PythonのKerasのLSTMでコロナの新規感染者予測
概要
シグネート様のコンペ「Covid 19 Challenge」のPhase-3「国内全体の累積罹患者数予測」を基に予測する。
※コンペ自体は終了している。
環境
Windows10
Python3.7
Kerasについて
Kerasは、Pythonで書かれたオープンソースのニューラルネットワークである。
MXNet、Deeplearning4j、TensorFlow、CNTK、Theanoの上部で動作することができる。
ディープニューラルネットワークを用いた迅速な実験を可能にするよう設計され、最小限、モジュール式、拡張可能であることに重点が置かれている。
※Wikipediaより引用
LSTMについて
長・短期記憶(ちょう・たんききおく、英: Long short-term memory、略称: LSTM)は、深層学習(ディープラーニング)の分野において用いられる人工回帰型ニューラルネットワーク(RNN)アーキテクチャである。
一般的なLSTMユニットは、セル、入力ゲート、出力ゲート、および忘却ゲートから構成される。セルは任意の時間間隔にわたって値を記憶し、3つの「ゲート」はセルを出入りする情報の流れを制御する。
LSTMネットワークは時系列データに基づく分類、処理(英語版)、予測によく適している。
※Wikipediaより引用
詳細については下記サイトがわかりやすい
RNNとLSTM(Long Short Term Memory)の違いと特徴
入力データの準備
シグネート様に新規感染者のデータがあるのでそれを使用する。
2020/1/16~2021/2/23までの各都道府県の新規感染者数を入力データとして、約一か月間(2021/2/1~2021/2/23)の全国の新規感染者数を予測する。
47都道府県の新規感染者数と曜日データを入力として使用する。
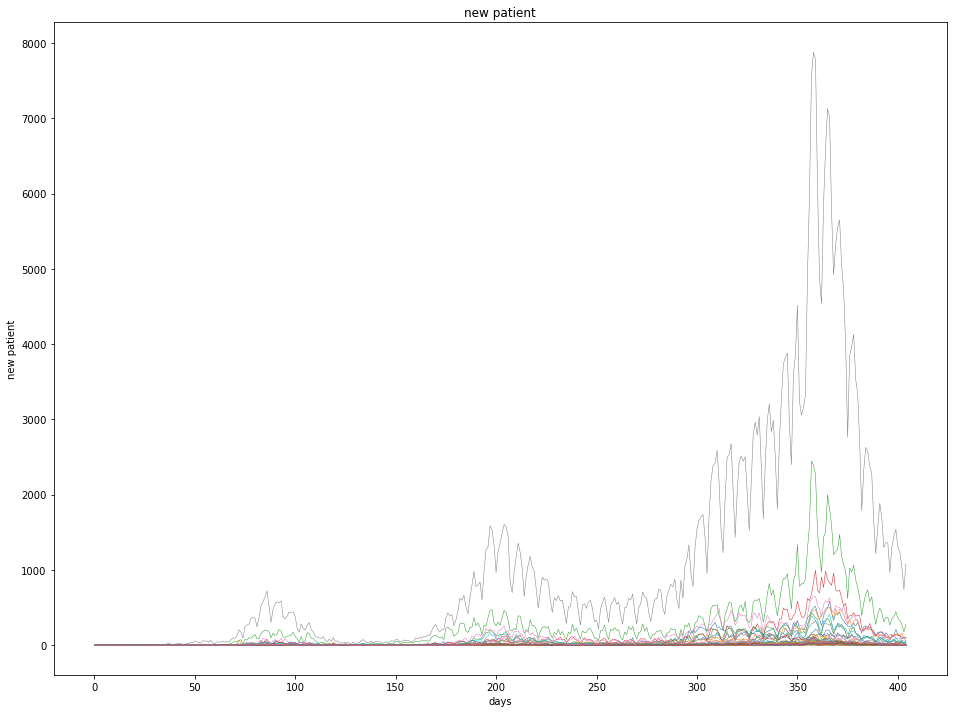
各都道府県のコロナ新規感染者
検査数の問題で新規感染者は、月曜日が極端に低くなり、木曜日が多くなる。
曜日データとして月曜日フラグと木曜日フラグを入力として使用する。
※検査数を入力として使用したかったが、各都道府県の検査数が見当たらなかった。。。
実装
TensorFlowを用いて開発を行う。
記事作成用に要点だけ記載している。
患者データの取り込み
def read_csv():
df = pd.read_csv('SIGNATE COVID-19 Case Dataset.csv')
date = pd.to_datetime(df['日付'][1:], format='%Y-%m-%d')
date_isoweekday = date.dt.dayofweek
week_flag = -1 * (date_isoweekday[:] == 0).astype(int) + (date_isoweekday[:] == 3).astype(int)
patient = df.drop('日付', axis=1).drop('日本国内累計罹患者数', axis=1)
columns = patient.columns
patient = patient.values[1:, :]
df = pd.DataFrame(data=patient, index=date, columns=columns, dtype='int')
return df, week_flag, date
入力データの作成
def create_patient_data(prefecture_list, df, week_flag):
patient_list = []
# 標準化スケーラ
ss = preprocessing.StandardScaler()
if len(prefecture_list) == 0:
prefecture_list = df.drop('日本国内新規罹患者数', axis=1).columns
for p in prefecture_list:
patient = df[[p]].values
# 標準化
patient = ss.fit_transform(patient)
patient_list.append(patient)
return np.array(patient_list), week_flag[:].values.reshape([week_flag[:].shape[0], 1])
モデル入力データの作成
目的変数:予測したい新規感染者数のデータ
説明変数:予測したい新規感染者から前14日分のデータ
def create_data(patient_list, use_days, week_flag):
x_data = []
y_data = []
for p in patient_list[:]:
new_patient = np.concatenate([p[:, ], week_flag], 1)
for i in range(use_days, new_patient.shape[0]):
x_data.append(new_patient[i-use_days:i, :])
y_data.append(new_patient[i, 0])
x_data = np.array(x_data)
y_data = np.array(y_data)
return x_data, y_data, patient_list
モデルの作成
LSTMのモデルの作成
モデルの入力としてuse_days分のデータを使用する。
use_daysは、コロナの潜伏期間である14日を採用している。
def create_model(use_days):
model = Sequential()
model.add(LSTM(32, input_shape=(use_days, 2)))
model.add(Dense(1, activation='linear'))
model.compile(loss='mean_squared_error', optimizer='adam')
return model
メイン処理
import pandas as pd
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, LSTM, Dropout, TimeDistributed
from sklearn import preprocessing
from tensorflow.keras.callbacks import EarlyStopping
import datetime
# csvの読み込み
df, week_flag, date = read_csv()
use_days = 14
# 予測を開始する日付
base_date = '2021-02-01 00:00:00'
base_date_index = date.loc[date == base_date].index[0]
future_use_days = df.values.shape[0] - base_date_index
# 訓練データ作成
training_prefecture_list = []
train_patient_list, train_week_flag = create_patient_data(training_prefecture_list)
train_x_data, train_y_data, train_origin_data = create_data(train_patient_list, use_days, train_week_flag)
# テストデータ作成
test_prefecture_list = ['日本国内新規罹患者数']
test_patient_list, test_week_flag = create_patient_data(test_prefecture_list)
test_x_data, test_y_data, test_origin_data = create_data(test_patient_list, use_days, test_week_flag)
test_x_data = test_x_data[:base_date_index-use_days]
test_y_data = test_y_data[:base_date_index-use_days]
# モデルの作成
model = create_model(use_days)
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=0, mode='auto')
# 学習
model.fit(train_x_data, train_y_data, epochs=30, verbose=2, validation_split=0.1, callbacks=[early_stopping])
# テストデータを用いて予測
pred = []
for x in test_x_data[:]:
x_test = x.reshape(1, x.shape[0], x.shape[1])
prediction = model.predict(x_test)
pred.append(prediction[0, :])
# 未来日のデータの曜日フラグを用意しておく
pred_week_flag = list(test_week_flag[use_days:])
use_pred = [np.array(pred[i]) for i in range(len(pred))]
last_date = pd.to_datetime(date.values[-1])
future_date = [(last_date + datetime.timedelta(days=i)) for i in range(1, future_use_days + 1)]
future_date_isoweek = np.array([future_date[i].dayofweek for i in range(len(future_date))])
future_week_flag = -1 * (future_date_isoweek[:] == 0).astype(int) + (future_date_isoweek[:] == 3).astype(int)
# 未来日の予測
count = 0
while(1) :
if count == future_use_days: break
v = use_pred[-use_days:]
mf = pred_week_flag[-use_days:]
x = np.array([v, mf]).T
prediction = model.predict(x)
use_pred.append(prediction[0, :])
pred_week_flag.append([future_week_flag[count]])
count += 1
まとめ
東京の新規感染者数を予測した。
緊急事態宣言後の下がり幅の大きさを予測できていないが、グラフの上がり下がりは割と捉えられて良い結果といえる。
入力として検査数、祝日や緊急事態宣言の期間等を持たせてみてもいいかも
モデルとしてもかなりシンプルなものになっているので改善の余地がかなりあり。。。
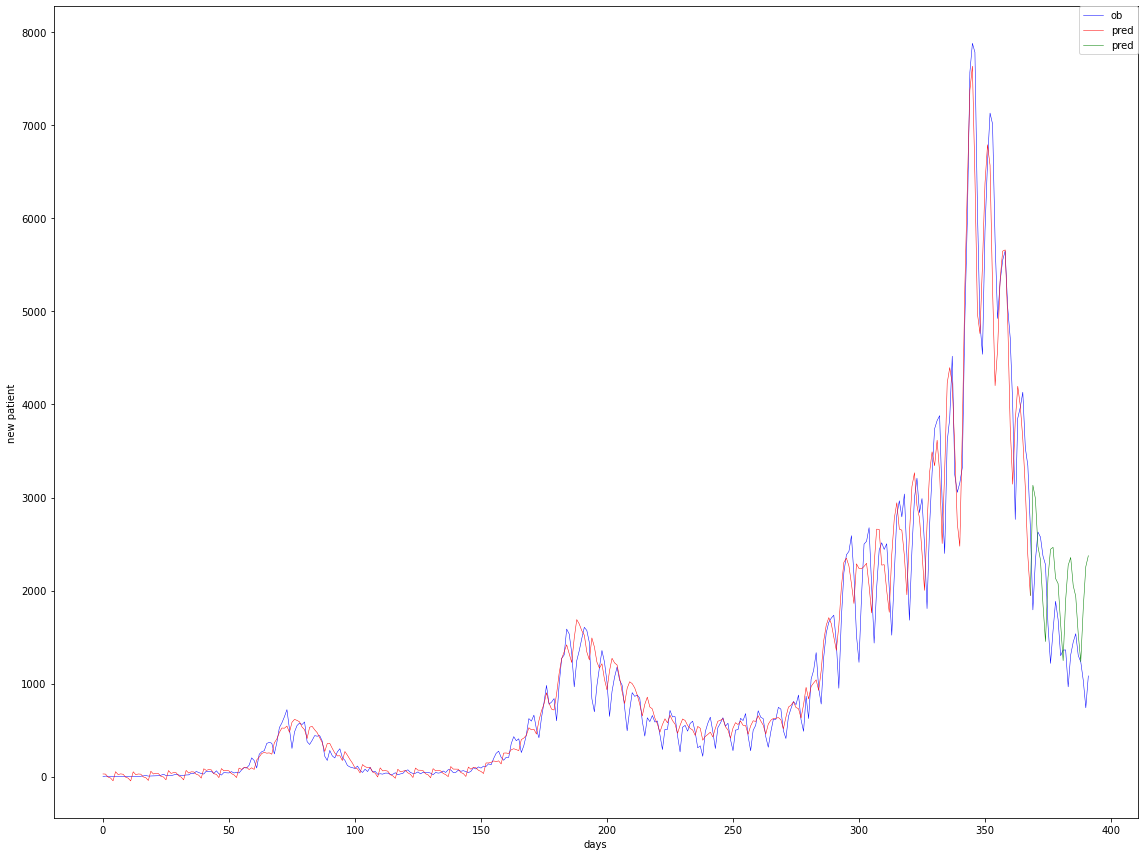
青:観測値
赤:観測値(青)を入力として予測した値
緑:予測値(赤)を入力として予測した値