はじめに
弊社でデータ基盤を構築する際、データパイプラインとしてAirflowを採用しました。
その際、つまづいた箇所がいくつかあったので書き記しておきます。
弊社でのAirflow
弊社では機械学習を使用したシステムを複数、開発運用しています。
プロジェクトが増え、運用が進んでいく上で共通して以下のような要望を満たすものが必要になってきました。
- 必要な複数のデータソースに一つのエンドポイントでアクセスできる
- 同じクエリであればどんな時でも同じ結果が返ってくる
- クエリが詰まらない
そこで、我々はデータ基盤が必要なフェーズだと判断し、構築するに至りました。
データ基盤を構築する際に元のデータをデータウェアハウスやデータマート用に加工する必要があります。
その際にデータパイプラインとして以下のような要件を満たす必要がありました。
- 同じロジックであればエラー等で中断再開する、データが作成された状態で最初から叩き直すといった状況でも最終的に作成されているデータは同じになる
- 一日分ごとにデータ処理が行われる
- 処理が失敗したことにすぐに気づくことができ、どこの処理から再開すればいいか明確になっている
これらを満たせそうなツールとしてAirflowを採用しました。
概念図でいうと下の部分です。
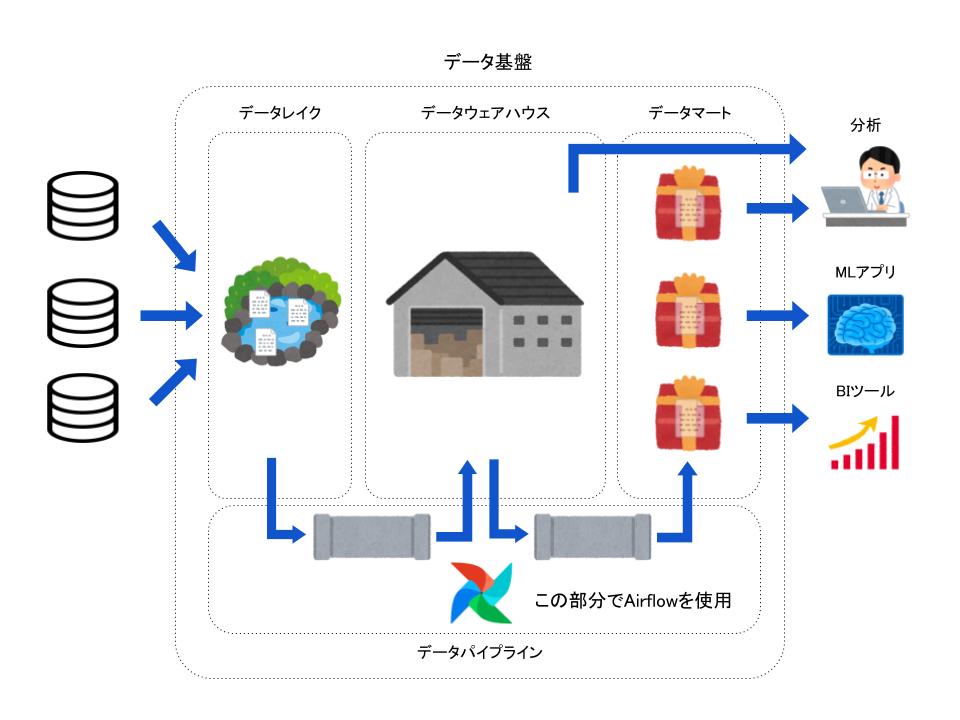
Aiflowでは上記の要件を満たすように実装を行いました。
- 前回分までのTaskInstanceが完了するまで今回分のTaskInstanceを動かさない
- 仮に作成したいデータがすでに作られていた場合はタスクをskipする
- 過去分を処理後、日時で実行する
- 今回分のTaskInstanceが成功した、失敗した場合は通知を出す
前提
Airflowのバージョンは1.10.5です。
つまづき1. execution_dateと実行日
default_args = {
'owner': 'Airflow',
'start_date': datetime(2019, 12, 1),
}
dag = DAG('tutorial1', default_args=default_args,
schedule_interval=timedelta(days=1))
このコードはexecution_dateが2019-12-01T00:00:00+00:00から
12/1, 12/2, 12/3 ...といったように実行され、過去分の実行が終了すると一日ごとの実行になります。
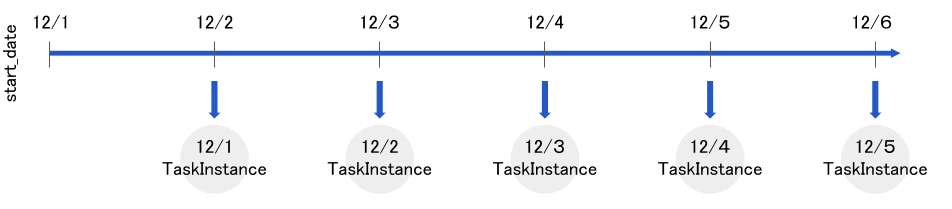
この時、今日が2019-12-06T01:00:00+00:00(UTC)だったと仮定するとexecution_dateがいつになるまで実行されるでしょうか。
答えは2019-12-05T00:00:00+00:00(UTC)までのTaskInstanceが実行されます。
私は今日の日付が12/6になったらexecution_dateが12/6のところまで実行されると勘違いしていました。
以下イメージ図です。
これに加えてタスク内でタイムゾーン:Asia/Tokyoで時間を扱いたい等の要件が重なると
混乱する可能性も高くなるので気をつけてください。
つまづき2. 前日分のTask Instanceを待つ
前日のTaskInstanceの実行結果を使用して本日分の処理を行う必要があったため、
本日分のTaskInstanceは前日分までのTaskInstanceの成功を待つ必要がありました。
そのため、前回のTaskInstanceの特定のタスク結果を待つwait_for_downstreamを使用しました。
t1 = BashOperator(
task_id='print1',
bash_command='echo 1',
wait_for_downstream=True,
dag=dag)
しかし、wait_for_downstreamは前回のTaskInstance全体の結果を待つわけではありません。
t1 = BashOperator(
task_id='print1',
bash_command='echo 1',
wait_for_downstream=True,
dag=dag)
t2 = BashOperator(
task_id='print2',
bash_command='echo 2',
wait_for_downstream=True,
dag=dag)
t1 >> t2
と記述した場合、前回分のt1タスクが完了した時点で(t2の完了を待つことなく)、今回分のt1タスクが実行されます。しかし、今回分のt1タスクは前回分t1,t2タスクどちらも待つ必要があります。
そこでExternalTaskSensorを使用し、前回分の最後のタスクを待つように設定しました。
t_check_previous_dag_run = ExternalTaskSensor(
task_id='is_success_pre_dag_run',
external_dag_id=dag.dag_id,
allowed_states=['success', 'skipped'],
external_task_id='your_last_task_id',
execution_delta=timedelta(days=1)
)
# t1は最初に実行したいtask
t_check_previous_dag_run >> t1
しかし、この記述だけだと最初に動くTaskInstance(execution_date=start_date)
が存在しないタスクの完了を待ちつづけ、先に進まなくなります。
そのため、さらに
# is_initialは最初の実行か判定するための関数をuser_defined_macrosで設定して使用している
t_check_is_initial = BranchPythonOperator(
task_id='is_initial',
python_callable=lambda is_initial_str: 'do_nothing' if is_initial_str == 'True' else 'is_success_pre_dag_run', # NOQA
op_args=['{{ is_initial(execution_date) }}']
)
t_do_nothing = DummyOperator(
task_id='do_nothing'
)
# skipされないようにtrigger_rule='none_failed'を設定
t1 = BashOperator(
task_id='print1',
bash_command='echo 1',
trigger_rule='none_failed',
dag=dag)
t_check_is_initial >> t_check_previous_dag_run >> t1
t_check_is_initial >> t_do_nothing >> t1
といったコードを書き、最初の実行ではExternalTaskSensorをSkipすることで回避しました。
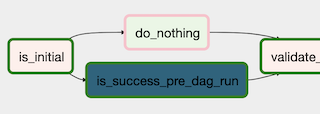
冗長になりましたが前日のTaskInstanceを待つことが明確になりました。
とはいえはやはり冗長なので必ず前日の実行結果を待つ別の方法を知っている方はご教授ください。
つまづき3. ShortCircuitOperator,Skipステータスのルール
ShortCircuitOperatorはpython_callableで宣言された関数がfalseを返した時、後続のタスクを全てに対してskipステータスを付与します。
そのため、直後のタスクはskipするががさらに先のタスクは実行させたいといったことができません。
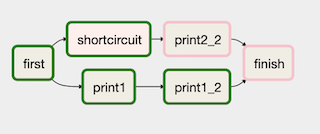
上記の例ではshortcircuitタスク(ShortCircuitOperator)を使用してprint2_2はskipさせてfinishタスクを実行させるといったことはできません。
またBranchPythonOperatorにおいても後続のタスクのtrigger_ruleをデフォルトのall_successにしていると似たようなことが起こります。
t0 = BranchPythonOperator(
task_id='first_and_branch',
python_callable=lambda: 'print1',
dag=dag)
t1 = BashOperator(
task_id='print1',
bash_command='echo 1',
dag=dag)
t2 = BashOperator(
task_id='print2',
bash_command='echo 2',
dag=dag)
t3 = BashOperator(
task_id='finish',
bash_command='echo finish',
dag=dag
)
t0 >> t1
t0 >> t2
t1 >> t3
t2 >> t3

finishタスクのtrigger_ruleがall_sucessだと親タスクのどれか一つでもskipステータスになるとskipステータスになります.
親のタスクに一つもfailステータスがついていない場合にはfinishタスクを実行させたい場合は
下記のようにtrigger_ruleを'none_failed'に設定すると想定通りの動きになります。
t3 = BashOperator(
task_id='finish',
bash_command='echo finish',
trigger_rule='none_failed',
dag=dag
)
なお、first_and_branchタスクの部分がShortCircuitOperatorでpython_callableの結果がfalseであった場合、後続タスクはtrigger_ruleに関わらず全てskipステータスになります。
つまづき4. 失敗時の通知
なにかのタスクが失敗した場合はslack通知を送れるようにdefault_argsを使用して
下記のように記述しました。
def send_slack():
# slack通知を出す処理
default_args = {
'start_date': datetime(2019, 12, 1),
'on_failure_callback': send_slack
}
しかし、この書き方の場合、なんらかの理由でslack通知がされなかった時にairflowの管理画面にその旨が表示されません。そのため、slack通知タスク自体がこけていることに気づくことができないことがありました。
そのため、以下のようにタスクの最後にslack通知を送ることを明示することでslack通知自体が失敗していても管理画面を見ればそれに気づくことができるようになりました。
t_finish = DummyOperator(
task_id='task_finish',
trigger_rule='none_failed',
)
# 独自に作成したSlack通知を送るOperatorを使用
# trigger_ruleでtaskを振り分けることで成功失敗に関わらず通知がとぶ
t_notification_on_success = CustomSlackOperator(
task_id='notification_on_success',
trigger_rule='none_failed'
)
t_notification_on_failed = CustomSlackOperator(
task_id='notification_on_failed',
is_success=False,
trigger_rule='one_failed'
)
t_finish >> t_notification_on_success
t_finish >> t_notification_on_failed

slack側の設定がいつの間にか変更されていることが原因で通知自体が失敗するといったことも考えられるので
通知タスクも明示しておいたほうが安心できると思います。
まとめ
他にも細かい部分でつまづきましたが、
ドキュメントをしっかり読めば解決するパターンがほとんどでした(時にはソースコードも読みましたが)。
Airflowは
- Dagをpythonコードで柔軟に定義できる
- 過去分はバッチのように動作し、それ以降は定期実行のように動作する(表現が難しい。。)
といったことができる数少ないツールです。
そのため、複数の複雑なタスクを定常的に動かす際は有力な候補になりうるツールだと思います。