概要
GWの間にGCPのサービスを復習します。
まずはBigtable。
なお、動作確認はCloudRunからPython(responder)を使って行っています。
事前準備
- GCPの課金が有効になっていること
- gcloudコマンドが利用可能であること(適宜updateも実行していること)
デフォルトプロジェクトの設定
gcloud config set <プロジェクトID>
ドキュメント
わかりやすい資料
特徴
- ビッグデータ(数テラ〜ペタバイト級)を扱える基盤
- 高スループット、低レイテンシ
- フルマネージド
- KVS(NoSQL)
料金
インスタンス
$0.85/hr per node(本番は最低3ノード)
ストレージ
SSD:$0.22
HDD:$0.034
あとはネットワークの通信料など。
代表的なユースケース
- 機械学習用データ
- 時系列データ
- IoTセンサ値
- 金融取引データ
価格が最低でも20万以上(本番ノード)はすることからもわかる通り、スモールスタートなアプリのストレージとして使うのには向かない。
数テラ〜ペタバイト級のデータを低レイテンシで扱う必要があることがわかっているユースケースに適用する。
アーキテクチャ
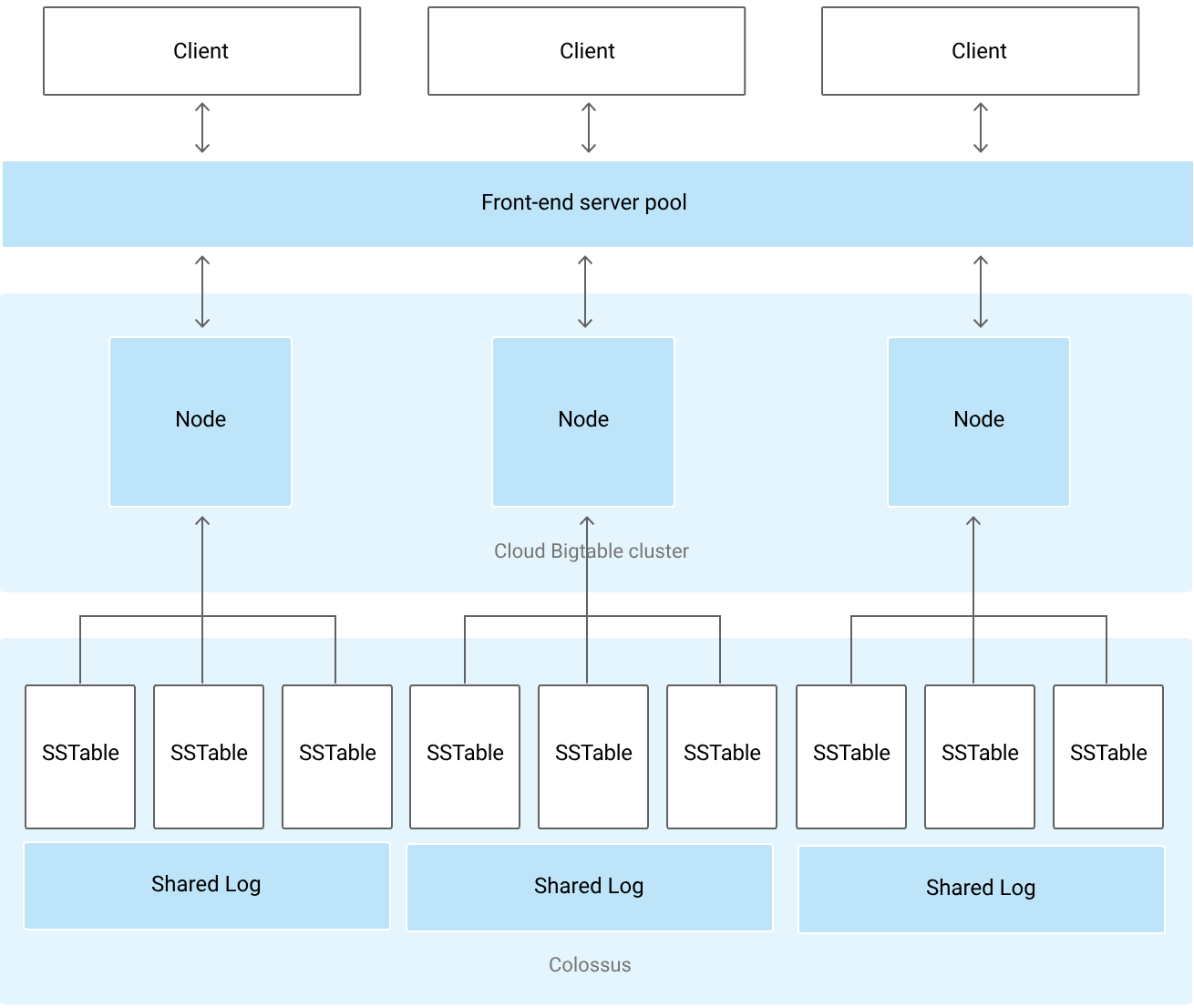
出典:https://cloud.google.com/bigtable/docs/overview?hl=ja#architecture
上記アーキテクチャは1インスタンス1クラスタの図となる。1インスタンス内には最大4つのクラスタを持つことができ、複数クラスタがあるとレプリケーションや、パフォーマンス向上が期待できる。
特徴はデータはcluster上に直接保存されず、ColossusというGoogleのストレージに保存される。Nodeはデータを持たないためスケールや障害時の復旧が高速に行われるメリットがある。
設計ポイント
上記「わかりやすい資料」のリンク先にまとまっている。
インスタンス作成
gcloud bigtable instances create INSTANCE_ID \
--cluster=CLUSTER_ID \
--cluster-zone=CLUSTER_ZONE \
--display-name=DISPLAY_NAME \
[--cluster-num-nodes=CLUSTER_NUM_NODES] \
[--cluster-storage-type=CLUSTER_STORAGE_TYPE] \
[--instance-type=INSTANCE_TYPE]
まずはクラスタを作成する。
インスタンスID(任意)、クラスタID(任意)、配置ゾーン、表示名を必須で指定する。
また、ストレージタイプ、インスタンスタイプ、ノード数を任意で指定する。
--cluster-storage-type={SSD|HDD} default:SSD
--instance-type={PRODUCTION|DEVELOPMENT} default:PRODUCTION
--cluster-num-nodesはPRODUCTIONでは3以上 DEVELOPMENTでは指定不可
クラスタの追加(本番環境のみ)
gcloud beta bigtable clusters create CLUSTER_ID \
--instance=INSTANCE_ID \
--zone=ZONE \
[--num-nodes=NUM_NODES] \
[--storage-type=STORAGE_TYPE]
pythonからの呼び出し
インポート
from google.cloud import bigtable
from google.cloud.bigtable import column_family
from google.cloud.bigtable import row_filters
インスタンスのオブジェクト取得
client = bigtable.Client(project='<プロジェクトID>', admin=True)
instance = client.instance('iot-sample')
テーブル作成
table = instance.table(table_id)
print('Creating column family cf1 with Max Version GC rule...')
column_family_id = 'cf1'
max_versions_rule = column_family.MaxVersionsGCRule(2)
column_families = {column_family_id: max_versions_rule}
if not table.exists():
table.create(column_families=column_families)
else:
print("Table {} already exists.".format(table_id))
テーブルID(テーブル名)とカラムファミリを指定してテーブルを作成する。
※カラムファミリは検索時に特定のカラム群だけを取り出せるようにするグルーピングのID。
insert
key='key1'
data='data1'
key_column = 'primary_key'.encode()
table = instance.table(table_id)
rows = []
row =table.row(key.encode())
column_family_id = 'cf1'
row.set_cell(column_family_id,
key_column,
data,
timestamp=datetime.datetime.utcnow())
rows.append(row)
table.mutate_rows(rows)
tableのrowメソッドにキーとする値(byteエンコードする)を指定することでrowオブジェクトを取得する。
rowオブジェクトにセルの情報をセットして、mutate_rowsで更新をかける。
データ取得
key='key1'
table = instance.table(table_id)
key = key.encode()
column_family_id = 'cf1'
row_filter = row_filters.CellsColumnLimitFilter(1)
row = table.read_row(key, row_filter)
cell = row.cells[column_family_id][key_column][0]
data = cell.value.decode('utf-8')
最後に
動作確認が終わったら、速やかにインスタンスを削除する。
放置していたらビビるほどお金が飛ぶ。