はじめに
長い間、SEなんて職業をしていると、正規化したデータ設計を無意識のうちにやってしまう癖がついてしまっています。ほとんど病気ですね。
あらためて正規化する意味をCopilotに聞いてみたところ、次のような回答がありました。
データを正規化する目的は、データベースの効率性と整合性を向上させることです。具体的には、以下のような利点があります:
データの重複を排除 : 同じデータが複数の場所に保存されることを防ぎます。
データの整合性を保つ :データの一貫性を確保し、更新や削除の際に矛盾が生じないようにします。
クエリの効率化 :データの検索や操作が効率的になり、パフォーマンスが向上します。
ストレージの節約 :不要なデータの重複を排除することで、ストレージの使用量を減らします。
データベースの設計において、正規化は非常に重要なステップです。
なるほど、なるほど...このような重要なステップを無意識のうちにやってしまうようになった私を褒めてやりたいと思います。![]()
ところがです...
正規化したデータは、マリアージュしてやらないと使えないわけです。
ん? Power Automateでどうやってマージするんだ?![]()
データの確認
なにはともあれ、まずはデータの確認と欲しい結果を想像するところからはじめます。
元データ
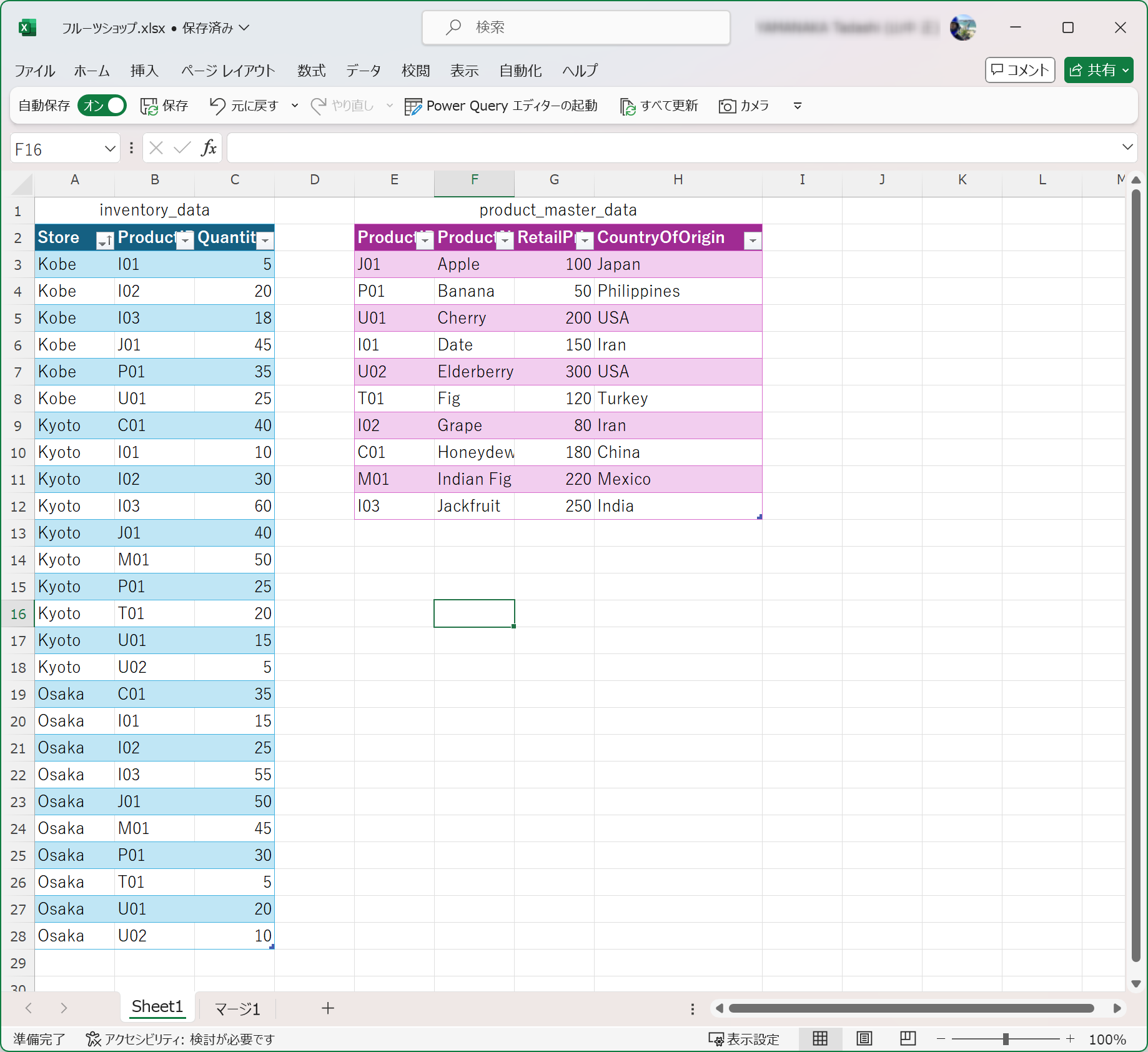
このように、店舗ごとの商品別在庫数と商品マスターのデータがあるとします。
商品マスターには、商品ID、商品名、小売価格、原産国の項目があります。
欲しいデータ
欲しいデータのイメージは、次のとおりです。
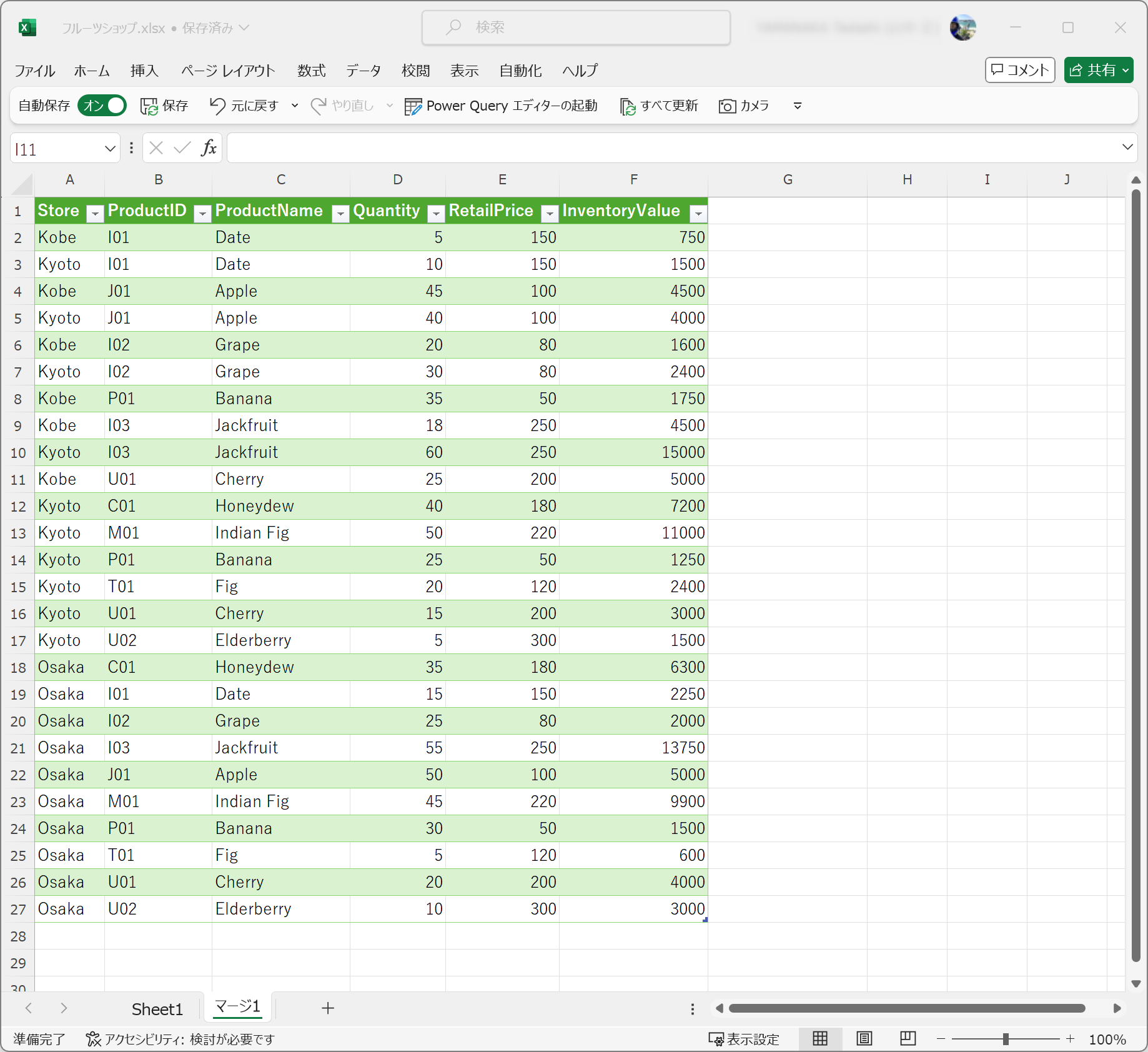
店舗それぞれの在庫と数量と小売価格を乗算した金額がありますが、原産国は不要です。
おまけ...
当然、Power Queryを使うとこの程度のことなら瞬殺できる内容ですね。
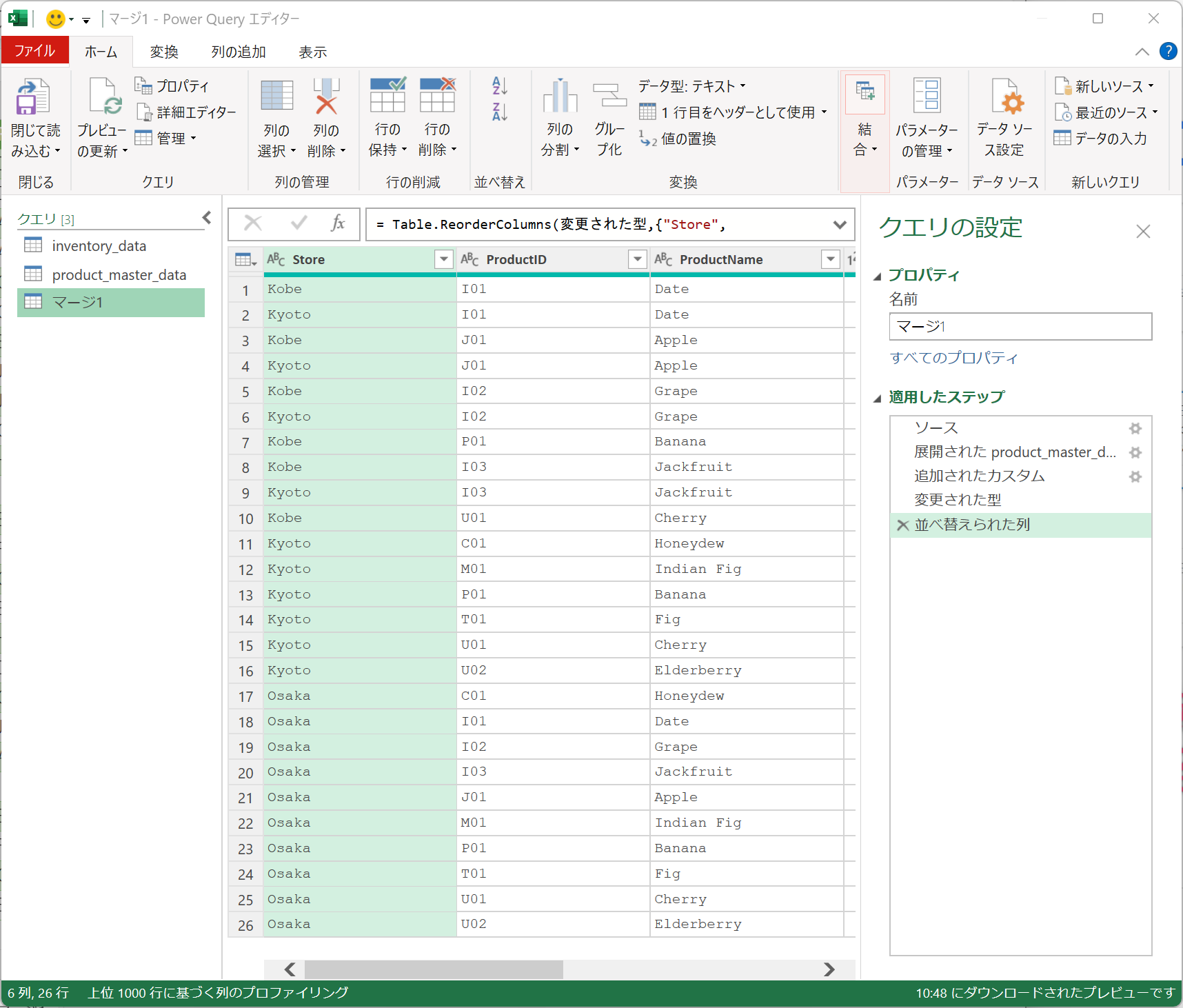
それぞれのデータを読み込ませたら、たったこれだけのステップで完成してしまいます。
Power Automateでの実現方法 (ダメなやり方)
まずは誰でも思いつきそうなダメなやり方から見ていきましょう。
在庫データの取得
普通に考えるとまず、まずは在庫データを取得しますよね。
こんなカタチになるかと思います。
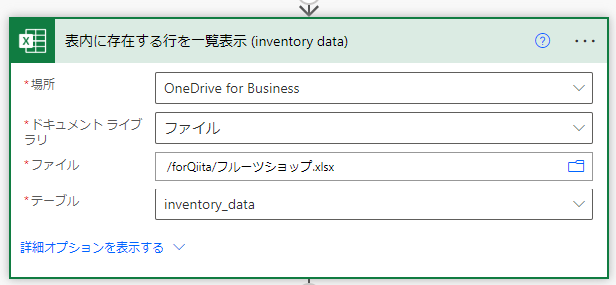
在庫データの商品IDをキーにマスターを検索
行の取得アクションを追加し、キー列にProductID、そして、キー値は、在庫データのProductID列を指定します。
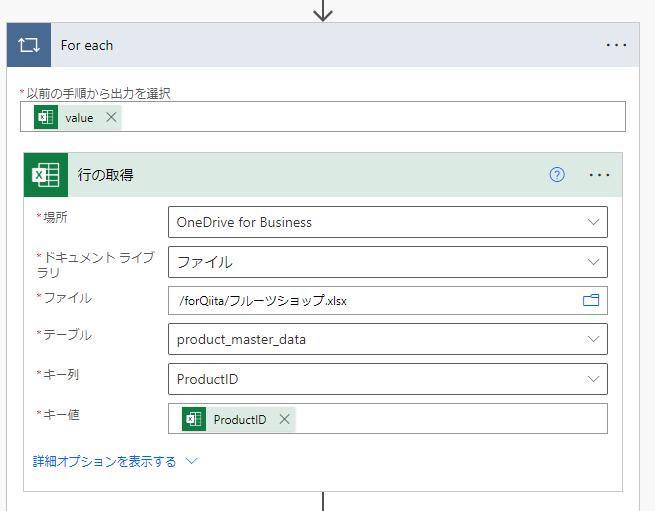
すると、在庫データは複数件取得できているため、一件づつ処理するために、Apply to each(For each)で囲まれてしまいます。
取得したデータのマッピング
ここで、在庫のデータとマスターの値をマッピングしてやらなければなりませんが、Apply to eachの中で1件づつマッピングしたものを配列変数に貯めて行く必要があります。
そこで、1件づつのデータがJson型なので、それを解析し、さらに自分でJson型のデータを作成して、配列に追加してやるわけです。
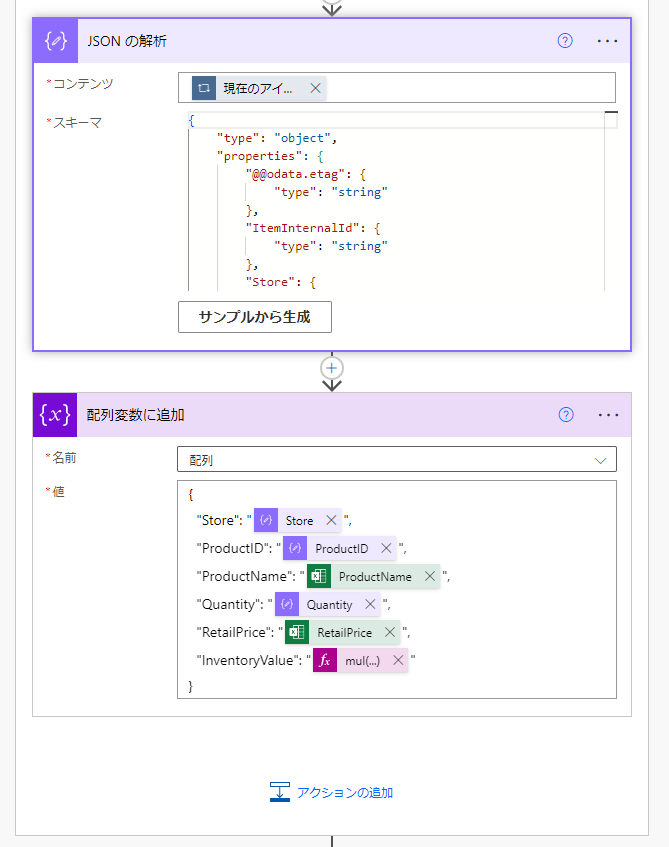
もちろん、配列という名前の変数は事前に初期化しておく必要があります。
これで、無事、在庫データと商品マスターがマリアージュされました。
めでたしめでたし。
最後にデータの確認
結果を確認するために配列変数の値からHTMLテーブルを作成しておきましょう。
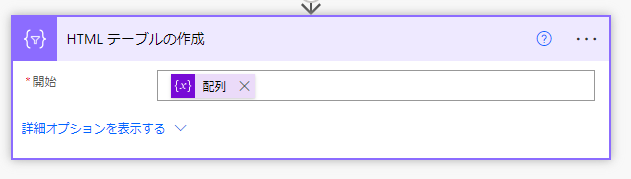
完成
全体のフローを確認しておきましょう。
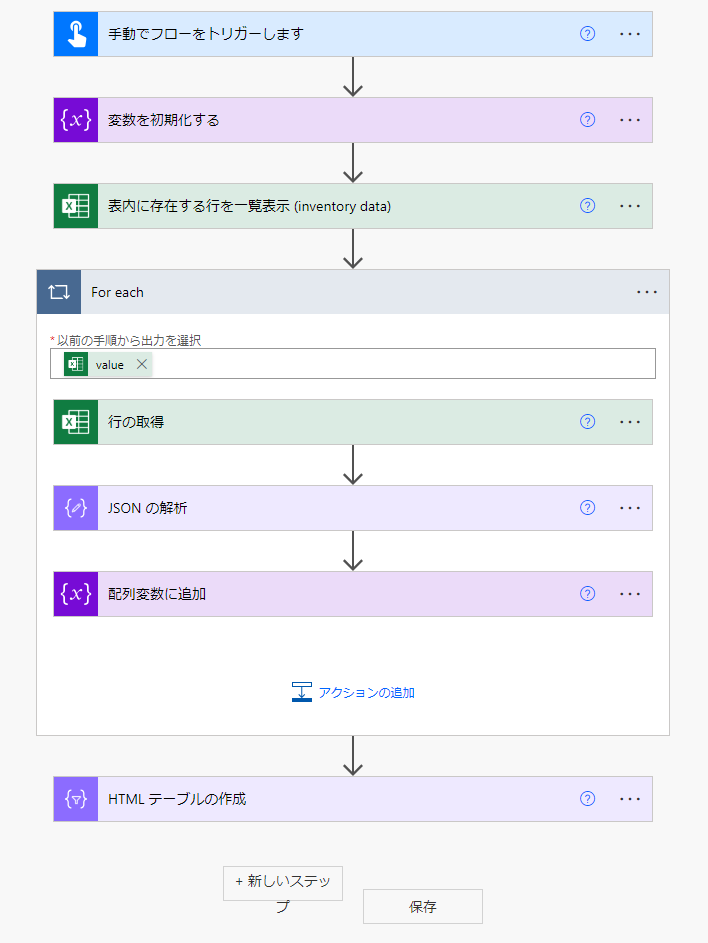
このような処理になりました。
実行してみます。

はい。期待通りのデータを作成することができました。
でも、実行時間が...
For eachのところで時間が23秒となっています。
より詳細な実行時間を確認するため、新しいデザイナーに切り替えて見ましょう。
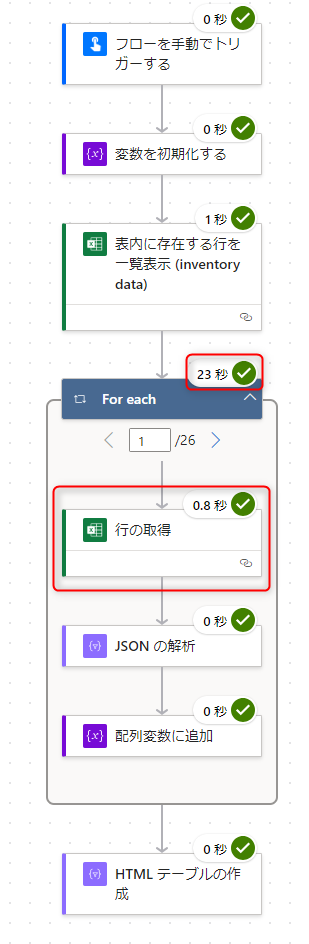
在庫データ1件処理するのに、だいたい0.6~0.8秒かかっています。
合計処理時間は25秒になっていました。
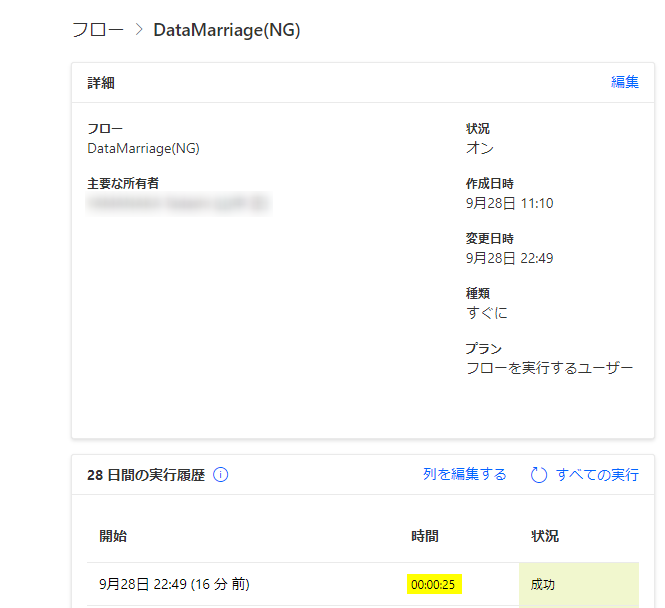
今回の在庫データは、3店舗あわせて26件だったので、合計すると23秒かかったということになります。
処理結果自体は正しく出来ていたとしても今後、店舗が増え在庫のアイテム数が増えていくとさらに多くの時間が必要となってきます。
そして、今回は在庫の金額でしたが、売上データで、顧客マスターと商品マスターを2つ結合するような処理が必要になったら、もっと時間がかかってしまいそうです。
そして、Power Automateの契約プランに寄るのですが、1日に実行できるアクション数の制限もあります。
したがって、Apply to eachの中で複数のアクションを回すというのはフローとしては良くない処理と言えるかと思います。
To be Continued
スミマセン。今回の文書もずいぶん長くなってしまったようです。
ですが、同じ件数をたったの1秒以下で出来る処理が作れるとしたら、どうですか?
興味を持ちませんか?
大げさなことを言っているのではありません。次の結果を見てください。
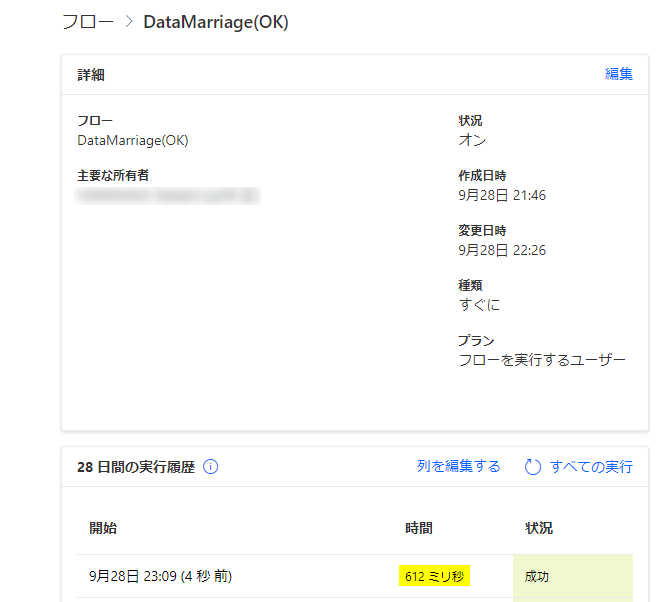
次回、後編では、この画期的な方法をご紹介したいと思います。
お楽しみに...