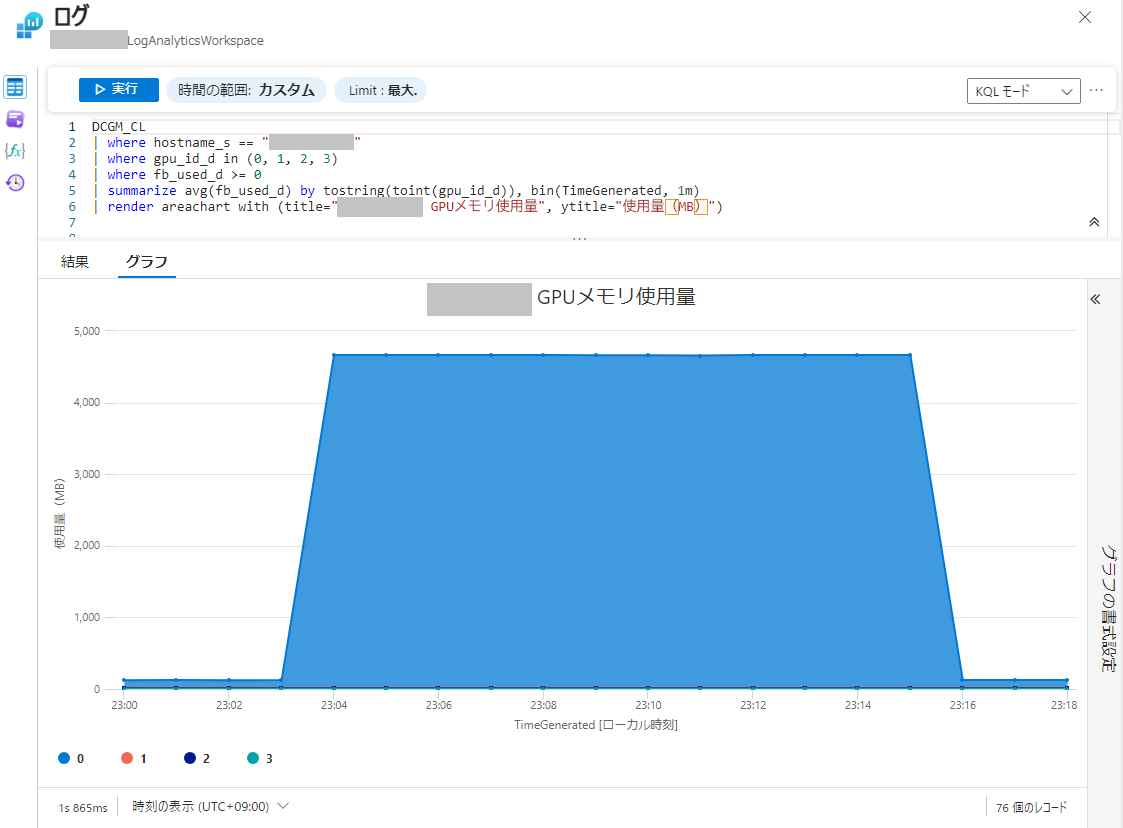
メモリ使用量を取得するクエリは以下です。
DCGM_CL
| where hostname_s == "GPU搭載VM名"
| where gpu_id_d in (0, 1, 2, 3) # GPU数に合わせて修正
| where fb_used_d >= 0
| summarize avg(fb_used_d) by tostring(toint(gpu_id_d)), bin(TimeGenerated, 1m)
| render areachart with (title="GPUメモリ使用量", ytitle="使用量(MB)")
実行をクリックするとグラフが表示されます。
作成したクエリは保存からピン留め先 Azure ダッシュボードを選択して共有ダッシュボード等に貼り付けることができます。

※ 本ブログに記載した内容は個人の見解であり、所属する会社、組織とは全く関係ありません。
※ 2024年10月 現在