WordTreeとは
皆さん、こんにちは。
googleのAPI「Word Trees」を使ったことはありますか?
どういうものかというと、ある文章の塊を基に単語の頻出度を構造化ツリーにしたものです。
文章の塊の中で、この単語の次にはこれが来る割合が多いとかが視覚的に判断出来るようになります。
下図がイメージ図です。ご覧ください。
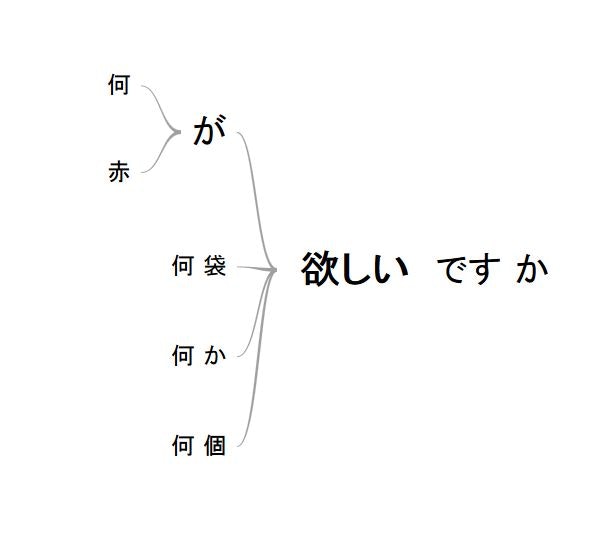
単語が太く、濃くなっているところが頻出度が高くなっているところです。
この例だと、「が」「欲しい」という単語が太く・濃くなっているので、頻出度が高いことが分かります。頻出度が高いということは、文章の中でより多く出現していることを現しています。「が欲しい」のように、「が」の後に「欲しい」が多いのは、データに偏りがあるからだとも思えますが.....。
では、実際に、Word TreesのAPIを使用した感想を述べたいと思います。
開発環境
windows7
Sublime Text
javascript
HTML
ソースコード
Word Treesのwebページに載っているソースコードがサンプルになります。
一応、下に載せておきます。
<html>
<head>
<script type="text/javascript" src="https://www.gstatic.com/charts/loader.js"></script>
<script type="text/javascript">
google.charts.load('current', {packages:['wordtree']});
google.charts.setOnLoadCallback(drawChart);
function drawChart() {
var data = google.visualization.arrayToDataTable(
[ ['Phrases'],
['cats are better than dogs'],
['cats eat kibble'],
['cats are better than hamsters'],
['cats are awesome'],
['cats are people too'],
['cats eat mice'],
['cats meowing'],
['cats in the cradle'],
['cats eat mice'],
['cats in the cradle lyrics'],
['cats eat kibble'],
['cats for adoption'],
['cats are family'],
['cats eat mice'],
['cats are better than kittens'],
['cats are evil'],
['cats are weird'],
['cats eat mice'],
]
);
var options = {
wordtree: {
format: 'implicit',
word: 'cats'
}
};
var chart = new google.visualization.WordTree(document.getElementById('wordtree_basic'));
chart.draw(data, options);
}
</script>
</head>
<body>
<div id="wordtree_basic" style="width: 900px; height: 500px;"></div>
</body>
</html>
使用してみての感想
サンプルの例では、文章が英語になっています。英語の場合、デフォルトで単語と単語の間にスペースをいれますよね。なので、必然的に単語区切りになっています。日本語もこうであれば良いのに..........。トホホ....orz
構造的には、多重配列を作成してその中に['文字列']を入れれば良い形式となっています。
ここで注意する必要があるのが、['文字列']を単語区切りにしてスペースを付与しなければいけないことです。
たとえば、日本語の場合、「'何が欲しいですか'」のように書きたくなってしまいます。
しかし、これでは 「'何が欲しいですか'」を一文字の単語として捉えてしまい、正確な分析は出来なくなります。
そこで、どうするのが良いのか?........!!!!
一番手っ取り早いのは、文字の間にスペースを入れることです。単語という概念を文字のレベルまで落とし、分析します。
「'何 が 欲 し い で す か'」
これだと、それっぽく分析することは可能です。
がしかし、これって、本当にいいの?....???
回答は、モノによってはダメです。
たとえば、「欲しい」をmecabで形態素解析すると、形容詞であることが分かります。
「欲」「し」「い」と分かれるモノではないのです。「欲」の後に「し」が多く出現するのは、言わずもがなかも知れません。
そこで、形態素解析を行い「'何が欲しいですか'」を「'何 が 欲しい です か'」、
このように分割していくことにします。これが一番スマートだと思いますよ。
実際に形態素解析を行って、単語区切りにしたモノを以下に示します。
<html>
<head>
<script type="text/javascript" src="https://www.gstatic.com/charts/loader.js"></script>
<script type="text/javascript">
google.charts.load('current', {packages:['wordtree']});
google.charts.setOnLoadCallback(drawChart);
function drawChart() {
var data = google.visualization.arrayToDataTable(
[ ['Phrases'],
['何 を 探し です か'],
['何 を お 探し です か'],
['何 か 探し です か'],
['何 が 欲しい です か'],
['何 を 探し て ます か'],
['何 を お 探し です か'],
['お 探し です か'],
]
);
var options = {
wordtree: {
format: 'implicit',
type: 'double',
word: '探し'
}
};
var chart = new google.visualization.WordTree(document.getElementById('wordtree_basic'));
chart.draw(data, options);
}
</script>
</head>
<body>
<div id="wordtree_basic" style="width: 900px; height: 500px;"></div>
</body>
</html>
こうすることで、以下のような構造化ツリーが表示できます。
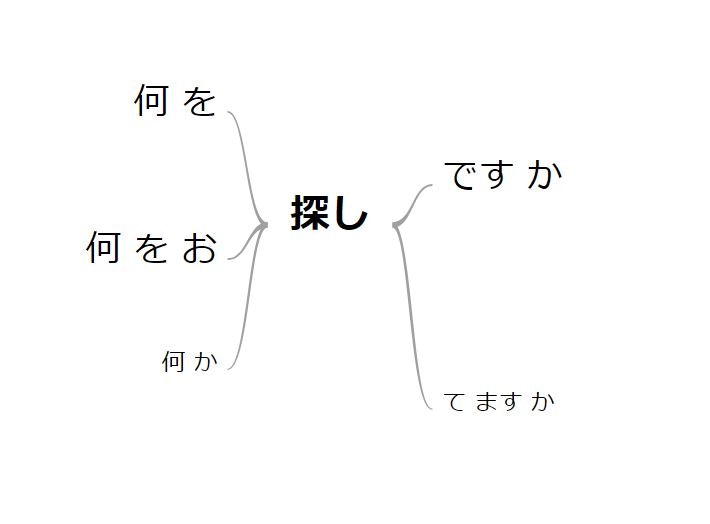
ここで、問題点として挙げられるのが、「何」「を」「探し」「です」「か」というツリーと、
「何」「を」「お」「探し」「です」「か」のツリーに分かれていることです。
両者の違いは、接頭詞の「お」が付与されているかいないかの違いのみです。
本来であれば、「何」「を」のツリーと、「何」「を」「お」のツリーは、「何」「を」までが同様のツリーとして捉えられなければなりません。しかし、この例だと、別々のツリーを作成しているため、思ったとおりの分析が出来ないです。....................orz
どなたか、この問題の解決策を知っている方がいたら教えてください!!!!!!!!!!
では、説明に戻ります。
options = wordtree:{format: 'implicit', type: 'double', word: '深し'}
と記載されている箇所があります。
ここでは、構造化ツリーの詳細を決定することが出来ます。
formatは、ツリーの構成を決定するものです。
defaultの設定を利用すると「implicit」になっています。
「implicit」とは.......。
公式HPの説明をGoogle翻訳すると、以下のように記載されていました。
『単語ツリーは、任意の順序でフレーズセットを取り、単語およびサブフレーズの頻度に従ってツリーを構成します。』
他にも、「explicit」というものがあります。こちらは、自分でいろいろと設定が出来るようになっているものです。
「explicit」とは.......。
公式HPの説明をGoogle翻訳すると、以下のように記載されていました。
『単語ツリーに何が何につながっているか、各サブフレーズを作成するにはどのくらいの大きさが必要か、どの色を使用するかを教えてください。』
なるほど............。「どの色を使用するかを教えてください。」ですか.....!
さすが、Google先生、低姿勢ですね!!
と、冗談は置いておいて、、、、
要するに、単語の大きさを極端に変更できたり、色で分けられたりできるようです。
さすが、Google先生のAPI。便利ですね~~!!
次に、typeの説明です。
typeは、ツリータイプを決定します。
デフォルトだと、typeの設定はありません。
これだと、指定した単語の右側ルートしかツリー構造を作成することは出来ません。
とっても不便!!
そこで、
私は、type: doubleを使用しています。これは、指定単語の両側にルートを取るため、両サイドにツリー構造を取ることが出来ます。
また、他にも「suffix」といったタイプもありますので、ご自分で挙動を確かめてください。
次は、wordです。
wordは、どの単語を基準にツリー構造を作成するかを決めるものです。上部の例では、"探し"という文字を基準にツリーを作成しています。
分析の肝になるものですね.......!!!
以上で、説明は終わります。皆様に幸福が訪れますように!!!
では、サヨウナラ!!