はじめに
2種類の時間帯のリストがあった場合に、それらの共通部分だけを抽出する方法を紹介する。使いどころは、例えば、2つの装置が同時にONとなっている時間帯だけを計算したい場合 (同時計測の時間帯)など。天体解析の世界における、heasoft の mgtime というツールを用いた GTI(Good Time Interval)をマージするような処理に相当します。
この記事の一式は下記の google colab からも確認できます。
簡単なプログラムの例
簡単な例として、
start1 = [0, 10, 21.5, 30]
stop1 = [5, 20, 22.5, 40]
start2 = [-1, 3, 18, 22.4]
stop2 = [0.5, 7, 22, 22.6]
という時間帯との AND を取ると、
[0, 3, 18, 21.5, 22.4]
[0.5, 5, 20, 22, 22.5]
となる場合の例を示します。
まずは、一番簡単な方法を紹介します。
def intersecting_range(start1, stop1, start2_list, stop2_list):
result_start = []
result_stop = []
for start2, stop2 in zip(start2_list, stop2_list):
s = max(start1, start2)
e = min(stop1, stop2)
# 交差する範囲が存在する場合、リストに追加
if s < e:
result_start.append(s)
result_stop.append(e)
return result_start, result_stop
start1 = [0, 10, 21.5, 30]
stop1 = [5, 20, 22.5, 100]
start2 = [-1, 3, 18, 22.4]
stop2 = [0.5, 7, 22, 22.6]
start3 = []
stop3 = []
# start1, stop1 の各範囲に対して交差する範囲を見つける
for s1, e1 in zip(start1, stop1):
s, e = intersecting_range(s1, e1, start2, stop2)
start3.extend(s)
stop3.extend(e)
print(start3) # [0, 3, 18, 21.5, 22.4, 50]
print(stop3) # [0.5, 5, 20, 22, 22.5, 60]
答えを図示すると、
F = plt.figure(figsize=(12,6))
ax = plt.subplot(1,1,1)
for x1, x2 in zip(start1, stop1):
plt.hlines(y=3, xmin=x1, xmax=x2, lw=80, color = "red")
for x1, x2 in zip(start2, stop2):
plt.hlines(y=2, xmin=x1, xmax=x2, lw=80, color = "green")
for x1, x2 in zip(start3, stop3):
plt.hlines(y=1, xmin=x1, xmax=x2, lw=80, color = "blue")
plt.grid(alpha=0.7)
plt.show()
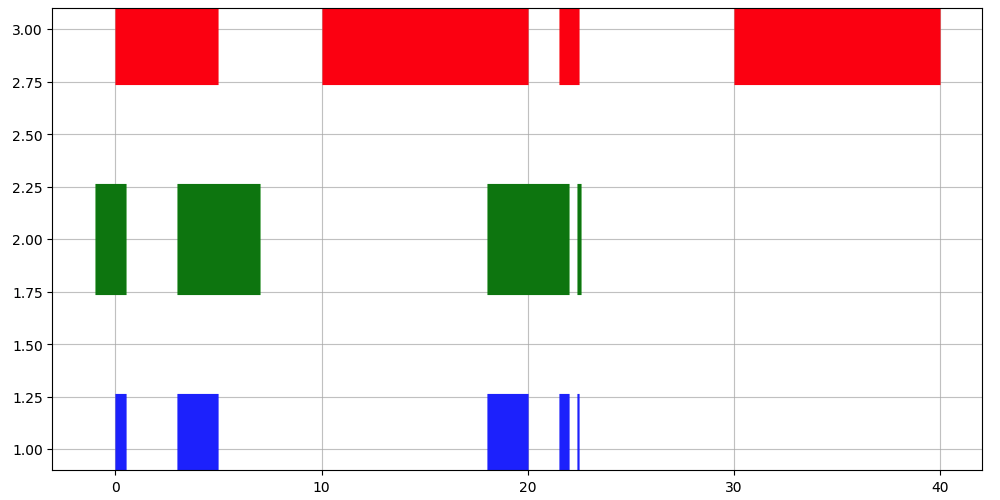
のように、赤と緑の共通分が青になっています。
このやり方は、それぞれのリストに対して、for loop を回すので、配列の長さが長いと、計算量が多くなります。
高速化したプログラムの例
時間帯リストを1回だけスキャンするだけで範囲の交差を正確に識別できれば高速化が実現できます。効率的に範囲の交差を見つけるために、時間帯リストをソートしておきます。
ここでは、スキャンを一度だけ行い、交差する範囲を見つける方法を紹介します。
- python の set型変数の inside1 および inside2 のセットを使用して、現在のイベント位置でどの範囲が有効かを追跡します。
- 交差の開始を識別するため、inside1 と inside2 の両方のセットが非空になった時点を確認します。
- 交差の終了を識別するため、inside1 または inside2 のいずれかのセットが空になった時点を確認します。
#!/usr/bin/env python
import numpy as np
import matplotlib.pyplot as plt
params = {'xtick.labelsize': 11, 'ytick.labelsize': 11, 'legend.fontsize': 11}
plt.rcParams['font.family'] = 'serif'
plt.rcParams.update(params)
def intersecting_range(start1, stop1, start2_list, stop2_list):
result_start = []
result_stop = []
for start2, stop2 in zip(start2_list, stop2_list):
s = max(start1, start2)
e = min(stop1, stop2)
# 交差する範囲が存在する場合、リストに追加
if s < e:
result_start.append(s)
result_stop.append(e)
return result_start, result_stop
def find_overlaps(start1, stop1, start2, stop2):
# すべての開始イベントと終了イベントを1つのリストにまとめる
# それぞれのイベントには、時間 (x)、イベントの種類 (kind)、および元のリストのインデックス (idx) が含まれる
events = [(x, 1, i) for i, x in enumerate(start1)] + \
[(x, 2, i) for i, x in enumerate(stop1)] + \
[(x, 3, i) for i, x in enumerate(start2)] + \
[(x, 4, i) for i, x in enumerate(stop2)]
# イベントを時間 (x[0]) とイベントの優先順位 (x[1]) に基づいてソートする
# 同じ時間のイベントが発生した場合、stop イベントが start イベントよりも優先されるようにする
events.sort(key=lambda x: (x[0], {2: 1, 4: 2, 1: 3, 3: 4}[x[1]]))
# 各セットは現在アクティブな時間区間を追跡するために使用される
inside1 = set() # start1-stop1 間のアクティブなインデックス
inside2 = set() # start2-stop2 間のアクティブなインデックス
# 重複期間の開始と終了を記録するリスト
overlaps_start = []
overlaps_stop = []
current_overlap_start = None # 現在の重複期間の開始時間を記録する変数
# ソートされたイベントリストを順に処理する
for x, kind, idx in events:
if kind == 1:
inside1.add(idx) # start1 イベントの場合、インデックスを inside1 に追加
elif kind == 2:
inside1.remove(idx) # stop1 イベントの場合、インデックスを inside1 から削除
elif kind == 3:
inside2.add(idx) # start2 イベントの場合、インデックスを inside2 に追加
else: # kind == 4
inside2.remove(idx) # stop2 イベントの場合、インデックスを inside2 から削除
# 両方のセットに要素が含まれている場合、重複が始まったと見なす
if inside1 and inside2 and current_overlap_start is None:
current_overlap_start = x # 重複の開始時間を記録
# どちらか一方のセットが空の場合、重複が終了したと見なす
elif (not inside1 or not inside2) and current_overlap_start is not None:
overlaps_start.append(current_overlap_start) # 重複の開始時間をリストに追加
overlaps_stop.append(x) # 重複の終了時間をリストに追加
current_overlap_start = None # 現在の重複開始時間をリセット
return overlaps_start, overlaps_stop # 重複期間の開始時間と終了時間のリストを返す
# サンプルデータの定義
tstart = 0
tstop = 30
timebinsize = 2
times = np.arange(tstart, tstop + timebinsize, timebinsize)
bintimes_start = times[:-1]
bintimes_stop = times[1:]
gtistart = np.array([1, 5.0, 11.5, 14.6, 21, 23, 26.1, 28.2])
gtistop = np.array( [3.5,10.5, 12.5, 19.2, 23, 26, 28.2, 29.0])
# 重複区間を見つける (高速メソッド)
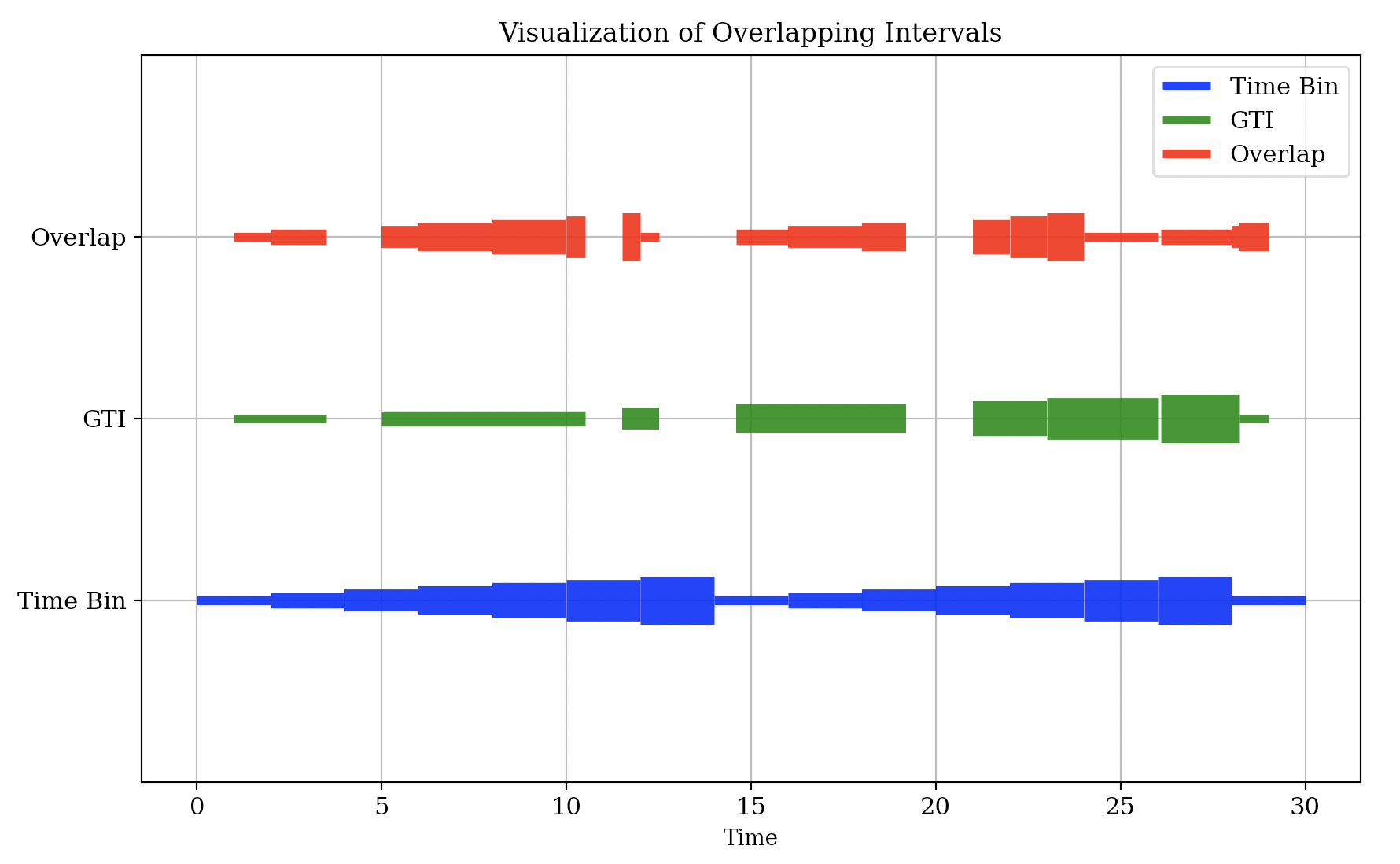
overlaps_start, overlaps_stop = find_overlaps(bintimes_start, bintimes_stop, gtistart, gtistop)
# プロットの設定
fig, ax = plt.subplots(figsize=(10, 6))
# 元の区間をプロット
for i, (s, e) in enumerate(zip(bintimes_start, bintimes_stop)):
print(i,s,e)
ax.hlines(y=1, xmin=s, xmax=e, color='blue', lw=4 + 3*(i%7), label='Time Bin' if s == bintimes_start[0] else "",alpha=0.9)
for i, (s, e) in enumerate(zip(gtistart, gtistop)):
ax.hlines(y=1.5, xmin=s, xmax=e, color='green', lw=4 + 3*(i%7), label='GTI' if s == gtistart[0] else "",alpha=0.9)
# 重複区間をプロット
for i, (s, e) in enumerate(zip(overlaps_start, overlaps_stop)):
ax.hlines(y=2, xmin=s, xmax=e, color='red', lw=4 + 3*(i%7), label='Overlap' if s == overlaps_start[0] else "",alpha=0.9)
# プロットの詳細設定
ax.set_ylim(0.5,2.5)
ax.set_yticks([1, 1.5, 2])
ax.set_yticklabels(['Time Bin', 'GTI', 'Overlap'])
ax.set_xlabel('Time')
ax.legend()
ax.grid(True)
plt.title('Visualization of Overlapping Intervals')
# プロットの表示
plt.savefig("fast_gti.png")
plt.show()
これで、一回の for loop で2種類の時間帯リストの共通部分を見つけることができます。
一応、この結果と、for loop を2回回す方法を比較して、同じ結果になることを確認しましょう。
# 確認してみる。
# 重複区間を見つける (ゆっくりメソッド)
start3 = []
stop3 = []
# start1, stop1 の各範囲に対して交差する範囲を見つける
for s1, e1 in zip(bintimes_start, bintimes_stop):
s, e = intersecting_range(s1, e1, gtistart, gtistop)
start3.extend(s)
stop3.extend(e)
# プロットの設定
fig, ax = plt.subplots(figsize=(10, 6))
# 元の区間をプロット
for i, (s, e) in enumerate(zip(bintimes_start, bintimes_stop)):
print(i,s,e)
ax.hlines(y=1, xmin=s, xmax=e, color='blue', lw=4 + 3*(i%7), label='Time Bin' if s == bintimes_start[0] else "",alpha=0.9)
for i, (s, e) in enumerate(zip(gtistart, gtistop)):
ax.hlines(y=1.5, xmin=s, xmax=e, color='green', lw=4 + 3*(i%7), label='GTI' if s == gtistart[0] else "",alpha=0.9)
# 重複区間をプロット
for i, (s, e) in enumerate(zip(start3, stop3)):
ax.hlines(y=2, xmin=s, xmax=e, color='red', lw=4 + 3*(i%7), label='Overlap' if s == overlaps_start[0] else "",alpha=0.9)
# プロットの詳細設定
ax.set_ylim(0.5,2.5)
ax.set_yticks([1, 1.5, 2])
ax.set_yticklabels(['Time Bin', 'GTI', 'Overlap'])
ax.set_xlabel('Time')
ax.legend()
ax.grid(True)
plt.title('Visualization of Overlapping Intervals')
# プロットの表示
plt.savefig("slow_gti.png")
plt.show()
どちらの方法でも同じ結果になるはずです(bugがなければ..)。
コードの補足
このアルゴリズムの目的は、2つの異なる時間区間のリストの重複部分を見つけることです。以下では、このコードの各部分について詳細に説明します。
関数の定義
def find_overlaps(start1, stop1, start2, stop2):
この関数は、4つのリストを引数として取ります:
-
start1: 最初の時間区間の開始時間 -
stop1: 最初の時間区間の終了時間 -
start2: 二番目の時間区間の開始時間 -
stop2: 二番目の時間区間の終了時間
イベントリストの作成
events = [(x, 1, i) for i, x in enumerate(start1)] + \
[(x, 2, i) for i, x in enumerate(stop1)] + \
[(x, 3, i) for i, x in enumerate(start2)] + \
[(x, 4, i) for i, x in enumerate(stop2)]
ここでは、4つのリストからイベントを作成し、1つのリスト events にまとめています。各イベントはタプル (x, kind, idx) です:
-
x: イベントの時間 -
kind: イベントの種類-
1:start1の開始イベント -
2:stop1の終了イベント -
3:start2の開始イベント -
4:stop2の終了イベント
-
-
idx: 元のリスト内のインデックス
イベントのソート
events.sort(key=lambda x: (x[0], {2: 1, 4: 2, 1: 3, 3: 4}[x[1]]))
events リストを時間 (x[0]) とイベントの種類 (x[1]) に基づいてソートします。同じ時間のイベントがある場合、以下の順序でソートされます:
-
stop1(優先順位 1) -
stop2(優先順位 2) -
start1(優先順位 3) -
start2(優先順位 4)
これにより、終了イベントが開始イベントよりも先に処理されるようになります。
時系列データを等間隔で生成する場合に気を付けるべき事項です。等間隔の時間の場合は、stopとstartが完璧に同じ値になるので、判定条件として、どちらを優先的に扱うかに気を付ける必要があります。この場合は、stop を優先することで、出力する配列を一度区切ることになります。
アクティブな時間区間の追跡
inside1 = set() # start1-stop1 間のアクティブなインデックス
inside2 = set() # start2-stop2 間のアクティブなインデックス
inside1 と inside2 のセットは、現在アクティブな時間区間を追跡するために使用されます。それぞれ start1-stop1 と start2-stop2 の間のインデックスを保持します。
重複期間の追跡と記録
overlaps_start = []
overlaps_stop = []
current_overlap_start = None # 現在の重複期間の開始時間を記録する変数
overlaps_start と overlaps_stop は、重複期間の開始と終了を記録するためのリストです。current_overlap_start は、現在の重複期間の開始時間を記録するための変数です。
イベントの処理
for x, kind, idx in events:
if kind == 1:
inside1.add(idx) # start1 イベントの場合、インデックスを inside1 に追加
elif kind == 2:
inside1.remove(idx) # stop1 イベントの場合、インデックスを inside1 から削除
elif kind == 3:
inside2.add(idx) # start2 イベントの場合、インデックスを inside2 に追加
else: # kind == 4
inside2.remove(idx) # stop2 イベントの場合、インデックスを inside2 から削除
# 両方のセットに要素が含まれている場合、重複が始まったと見なす
if inside1 and inside2 and current_overlap_start is None:
current_overlap_start = x # 重複の開始時間を記録
# どちらか一方のセットが空の場合、重複が終了したと見なす
elif (not inside1 or not inside2) and current_overlap_start is not None:
overlaps_start.append(current_overlap_start) # 重複の開始時間をリストに追加
overlaps_stop.append(x) # 重複の終了時間をリストに追加
current_overlap_start = None # 現在の重複開始時間をリセット
この部分では、各イベントを順に処理します:
-
kindに基づいて、inside1またはinside2にインデックスを追加または削除します。 -
inside1とinside2の両方に要素が含まれている場合、これは重複期間が始まったことを意味し、current_overlap_startを設定します。 -
inside1またはinside2が空になった場合、これは重複期間が終了したことを意味し、overlaps_startとoverlaps_stopに重複期間を記録し、current_overlap_startをリセットします。
結果の return
return overlaps_start, overlaps_stop # 重複期間の開始時間と終了時間のリストを返す
最終的に、重複期間の開始時間と終了時間のリストを返します。
このアルゴリズムは、時間区間の開始と終了イベントを一つのリストにまとめ、適切な順序でソートしてから、各イベントを順に処理することで、2つの時間区間リストの重複部分を効率的に検出します。