13章 DALL-E 2の内部モデルの解説
目標
- テキストから画像を生成するOpenAIの大規模言語モデル「DALL-E 2」の内部構造を調べる
- マルチモーダル学習の仕組みを理解する
13.1 マルチモーダル学習とは?
マルチモーダル学習とは、異なる種類のデータ(例:テキストと画像)の間で変換を行う生成モデルを訓練する手法です。
テキストからの画像生成
テキストプロンプトから画像を生成するタスクでは、与えられた文章を高品質な画像へ変換することが目的です。モデルは以下の課題に取り組む必要があります:
-
テキストと画像の橋渡し
2つの領域間の共有表現を学習し、情報の欠落なく変換を行う。 -
新しい概念とスタイルの理解
見たことのない概念やスタイルを適切に結びつける。 -
文脈の理解
単語が文脈で持つ意味を学び、それを画像に正確に反映する。
13.2 DALL-E 2の内部構造
DALL-Eは、2021年2月にリリースされ、進化版のDALL-E 2は2022年4月に登場しました。以下では、そのアーキテクチャを解説します。
13.2.1 アーキテクチャの概要
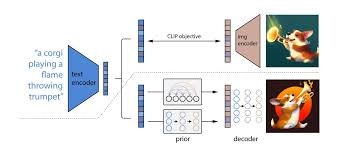
DALL-E 2の処理フローは以下の通りです:
-
テキストエンコーダ
テキストプロンプトを埋め込みベクトルに変換します -
ブライア(Prior)
テキスト埋め込みを画像埋め込みに変換します -
デコーダ
画像埋め込みを条件として画像を生成します
13.2.2 テキストエンコーダ
目的: テキストプロンプトを潜在空間の埋め込みベクトルに変換する。
これにより、ベクトルを基にさらなる操作が可能になります。
DALL-E 2では、CLIP(Contrastive Language-Image Pre-training)というモデルを使用しています。
CLIPの特徴:
- テキスト埋め込みを、対応する画像埋め込みにできるだけ近づけるように訓練
- テキストが持つ豊富な概念を理解可能
13.2.3 ブライア(Prior)
目的: テキスト埋め込みを、対応する画像埋め込みに変換する。
ブライアの実装には2つのアプローチが試されました:
-
自己回帰モデル
- CLIPの埋め込みペアを逐次的に変換
- 欠点:計算効率が悪い
-
拡散モデル(採用)
- ノイズ除去過程を利用して、効率的に画像埋め込みを生成
拡散ブライアの仕組み
-
訓練プロセス
- CLIPで生成したテキストと画像の埋め込みを結合
- 画像埋め込みにランダムノイズを付加
- 拡散モデルがノイズを取り除き、元の画像埋め込みを予測
-
生成プロセス
- ランダムノイズを徐々に除去して画像埋め込みを生成。
13.2.4 デコーダ
目的: ブライアが出力した画像埋め込みを基に、最終的な画像を生成します。
DALL-E 2のデコーダ部分では、GLIDEという技術が活用されています。
GLIDEの特徴:
- テキストプロンプトを基に、写実的な画像を生成可能
- CLIPを使用せず、生のテキストプロンプトから学習
13.2.5 DALL-E 2のユースケース
-
画像のバリエーション生成
ランダムノイズを変えることで、多様な画像バリエーションが得られる -
ブライアの重要性
- ブライアがないと、情報が欠落した画像しか生成されない
- ブライアを使うことで、正確で詳細な画像が得られる
13.2.6 制限
- モデルが訓練されたデータ範囲外の概念やスタイルを扱う場合、生成精度が低下する可能性があります
まとめ
DALL-E 2は、テキストから画像を生成する際に以下の手法を駆使しています:
- 訓練済みのCLIPモデルを使用し、テキスト埋め込みを生成
- 拡散モデル(ブライア)を使い、画像埋め込みに変換
- GLIDEスタイルのデコーダを用いて、最終的な画像を生成
DALL-E 2は、テキストからの画像生成だけでなく、画像バリエーション生成やその他の応用にも対応可能です。
参考文献