FoF(Friends-of-Friends)アルゴリズムとは(2025年版・Python実装つき)
FoF(Friends-of-Friends)は、点群データに対して
- 距離が r 以下なら辺を張る(友達)
- 辺でつながっている点の連結成分(connected component)をクラスタとして返す
という、「グラフの連結成分」そのもののクラスタリングです。
階層クラスタリングでいうと single-linkage を距離しきい値で打ち切ったものに一致します。
1. 数学的な定義(これが一番クリア)
点集合 $X={x_i}_{i=1}^N\subset \mathbb{R}^d$ と閾値 $r>0$ を与える。
無向グラフ $G=(V,E)$ を
- 頂点 $V={1,\dots,N}$
- 辺 $(i,j)\in E \iff |x_i-x_j|\le r$
で定める。
このとき FoF のクラスタは、グラフ (G) の 連結成分の集合である。
つまり「友達の友達は友達」を、曖昧な手続きでなく連結性として定義しているだけです。
2. なぜ FoF が必要か(“不変量を探す”より現実的な答え)
FoF が便利なのは、次の性質があるからです。
- クラスタ数を事前に決めなくてよい
- 形状を仮定しない(球状・楕円体など不要。細長い構造も拾える)
- しきい値 $r$ だけで「密な領域」を拾える
- 実装が「近傍探索+Union-Find」で済む(再現性が高い)
一方で、FoF は single-linkage と同じ弱点も持ちます。
FoFの代表的な弱点:bridging(鎖で全部つながる)
2つの塊の間に、点が“橋”のように並ぶと、本当は別クラスタでも 1 つに連結してしまうことがあります。
これは「FoFのバグ」ではなく、定義上そうなる(連結成分だから)という性質です。
3. パラメータ r の意味(何を調整しているのか)
FoF の唯一のパラメータ $r$(linking length)は、
- 「この距離以内なら同じ構造だとみなす」空間スケール
- 密度しきい値の代用品(近い点が多い領域ほど連結しやすい)
という意味を持ちます。
特に宇宙論 N-body の FoF では、しばしば
- $r = b \times \bar{\ell}$($\bar{\ell}$:平均粒子間隔)
のように書くことがあります。このように対応付けをすることで、FoF 群の平均過密度が経験則として良い感じの量を探すことがあります。
4. pyfof はどうなった?(2025年時点の現実)
pyfof は R*-tree を使って高速化した FoF 実装として知られています。(GitHub)
ただし PyPI の最新リリースは **2019-07-06(v0.1.5)**で、ビルドには C++11 + boost が必要です。環境によっては pip install が通らない(あるいは通りにくい)タイプです。(PyPI)
なので2025年以降のおすすめは、
- まず SciPy(cKDTree)で自前実装(依存が軽く、移植性が高い)
- 必要なら
pyfofを試す
が良い気がします。
5. まずは「SciPyだけで動く」FoF最小実装(おすすめ)
ポイントは2つだけ:
-
cKDTree.query_pairs(r)で「距離 ≤ r のペア」を列挙 - Union-Find(Disjoint Set Union)で連結成分を作る
import numpy as np
from scipy.spatial import cKDTree
class UnionFind:
def __init__(self, n: int):
self.parent = np.arange(n, dtype=int)
self.size = np.ones(n, dtype=int)
def find(self, x: int) -> int:
# path compression
while self.parent[x] != x:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
def union(self, a: int, b: int) -> None:
ra, rb = self.find(a), self.find(b)
if ra == rb:
return
# union by size
if self.size[ra] < self.size[rb]:
ra, rb = rb, ra
self.parent[rb] = ra
self.size[ra] += self.size[rb]
def fof_groups(data: np.ndarray, r: float):
"""
Friends-of-Friends clustering by connected components of the r-neighborhood graph.
Parameters
----------
data : (N, d) array
r : linking length
Returns
-------
groups : list[list[int]] (index lists)
"""
data = np.asarray(data)
n = data.shape[0]
tree = cKDTree(data)
# all unordered pairs (i, j) with distance <= r
pairs = tree.query_pairs(r, output_type='ndarray') # shape (M, 2)
uf = UnionFind(n)
for i, j in pairs:
uf.union(int(i), int(j))
# collect components
roots = np.array([uf.find(i) for i in range(n)], dtype=int)
uniq = np.unique(roots)
groups = []
for rt in uniq:
members = np.where(roots == rt)[0].tolist()
groups.append(members)
return groups
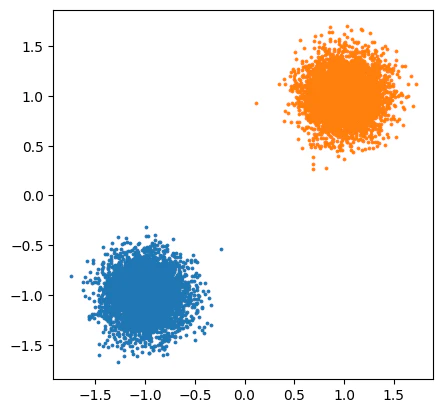
6. 実行例(2つの塊)
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
npts = 10000
data = np.vstack([
np.random.normal(-1, 0.2, (npts//2, 2)),
np.random.normal( 1, 0.2, (npts//2, 2)),
])
groups = fof_groups(data, r=0.4)
for g in groups:
plt.scatter(data[g, 0], data[g, 1], s=3)
plt.gca().set_aspect("equal")
plt.show()
この例は(だいたい)2群に分かれます。
7. 「全部つながる」状態
パラメータが適切じゃないと、全部1つになるのは、FoFの典型的挙動です。
- linking length が大きい
- あるいは分布のシグマが大きくて裾が重なる
- その結果「連結グラフ」になってしまう
つまり人間の直感と、FoFの定義(連結成分)がズレる瞬間があります。
そのあたりを人力で補正する必要があります。
対処の考え方
- r を最適化する(最優先)
- 標準化(whitening):軸ごとにスケールが違うなら正規化してから距離を測る
- bridging が本質的に困るなら FoF をやめて別手法へ(DBSCAN/HDBSCANなど)
8. pyfof を使うなら(補足)
pyfof は「R*-treeで高速化したFoF」として説明されています。(GitHub)
ただし、PyPIの最終リリースが2019年で、boostなどのビルド要件があるため、環境によってはハマります。(PyPI)
pip install pyfof
が通れば、APIはシンプルです:
import pyfof
groups = pyfof.friends_of_friends(data, 0.4)
9. まとめ(2025年のおすすめ方針)
- FoF = 距離しきい値グラフの連結成分
- 弱点(bridging)は仕様であり、r の調整が本質
- 2025年はまず SciPy cKDTree + Union-Find の実装が堅牢
-
pyfofは便利だが 2019年止まりなので「入ればラッキー」枠 (PyPI)

コードは google colab でも閲覧可能です.