こんにちは、Qiita初投稿のヤマダです!
AWSのサーバレスサービスを実際にいくつか触ってみるハンズオン手順を作成しました。
私自身、AWSサービスの理解が深まったと感じたのはいくつかのハンズオンを実施してからでした。可能な限り丁寧に手順や内容について記していきたいと思います🙇♂️
【対象読者】
- AWS初心者の方
- AWSのサーバレスアーキテクチャを実際に触ってみたい方
【説明しないこと】
- 使用するAWSサービスの詳細について
- AWSアカウントの作成方法、事前準備について
はじめに
- 本記事は2024年12月時点の各種ドキュメントを参照して作成しています
- 最新の情報については公式ドキュメントをご確認ください
ハンズオンの全体説明

以下のサービスを使用した、シンプルなREST APIの配信を行う構成を作成します。
- Amazon API Gateway
- AWS Lambda
- Amazon Bedrock
- Amazon DynamoDB
ユーザーからのリクエストに対して、生成AIを利用して結果を取得し、履歴をDBに保存しつつレスポンスを返却します。作業は全てマネジメントコンソールから行います。作業全体の流れは以下の通りです。
- AWS Lambdaを作成し、Amazon Bedrockの機能を利用する
- AWS Lambdaにて1で得た結果をAmazon DynamoDBに保存する
- AWS LambdaとAmazon API Gatewayを連携し、REST APIを配信する
- APIを呼び出し、結果を確認する
- リソースの削除
始める前の注意点
ハンズオンではリージョンを何度か切り替えます。
リージョンを間違えるとLambdaが期待通り動作しない可能性もあるので注意してください。
操作にどのような意味があるのかが伝わるように、あえて操作後にエラーが出る手順もあります。
アクセス権限について。AWSでは最小権限にて実行することが推奨されていますが、本ハンズオンでは作業をシンプルにするために大きめの権限を付与しています。
ハンズオン本編
①AWS Lambdaを作成し、Amazon Bedrockの機能を利用する
Lambda関数の作成
まずはAWS Lambdaを作成します。マネジメントコンソールの検索からAWS Lambdaのページに移動します。

リージョンが「東京(ap-northeast-1)」になっていることを確認します。その他のリージョンになっている場合は「東京(ap-northeast-1)」に切り替えてください。「関数の作成」を押下します。
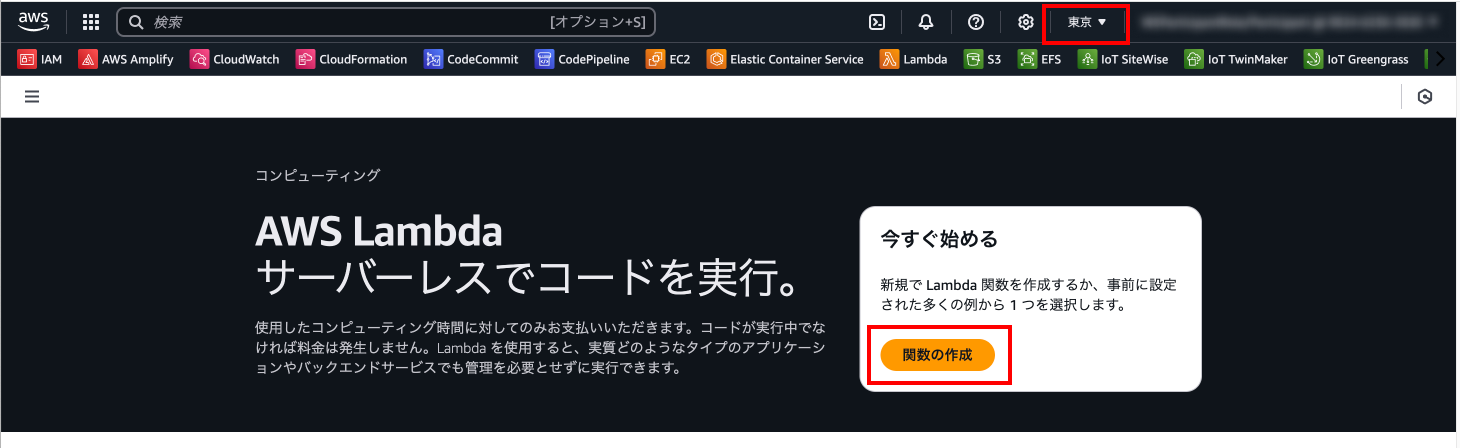
※初めてコンソールにアクセスする場合とすでにリソースを作成したことのある人では画面が違う可能性があります。
以下の入力を行います。
関数名とランタイム以外は初期値で設定されていると思います。
他は特に入力などを行わず、下までスクロールして「関数の作成」を押下します。

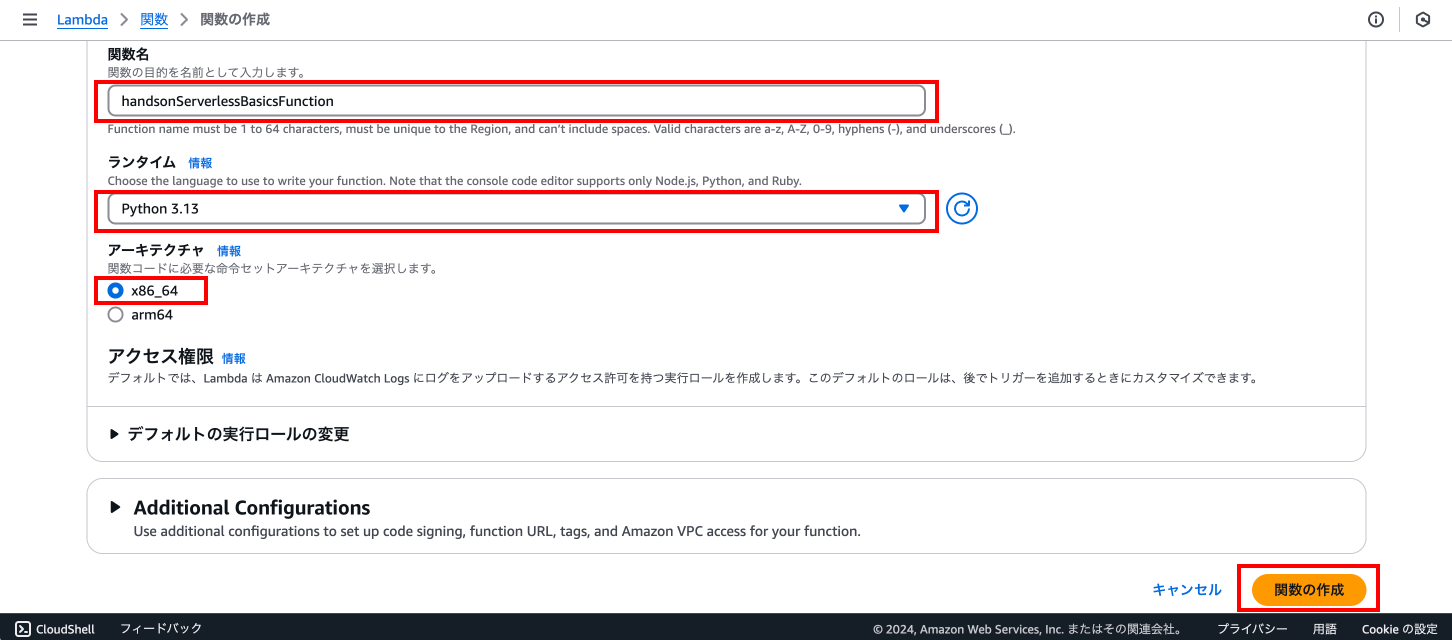
オプション: 「一から作成」を選択する
handsonServerlessBasicsFunction
Python 3.13
x86_64
少し待つと関数が作成され、上に成功した旨のメッセージが表示されます。
画面が見にくければこれは消してしまっても問題ありません。
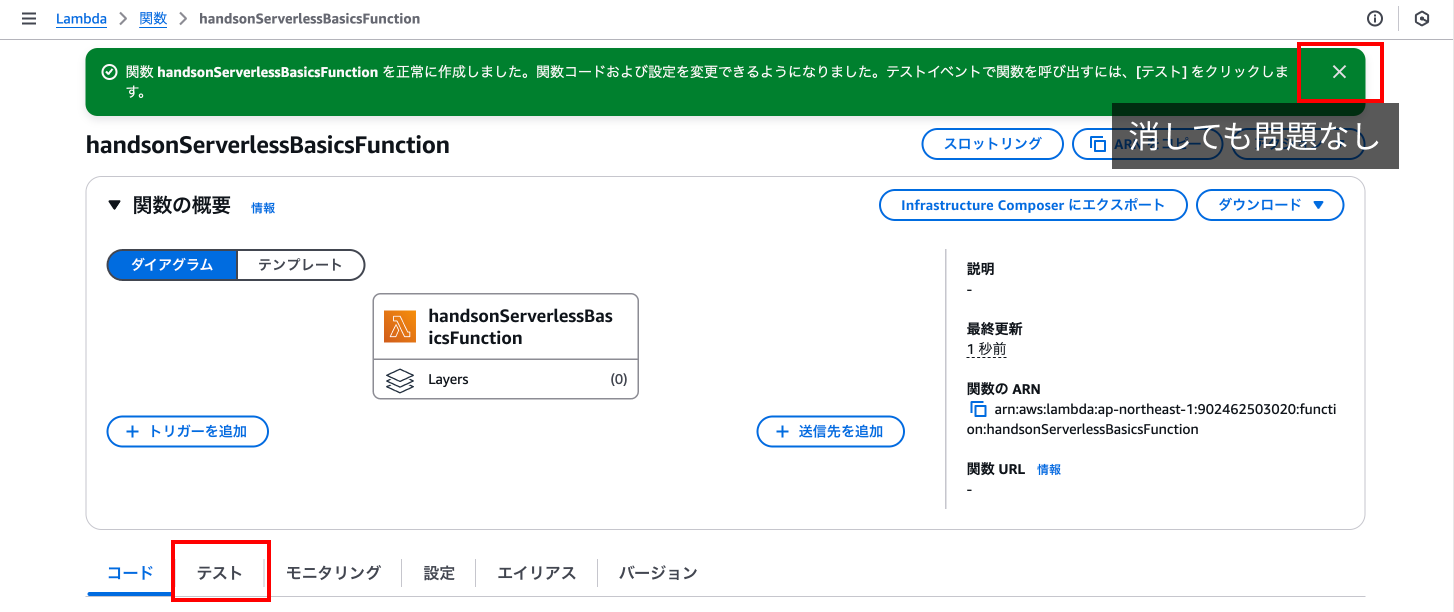
まずは一度作成した関数を実行してみましょう。
下にある「テスト」タブを押下し、テストイベントの「テスト」を押下します。
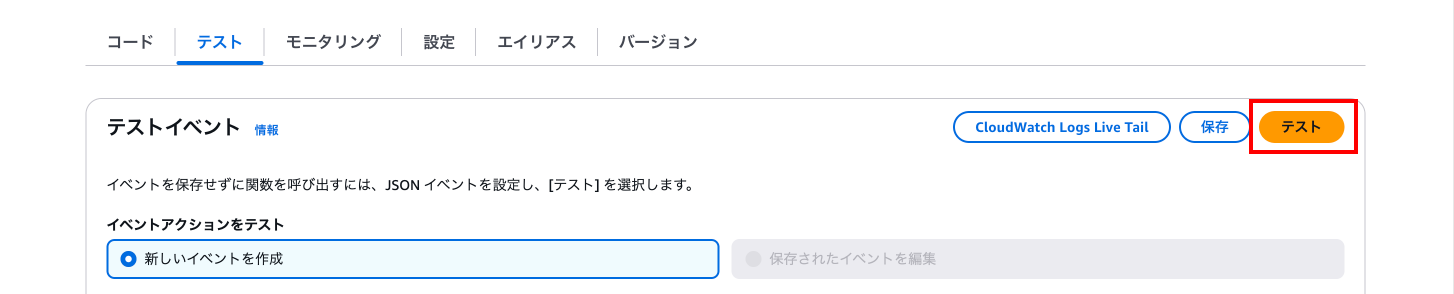
緑色で成功と表示されます。
「▶︎詳細」を押下して詳細を表示します。


レスポンスとして以下のjsonが戻ってきていることが分かります。
{
"statusCode": 200,
"body": "\"Hello from Lambda!\""
}
では次に「コード」タブに移動し、Lambdaのソースを見ていきましょう。
現在はデフォルトで先ほどのレスポンスを返却するコードが書かれています。
この部分を以下のコードに置き換えてください。
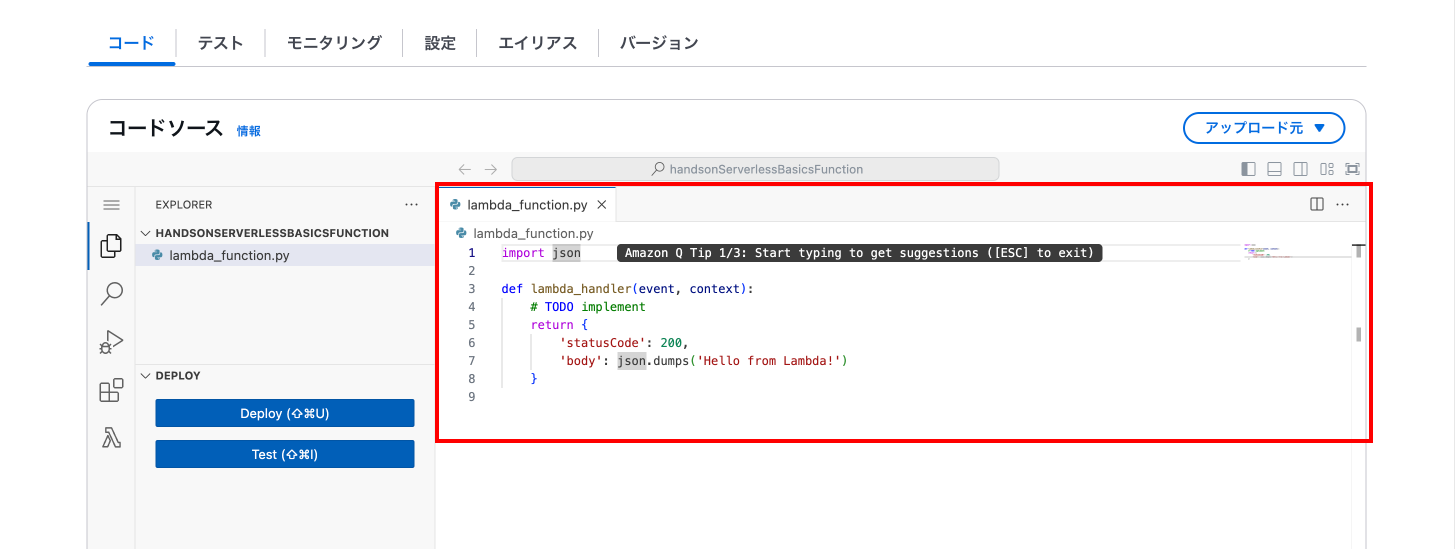
import boto3
import json
from botocore.exceptions import ClientError
def lambda_handler(event, context):
request_prompt = event["request_prompt"]
# Bedrockから回答を取得
output_text = callBedrock(request_prompt)
# 回答をユーザーに返却
return {
"statusCode": 200,
"body": output_text,
}
def callBedrock(request_prompt):
# Amazon Bedrock Runtime clientを作成
brt = boto3.client("bedrock-runtime", region_name="us-west-2")
# 使用するモデルID
model_id = "amazon.titan-text-express-v1"
# 生成AIに渡すプロンプト
prompt = request_prompt
native_request = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512,
"temperature": 0.5,
"topP": 0.9
},
}
request = json.dumps(native_request)
try:
# Bedrockを呼び出し
response = brt.invoke_model(modelId=model_id, body=request)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)
model_response = json.loads(response["body"].read())
response_text = model_response["results"][0]["outputText"]
print(f"{response_text=}")
return response_text
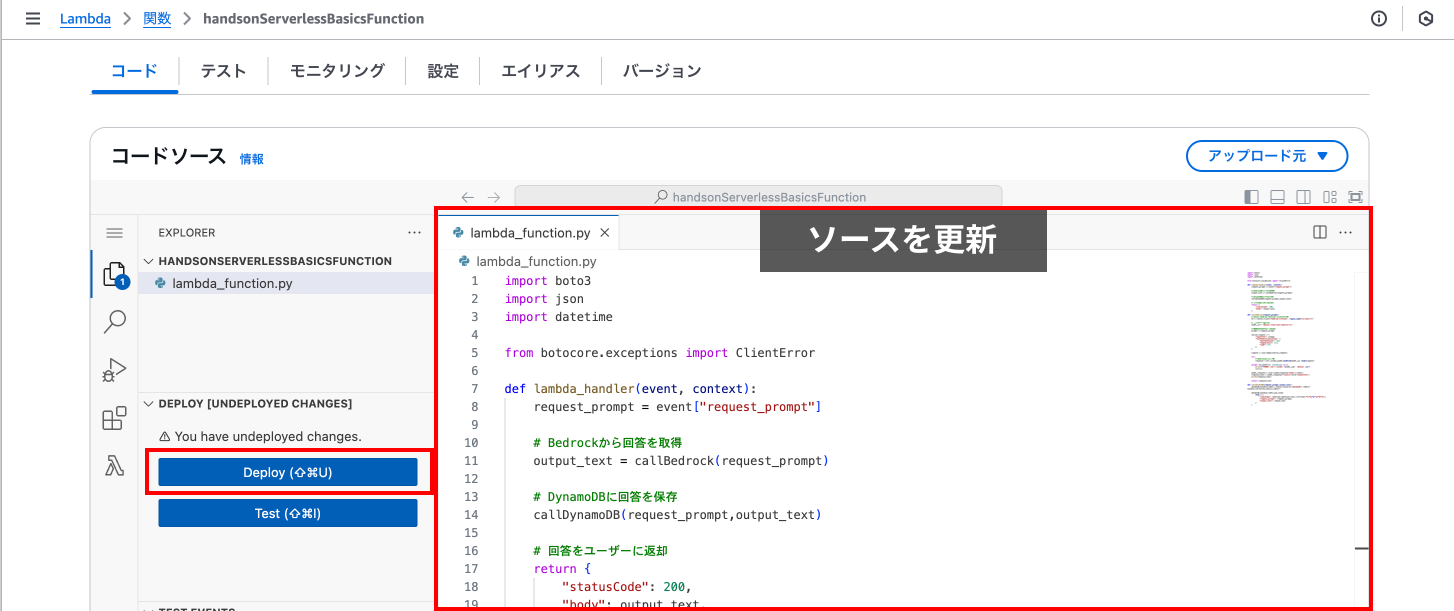
ソースコードを置き換えたらエディターの左側にある「Deploy」を押下します。
問題なくデプロイできると画面上部に正常に更新された旨のメッセージが表示されます。

コードを実行する前にLambda関数の設定を変更する必要があります。
生成AIを使用する場合は、Lambdaの実行時間がデフォルトの3秒では足りません。
あとは今回作成したLambdaがBedrockを使用できるようにアクセス権限の追加も行います。
「設定」タブに移動し「一般設定」を確認します。
タイムアウトがデフォルト値の3秒になっていると思います。
この部分を今回は1分に設定しましょう。

「編集」を押下し、少し下にある「タイムアウト」を「1分0秒」と入力します。
画面下部にある「保存」を押下します。

次に「設定」タブの「アクセス権限」を押下します。
ここではこのLambdaに割り当てられている実行ロールが確認できます。
ロールを編集するために、ロール名の下にあるリンクを押下します。
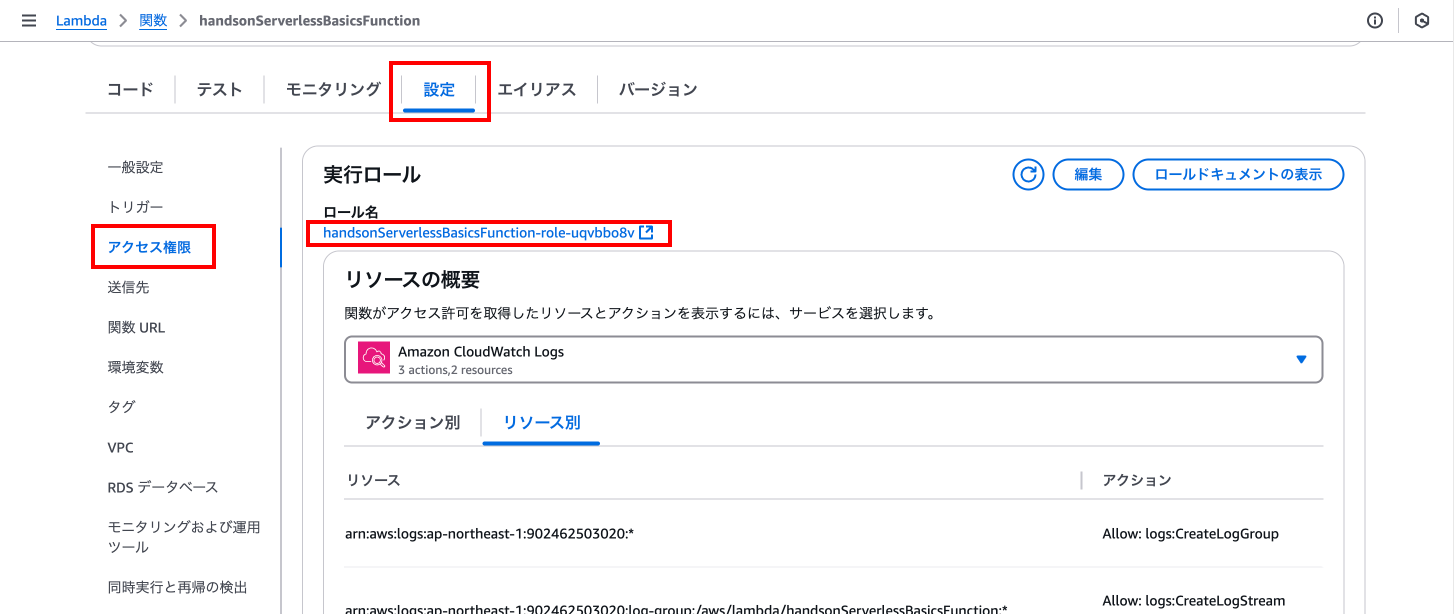
「許可」タブにある「許可を追加」を押下し「ポリシーをアタッチ」を押下します。
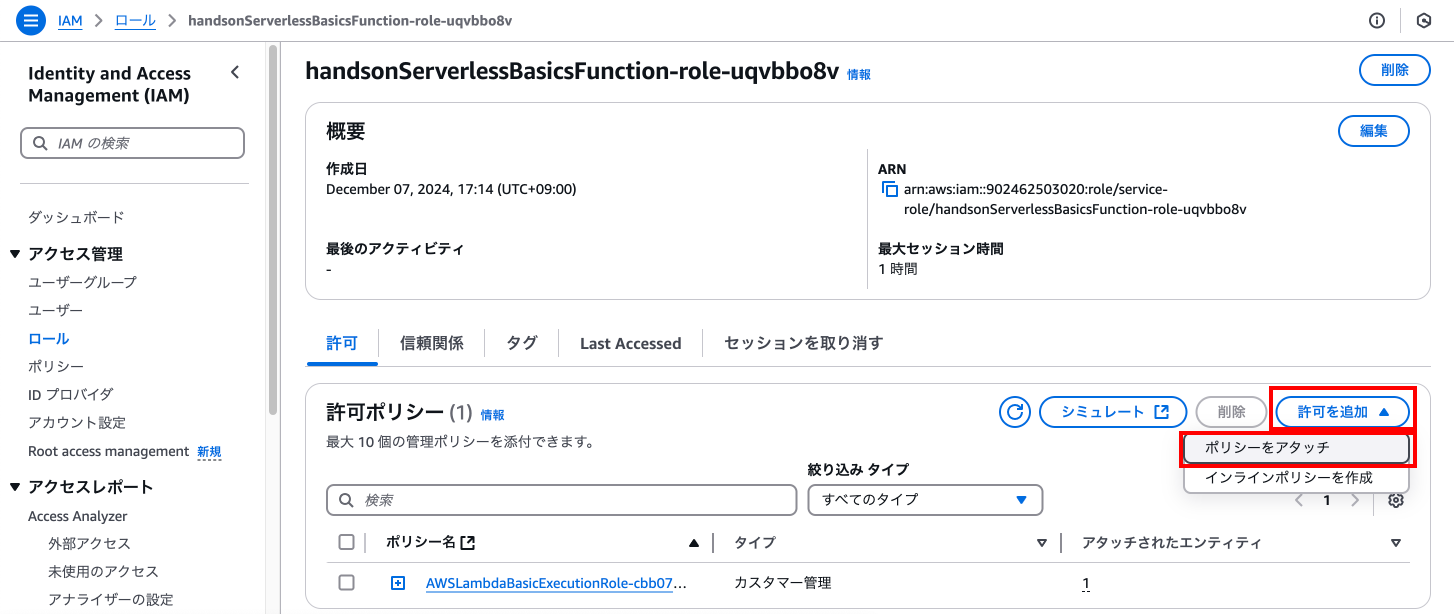
その他の許可ポリシーにある検索に「Bedrock」と入力し、「AmazonBedrockFullAccess」というポリシーの左にチェックマークをつけ、「許可を追加」を押下します。
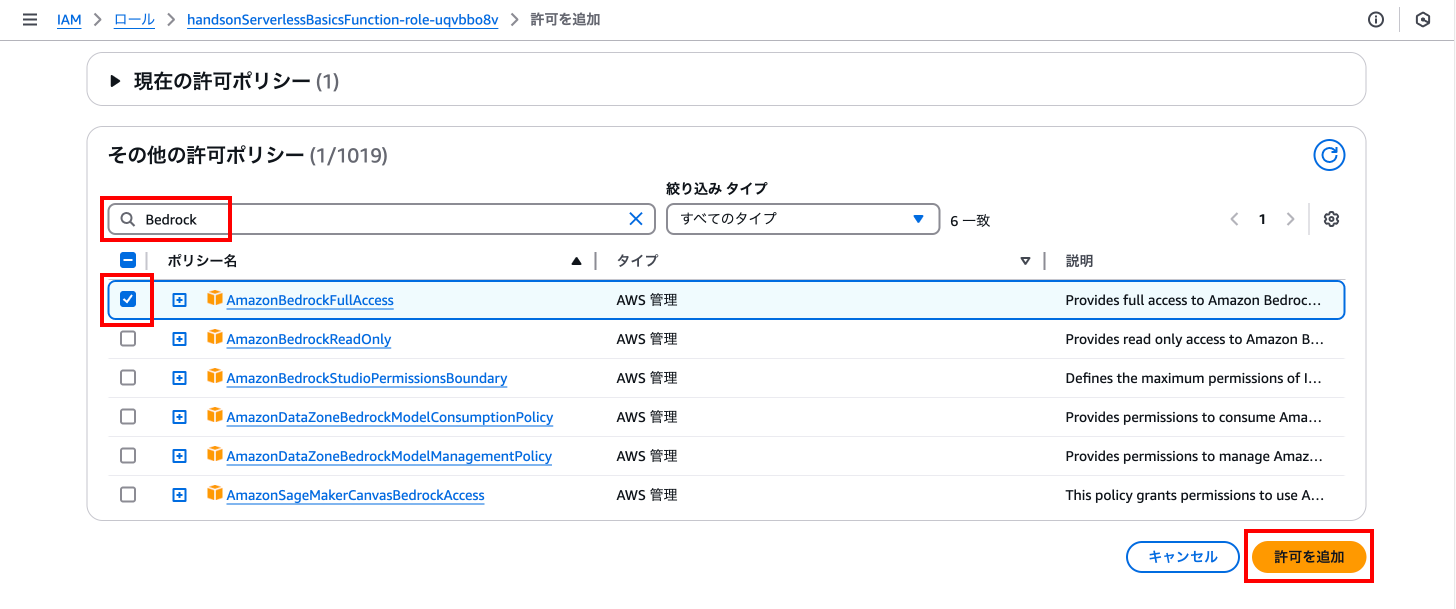
正常にポリシーが追加されたことを確認し、Lambdaの画面に戻りましょう。
ではコードを実行するため、「テスト」タブに移動します。
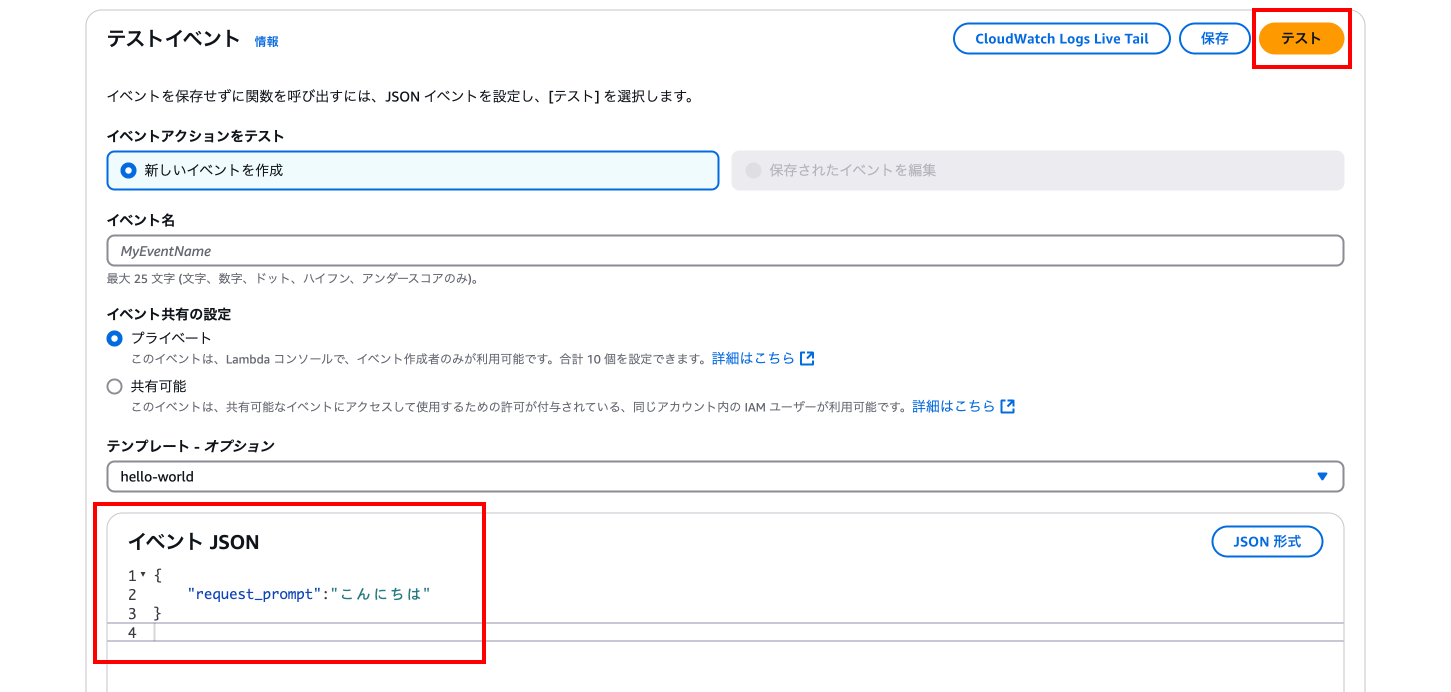
下までスクロールし、イベントJSONに以下のJSON文字列を入力してください。
{
"request_prompt": "こんにちは"
}
これはテスト時にリクエストの値を設定する箇所となります。
では「テスト」を押下してコードを実行します。
おそらく下記のようなBedrockのモデルアクセスのエラーが発生します。
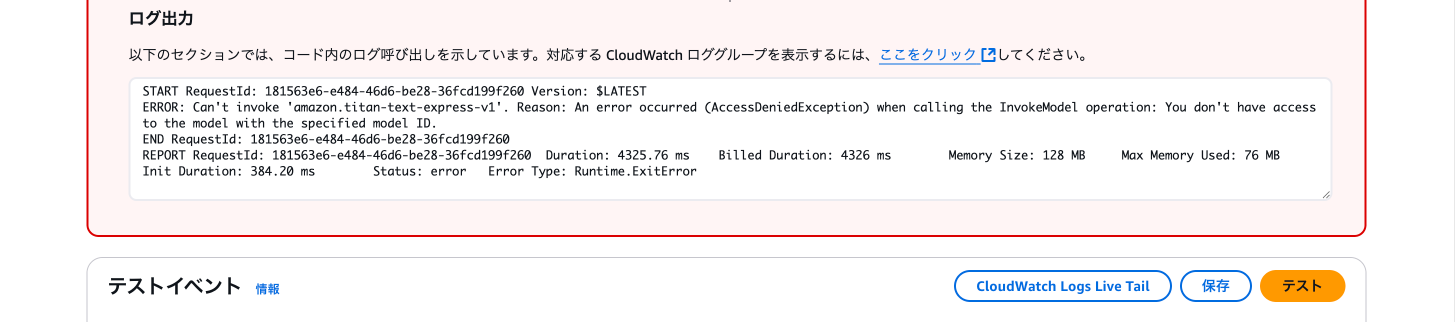
ここからは一旦Bedrockのページに移動し、モデルアクセス権限を設定します。
Bedrockのモデルアクセス権限の設定
マネジメントコンソールの検索からAmazon Bedrockのページに移動します。
Amazon Bedrockではリージョン毎に許可されているモデルが大きく違います。
移動後にリージョンを「オレゴン(us-west-2)」に変更してください。
左側のサイドメニューを下にスクロールしていき、「Bedrock configurations」の「モデルアクセス」を押下します。
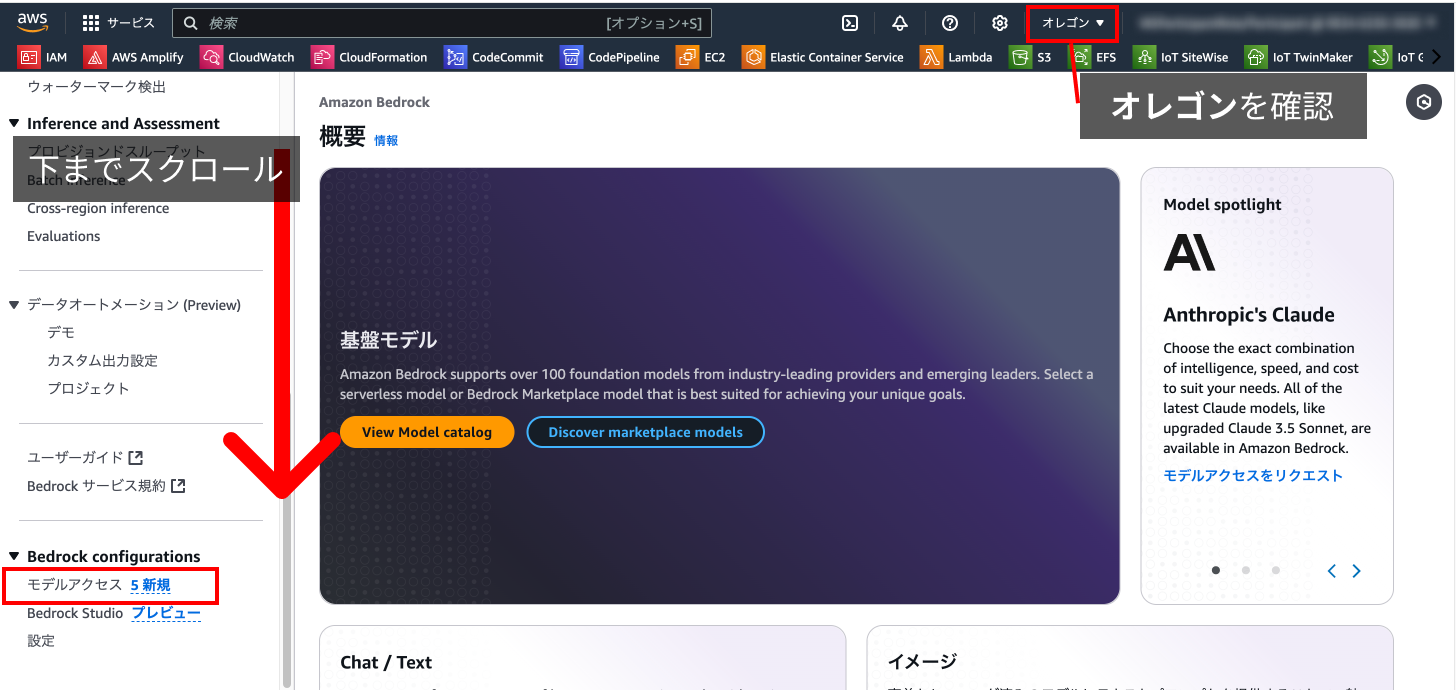
「特定のモデルを有効にする」を押下します。
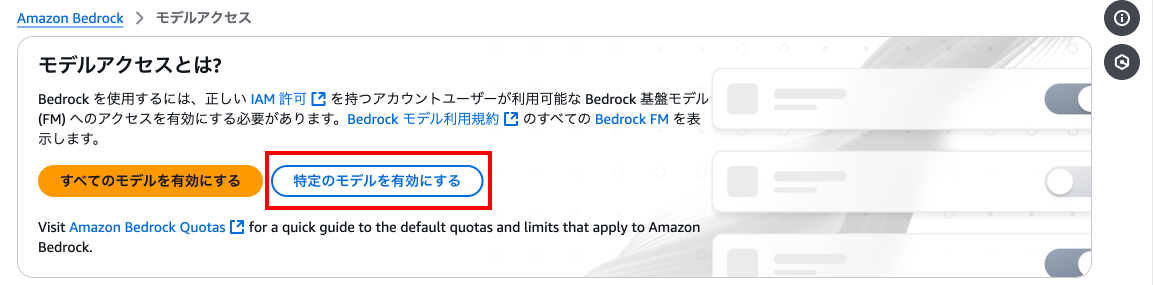
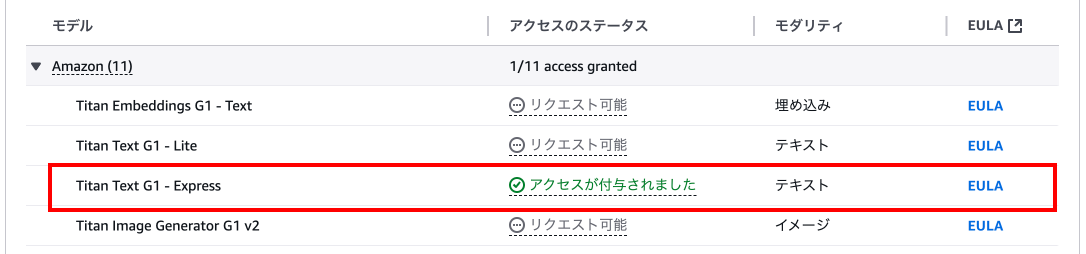
「Titan Text G1 - Express」の左のチェックマークを押下し、下の「次へ」を押下します。
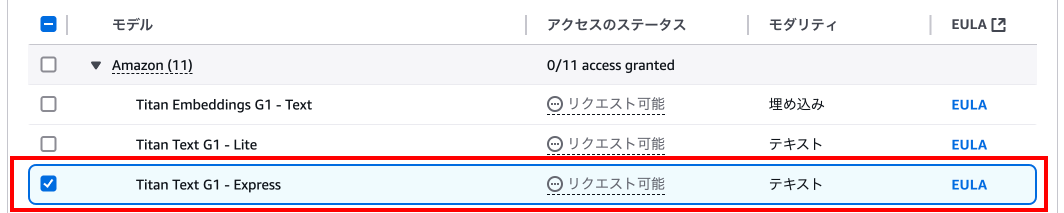

変更に上記で選択したモデルが出ていることを確認し、「送信」を押下します。
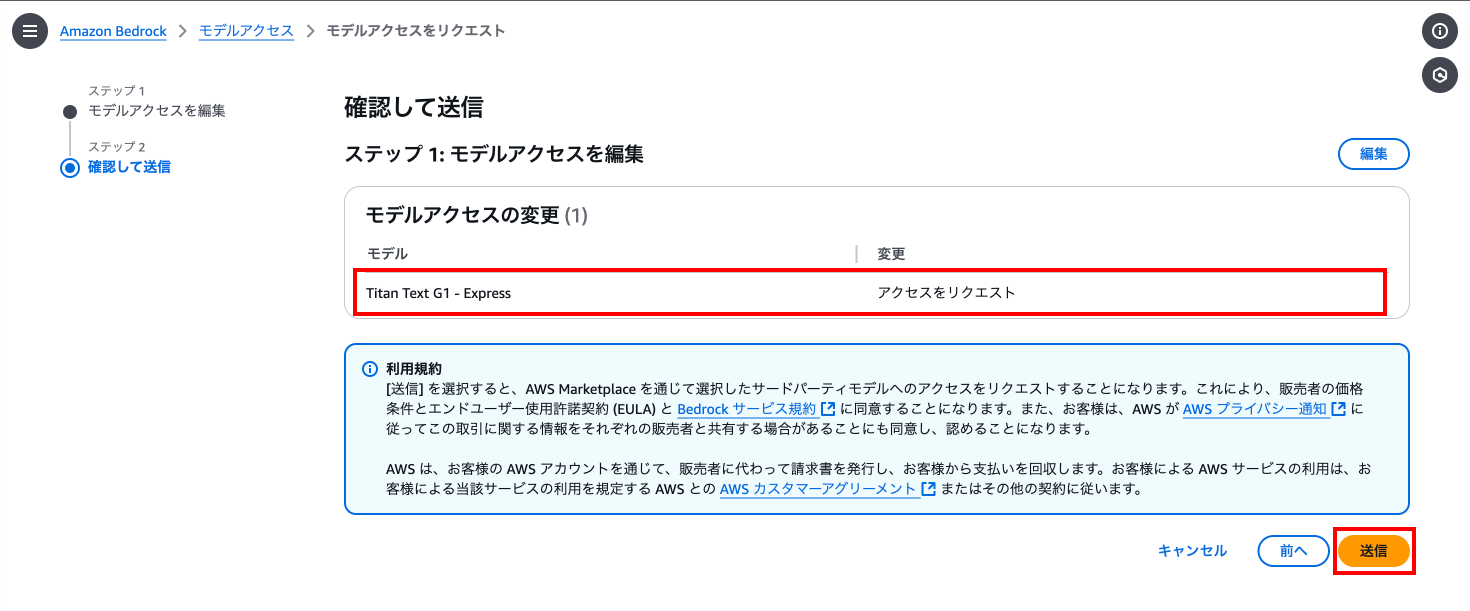
少し待ち、モデルに「アクセスが付与されました」が表示されていることを確認します。
Lambda関数の実行確認
AWS Lambdaのサービスページに戻ります。
左側のサイドメニューから「関数」を押下し、先ほど作成した「handsonServerlessBasicsFunction」を押下します。
「テスト」タブに移動し、先ほどと同じ様にイベントJSONに以下のJSON文字列を入力して「テスト」を押下します。

{
"request_prompt": "こんにちは"
}
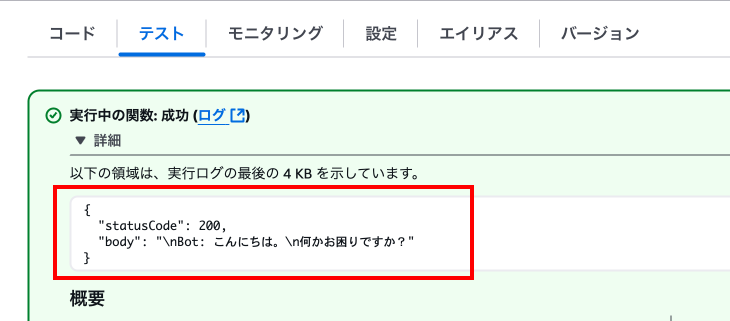
成功しました!
関数が実行され、レスポンスでAmazon Bedrockからの結果が返ってきていることを確認します。生成AIから挨拶への返答と気遣いが返ってきていますね。
②AWS Lambdaにて①で得た結果をAmazon DynamoDBに保存する
DynamoDBにテーブルを作成する
検索バーからDynamoDBのページに移動し、「テーブルの作成」を押下します。
移動後にリージョンを「東京(ap-northeast-1)」に変更してください。

テーブルの作成で以下の入力を行い、「テーブルの作成」を押下します。


handson_serverless_basics_table
timestamp
少し待つとテーブルが作成されます。

LambdaからDynamoDBにデータを保存してみる
次に①で作成したLambdaにDynamoDBへのデータ保存機能を追加します。
可能であればドキュメントを参考に手作業でコードを書いてみてください。
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/getting-started-step-2.html
様々な機能を実装する際、基本的には公式のドキュメントを参考にすれば簡単に実装できます。分からない時はインターネットに公開されている事例を調べてみると理解が深まります。
以下のようにLambda関数を更新してください。
import boto3
import json
import datetime
from botocore.exceptions import ClientError
def lambda_handler(event, context):
request_prompt = event["request_prompt"]
# Bedrockから回答を取得
output_text = callBedrock(request_prompt)
# DynamoDBに回答を保存
callDynamoDB(request_prompt,output_text)
# 回答をユーザーに返却
return {
"statusCode": 200,
"body": output_text,
}
def callBedrock(request_prompt):
# Amazon Bedrock Runtime clientを作成
brt = boto3.client("bedrock-runtime", region_name="us-west-2")
# 使用するモデルID
model_id = "amazon.titan-text-express-v1"
# 生成AIに渡すプロンプト
prompt = request_prompt
native_request = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512,
"temperature": 0.5,
"topP": 0.9
},
}
request = json.dumps(native_request)
try:
# Bedrockを呼び出し
response = brt.invoke_model(modelId=model_id, body=request)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)
model_response = json.loads(response["body"].read())
response_text = model_response["results"][0]["outputText"]
print(response_text)
return response_text
def callDynamoDB(request_prompt,output_text):
dynamodb_handson_table = boto3.resource("dynamodb").Table("handson_serverless_basics_table")
dynamodb_handson_table.put_item(
Item = {
"timestamp": datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S"),
"request_prompt": request_prompt,
"output_text": output_text
}
)
Lambda関数のページを開き、ソースコード全体を上書きした後に「Deploy」ボタンを押下することで作業完了です。
Lambda関数を実行し、結果を確認する
このままLambda関数を一度実行してみましょう。
いつものように以下のイベントJSONを入力し、「テスト」を押下します。


{
"request_prompt": "こんにちは"
}
おそらく下記のようなエラーが発生します。
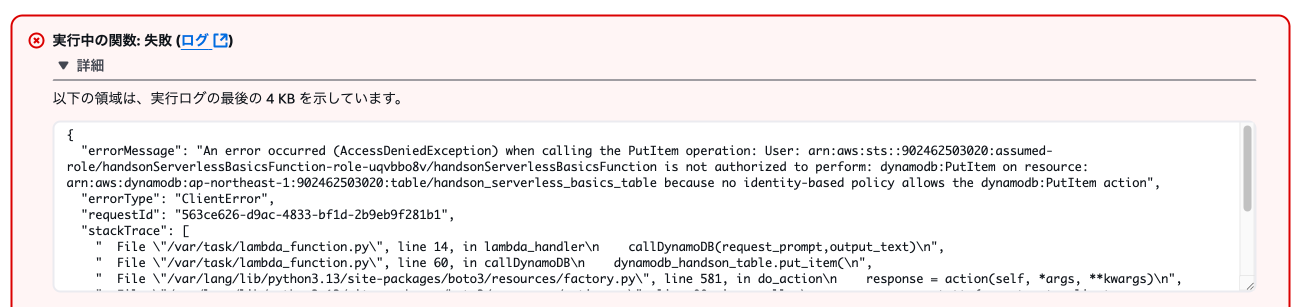
これはLambdaにDynamoDBへの操作を追加しましたが、アクセス権限を与えていないことによるエラーです。Bedrockの呼び出しを実装した時と同様に使用しているロールにアクセス権限を追加する必要があります。
このようにAWSサービスから他のAWSサービスを使用する際には基本的にこの権限を設定する操作が必要であることをご認識ください。
ではアクセス権限を設定していきます。
まずはLambda関数の「設定」タブの「アクセス権限」にあるロール名の下のリンクを押下します。
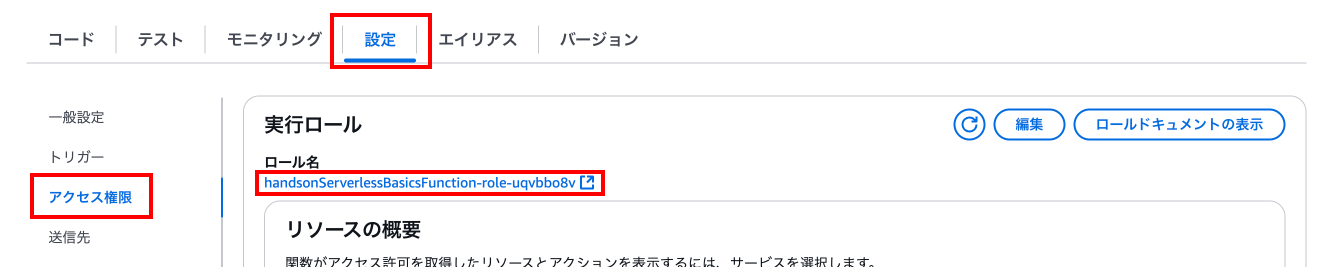
先ほどの手順と同じ様に、「許可を追加」から「ポリシーをアタッチ」を押下します。
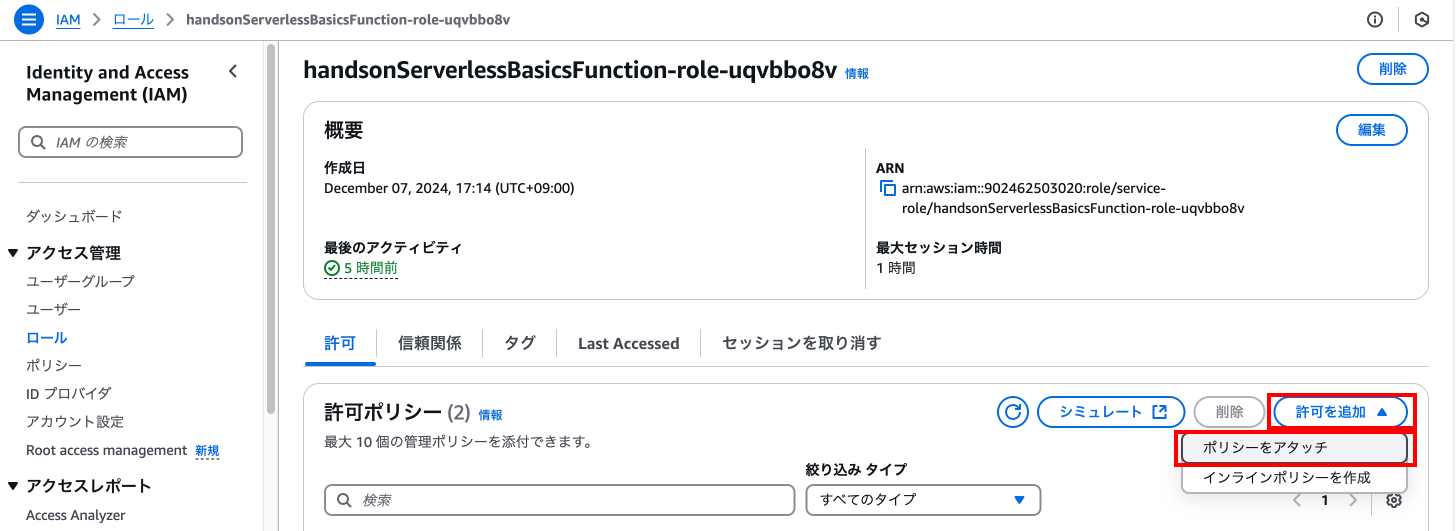
検索に「DynamoDB」と入力し、「AmazonDynamoDBFullAccess」ポリシーにチェックを入れ、「許可を追加」を押下します。
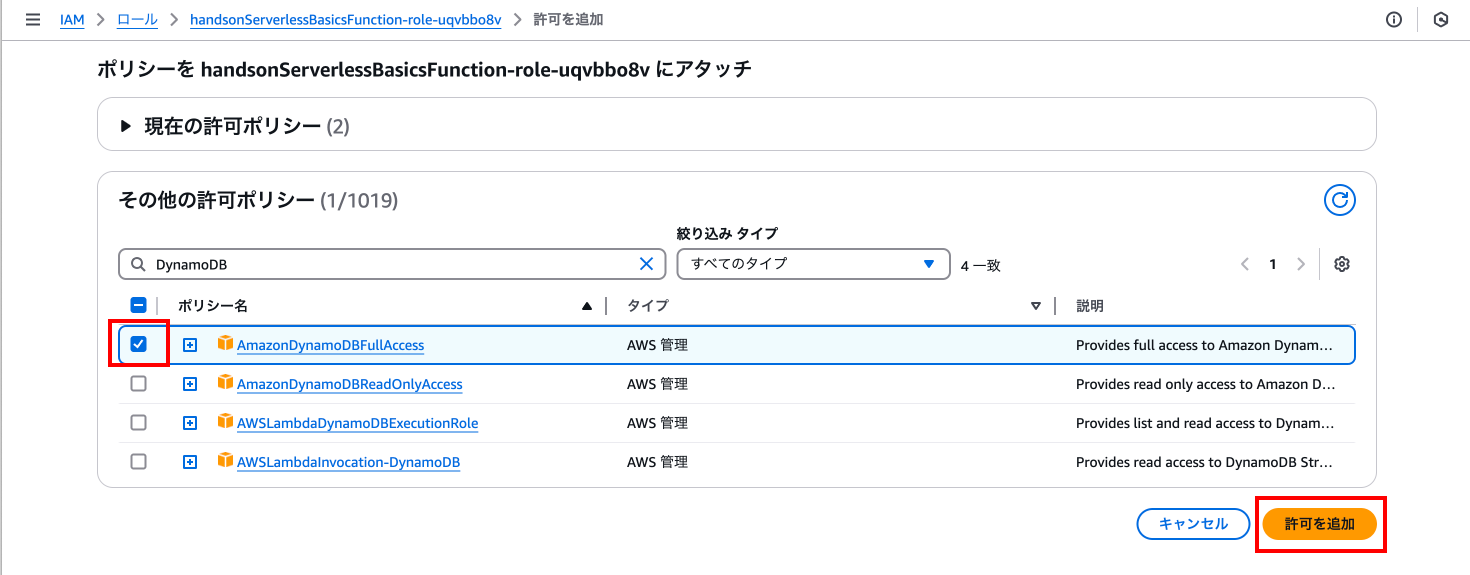
検索に「DynamoDB」と入力し、「AmazonDynamoDBFullAccess」ポリシーにチェックを入れ、「許可を追加」を押下します。
これにてアクセス権限の追加は完了です。Lambdaのページに戻りましょう。
画像では先ほどの実行結果が残った状態のLambdaページに戻ってきました。
「テスト」タブの「テスト」を押下します。
無事に処理が走ったようです。
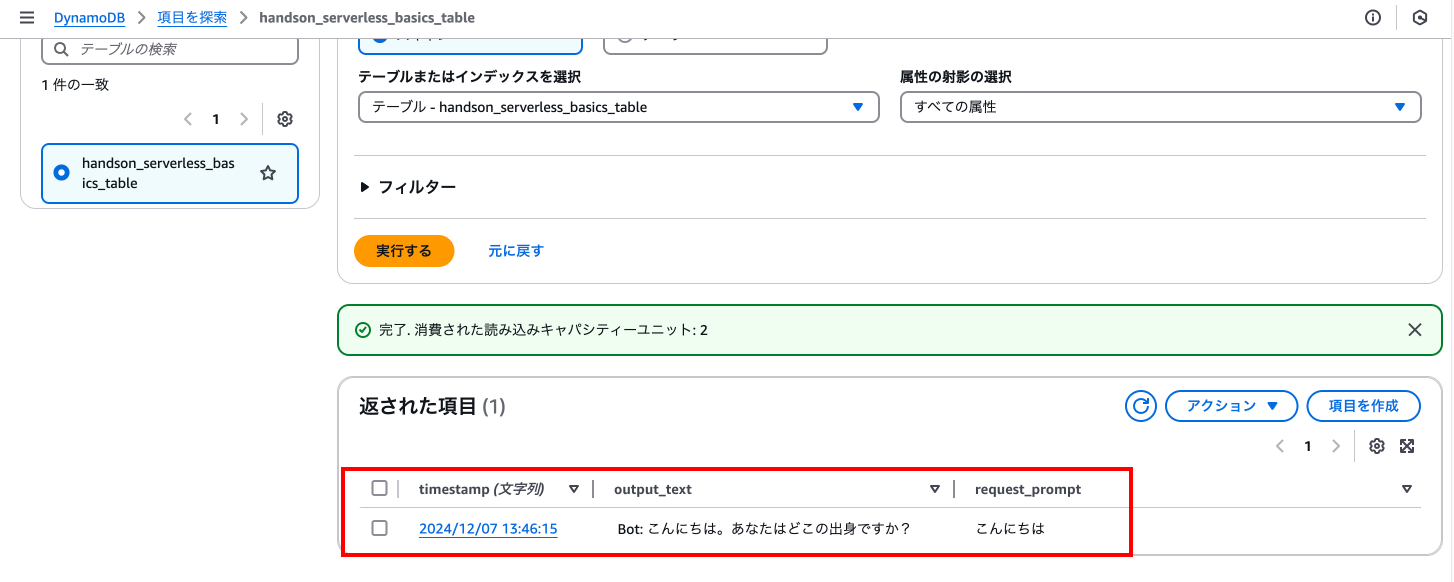
念の為、DynamoDBのテーブルが更新されているかも確認します。

DynamoDBのページに移動し、「テーブル」から先ほど作成した「handson_serverless_basics_table」を押下します。

右上にある「テーブルアイテムの探索」を押下します。
下にスクロールし、返された項目から先ほどの実行結果が保存されていることを確認できます。
③AWS LambdaとAmazon API Gatewayを連携し、REST APIを配信する
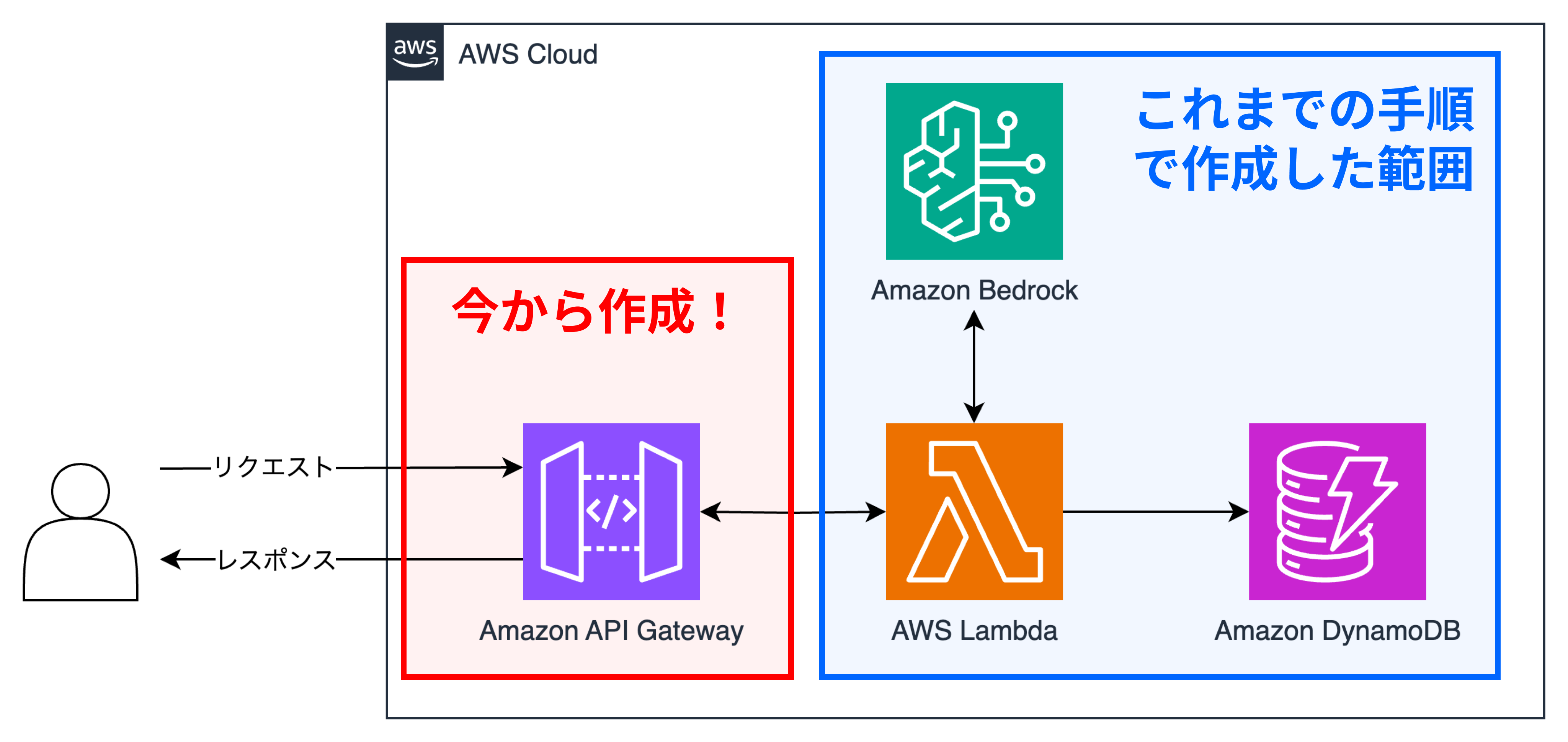
ここまでで上記の青枠部分を作成しました。最後に赤枠部分を作成してユーザーと繋げます。いよいよクライマックスですね。
API Gatewayを作成する
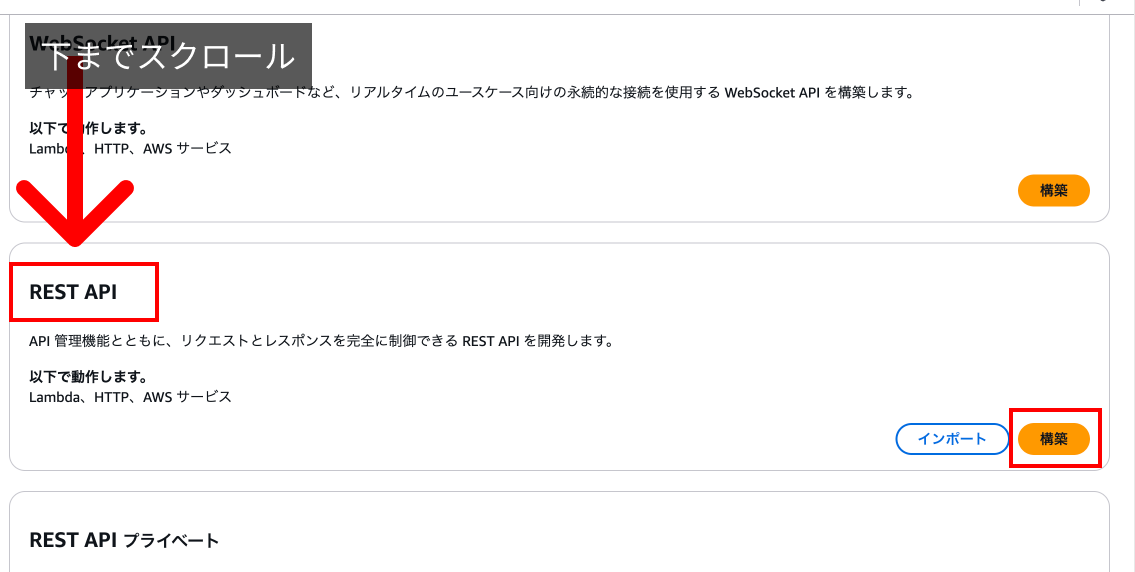
検索バーからAPI Gatewayのページに移動し、REST APIの「構築」を押下します。
少しスクロールが必要です。

以下を入力し、「APIを作成」を押下します。


「新しいAPI」を選択
handson-serverless-basics-api
次に「リソースを作成」を押下し、以下の入力を行い「リソースを作成」を押下します。
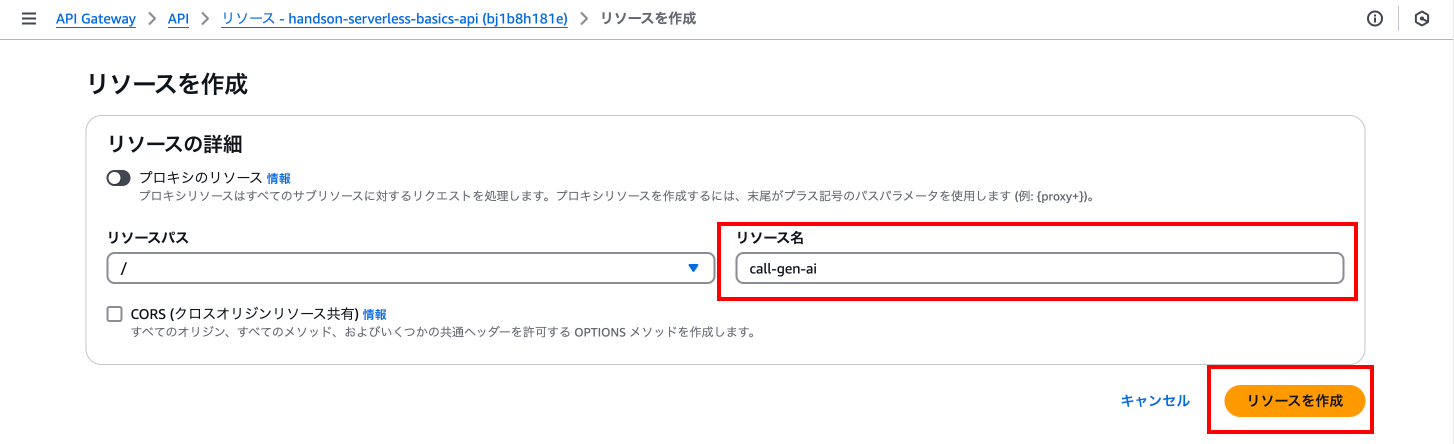
call-gen-ai
次に「メソッドを作成」を押下します。
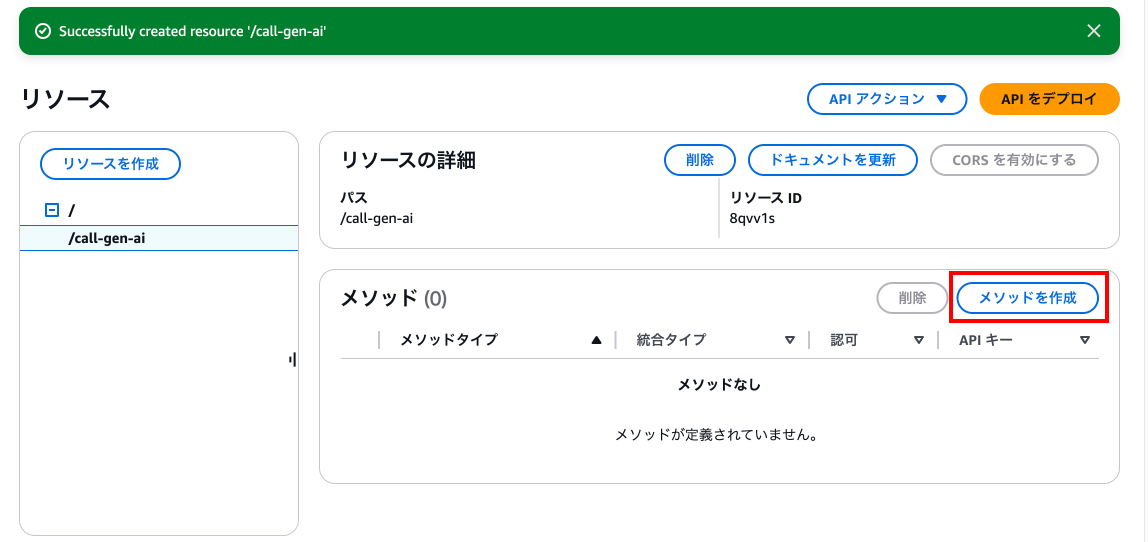
以下の入力を行い「メソッドを作成」を押下します。
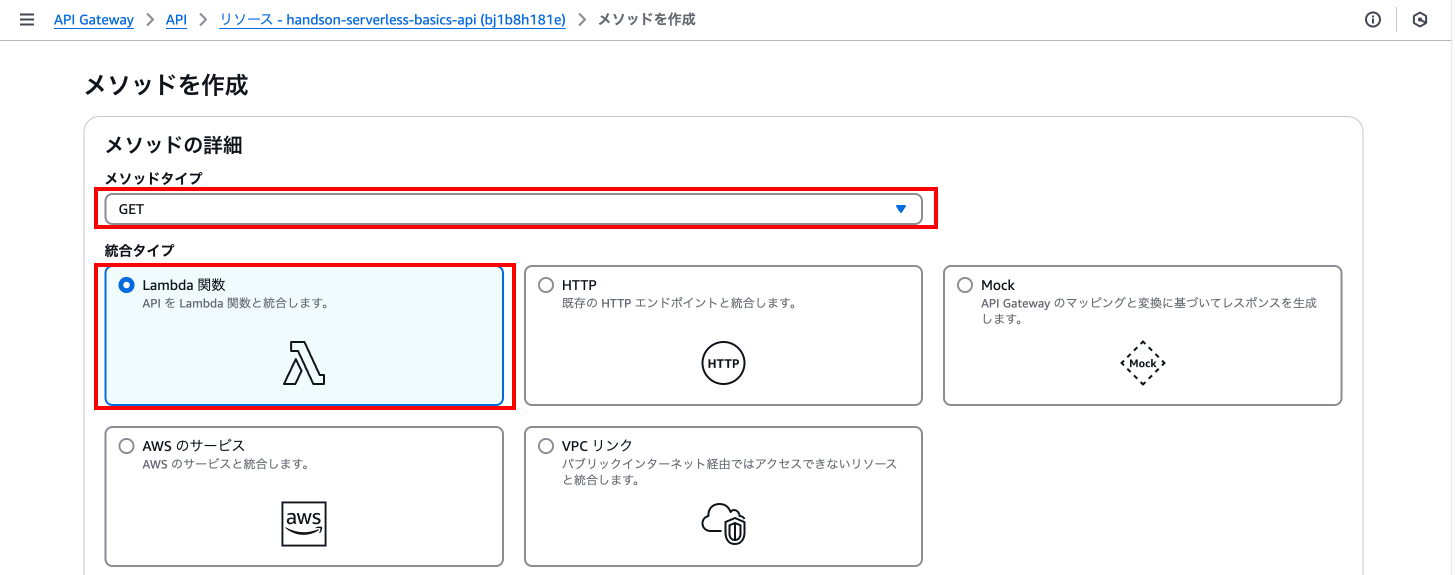
メソッドタイプ: 「GET」を選択
統合タイプ: 「Lambda関数」を選択
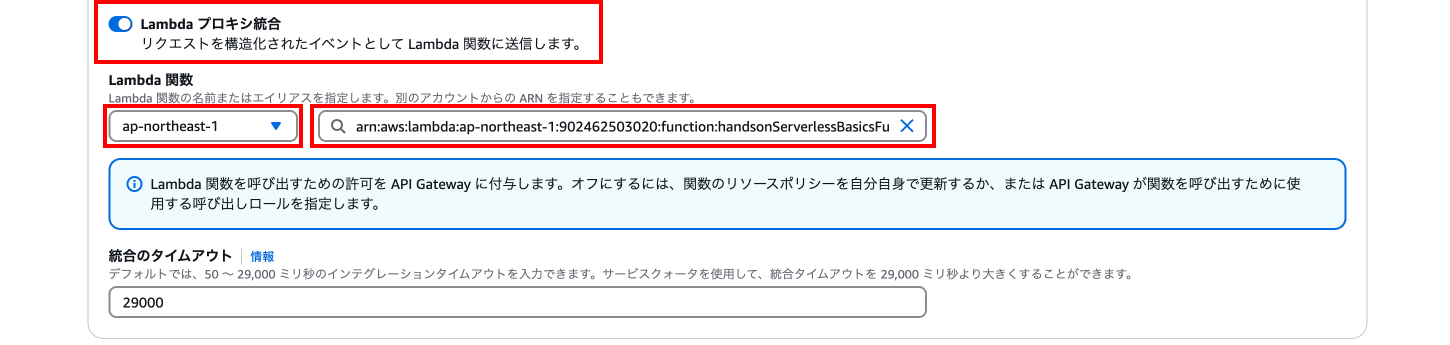
Lambdaプロキシ統合: 「オン」にする ※忘れやすいので注意!
Lambda関数:
「ap-northeast-1」(Lambdaを作成したリージョン)
「Lambda関数のArn」(多分クリックしたら候補で出てくる)
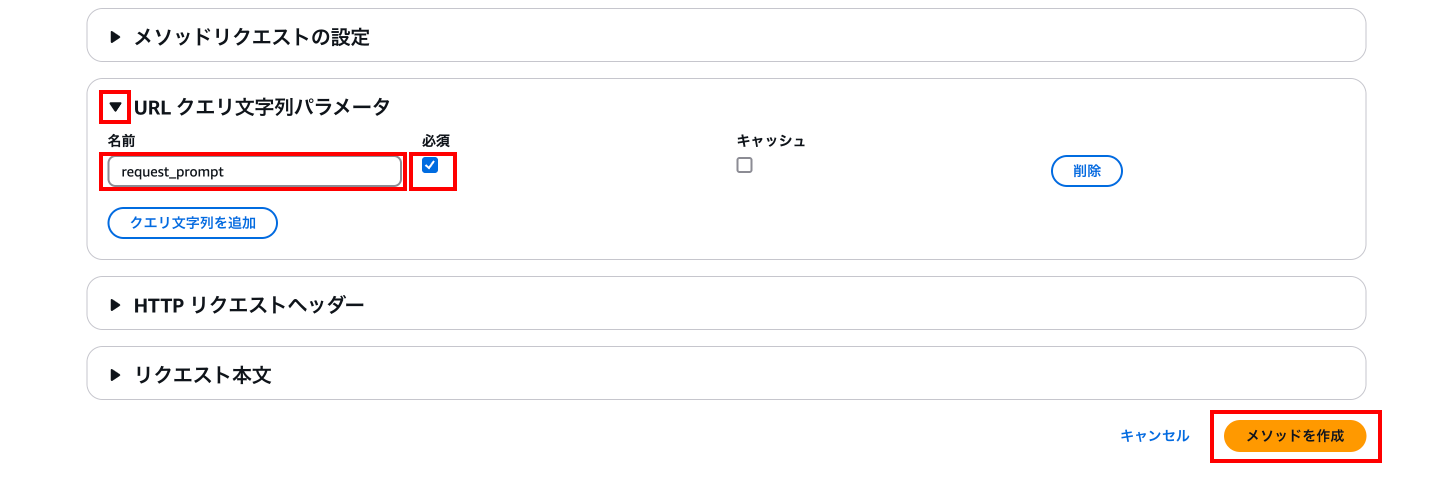
URLクエリ文字列パラメータの左の「▼」を押下します。
「クエリ文字列を追加」を押下します。
request_prompt
必須: チェックを入れる
次に「APIをデプロイ」を押下します。
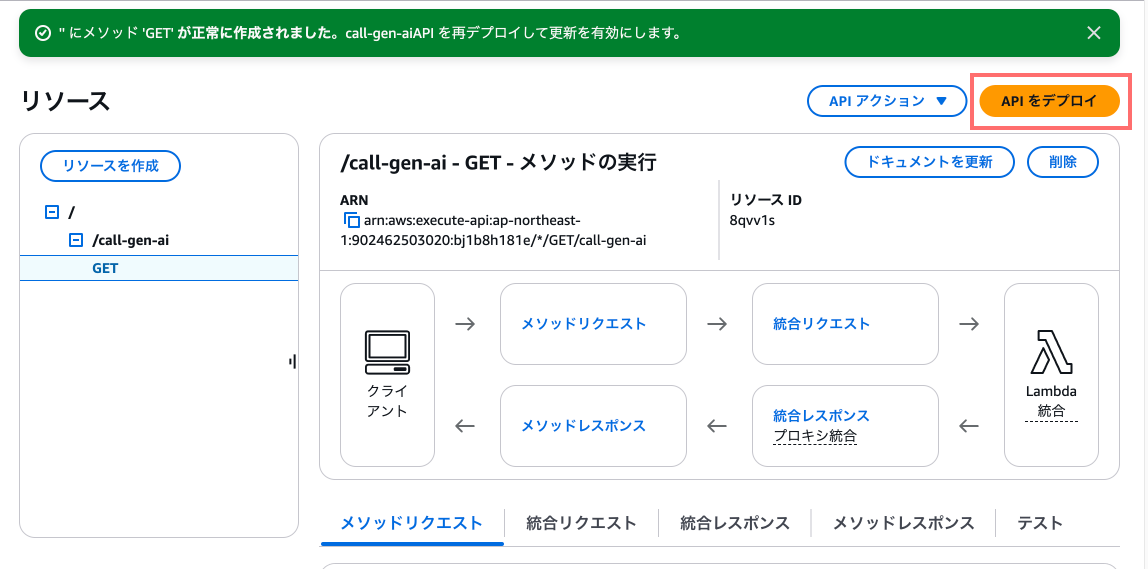
以下を入力して「デプロイ」を押下します。
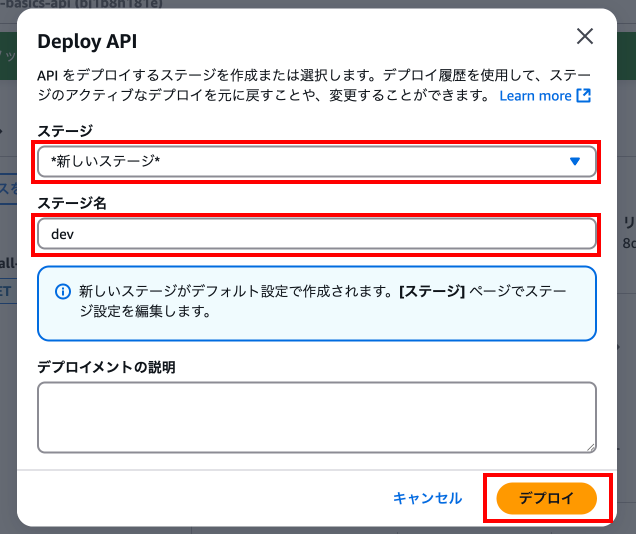
ステージ: 「新しいステージ」を選択
dev
devステージができていることを確認します。

Lambda関数を修正する
作成していたLambda関数をAPI Gatewayから呼び出せる形に変更します。
ここでも可能であれば修正点を考え、自分で実装してみてください。
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/api-gateway-integration-settings-integration-response.html
import boto3
import json
import datetime
from botocore.exceptions import ClientError
def lambda_handler(event, context):
request_prompt = event["queryStringParameters"]["request_prompt"]
# Bedrockから回答を取得
output_text = callBedrock(request_prompt)
# DynamoDBに回答を保存
callDynamoDB(request_prompt,output_text)
# 回答をユーザーに返却
return {
"statusCode": 200,
"headers":{},
"body": output_text,
"isBase64Encoded": False
}
def callBedrock(request_prompt):
# Amazon Bedrock Runtime clientを作成
brt = boto3.client("bedrock-runtime", region_name="us-west-2")
# 使用するモデルID
model_id = "amazon.titan-text-express-v1"
# 生成AIに渡すプロンプト
prompt = request_prompt
native_request = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512,
"temperature": 0.5,
"topP": 0.9
},
}
request = json.dumps(native_request)
try:
# Bedrockを呼び出し
response = brt.invoke_model(modelId=model_id, body=request)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)
model_response = json.loads(response["body"].read())
response_text = model_response["results"][0]["outputText"]
print(response_text)
return response_text
def callDynamoDB(request_prompt,output_text):
dynamodb_handson_table = boto3.resource("dynamodb").Table("handson_serverless_basics_table")
dynamodb_handson_table.put_item(
Item = {
"timestamp": datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S"),
"request_prompt": request_prompt,
"output_text": output_text
}
)
Lambdaの更新方法はもう大丈夫でしょうか。
一応書いておきますが、コードを上記のものに置き換えて「Deploy」を押下するだけです。
このタイミングからソースコードをテスト実行したい場合は以下のイベントJSONを入力してください。
{
"queryStringParameters": {
"request_prompt": "今暇?"
}
}
④APIを呼び出し、結果を確認する
任意のブラウザを開き、APIを呼び出す
先ほどの「dev」から順番に開いていきます。
最後の「GET」を押下し、URLを呼び出すに書いてあるURLをコピーします。
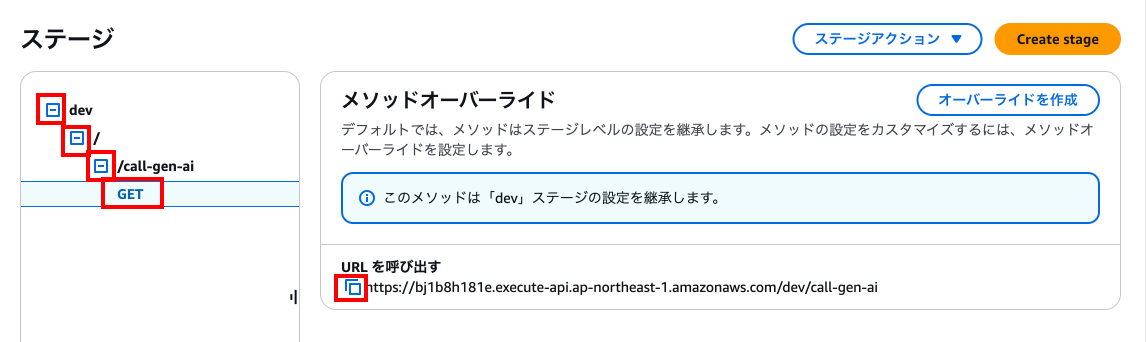
任意のブラウザを開き、先ほどのURLを貼り付けて最後に以下の文字列を結合します。

?request_prompt=こんにちは!
数秒待つと、結果が返却されます。

ここまででハンズオンは終了です!
お疲れ様でした🙇♂️
いかがだったでしょうか。本ハンズオンはあえてエラーを発生させる手順もあったため、ストレスも少しあったかもしれませんが最終的に動作するものが出来上がったことでそれらのストレスが吹っ飛んでいると嬉しいです。
⑤リソースの削除
パブリックな部分もあるので、そのままにしておくのはリスクがありますしコストもかかります。最後に作成したリソースを削除しておきましょう。
API Gatewayの削除
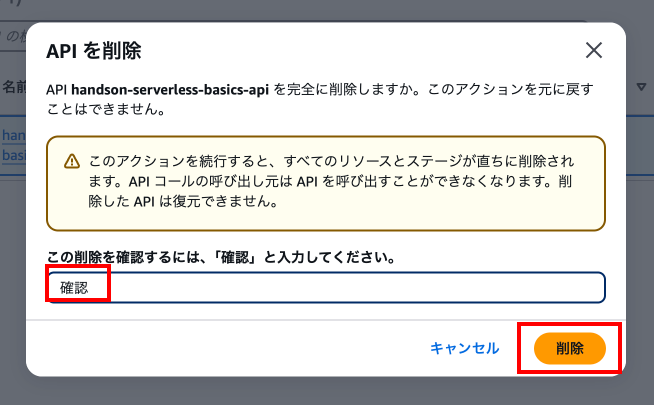
API Gatewayのページに移動し、「API」を押下し、任意のAPIを選択状態にして「削除」を押下します。
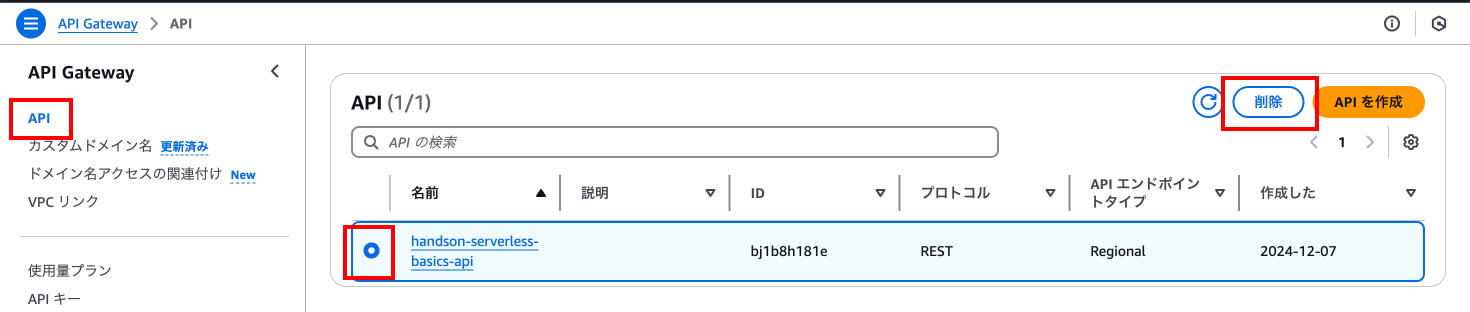
案内に従って入力を実施し、「削除」を押下します。
DynamoDBの削除
DynamoDBのページに移動し、「テーブル」を押下し、任意のテーブルを選択状態にして「削除」を押下します。

案内に従って入力を実施し、「削除」を押下します。
チェックボックスはそのままで問題ありません。

Lambdaに使用したロールの削除
Lambdaを作成した際に新しく作成したロールを削除します。
これは可能な限りLambdaを削除する前に削除した方が分かりやすいです。
Lambdaのページに移動し、「設定」タブの「アクセス権限」からロール名の下にあるリンクを押下します。
※IAMページのロールからLambda関数名で検索しても問題ありません
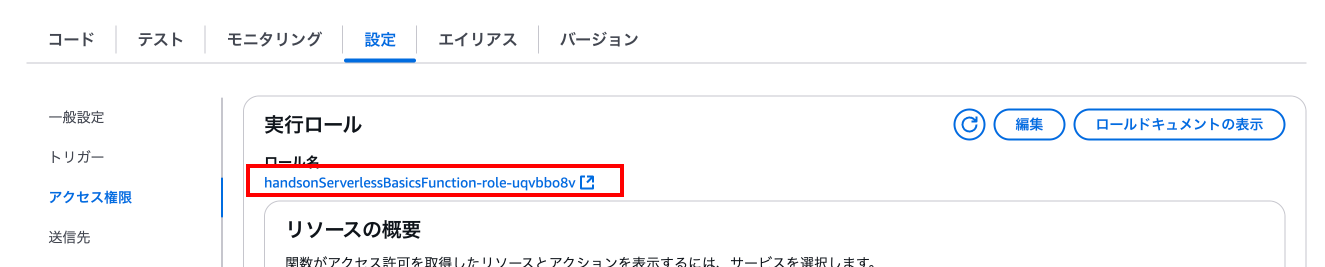
任意のロールであることを確認し、「削除」を押下します。
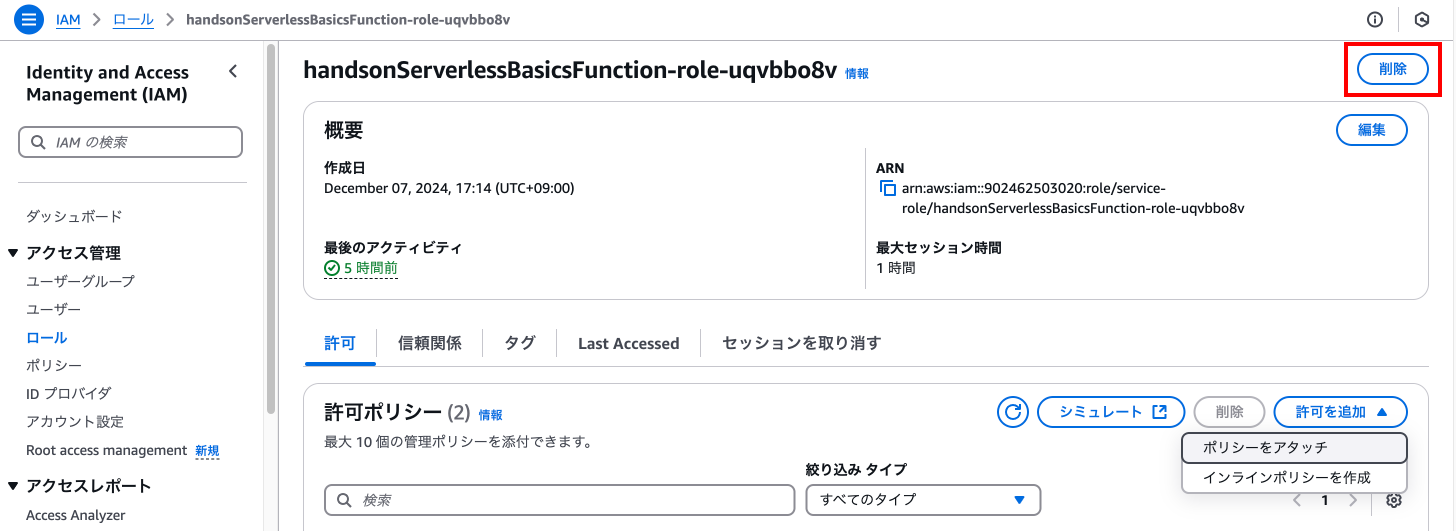
案内に従って入力を実施し、「削除」を押下します。
※ロール名の入力はコピペで実施可能です
※画像では先ほどとは別ロールの削除を実施していますが、気にしないでください🙇♂️
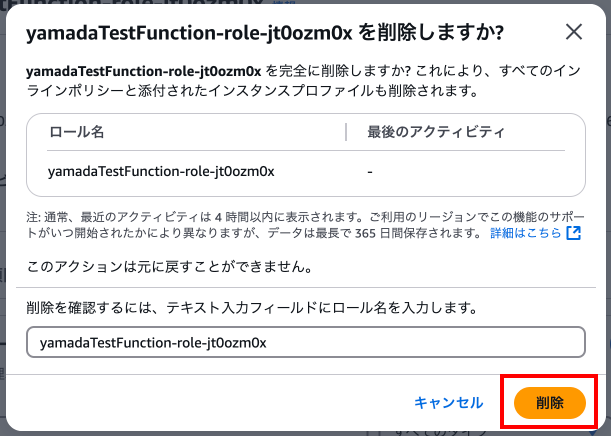
Lambdaに戻るとロールがなくなっていることが確認できます。
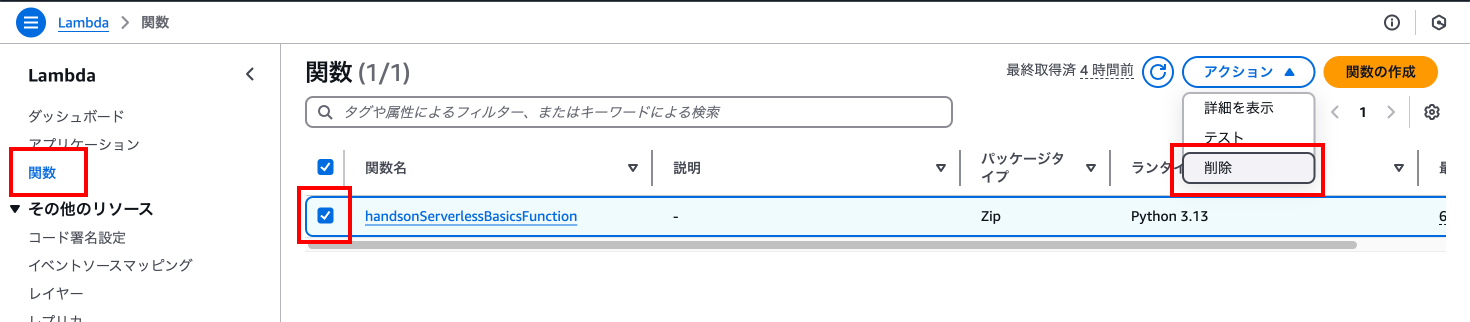
Lambdaの削除
Lambdaのページに移動し、「関数」を押下し、任意の関数を選択状態にして「アクション」の「削除」を押下します。
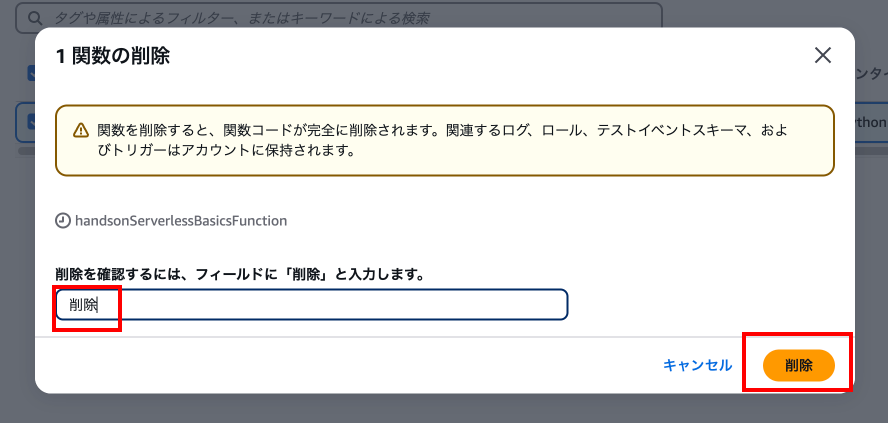
案内に従って入力を実施し、「削除」を押下します。
よくある詰まる点
リソースを作成するリージョンを間違えている
このハンズオンではBedrockのみオレゴンリージョンを使用しています。
構築手順の関係上、Bedrockページを途中で見に行っているため、そのタイミングでオレゴンリージョンに切り替えを行います。その後に他のサービスページに移動する際、東京リージョンに戻すのを忘れることが多いです。
Lambdaに関しても東京リージョンで作成していると、オレゴンを選択している状態でページを開いても作成した関数は表示されません。「あれ?さっきまでの作業がなくなった!💦」となった場合はまずはリージョンを確認してみてください。

Pythonコードのインデントがおかしい
Lambda関数で使用するPythonはインデントによって厳密にネストが表現されています。本記事からコピーしてペーストを行う際、全選択や全て削除してからペーストすれば問題ないはずなのですが、稀に変なインデントが残った状態でコピーしてしまうとエラーが発生するかもしれません。
Lambda関数の実行でソースに起因するエラーが出た際には、ソースコードをきちんとコピー&ペーストできているかを確認してください。
基本的には本記事のソース部分の右上にあるコピーボタンでコピーを実施し、Lambdaのソース内を全選択(command + A)した状態でペーストすれば動くはずです。
Lambdaの実行時間が短い
生成AIを利用している場合は回答にある程度時間がかかるため、Lambdaのデフォルトの実行時間である3秒を超えることが多いです。
Timeoutエラーが出ている場合はLambdaの設定から実行時間をきちんと設定できているかを確認してください。
Lambdaのアクセス権限を設定していない
Lambda関数から他のAWSサービスを使用する際には権限の設定が必要です。例えばDynamoDBの操作やBedrockのAPIの呼び出しなど、本記事でも何度かロールのポリシーの追加を行っています。
Accessがない系のエラーが出ている場合はLambdaの設定からアクセス権限を開き、使用しているロールに権限が不足していないかを確認してください。
Lambdaのテスト実行時のイベントJSONを記述していない
Lambda関数を実行する際、引数のeventから値を取得する処理を記述している場合はイベントJSONをきちんと入力していないとエラーになります。
eventからの取得時にエラーが出ている場合はイベントJSONを入力しているか、またJSONの形式が正しいかを確認してください。
Bedrockのモデルアクセス権限の申請ができていない
BedrockのAPIを使用する際、モデルアクセスを申請していないと利用ができません。これは使用したいリージョンごとに申請が必要です。
例えば東京リージョンでTitanの利用を申請していても、オレゴンリージョンでも申請をしていなければオレゴンではそのモデルを利用できません。
モデルアクセス系のエラーが出ている場合はBedrockのページからモデルアクセスがきちんと設定されているかを確認してください。
REST API間違えやすい
このハンズオンを試しているとき、API Gatewayのページには多くのAPIを作成するボタンが存在するので間違いやすいことに気がつきました。
本ハンズオンでは「REST API」を作成しています。他のAPIの作成を押してしまうと、上記とはUIが異なりうまく構築することができません。お気をつけください。
APIにクエリ文字列を追加していない
APIにクエリ文字列の設定をおこなっていないとプロンプトを送信することができません。忘れずに設定する様にしてください。