目次
1 . 本記事の最終目標
2 . 実施手順
3 . 結論
4 . 感想
実行環境
・Python3.10.12
・Google Colaboratory
1.本記事の最終目標
この記事では、ビジネスリーダーが直面する日々の課題に対処するためのデータ駆動型アプローチを探求します。具体的には、Pythonを用いた自然言語処理技術を活用し、YouTubeのタイトルを分析することで、日本経済の動向を洞察し、ビジネスマンとしての洗練された見識を磨くことを目指します。また、このプロセスを通じて、現代ビジネスにおけるデータ分析の重要性と効果的な活用法を明らかにし、読者の皆様がより戦略的な意思決定を行えるようサポートします。なお、このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。
データ駆動型アプローチ(Data-Driven Approach)とは、決定、プロセス、または企画を行う際に、直感や経験だけでなく、客観的なデータ分析を重視する方法です。
2.実施手順
⑴ Youtube Data API keyを取得する
|
⑵ タイトルに関連するデータを日別で取得する
|
⑶ 取得したデータを統合する
|
⑷ 形態素解析にてキーワードを抽出する
|
⑸ 感情分析にて3種類のラベルを付与する
|
⑹ ワードクラウド
|
⑺ 共起ネットワーク
|
⑻ Stratified histogram by category_seaborn
⑴ Youtube Data API keyを取得する
Google Cloud Platformにアクセスし、Youtube Data API keyを取得します。
※本記事の目的とは関連性が低い為、APIkeyの取得方法は割愛させて頂きます。
⑵ タイトルに関連するデータを日別で取得する
取得したYoutube Data API keyを使用し、以下の条件でタイトルに関連するデータを取得します。
ーーーーーーーーーーーーーーーーーーーーーーーーーー
(条件)
● 期間 : 2023年10月01日 〜 2023年10月31日
● キーワード : ”経済”
ーーーーーーーーーーーーーーーーーーーーーーーーーー
import pandas as pd
from googleapiclient.discovery import build
YOUTUBE_API_KEY = 'youtubeAPIkeyを入力する'
YOUTUBE_API_SERVICE_NAME = 'youtube'
YOUTUBE_API_VERSION = 'v3'
# 検索語
search_word = '経済'
youtube = build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey=YOUTUBE_API_KEY)
dic = {}
column = ['videoId', 'title', 'channelTitle', 'publishedAt']
i = 0
# videoDuration の値を medium と long でループ
for video_duration in ['medium', 'long']:
if i >= 1000: # 1000件以上でループを終了
break
nextPagetoken = None # 次の検索のためにリセット
while i < 1000:
search_response = youtube.search().list(
part='id,snippet',
maxResults=50,
pageToken=nextPagetoken,
publishedAfter='2023-10-01T00:00:00Z',
publishedBefore='2023-10-01T23:59:59Z',
q=search_word,
regionCode='JP',
type='video',
videoDuration=video_duration
).execute()
for search_result in search_response.get('items', []):
videoId = search_result['id']['videoId']
title = search_result['snippet']['title']
channelTitle = search_result['snippet']['channelTitle']
publishedAt = search_result['snippet']['publishedAt']
dic[i] = [videoId, title, channelTitle, publishedAt]
i += 1
try:
nextPagetoken = search_response['nextPageToken']
except:
break
df = pd.DataFrame.from_dict(dic, orient="index", columns=column)
print(df)
df.to_excel("output_wbc_20231001_20231001.xlsx") # xlsx出力
このコードは、YouTube APIを使用してキーワード ” 経済 ” に基づいたYouTubeタイトルの情報を収集し、それをExcelファイルに保存するためのものです。
pandasライブラリのインポート:
import pandas as pd はpandas はデータ操作と分析のためのライブラリです。
YouTube APIの設定:
googleapiclient.discovery はGoogle APIクライアントライブラリの一部で、GoogleのAPIを簡単に利用できるようにします。build 関数を使用してYouTube APIのクライアントを作成します。
また、YOUTUBE_API_KEY には、YouTube Data API v3を使用するためのAPIキーを設定します。YOUTUBE_API_SERVICE_NAME と YOUTUBE_API_VERSION は、利用するAPIの名前とバージョンを指定します。
検索語の設定:
search_word = '経済' はsearch_word にYouTubeで検索するためのキーワードを設定します。
データ収集のループ:
for ループを使用してビデオの持続時間('medium' と 'long')に基づいて検索を行います。
while ループを使用して、最大1000件のビデオ情報を収集します。
youtube.search().list() メソッドで検索を行い、指定された条件(検索語、地域コード、ビデオの種類、持続時間、公開日時など)に基づいてビデオ情報を取得します。なお、後悔日時は、都度目的の日時に変更します。
データの抽出と保存:
抽出された各ビデオの情報(ビデオID、タイトル、チャンネル名、公開日時)を dic という辞書に保存します。
pandas.DataFrame.from_dict を使用して辞書からデータフレームを作成し、これを print で表示します。
最後に、to_excel メソッドを使用してデータフレームを1日ずつExcelファイルに出力します。
上記を繰り返し2023年10月01日 〜 2023年10月31日全てのデータを入手します。
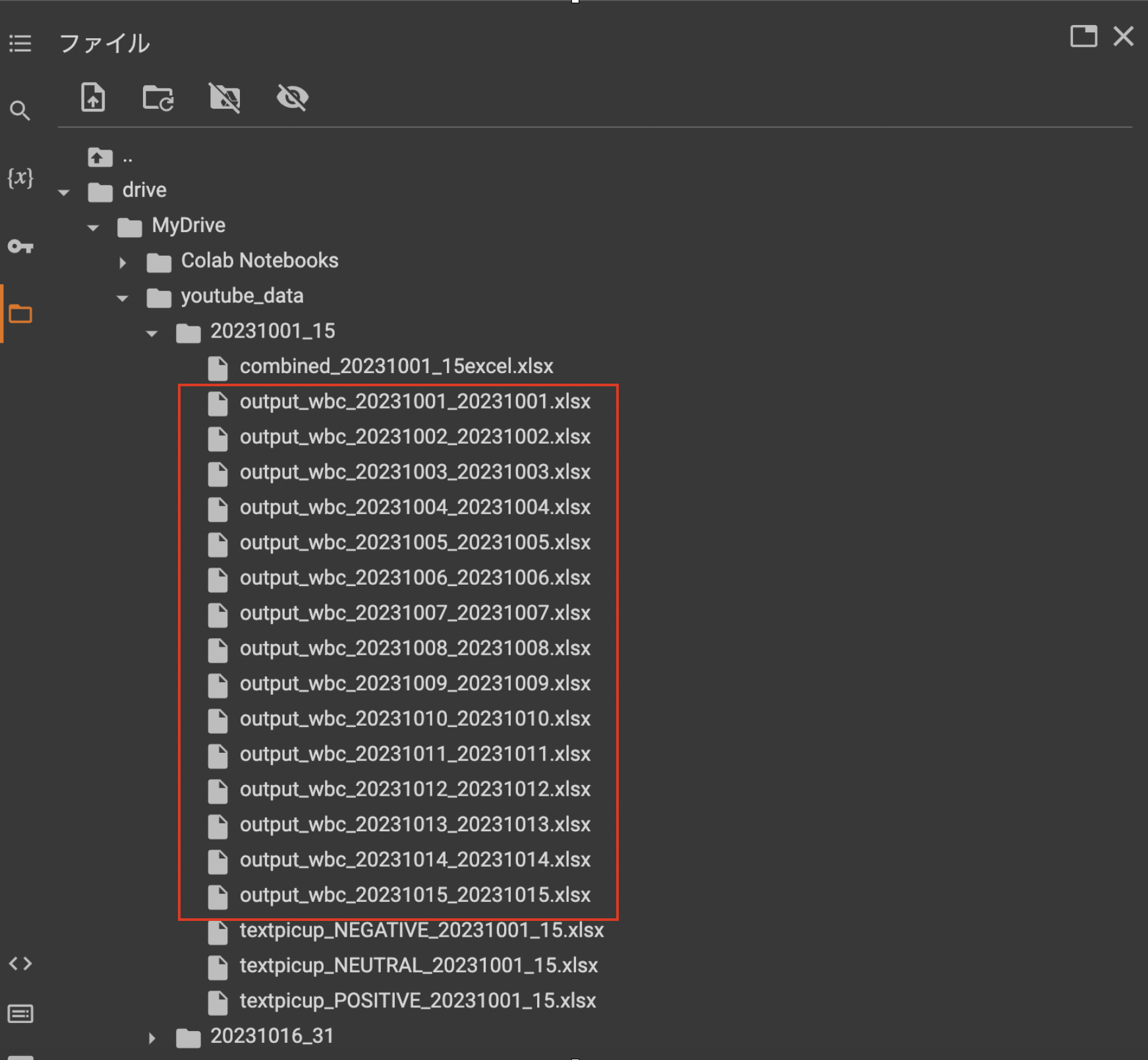
ファイル構成について
・ 'content/drive/MyDrive/youtube_data/20231001_15'
・ 'content/drive/MyDrive/youtube_data/20231016_31'
のフォルダをGoogleドライブに作成し、それぞれにExcelファイルを格納します。
以下のスクショを参考にして下さい。
⑶ 取得したデータを統合する
取得したExcelファイルをフォルダ毎に統合します。
import os
import pandas as pd
# フォルダのパスを設定します(Macのユーザー名に応じて変更してください)
folder_path = 'フォルダパス'
# フォルダ内の全Excelファイルのリストを取得します
excel_files = [file for file in os.listdir(folder_path) if file.endswith('.xlsx')]
# 空のDataFrameを初期化します
combined_df = pd.DataFrame()
# 各Excelファイルを読み込み、DataFrameに追加します
for file in excel_files:
file_path = os.path.join(folder_path, file)
df = pd.read_excel(file_path)
combined_df = combined_df.append(df, ignore_index=True)
# 結合したDataFrameを新しいExcelファイルに保存します
output_path = os.path.join(folder_path, '任意のファイル名.xlsx')
combined_df.to_excel(output_path, index=False)
print(f'All files have been combined into {output_path}')
このコードは、特定のフォルダ内の全てのExcelファイルを読み込み、それらを単一のDataFrameに結合して、新しいExcelファイルとして保存するためのものです。
OSライブラリのインポート:
os はファイルやディレクトリの操作に使用される標準ライブラリです。
pdpandas はデータ操作と分析に使用されるライブラリです。
フォルダパスの設定:
folder_path 変数に、読み込むExcelファイルが格納されているフォルダのパスを設定します。
Excelファイルリストの取得:
os.listdir() 関数を使用してフォルダ内のファイルのリストを取得します。
リスト内包表記を使用して、ファイル名が '.xlsx' で終わるファイル(Excelファイル)のみを excel_files リストに追加します。
各ファイルのデータの読み込みと結合:
空のDataFrame combined_df を初期化します。
for ループを使用して各Excelファイルを一つずつ処理します。ファイルパスを組み立て、pd.read_excel() を使用してファイルの内容をDataFrameとして読み込みます。
combined_df.append() を使用して、読み込んだDataFrameを combined_df に追加します。ignore_index=True により、インデックスがリセットされます。
結合されたDataFrameの保存:
output_path を設定して新しいExcelファイルの保存先を決定します。
combined_df.to_excel() を使用して結合されたデータをExcelファイルとして保存します。index=False は、インデックスをファイルに含めないことを意味します。
終了メッセージの表示:
print 関数を使用して、処理の完了と出力ファイルのパスを表示します。
このコードは、複数のExcelファイルからデータを集約し、それらを一つのファイルにまとめるためのものです。
(今回は統合したExcelファイルは以下となります。)
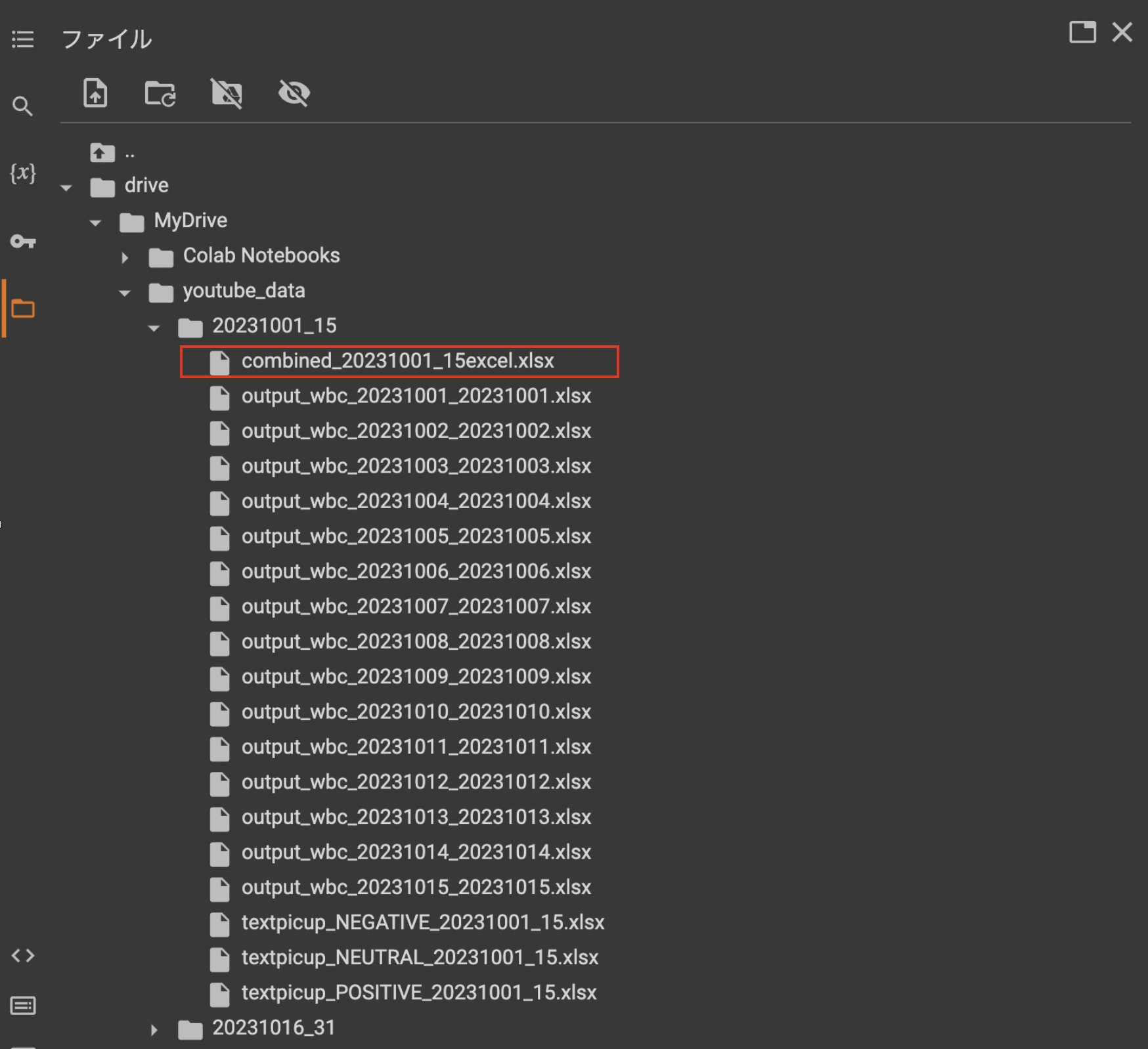
⑷ 形態素解析にてキーワードを抽出する
形態素解析に必要なMeCab辞書と極性辞書ののインストールを行います。
### MeCab辞書をインストール
!sudo apt install mecab
!sudo apt install libmecab-dev
!sudo apt install mecab-ipadic-utf8
### 辞書を使える場所に移す
!mv /etc/mecabrc /usr/local/etc/
# 極性辞書の取得
!wget http://www.lr.pi.titech.ac.jp/%7Etakamura/pubs/pn_ja.dic
### pipでインストール
!pip3 install mecab-python3
MeCabと関連パッケージのインストール:
!sudo apt install mecab はMeCab本体をインストールします。
!sudo apt install libmecab-dev はMeCabの開発に関連するライブラリ(libmecab)をインストールします。これは、MeCabをカスタマイズしたり、拡張したりする際に必要です。
!sudo apt install mecab-ipadic-utf8 はMeCab用の標準辞書であるIPAdicをUTF-8エンコーディングでインストールします。これは、日本語の形態素解析に必要な基本的な辞書データです。
辞書ファイルの移動:
!mv /etc/mecabrc /usr/local/etc/ はmecabrcファイル(MeCabの設定ファイル)を、MeCabがアクセス可能な場所に移動します。これにより、MeCabが正しく設定ファイルを読み込むことができるようになります。
極性辞書の取得:
!wget http://www.lr.pi.titech.ac.jp/%7Etakamura/pubs/pn_ja.dic は極性辞書(ポジティブやネガティブな単語が評価された辞書)をインターネットからダウンロードします。これは、テキストの感情分析などに利用されます。
mecab-python3のインストール:
!pip3 install mecab-python3 はPythonからMeCabを使用するためのライブラリである mecab-python3 をインストールします。これにより、Pythonプログラム内でMeCabの機能を利用できるようになります。
これらの手順を踏むことで、MeCabのセットアップが行われ、Pythonから日本語の形態素解析を行うことが可能になります。また、極性辞書を用いることで、テキストデータの感情分析などの高度な処理も実施できます。
!pip install mecab-python3
!pip install unidic
!python -m unidic download
MeCabとmecab-python3のインストール:
!pip install mecab-python3 は、PythonでMeCabを使用するためのライブラリである mecab-python3 をインストールします。MeCabは日本語の形態素解析器で、テキストを単語に分割し、各単語の品詞などの情報を提供します。
UniDicのインストール:
!pip install unidic は、UniDic(ユニバーサルデザイン辞書)をインストールします。UniDicは、MeCab用の辞書の一つで、日本語の形態素解析に適した豊富な語彙データを含んでいます。
UniDicのダウンロード:
!python -m unidic download は、インストールしたUniDicライブラリから必要な辞書ファイルをダウンロードします。これは、UniDicを使用する前に必要です。
これらを実行することで、Python環境にMeCabとUniDicがセットアップされ、日本語テキストの形態素解析が可能になります。
# ライブラリのインポート その1
import pandas as pd
import MeCab
Pandasのインポート:
import pandas as pd はPandasライブラリをインポートします。Pandasは、データ分析と操作のための非常に強力なライブラリであり、データフレーム(データを表形式で扱うことができる構造)を使用して、データの読み込み、処理、分析を簡単に行うことができます。
pd という短縮形を使用することで、コード内でPandas関数を簡単に呼び出すことができます(例:pd.DataFrame())。
MeCabのインポート:
import MeCab はMeCabライブラリをインポートします。
Pandasを使用してデータを管理し、MeCabを利用して日本語テキストの形態素解析を行うことで、データの洞察を得るための詳細な処理が可能になります。
# 辞書の場所を指定してMeCabを初期化
# tagger = MeCab.Tagger("-Ochasen")
print(tagger.parse("こんにちは、MeCabのテストです。"))
辞書の場所を指定してMeCabを初期化:
tagger = MeCab.Tagger("-Ochasen") により、MeCabのTaggerオブジェクトが作成されます。
形態素解析のテスト:
print(tagger.parse("こんにちは、MeCabのテストです。")) により、指定したテキスト("こんにちは、MeCabのテストです。")が形態素解析され、結果が出力されます。上記のコードでは、単語ごとに原形、読み、品詞などが行単位で出力されます。
このコードを実行すると、"こんにちは、MeCabのテストです。" という文がMeCabによって形態素解析され、各単語の基本形、品詞、読みなどが出力されます。
data = '/content/drive/MyDrive/youtube_data/20231001_15/combined_20231001_15excel.xlsx' # Excelファイルのパスを指定
df = pd.read_excel(data)
# キーワードの洗い出し(形態素解析)
def extract_keywords(text):
# 辞書ファイルへのパスを指定
tagger = MeCab.Tagger("-Ochasen")
nodes = tagger.parseToNode(text)
keywords = []
while nodes:
features = nodes.feature.split(',')
# 名詞だけを抽出
if features[0] == '名詞':
keywords.append(nodes.surface)
nodes = nodes.next
return keywords
# タイトルからキーワードを抽出
df['keyword'] = df['title'].apply(extract_keywords)
df
Excelファイルの読み込み:
pd.read_excel(data) で指定されたパスのExcelファイルをPandasのデータフレームに読み込みます。
キーワード抽出関数の定義:
extract_keywords 関数は、与えられたテキストに対して形態素解析を行い、名詞をキーワードとして抽出します。
tagger = MeCab.Tagger("-Ochasen") でMeCabのTaggerオブジェクトを初期化します。
名詞の抽出:
tagger.parseToNode(text) を用いてテキストを形態素ノードに分解します。
形態素ノードをループで処理し、features[0] == '名詞' の条件に基づいて名詞だけを抽出します。
抽出された名詞を keywords リストに追加します。
タイトルからキーワードの抽出:
df['title'].apply(extract_keywords) を使用して、データフレームの各タイトルに対して extract_keywords 関数を適用します。
得られたキーワードのリストを新しい列 df['keyword'] に追加します。
⑸ 感情分析にて3種類のラベルを付与する
統合したデータを漢書分析し、以下の3つにラベリングします。
ーーーーーーーーーーーーーーーーーーーーーーーーーー
(ラベル)
● POSITIVE
● NEGATIVE
● NIUTRAL
ーーーーーーーーーーーーーーーーーーーーーーーーーー
# 極性辞書の読み込み(pn_ja.dicをダウンロードして適切なパスに配置してください)
polarity_dict = pd.read_csv('/content/pn_ja.dic', sep=':', header=None, names=['Word', 'Pos', 'Score'], encoding='shift_jis')
# 極性辞書を辞書型に変換
polarity_dict = dict(zip(polarity_dict['Word'], polarity_dict['Score']))
# ネガポジ分析
def sentiment_analysis(text):
tagger = MeCab.Tagger("-Ochasen")
nodes = tagger.parseToNode(text)
score = 0
while nodes:
word = nodes.surface
# 極性辞書に単語が存在する場合、スコアを加算
if word in polarity_dict:
score += float(polarity_dict[word]) # ここを修正
nodes = nodes.next
print(score)
# スコアが正ならポジティブ、負ならネガティブ、0ならニュートラル
if score > 0:
return "Positive"
elif score < 0:
return "Negative"
else:
return "Neutral"
# タイトルから感情を分析
df['感情'] = df['title'].apply(sentiment_analysis)
df
極性辞書の読み込み:
polarity_dict を pandas を使用して読み込み、辞書型に変換します。これにより、単語とその感情スコア(ポジティブかネガティブかを示す数値)がマッピングされます。
感情分析関数の定義:
sentiment_analysis 関数は、与えられたテキストに対して形態素解析を行い、各単語の感情スコアを合計して感情を判定します。
ネガポジ分析のロジック:
形態素解析された各単語に対して、極性辞書を参照して感情スコアを計算します。
総合スコアに基づき、ポジティブ、ネガティブ、またはニュートラルを判定します。
計算結果を確認しましたが、大多数が「Negative」判定となりました。予測として、単純に形態素解析された名詞を極性辞書に照らし合わせただけであった為、各名詞の前後の文脈を反映できていないと考えます。このことから、後ほど紹介する「⑺共起ネットワーク」にてHugging FaceのTransformersライブラリを使ったモデルを使用し、再度感情分析を実施することとします。
⑹ ワードクラウド
「⑷ 形態素解析にてキーワードを抽出する」にて品詞分解したdfをワードクラウドにて可視化してみる。
ワードクラウドとは:
テキストデータの中で頻繁に出現する単語を視覚的に表現したものです。単語の大きさはその出現頻度に比例し、より頻繁に使われる単語ほど大きく表示されます。この方法は、特定の文章や話題におけるキーワードを一目で把握するのに役立ちます。
ワードクラウドを使用する理由:
youtubeタイトルをの傾向を分析することで視覚的に世論の注目が何なのか?について把握するために今回は使用します。
%%shell
# IPAexフォントのインストール
apt-get -y install fonts-ipaexfont-gothic
# キャッシュの削除
rm /root/.cache/matplotlib/fontList.json
wget https://ipafont.ipa.go.jp/old/ipaexfont/ipaexg00301.zip
unzip ipaexg00301.zip
mv ipaexg00301/ipaexg.ttf /usr/share/fonts/truetype/
# 必要なライブラリのインストール
pip install japanize-matplotlib
pip install fugashi
pip install transformers['ja']
pip install sentencepiece
pip install ipadic
IPAexフォントのインストール:
apt-get -y install fonts-ipaexfont-gothic はIPAexゴシックフォントをインストールします。これは、日本語のテキスト表示に適したフォントです。
キャッシュの削除:
rm /root/.cache/matplotlib/fontList.json はMatplotlibのフォントキャッシュを削除します。新しいフォントをインストールした後に、Matplotlibが新しいフォントを認識できるようにするために必要です。
IPAexフォントのダウンロードと配置:
wget https://ipafont.ipa.go.jp/old/ipaexfont/ipaexg00301.zip でIPAexゴシックフォントのzipファイルをダウンロードします。
unzip ipaexg00301.zip でzipファイルを解凍します。
mv ipaexg00301/ipaexg.ttf /usr/share/fonts/truetype/ で解凍したフォントファイルをシステムのフォントディレクトリに移動します。
必要なライブラリのインストール:
pip install japanize-matplotlib はMatplotlibで日本語を表示するためのライブラリです。
pip install fugashi は日本語形態素解析器MeCabのPythonラッパーです。
pip install transformers['ja'] はHugging FaceのTransformersライブラリの日本語に特化した部分をインストールします。
pip install sentencepiece は自然言語処理で使用される、テキストをサブワードユニットに分割するライブラリです。
pip install ipadic はMeCab用の日本語辞書です。
# ライブラリのインポートその2
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import japanize_matplotlib
from itertools import combinations
import networkx as nx
import re
from tqdm import tqdm
import fugashi
from collections import Counter
from collections import defaultdict
# import ipadic
from transformers import pipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer,BertTokenizer, BertForSequenceClassification
WordCloud:
from wordcloud import WordCloud はテキストデータからワードクラウド(単語の出現頻度に基づいたビジュアル)を生成するためのライブラリです。
Matplotlibとjapanize_matplotlib:
import matplotlib.pyplot as plt はデータ可視化のための基本的なライブラリで、グラフやチャートを作成します。
import japanize_matplotlib はMatplotlibで日本語を正しく表示するためのライブラリです。
NetworkX:
import networkx as nx はネットワーク構造やグラフを操作、分析するためのライブラリです。
正規表現:
import re は正規表現を使用して、文字列の検索や置換、分割を行います。
tqdm:
from tqdm import tqdm : ループの進行状況をプログレスバーとして表示します。
Fugashi:
import fugashi は日本語の形態素解析器MeCabのPythonラッパーです。
Counterとdefaultdict:
from collections import Counter は要素の出現回数をカウントするためのデータ型です。
from collections import defaultdict はデフォルト値を持つ辞書型です。
Transformers:
自然言語処理に関連する様々なモデルやツールを提供するライブラリです。
# ストップワードの設定(必要に応じて拡張)
stopwords = set(["これ", "それ", "あれ", "この", "その", "あの", "ここ", "そこ", "あそこ", "こちら", "どこ", "だれ", "なに", "など", "なん", "の", "こと", "なん", "ちゃん", "ため", "さん", "S", "たち", "A", "さ", "ジャ", "ん", "なん"])
# キーワードを一つのテキストにまとめる(重複排除とストップワード除外)
all_keywords = " ".join(set([" ".join(set(keywords) - stopwords) for keywords in df['keyword']]))
# ワードクラウドの生成(フォントにIPAexフォントを指定)
wordcloud = WordCloud(background_color='white', width=800, height=400, stopwords=stopwords, font_path='/usr/share/fonts/truetype/ipaexg.ttf').generate(all_keywords)
# ワードクラウドの表示
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
ストップワードの設定:
ストップワードは、分析にはあまり意味を持たない一般的な単語(例: 「これ」、「その」など)です。これらの単語はワードクラウドから除外されます。
キーワードの処理:
df['keyword'] からキーワードのリストを取得し、ストップワードを除外して、全キーワードを一つの長いテキスト(all_keywords)にまとめます。ここでは、キーワードの重複も排除されます。
ワードクラウドの生成:
wordCloud オブジェクトを作成して、処理したキーワードテキストからワードクラウドを生成します。font_path には日本語をサポートするフォント(この場合はIPAexフォント)のパスを指定します。
ワードクラウドの表示:
plt.figure で図のサイズを設定し、plt.imshow でワードクラウドを表示します。interpolation='bilinear' は表示の滑らかさを高めるための設定です。
plt.axis("off") で軸の表示をオフにします。
(ワードクラウド_20231001_15)

(ワードクラウド_20231016_31)

⑺ 共起ネットワーク
「 ⑸ 感情分析にて3種類のラベルを付与する」にて品詞分解したdfを利用して、共起ネットワークで可視化してみる。
共起ネットワークとは:
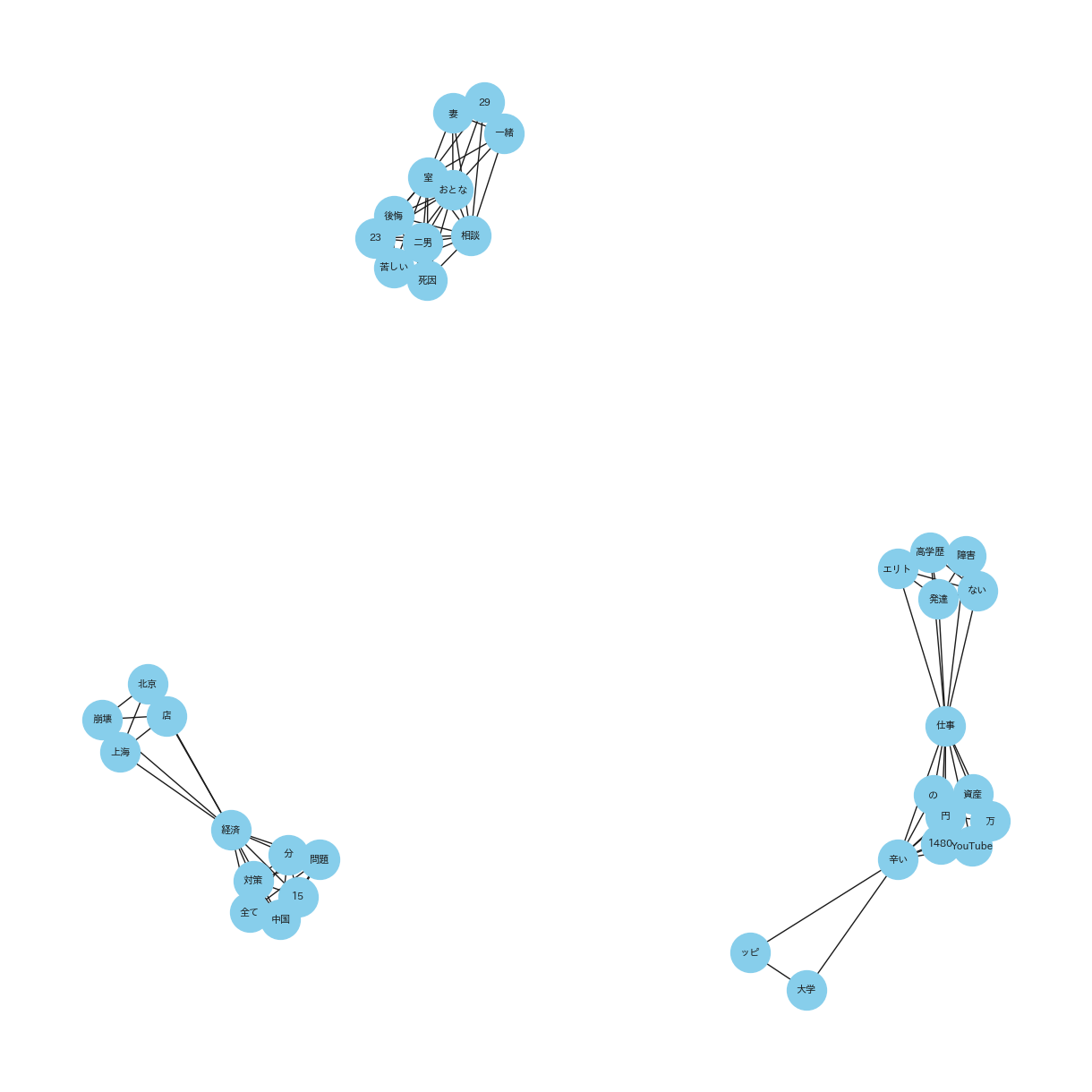
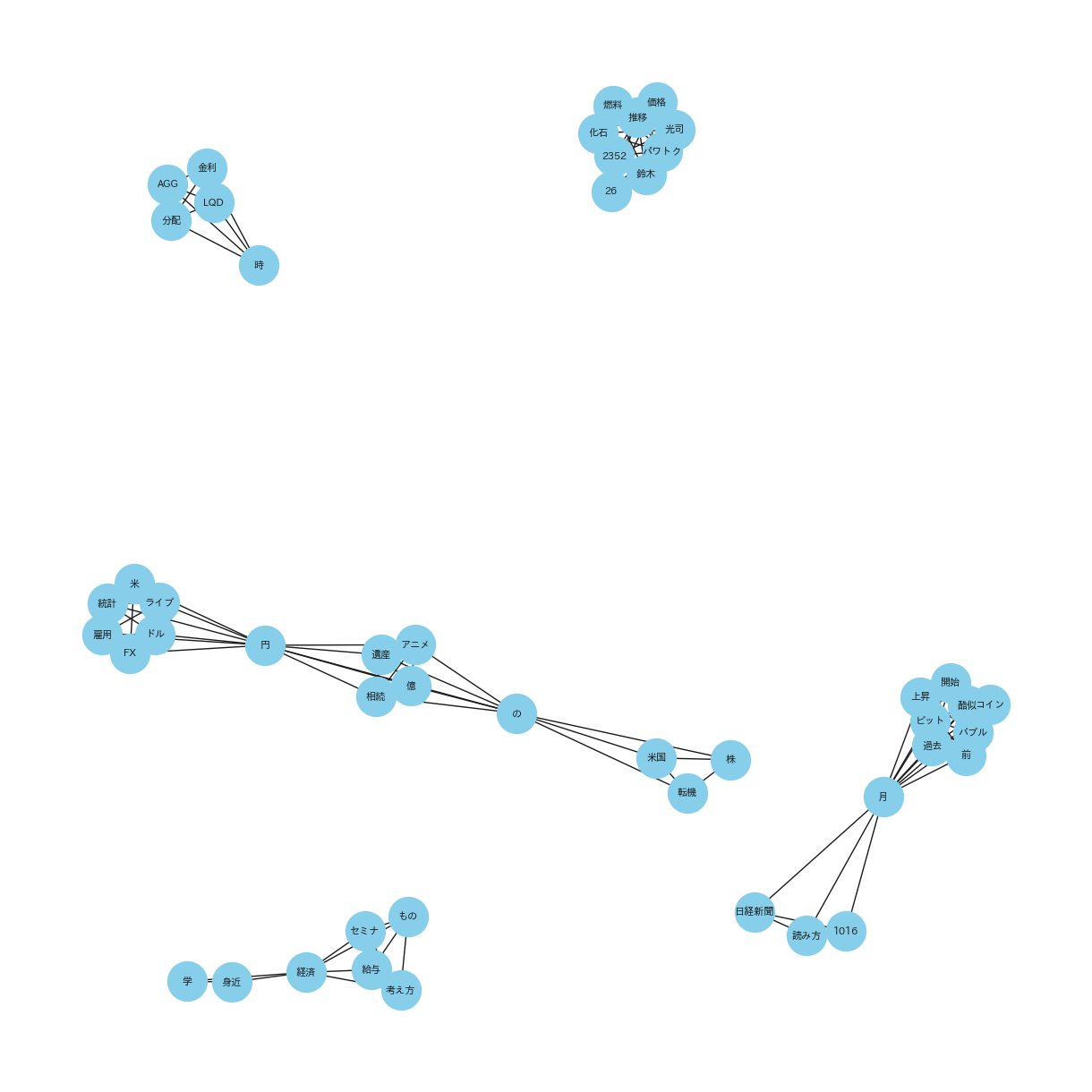
共起ネットワークは、異なる要素間の共起関係をネットワーク図で表したものです。特にテキストデータにおいては、単語やフレーズが文書中でどのように関連して出現するかを視覚化します。また、ノードは単語を表し、エッジは単語間の共起、つまり同時出現の関連性を示します。共起ネットワークを利用することで、テキスト内の概念やテーマの関係を解析し、深い洞察を得ることができます。
共起ネットワークを使用する理由:
共起ネットワークを使用した理由は、YouTubeタイトルから抽出された単語やフレーズの間にどのような関連性があるかを明らかにするためです。形態素解析によってテキストを単語単位に分割した後、これらの単語がどのように共に出現するかを視覚的に表現することで、タイトル内の重要なテーマやトレンド、関連するキーワードを識別することができます。この分析により、特定の単語が他の多くの単語と頻繁に組み合わされている場合、その単語はトピックの中心的な概念である可能性が高いと推測できます。共起ネットワークは、これらの関係性を直感的に理解するための強力な手法です。
data = '/content/drive/MyDrive/youtube_data/20231001_15/combined_20231001_15excel.xlsx' # Excelファイルのパスを指定
df = pd.read_excel(data)
# 前処理関数
def preprocess_text(text):
# 特殊文字の削除
text = re.sub(r'[^ぁ-んァ-ン一-龥a-zA-Z0-9]', '', text)
# 半角・全角の統一などの追加処理が必要であればここに記述
return text
# キーワードの洗い出し(形態素解析)
def extract_keywords(text):
# 辞書ファイルへのパスを指定
nodes = tagger.parseToNode(text)
keywords = []
while nodes:
features = nodes.feature.split(',')
# 名詞だけを抽出
if features[0] == '名詞':
keywords.append(nodes.surface)
elif features[0] == '形容詞':
keywords.append(nodes.surface)
nodes = nodes.next
return keywords
# データフレームの前処理
df['title'] = df['title'].apply(preprocess_text)
# タイトルからキーワードを抽出
df['keyword'] = df['title'].apply(extract_keywords)
# モデルとトークナイザーのセットアップ
model = AutoModelForSequenceClassification.from_pretrained('koheiduck/bert-japanese-finetuned-sentiment')
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
column_name = "title"
# データフレームからリストへ変換
corpus_list = df[column_name].to_list()
# 結果を表形式で出力
result_df = pd.DataFrame(columns=['text', 'label', 'score'])
for corpus in tqdm(corpus_list):
result = classifier(corpus)[0]
result_df = result_df.append({'text': corpus, 'label': result['label'], 'score': round(result['score'], 4)}, ignore_index=True)
result_df.head()
Excelファイルの読み込み:
pd.read_excel(data) を使用して、指定されたパスのExcelファイルをPandasのデータフレームに読み込みます。
テキストの前処理関数:
preprocess_text 関数は、不要な特殊文字を削除してテキストをクリーニングします。
キーワード抽出関数:
extract_keywords 関数は、形態素解析を用いてテキストから名詞と形容詞をキーワードとして抽出します。
データフレームの前処理:
df['title'] 列に preprocess_text 関数を適用して、タイトルを前処理します。
キーワードの抽出:
df['title'] 列に extract_keywords 関数を適用して、各タイトルからキーワードを抽出します。
感情分析モデルのセットアップ:
Hugging FaceのTransformersライブラリを使用して、BERTモデルと日本語のトークナイザーをセットアップします。
pipeline を使用して感情分析のためのモデルをセットアップします。
感情分析の実行:
df の title 列をリストに変換し、各タイトルに対して感情分析を実行します。
結果は result_df という新しいデータフレームに保存されます。
結果の表示:
result_df.head() を使用して、感情分析の結果の先頭部分を表示します。
このコードは、YouTubeビデオのタイトルのキーワードを分析し、それらの感情的傾向(ポジティブ、ネガティブ、ニュートラル)を把握するために役立ちます。
# dfとresult_dfを結合
combined_df = pd.concat([df, result_df], axis=1)
# 必要な列のみを選択
final_df = combined_df[['title', 'publishedAt', 'keyword', 'label', 'score']]
final_df
データフレームの結合:
pd.concat([df, result_df], axis=1) を使用して、df と result_df を横方向(列を追加する形式)に結合します。これにより、両方のデータフレームの情報が一つのデータフレームにまとめられます。
必要な列の選択:
combined_df[['title', 'publishedAt', 'keyword', 'label', 'score']] により、結合したデータフレームから特定の列('title', 'publishedAt', 'keyword', 'label', 'score')のみを選択して新しいデータフレーム final_df を作成します。
新しいデータフレームの表示:
最後に、final_df を表示します。このデータフレームには、YouTubeのビデオタイトル、公開日、抽出されたキーワード、感情分析の結果(ラベルとスコア)が含まれます。
# 'label' 列が 'POSITIVE' である行のみを抽出
positive_df = final_df[final_df['label'] == 'POSITIVE']
# 結果を表示
positive_df
ポジティブな行の抽出:
positive_df = final_df[final_df['label'] == 'POSITIVE'] はこの行は、final_df データフレームから label 列の値が 'POSITIVE' であるすべての行を選択し、それらの行で新しいデータフレーム positive_df を作成します。
結果の表示:
positive_df の内容を表示します。このデータフレームには、感情分析でポジティブと判定されたYouTubeビデオのタイトル、公開日、キーワード、ラベル、スコアが含まれます。
# 'score' 列で降順にソートし、上位10のデータを選択
top10_positive = positive_df.sort_values(by='score', ascending=False).head(10)
top10_positive
データの降順ソート:
positive_df.sort_values(by='score', ascending=False) は、positive_df データフレームを score 列の値に基づいて降順(大きい値から小さい値へ)にソートします。
上位10件のデータの選択:
head(10) メソッドは、ソートされたデータフレームの最初の10行を取得します。これにより、score が最も高い上位10件のデータが選択されます。
結果の表示:
top10_positive にソートされた上位10件のデータが格納されます。
最後に top10_positive を表示します。これにより、感情分析でポジティブと判定された上位10件のYouTubeビデオのタイトル、公開日、キーワード、ラベル、スコアが表示されます。
import pandas as pd
import networkx as nx
from itertools import combinations
from collections import defaultdict
import matplotlib.pyplot as plt
# キーワードの共起集計
keyword_sets = [set(keywords) for keywords in top10_positive['keyword']]
keyword_pair_counts = defaultdict(int)
total_counts = defaultdict(int)
for keywords in keyword_sets:
for keyword in keywords:
total_counts[keyword] += 1
for a, b in combinations(keywords, 2):
keyword_pair_counts[(a, b)] += 1
# 共起ネットワークの作成
G = nx.Graph()
for (a, b), count in keyword_pair_counts.items():
union_count = total_counts[a] + total_counts[b] - count
jaccard_coeff = count / union_count
G.add_edge(a, b, weight=jaccard_coeff)
# 描画
plt.figure(figsize=(12, 12))
pos = nx.spring_layout(G, k=0.3)
nx.draw(G, pos, with_labels=True, font_size=8, node_size=1000, node_color='skyblue', font_family='IPAexGothic')
plt.show()
キーワードの共起集計:
keyword_sets は top10_positive['keyword'] からキーワードのセットを作成します。これにより、各エントリーのキーワードが個別のセットとして扱われます。
keyword_pair_counts と total_counts はそれぞれキーワードペアと個々のキーワードの出現回数を集計するためのデフォルト辞書です。
共起ネットワークの作成:
networkx ライブラリを使用して共起ネットワークグラフ G を作成します。
各キーワードペアについて、ジャッカード係数(共起頻度と個別頻度の比率)を計算し、それをエッジの重みとしてグラフに追加します。
ネットワークの描画:
plt.figure で図のサイズを設定し、nx.spring_layout でネットワークのレイアウトを決定します。
nx.draw を用いてネットワークグラフを描画します。ノードのサイズ、色、ラベルのフォントなどのオプションが指定されています。
ここまでが2023年10月01日〜15日における’POSITIVE TOP10’ の共起ネットワークの作成です。この後、’NEGATIVE TOP10’、’NEUTURAL TOP10’’ネガポジニュー TOP10(全てのTOP10)’を同じ手順で繰り返します。また、2023年10月16日〜31日のデータについても同様に作業します。
(共起ネットワーク_20231001_15_POSITIVE_top10)
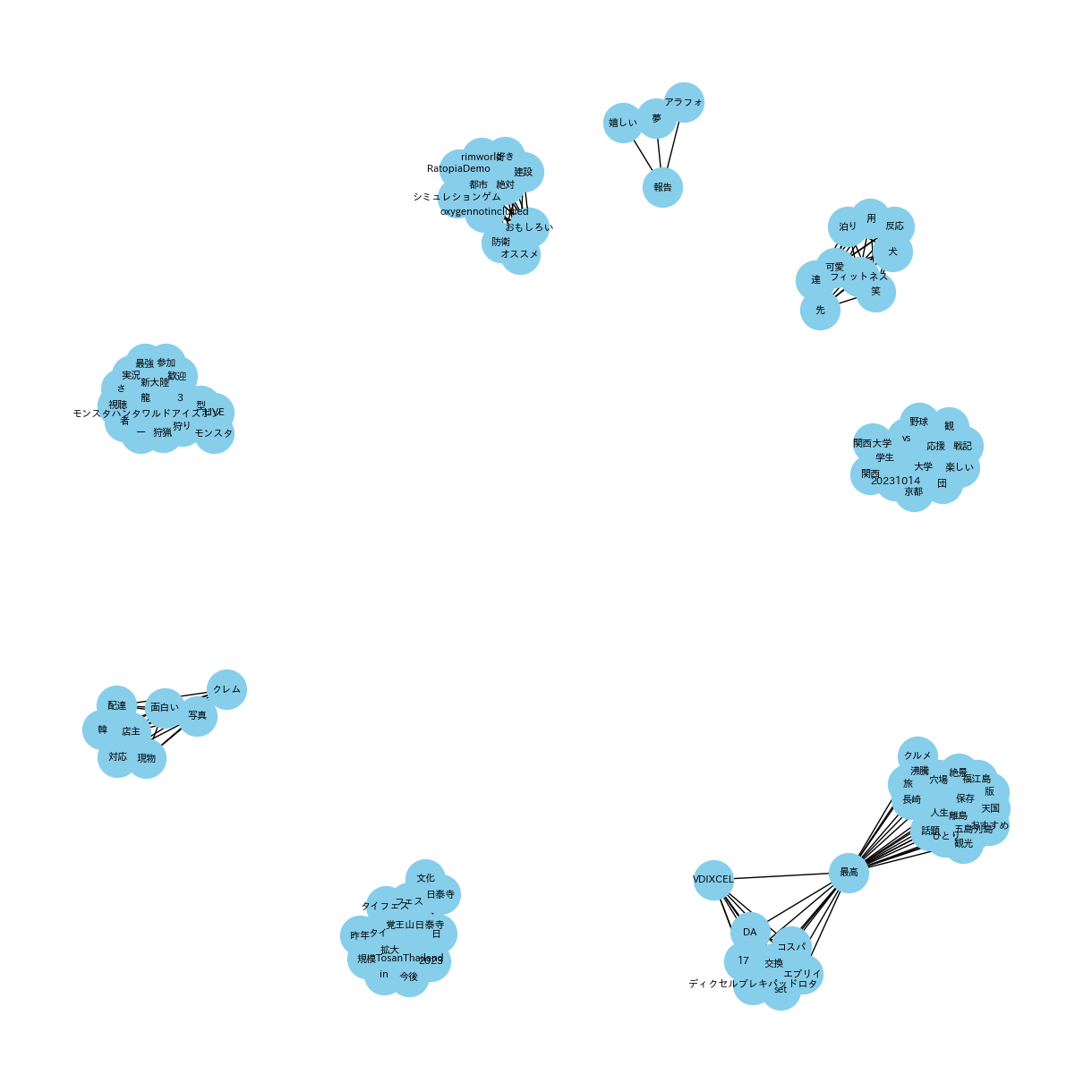
(共起ネットワーク_20231001_15_NEGATIVE_top10)
(共起ネットワーク_20231001_15_NEUTRAL_top10)
(共起ネットワーク_20231001_15_ネガポジニュー合算_top10)
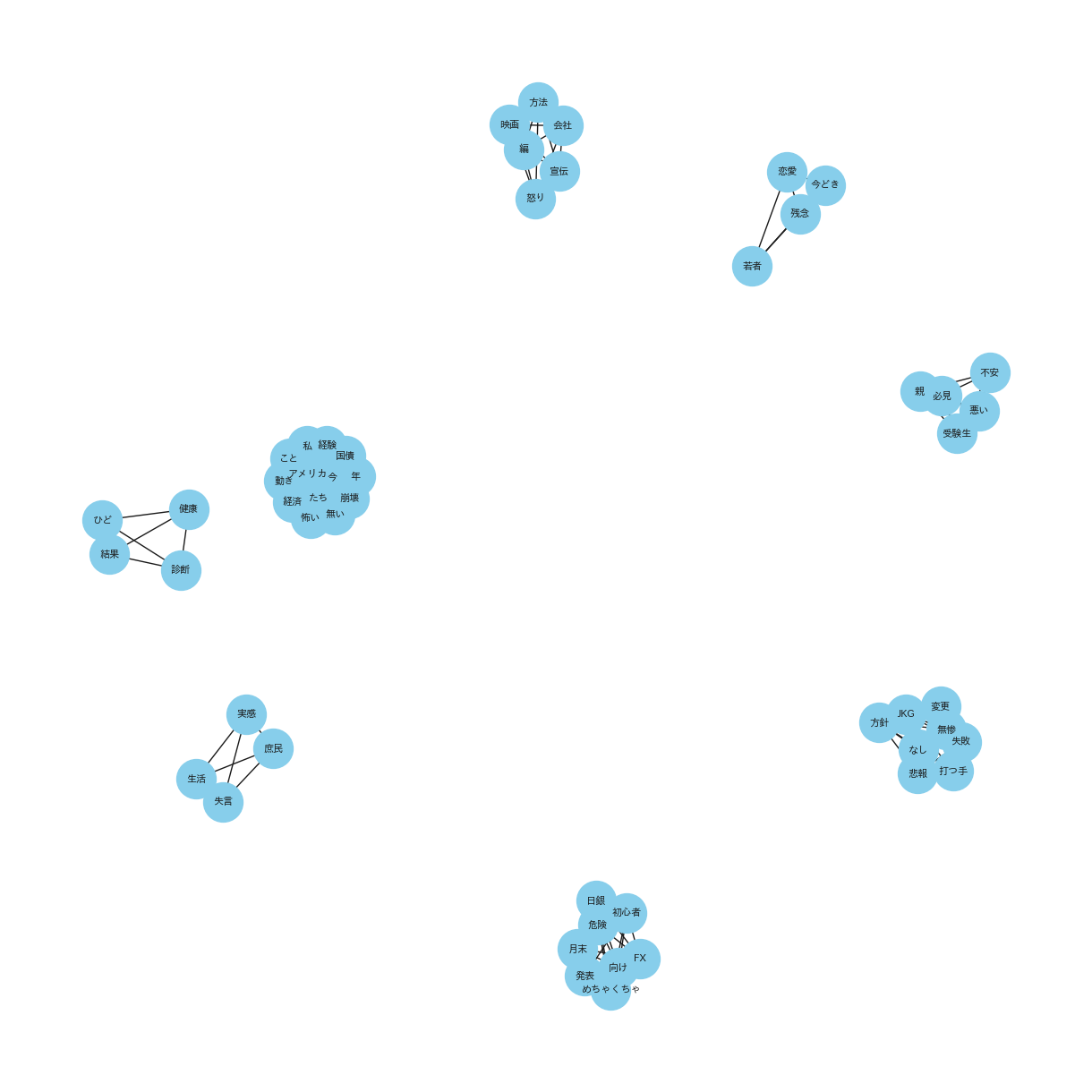
(共起ネットワーク_20231016_31_POSITIVE_top10)
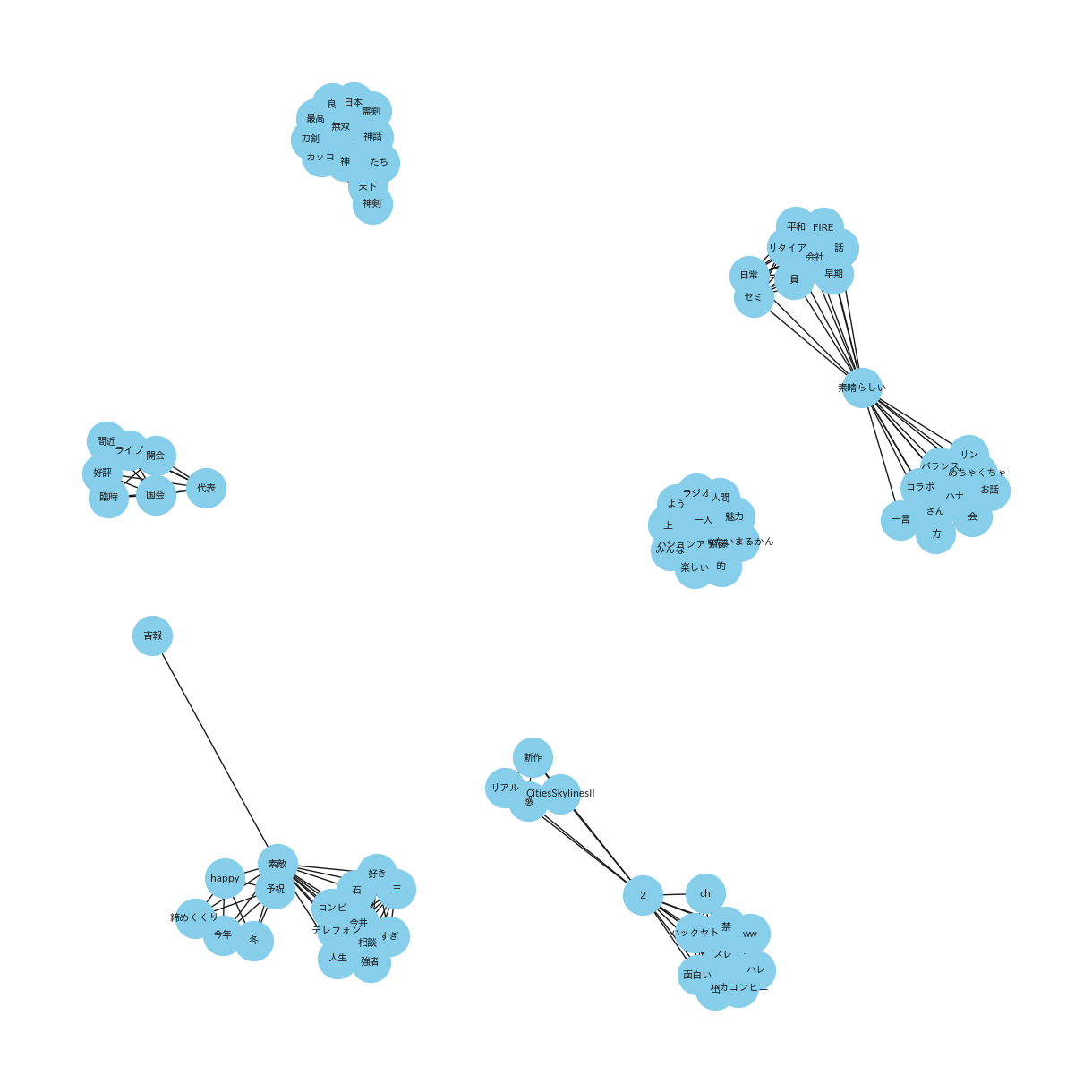
(共起ネットワーク_20231016_31_NEGATIVE_top10)
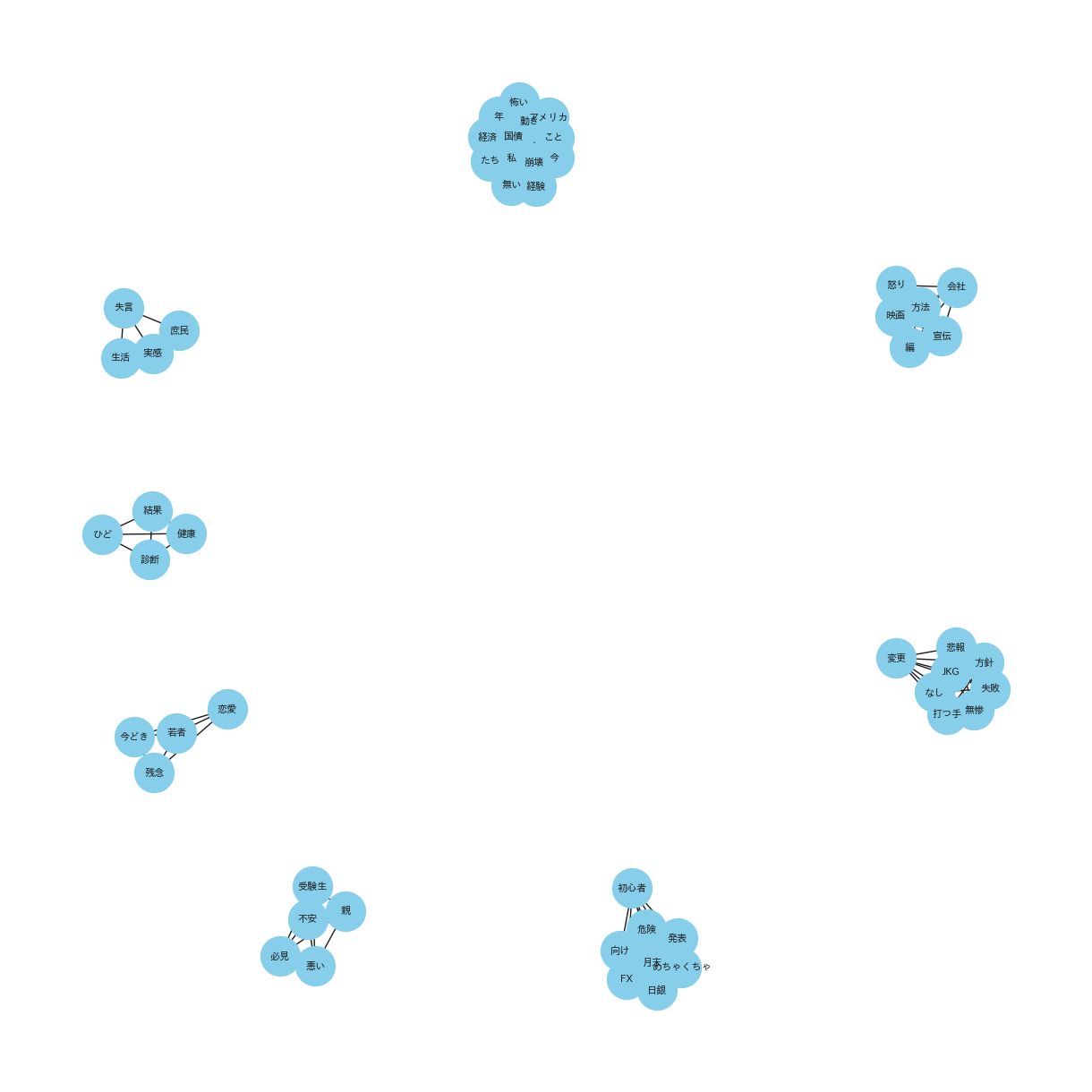
(起ネットワーク_20231016_31_NEUTRAL_top10)
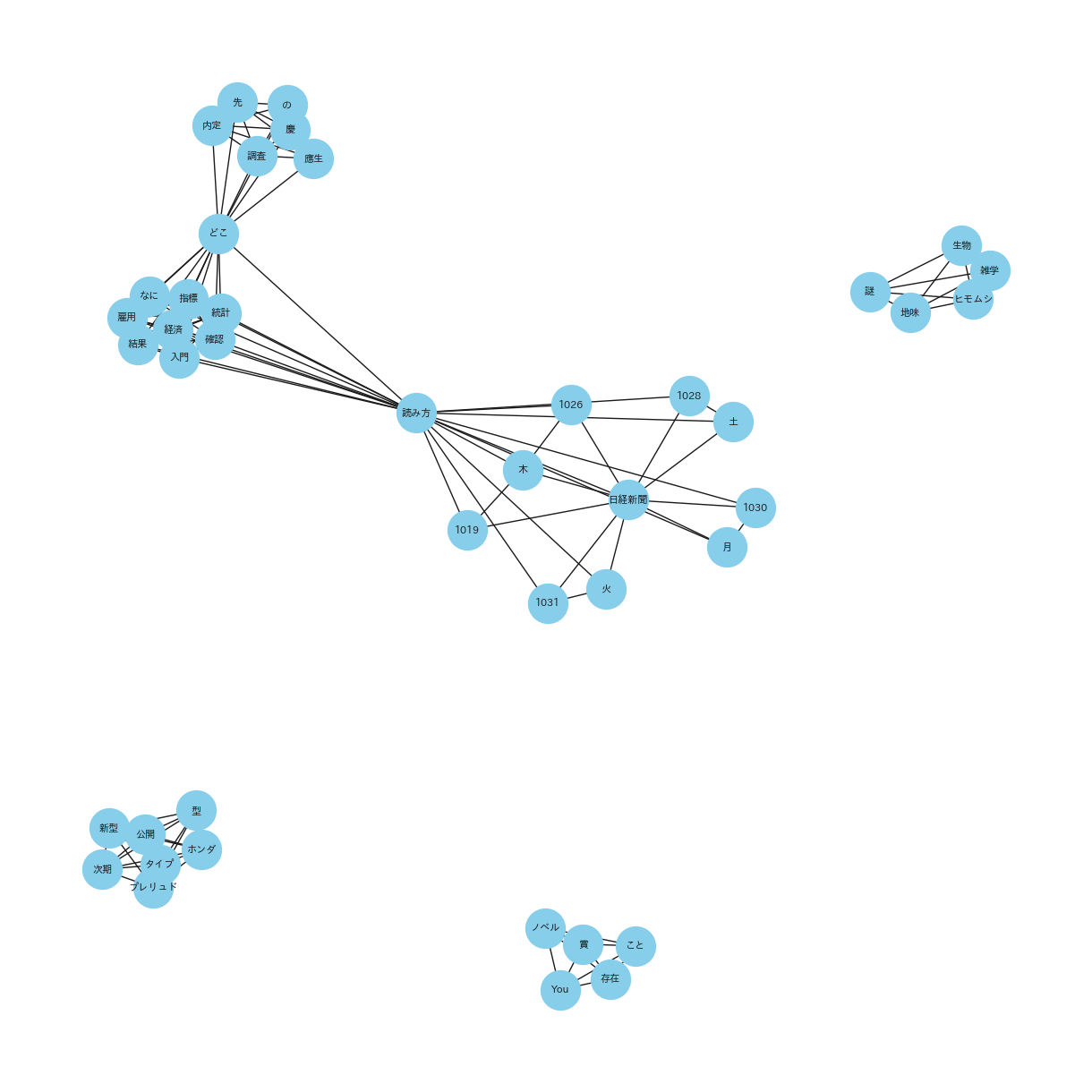
(共起ネットワーク_20231016_31_ネガポジニュー合算_top10)
⑻ Stratified histogram by category_seaborn
最後にヒストグラム形式にて可視化してみます。
Stratified histogram by category_seabornとは:
Stratified histogram by category_seabornは、データの分布をカテゴリー別に層別化して表示するヒストグラムです。Seabornライブラリを用いて、データセット内の変数の分布をグループ化し、カテゴリーごとに色分けして重ねて描画します。この方法により、異なるグループ間でのデータの分布の違いを明瞭にし、比較分析を容易に行うことができます。視覚的にインパクトがあり、データの傾向を一目で捉えることが可能となる有効な手法です。
Stratified histogram by category_seabornを使用する理由:
Stratified histogram by category_seabornを使用した理由は、YouTubeタイトルから得られた形態素解析の結果に基づいて、異なるカテゴリーに属する単語の分布を詳細に比較分析するためです。この手法により、例えば「ポジティブ」「ネガティブ」「ニュートラル」といった感情のカテゴリーごとに、どのような単語がどれだけの頻度で使われているかを視覚化できます。各カテゴリーにおける単語の使用頻度を色分けしたヒストグラムで示すことで、データの傾向を直感的に理解し、より深い考察を得ることができるからです。これにより、世論の関心を引くキーワードやトピックを特定するのに役立ちます。
#@title Stratified histogram by category_seaborn
Column_name = 'score'#@param {type:"raw"}
Category_column_name = 'label'#@param {type:"raw"}
bins_number_slider = 10 #@param {type:"slider", min:5, max:20, step:1}
import seaborn as sns
sns.set_style('whitegrid') #style指定
sns.set(font='IPAexGothic')
sns.histplot(x= Column_name, hue= Category_column_name, bins = bins_number_slider, kde=True, data=positive_df);
Seabornの設定:
sns.set_style('whitegrid') は、ヒストグラムのスタイルを「白いグリッド」に設定します。これにより、背景に格子状のラインが表示され、データの読み取りやすさが向上します。
sns.set(font='IPAexGothic') は、グラフのフォントをIPAexゴシックに設定します。これは日本語の文字を正しく表示するために重要です。
ヒストグラムの描画:
sns.histplot 関数は、指定されたデータフレームの列に基づいてヒストグラムを描画します。
x=Column_name で、ヒストグラムのx軸に表示するデータの列(この場合は score)を指定します。
hue=Category_column_name で、異なる色で区別するカテゴリー(この場合は label)を指定します。
bins=bins_number_slider は、ヒストグラムのビン(棒)の数を指定します。ここではスライダーで選択した値を使用します。
kde=True は、カーネル密度推定(KDE)の曲線をヒストグラムに追加するオプションです。これにより、分布の形状がより明確になります。
data=positive_df は、ヒストグラムを作成するためのデータソースとして positive_df を指定します。
ここまでが2023年10月01日〜15日における’POSITIVE TOP10’ の共起ネットワークの作成です。この後、’NEGATIVE TOP10’、’NEUTURAL TOP10’’ネガポジニュー TOP10(全てのTOP10)’を同じ手順で繰り返します。※2023年10月16日〜31日のデータについても同様に作業します。
なお、’ネガポジニュー TOP10(全てのTOP10)’については、両期間のそれぞれの色を下記の通り指定し、比較しやすいよう調整します。
import seaborn as sns
# スタイルとフォントの設定
sns.set_style('whitegrid')
sns.set(font='IPAexGothic')
# カラーパレットの定義
palette = {
'NEGATIVE': 'royalblue', # NEGATIVEは青色
'NEUTRAL': 'peru', # NEUTRALはオレンジ色
'POSITIVE': 'seagreen' # POSITIVEは緑色
}
# 凡例の順番を指定
order = ['NEGATIVE', 'NEUTRAL', 'POSITIVE']
# ヒストグラムの描画
sns.histplot(
x=Column_name,
hue=Category_column_name,
bins=bins_number_slider,
kde=True,
data=final_df,
palette=palette,
hue_order=order # 凡例の順番を設定
);
(Stratified histogram by category_seaborn_20231001_15_negative_top10)
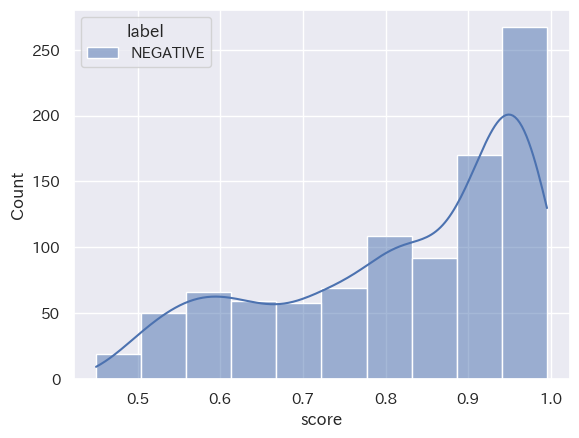
([Stratified histogram by category_seaborn_20231001_15_neutral_top10)
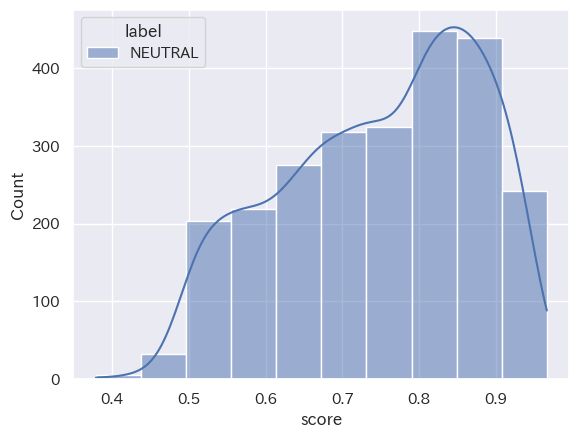
(Stratified histogram by category_seaborn_20231001_15_positive_top10)
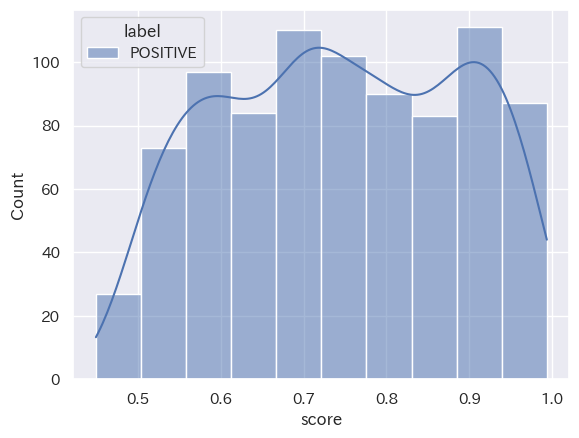
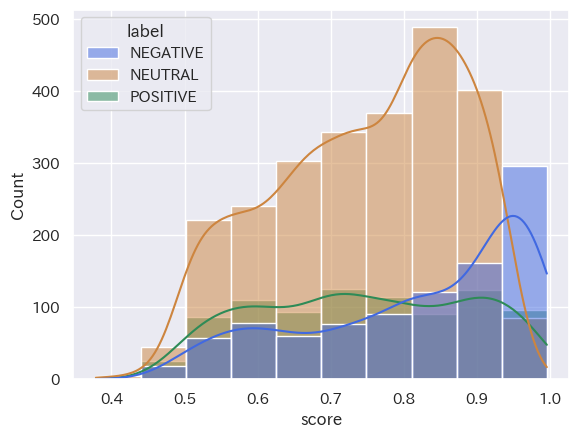
(Stratified histogram by category_seaborn_2023101_15_ネガポジニュー_top10)
(Stratified histogram by category_seaborn_20231016_31_negative_top10)
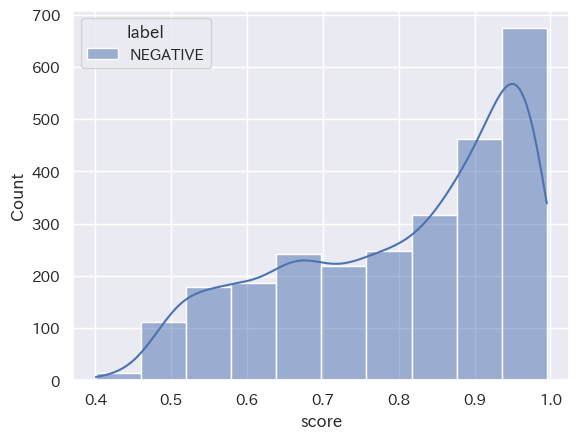
(Stratified histogram by category_seaborn_20231016_31_neutral_top10)
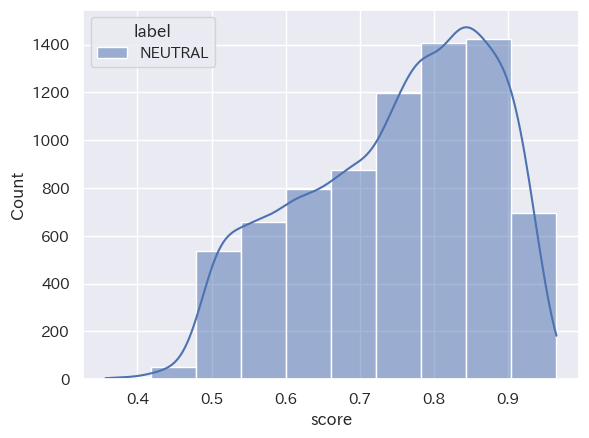
(Stratified histogram by category_seaborn_20231016_31_positive_top10)
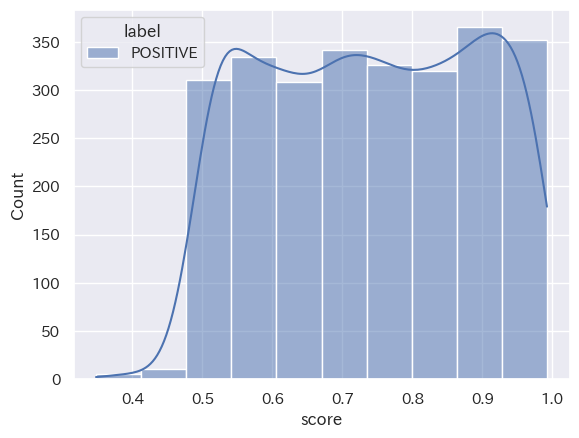
(Stratified histogram by category_seaborn_20231016_31_ネガポジニュー_top10)
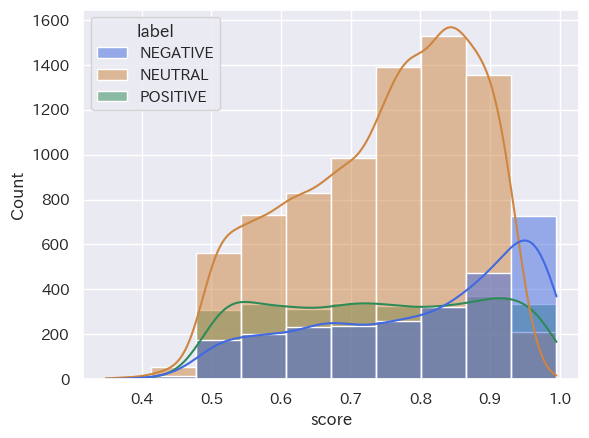
3.結論
● ワードクラウド
(ワードクラウド_20231001_15)

(ワードクラウド_20231016_31)

共通点:「2023年10月1日から15日」と「2023年10月16日から31日」において、経済をキーワードにしていることもあり、国名が多く使用されています。また、「解説」や「月日」などニュースを連想させるキーワードが多いことがわかる。
特徴的なキーワード::「株」や「投資」など資産運用に関連する単語が確認できます。これは近年日本でも資産運用が注目されている傾向にあることがわかります。また、「ウクライナ」や「ロシア」「ハマス」など世界で起きている戦争に関するニュースも多いと読み取れます。
トレンドの変化:2つの画像に表示される単語の違いは、時間の経過とともにトレンドが変化したことを示しています。また、1つ目の期間と2つ目の期間で大きく表示される単語が異なる場合、その期間における視聴者の関心のシフトを反映していると考えられます。
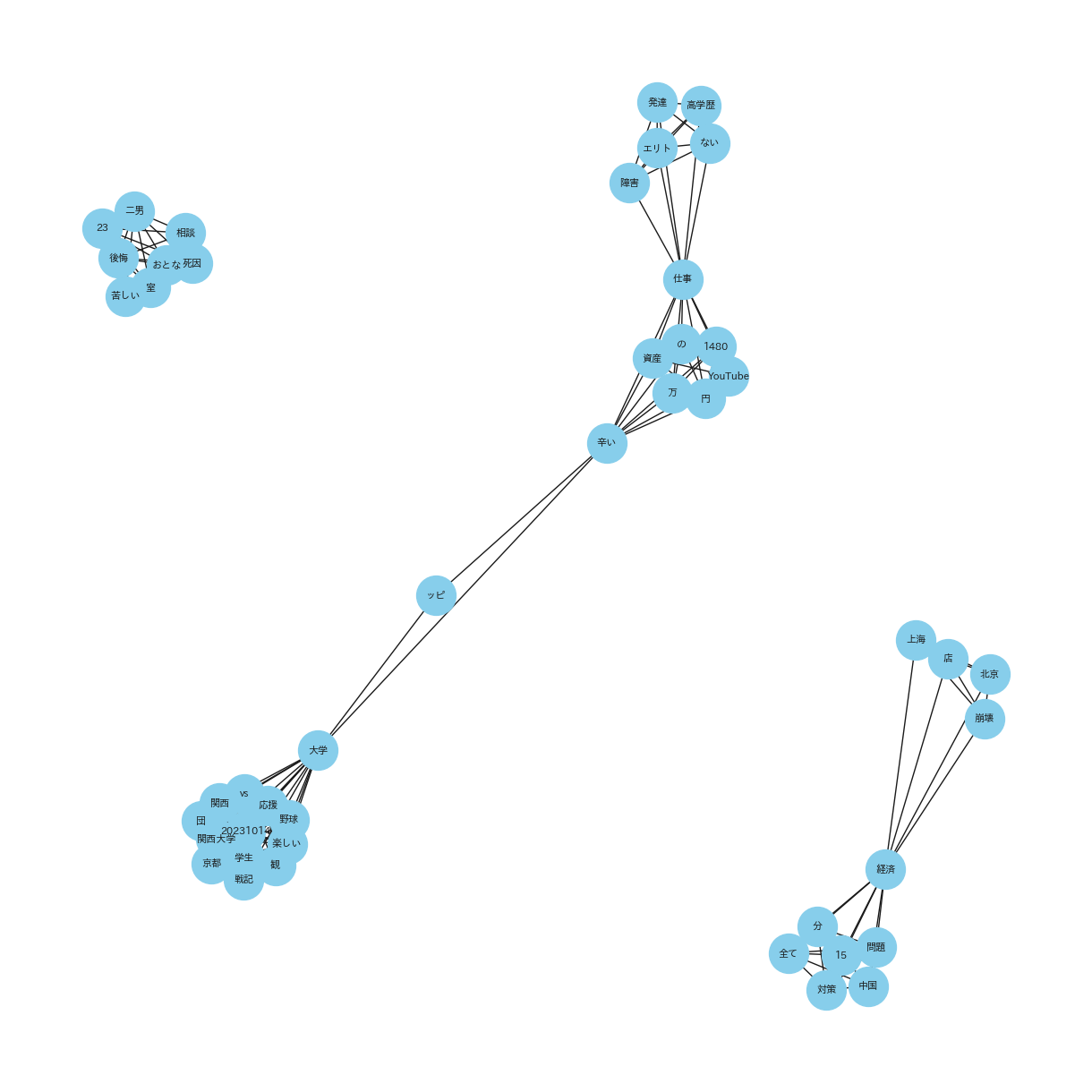
● 共起ネットワーク
(共起ネットワーク_20231001_15_POSITIVE_top10)
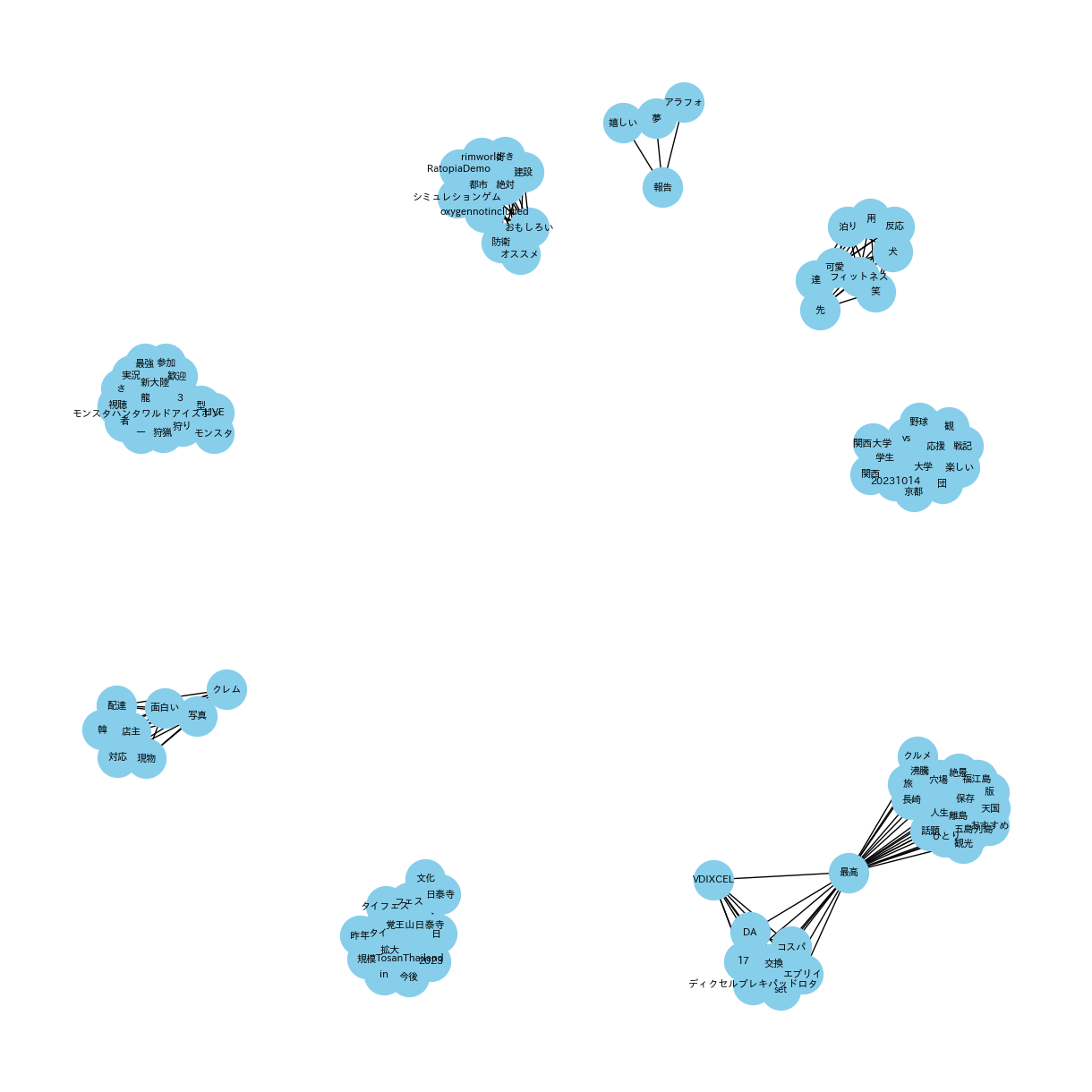
(共起ネットワーク_20231016_31_POSITIVE_top10)
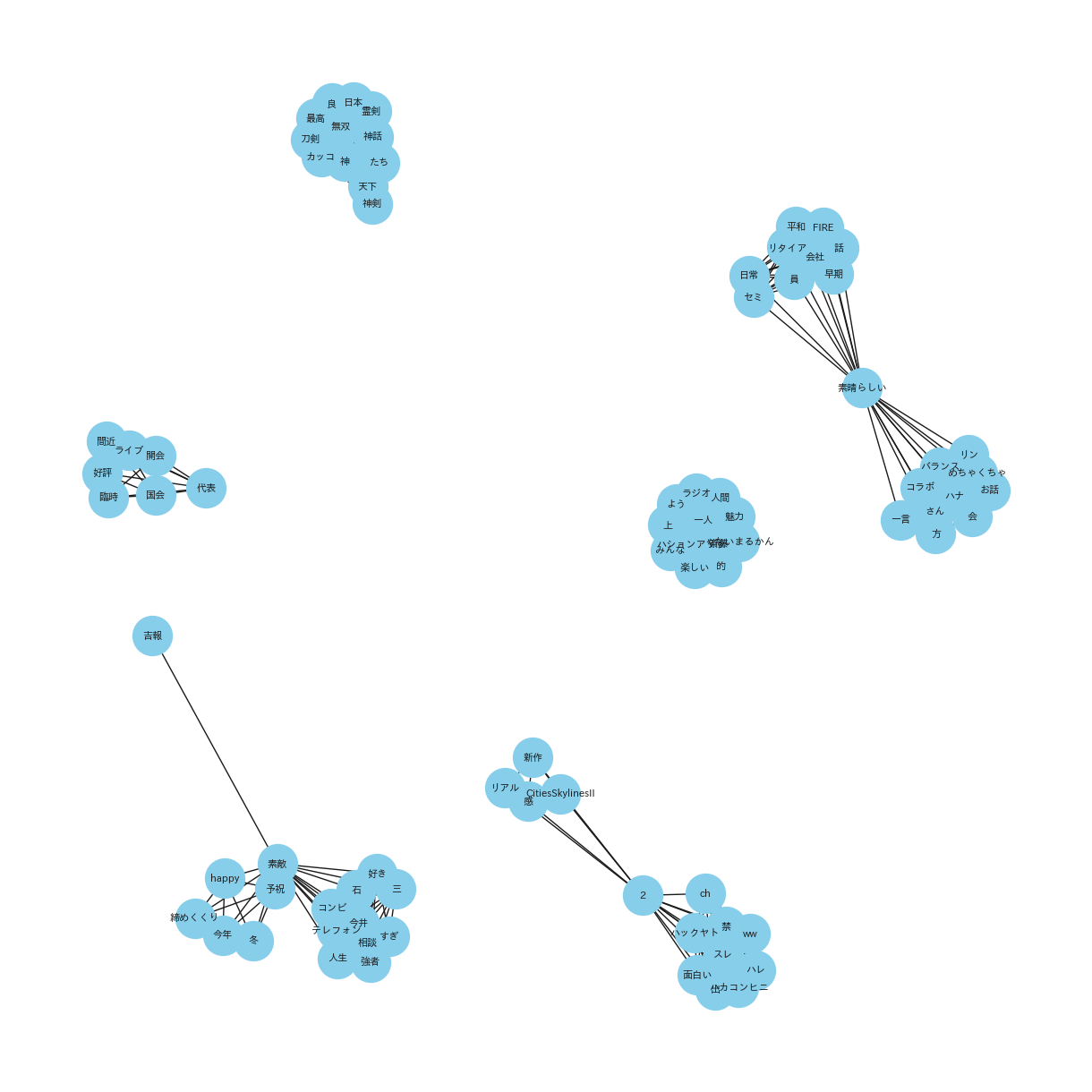
共通点:「2023年10月1日から15日」と「2023年10月16日から31日」において、どちらも中心となPOSITIVEなキーワードを中心に関連しているキーワードがプロットされています。
特徴的なキーワード::ここではPOSITIVEについて、注目して見ます。「最高」や「夢」、「素敵」など経済の領域においても前向きなキーワードを使われていることが確認できることから、くらいニュースだけでなく明るいニュースもyoutubeを通じて発信されていることがわかります。
● Stratified histogram by category_seaborn
(Stratified histogram by category_seaborn_20231001_15_ネガポジニュー_top10)
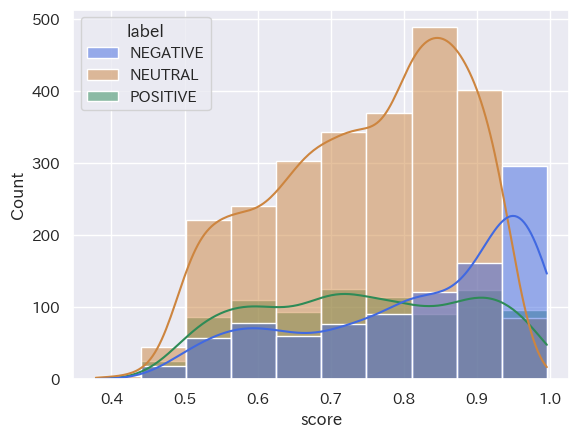
(Stratified histogram by category_seaborn_20231016_31_ネガポジニュー_top10)
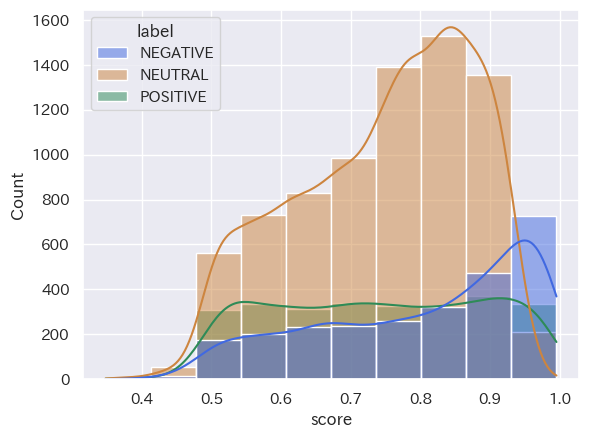
共通点:「2023年10月1日から15日」と「2023年10月16日から31日」において、分類された結果の数は「NEUTRAL」「NEGATIVE」「POSITIVE」の順ということが読み取れます。また、score値は、どの分類においても0.8付近から0.9付近が多いということも分かります。
トレンドの変化:2つのヒストグラムを比較して分かるように、分類された結果の数は「NEUTRAL」「NEGATIVE」「POSITIVE」の順となり、時間の経過してもこの構造に変化は出にくい傾向にあると読み取れることが分かります。つまり、’経済’というキーワードにおいては、POSITIVE判定される動画タイトルよりNAGATIVE判定される動画の方が多くアップロードされていることになります。
4.感想
2023年9月からプログラミング学習を開始して3ヶ月が経ちました。この期間、Pythonの可能性について多くの実践を通じて学び、特に自然言語処理の分野でのその多様性を実感することができました。
感情分析、ワードクラウド、共起ネットワークの生成といった多岐にわたるプロジェクトに取り組むことができ、これらの経験がとても有意義だったと感じています。今後はこれらの経験を活かし、さらに深い理解を目指していきたいと思います。
この記事を最後まで読んでいただき、ありがとうございました。。