やりたいこと
あるハッシュタグがこれまでどのように使われてきたのかを分析したい。そのために特定のハッシュタグが含まれた投稿を一斉に取得することが必要。
手作業でやったら死ぬので、APIでできないか模索中。
注記
この記事はまだ書きかけです。
手順
- APIを使えるようになる
- APIで投稿を取得できるようになる
- テキストマイニングをかけられるデータにする
APIの仕様を見る
APIの仕様書を見ると投稿別のデータを取得するエンドポイントが用意されているっぽい。IGAPI仕様書
GET https://graph.instagram.com/{ig-hashtag-id}
?fields={fields}
&access_token={access-token}
こんな感じでGETリクエストすればJsonで返ってくるらしい。
方針
つまるところ表データにして取りたいのでGASで書くことにする。
コード書く
【GAS】Instagram Graph APIを利用して投稿毎のいいね数を取得する
似たようなことしている人が居たので、参考にしてコードを書いたのが以下。ほぼコピペなので、引用元を参照してほしい。
function myFunction() {
var instragramID = '【インスタグラムビジネスID】';
var ACCESS_TOKEN = "【アクセストークン】";
var num = 50; // 取得件数
var facebook_url = "https://graph.facebook.com/【ハッシュタグID】/top_media?user_id=" + instragramID + "&access_token=" + ACCESS_TOKEN + "&fields=id,media_type,media_url,permalink,like_count,comments_count,caption,timestamp,children{id,media_url}&limit=50";
var encodedURI = encodeURI(facebook_url);
var response = UrlFetchApp.fetch(encodedURI);
var jsonData = JSON.parse(response);
console.log(jsonData);
// スプレットシート読み込み
var ss = SpreadsheetApp.getActiveSpreadsheet();
var sheet = ss.getSheetByName('投稿別');
var sheet_row = 2; // スプレットシートの開始行(2行目から)
console.log(jsonData['data'][1]);
// 取得したデータの分だけくり返し
//ここではnumと同一にしている
for(var i=1; i<50; i++){
var timestamp = jsonData['data'][i].caption; // 投稿日時
var caption = jsonData['data'][i].caption; // caption
var like_count = jsonData['data'][i].like_count; // いいね数
var media_type = jsonData['data'][i].media_type; // メディア種別
var permalink = jsonData['data'][i].permalink; // リンク
sheet.getRange(sheet_row,1).setValue(Utilities.formatDate(new Date(timestamp), 'Asia/Tokyo','yyyy/MM/dd HH:mm:ss'));
sheet.getRange(sheet_row,1).setValue(caption);
sheet.getRange(sheet_row,2).setValue(like_count);
sheet.getRange(sheet_row,3).setValue(media_type);
sheet.getRange(sheet_row,4).setValue(permalink);
sheet_row++;
console.log(i);
}
}
出力結果
試しにハッシュタグ「エモみ」で出力をしてみる。
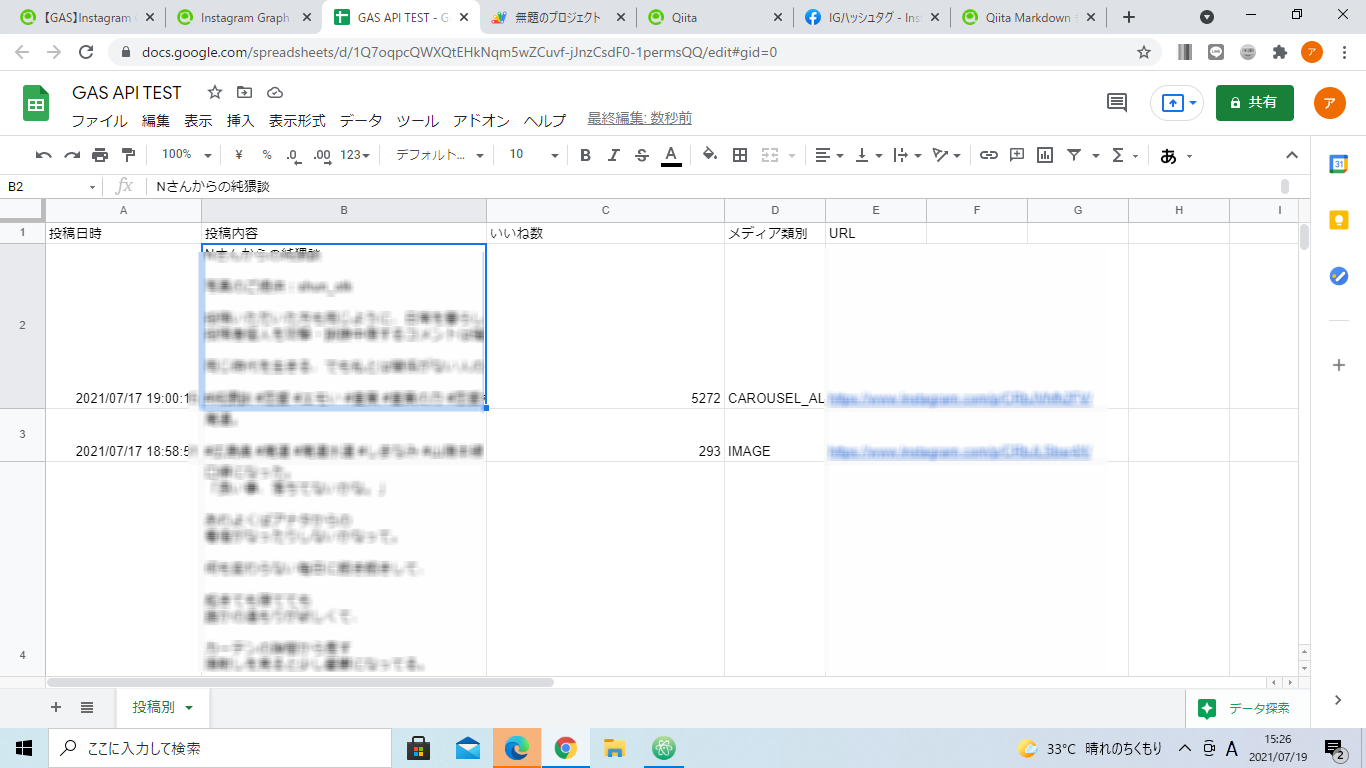
「#エモみ」が含まれた投稿を50件取得できた。ハッシュタグの内容は【ハッシュタグID】の中身を変えたらできる!
これをテキストマイニングにかけてみる
本来ならKHコーダーとかできちんとやるべきだろうが、めんどいので適当なやつにかけてみる。
つかったのはユーザーローカルのテキストマイニング↓ たまに使うけど、ほんとに便利。
ユーザーローカルAIテキストマイニング
分析結果
下記は「エモみ」のハッシュタグで投稿結果を50件取得し、それらをテキストマイニングにかけた結果!
ワードクラウド

※引用元ワードクラウド結果
「熱海」とか「時間旅行」とか、字面からしてエモみが深くてウケる。時間旅行ってなんだ?ってことはあるけど。
あと「繋がる」もなんかエモみがある。
頻出語
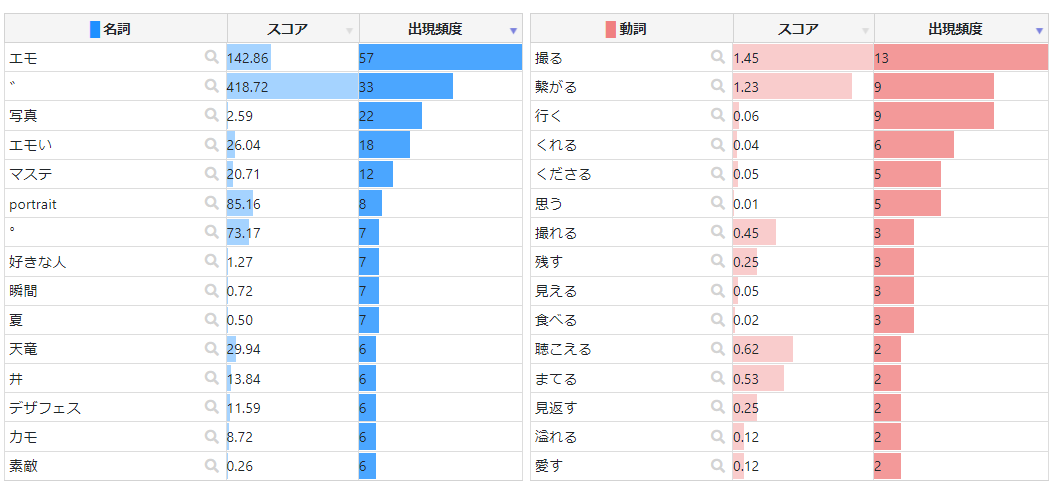
※引用元ワードクラウド結果
動詞の再頻出語の2番目が「繋がる」なのなんかエモい。
共起
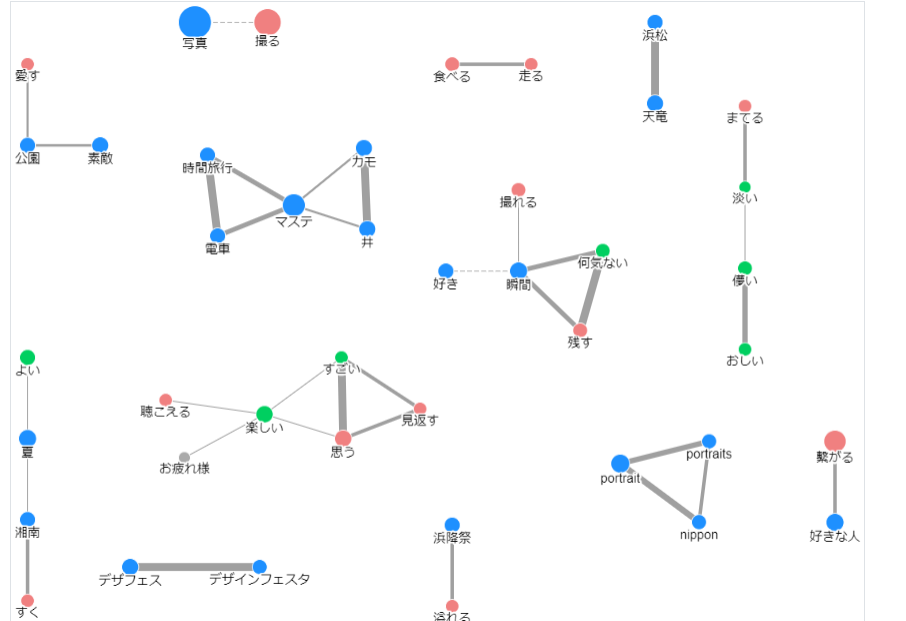
※引用元ワードクラウド結果
「写真」と「撮る」が共起しているのは分かる。「好きな人」と「繋がる」が一緒なのはマジでエモい。「夏」と「湘南」が共起しているのもなんか分かる。「すく」ってなんだろう?
最後に
最後に問題点を色々列挙しておく。
問題点①
InstaのAPIに制限がデカすぎるのと、時間で取れないのが難点。つまり、つまり〇年前のこの時期の投稿で取るというのが出来ないっぽい。リファレンスざっとみた感じではできなかったけど、もしかしたらできるかも。
問題点②
問題①に起因するけど、時間ごとに取れないので継時的な分析がかけづらい。そうすると微妙な気がする。
やれそうなこと①
マイニングするときに「いいね」されてない群と「いいね」されてる群でやったら面白そう笑
やれそうなこと②
そもそもの趣旨だけど時系列的な変化を追えたら普通に面白いはず
教えてくださいポイント
APIのリファレンスにこんな感じで書いてあった。
ようするに50件以上をリクエストしたら、51件からpagenationされますよということらしい。めんどい。paginationされたURLをfetchしてもう一回Jsonを読み込むコード書けばかなりの数を取得できるっぽい。多分普通にできるけど、書くのがめんどいので、書いた人いたらください。
制限
応答は、ページあたりの結果が最大50件のlimitでページネーションされます。
20211010 コード修正
ページネーション処理書いたので、一度に800件くらい取得できる。それ以上はGASのタイムアウト食らう。
function myFunction() {
//ID渡す処理
var instragramID = '【ID】';
var ACCESS_TOKEN = "【トークン】";
//APIのエンドポイントにパラメータ渡す
var num = 50; // 取得件数
var facebook_url = "https://graph.facebook.com/17843524651051981/top_media?user_id=" + instragramID + "&access_token=" + ACCESS_TOKEN + "&fields=id,media_type,media_url,permalink,like_count,comments_count,caption,timestamp,children{id,media_url}&limit=50";//top_mediaというエンドポイント使ってる
//フェッチしてJSON形式にパース
var encodedURI = encodeURI(facebook_url);
var response = UrlFetchApp.fetch(encodedURI);
var jsonData = JSON.parse(response);
// スプレットシート読み込み
var ss = SpreadsheetApp.getActiveSpreadsheet();
var sheet = ss.getSheetByName('シート1');
//for文ここから
for (let step = 0; step < 100; step++) {
if(step==0){
//最初のGETがJSONで返るのでパース
var encodedURI = encodeURI(facebook_url);
var response = UrlFetchApp.fetch(encodedURI);
var jsonData = JSON.parse(response);
const AValues = sheet.getRange('A:A').getValues(); //A列の値取得
var sheet_row = AValues.filter(String).length; //空白の要素を除いた長さを取得
sheet_row++;
//書き込みのためのfor文-array
for(var i=1; i<49; i++){
var timestamp = jsonData['data'][i].timestamp; // 投稿日時
var caption = jsonData['data'][i].caption; // caption
var like_count = jsonData['data'][i].like_count; // いいね数
var media_type = jsonData['data'][i].media_type; // メディア種別
var permalink = jsonData['data'][i].permalink; // リンク
var id = jsonData['data'][i].id; // ID
var comments_count = jsonData['data'][i].comments_count; // コメント数
//重複のスキップ処理
var search_range = sheet.getRange('F:F').getValues();//F列(=ID列)を全て取得
var src_flat = search_range.flat();//取得した範囲を二次元配列に変換
if(src_flat.includes(id)===true) {
//既に重複するIDがあった場合の処理。ここではなにもしない=スキップのためなにも入れない
}
else {
//重複するIDが無ければ書き込み
sheet.getRange(sheet_row,1).setValue(Utilities.formatDate(new Date(timestamp), 'Asia/Tokyo','yyyy/MM/dd HH:mm:ss'));
sheet.getRange(sheet_row,2).setValue(caption);
sheet.getRange(sheet_row,3).setValue(like_count);
sheet.getRange(sheet_row,4).setValue(media_type);
sheet.getRange(sheet_row,5).setValue(permalink);
sheet.getRange(sheet_row,6).setValue(id);
sheet.getRange(sheet_row,7).setValue(comments_count);
sheet_row++;
console.log(i);
}
}
}else if(step==1){
//ページネーション処理
var encodedURI = encodeURI(facebook_url);
var response = UrlFetchApp.fetch(encodedURI);
var jsonData = JSON.parse(response);
var paginationQuery = jsonData['paging']['next'];
console.log("これページネーションクエリ"+paginationQuery);
//2回目以降のGETがJSONで返るのでパース
var responsePaging = UrlFetchApp.fetch(paginationQuery);
var PaginationData = JSON.parse(responsePaging);
console.log("これページネーションデータ"+PaginationData);
const AValues = sheet.getRange('A:A').getValues(); //A列の値取得
var sheet_row = AValues.filter(String).length; //空白の要素を除いた長さを取得
sheet_row++;
//書き込みのためのfor文-arrayPagination
for(var i=1; i<49; i++){
var timestamp = PaginationData['data'][i].timestamp; // 投稿日時
var caption = PaginationData['data'][i].caption; // caption
var like_count = PaginationData['data'][i].like_count; // いいね数
var media_type = PaginationData['data'][i].media_type; // メディア種別
var permalink = PaginationData['data'][i].permalink; // リンク
var id = PaginationData['data'][i].id; // ID
var comments_count = PaginationData['data'][i].comments_count; // コメント数
//重複のスキップ処理
var search_range = sheet.getRange('F:F').getValues();//F列(=ID列)を全て取得
var src_flat = search_range.flat();//取得した範囲を二次元配列に変換
if(src_flat.includes(id)===true) {
//既に重複するIDがあった場合の処理。ここではなにもしない=スキップのためなにも入れない
}
else {
//重複するIDが無ければ書き込み
sheet.getRange(sheet_row,1).setValue(Utilities.formatDate(new Date(timestamp), 'Asia/Tokyo','yyyy/MM/dd HH:mm:ss'));
sheet.getRange(sheet_row,2).setValue(caption);
sheet.getRange(sheet_row,3).setValue(like_count);
sheet.getRange(sheet_row,4).setValue(media_type);
sheet.getRange(sheet_row,5).setValue(permalink);
sheet.getRange(sheet_row,6).setValue(id);
sheet.getRange(sheet_row,7).setValue(comments_count);
sheet_row++;
console.log(i);
}
}
}
else{
//3回目以降のGETがJSONで返るのでパース
var paginationQuery = PaginationData['paging']['next'];
//3回目以降のGETがJSONで返るのでパース
var responsePaging = UrlFetchApp.fetch(paginationQuery);
var PaginationData = JSON.parse(responsePaging);
var responsePaging = UrlFetchApp.fetch(paginationQuery);
var PaginationData = JSON.parse(responsePaging);
const AValues = sheet.getRange('A:A').getValues(); //A列の値取得
var sheet_row = AValues.filter(String).length; //空白の要素を除いた長さを取得
sheet_row++;
//書き込みのためのfor文-arrayPagination
for(var i=1; i<49; i++){
var timestamp = PaginationData['data'][i].timestamp; // 投稿日時
var caption = PaginationData['data'][i].caption; // caption
var like_count = PaginationData['data'][i].like_count; // いいね数
var media_type = PaginationData['data'][i].media_type; // メディア種別
var permalink = PaginationData['data'][i].permalink; // リンク
var id = PaginationData['data'][i].id; // ID
var comments_count = PaginationData['data'][i].comments_count; // コメント数
//重複のスキップ処理
var search_range = sheet.getRange('F:F').getValues();//F列(=ID列)を全て取得
var src_flat = search_range.flat();//取得した範囲を二次元配列に変換
if(src_flat.includes(id)===true) {
//既に重複するIDがあった場合の処理。ここではなにもしない=スキップのためなにも入れない
}
else {
//重複するIDが無ければ書き込み
sheet.getRange(sheet_row,1).setValue(Utilities.formatDate(new Date(timestamp), 'Asia/Tokyo','yyyy/MM/dd HH:mm:ss'));
sheet.getRange(sheet_row,2).setValue(caption);
sheet.getRange(sheet_row,3).setValue(like_count);
sheet.getRange(sheet_row,4).setValue(media_type);
sheet.getRange(sheet_row,5).setValue(permalink);
sheet.getRange(sheet_row,6).setValue(id);
sheet.getRange(sheet_row,7).setValue(comments_count);
sheet_row++;
console.log(i);
}
//最初のGETとそれ以降のGETを分岐させるif文ここまで
}
}
}
}
↑のコードで重複なし、タイムアウトするまでページングしてくれる。