目次
1.はじめに
2.本コンペの概要
3.コンペ参加の流れ
4.コンペの順位(重要)
5.本コンペの詳細
6.次回予告
1. はじめに
本記事は、SIGNATE Student Cup 2022【予測部門】に参加する方に向けて、一緒に取り組めればと思い作成しました!
今回からSIGNATEに挑戦したい!初めて自然言語処理を始めてみよう!という方に読んでもらいたいです!
第一弾は、データ分析コンペとは何か?仕組みついて説明していきます。仕組みが分からないと、順位を上げる方法も分からないのでとても重要です!
【第二弾の記事】
【第三弾の記事】
2. コンペの概要
今回のコンペは、英語で書かれた職務内容(求人情報に乗っている要件)から職種を予測するものです。職種は以下の4種類になります。
- データサイエンティスト(DS)
- 機械学習エンジニア(ML Engineer)
- ソフトウェアエンジニア(Software Engineer)
- コンサルタント(Consultant)
つまり、自然言語に関する機械学習を使って、仕事に関する文章を学習させて予測してもらえばいいということです!
3. コンペ参加の流れ
SIGNATEやKaggleといったコンペは、主催者のお題にそって参加者が分析技術を競うというものです。分析技術は、データの加工力や機械学習モデルの作成力だったりになります。簡単にコンペの参加方法について説明していきます。基本的には、5個のステップになっています。
1個1個のステップについては、丁寧に記載されている記事が多いので紹介します。
【SIGNATE練習問題】お弁当の需要予測をやってみた(テーブルデータ)
【SIGNATE, 初心者向け】初コンペ参加と解析手法概要まとめ(Docker, Python)(テーブルデータ)
このようにweb記事で学ぶこともできますが、SIGNATE QUESTという学習コンテンツで1から学ぶことが最短で確実に理解できると思います!(筆者も初めてメダルを取れるまで、ずっとSIGNATE QUESTで勉強してました)
4. コンペの順位
初めてコンペに参加される方に注意してもらいたいのが、公開されている順位が最終順位ではないということです!
データ分析コンペでは、機械学習の汎化性能(どのデータに対しての同じような精度がでること)を高めることが目的としてあります。つまり、一部のデータでは80%の精度は出るが、他のデータで50%の精度になってしまう状態を避けたいということです。これを考慮して、以下のような順位付けを行っています。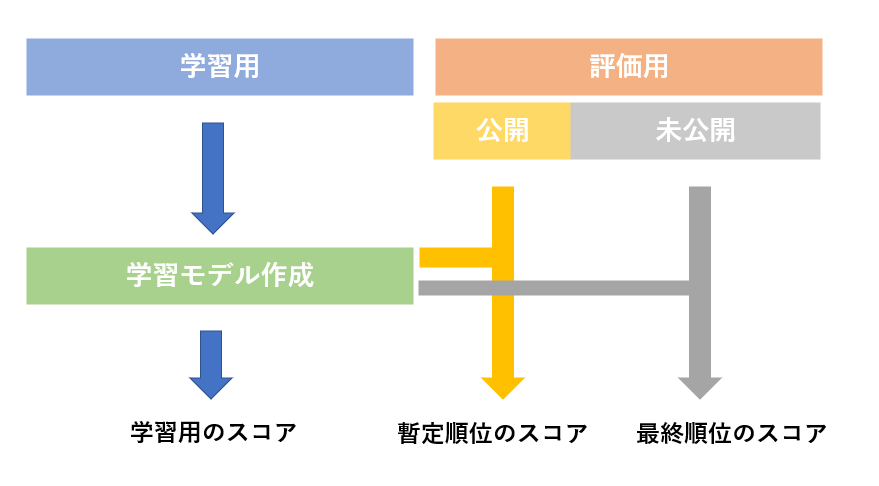
評価用のデータを予測して、コンペサイトに予測結果を提出します。この時、評価データの一部をのみしかスコア採点をしません。よって、リーダーボードに出るのは暫定順位のスコアになります。よって、暫定順位では10位だったのに、最終順位では1位になることもあります。
この最終順位のスコアは、コンペ終了後に計算されるのでコンペ終了まで何があるか分からないということです!!
上位を狙うには、学習用のスコアと暫定順位のスコアを見比べてスコアに乖離がないかを判断しながら過学習を防ぐことは重要になります。学習用で精度が80%だったのに、提出して暫定順位のスコアをみたら精度が60%だったときは過学習が起こっている可能性が高いです。
5. 本コンペの詳細
データ数を見てみると、学習用とテスト用でほとんど同じ数でした。簡単にデータについて説明すると、学習用は正解データがついたもの、テスト用は正解データのないデータです。つまり、学習用で機械学習に学習させて、テスト用の正解データを作る(予測する)という感じです!
| 学習用 | テスト用 | |
|---|---|---|
| データ数 | 1516 | 1517 |
実際にデータの中身を見てみます。データの種類は3種類でした。
| カラム名 | 概要 |
|---|---|
| id | データに順番に振ってある番号のようなもの |
| description | 仕事の内容を記載した文章 |
| jobflag | 職種のラベル(DSなら1、Consultantなら4といった感じ) |
評価指標は、F1 Macroスコアを採用しています。このスコア指標は、分類データの数に偏りがある時に使用することが多い指標です。今回のデータだと、コンサルタントが500個・機械学習エンジニアリングが80個のデータになるので、データの数に偏り(不均衡)があるためこの指標を使っているのだと思います。
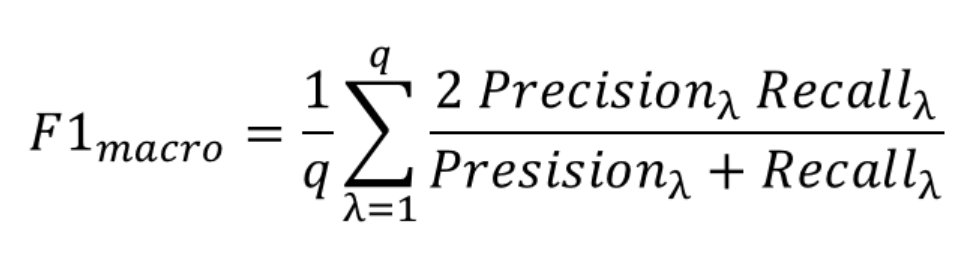
詳しくは、以下のリンクを参照してみてください。
5. 次回予告
第二弾では、自然言語モデルであるBERTを使用して予測を行っていきます。BERTのコードは複雑で何を書いてあるか分からない、どこを改良すればいいか分からないという方も多いと思うので解説しながら書いていきます。
本記事を気に入って頂けたら、「LGTMボタン、コンペのフォーラムでのいいね」をお願いします!
【第二弾の記事】
【第三弾の記事】