はじめに
こんにちは。株式会社ジールの@yakisobapanです。
AWS Glueにて、ジョブのキューイング機能が提供開始されましたので、試してみました!
目次
- アップデート内容
- やってみた
- 所感
アップデート内容
AWSはAWS Glueジョブのジョブキューイングを追加しました。
この新しい機能により、アカウントレベルのクォータや制限を管理することなく、AWS Glue ジョブを投入することができます。
AWS Glue ジョブキューイングは、アカウントレベルのクォータと制限を監視します。
ジョブの実行を開始するためにクォータやリミットが不足している場合、Glue は自動的にジョブをキューに入れ、リミットが解放されるのを待ちます。
制限が利用可能になると、Glue はジョブの実行を再試行します。
ジョブは
・アカウントあたりの最大同時実行ジョブ数
・最大同時実行データ処理ユニット数(DPU)
・Amazon VPCのIPアドレス枯渇によるリソース利用不可
などの制限のために、キューに入れられます。
AWS Glue のジョブキューイングは、AWS Management コンソールまたは API/CLI を使用して有効にすることができます。
AWS Glue now provides job queuingより引用
(2024/09/04 What's New with AWS?)
今回のアップデート機能を利用することで、
サービスクォータの制限によるエラーや、
サブネット内で利用できるIPアドレスが枯渇した際に発生する「The specified subnet does not have enough free addresses to satisfy the request」エラー
などにも、簡単に対応できるようになりました。
通常であれば、エラーとなりジョブが失敗してしまうところ、
リソースが確保できるまで待ち、失敗させずにジョブを継続させるようにできます!
やってみた
サービスクォータの上限に触れてみました。
サービスクォータの確認
- マネジメントコンソールからアカウントのGlueのクォータを確認
※アカウント、リージョンごとにデフォルト値は異なります。
一番お手頃(?)そうな Max task DPUs per account
(アカウントあたりの最大タスク DPU)、こちらを選択

クォータに抵触するパターンとして挙げられる候補は他には以下かなと思います。
・ Max concurrent job runs per account (アカウントあたりの最大同時ジョブ実行数)
※デフォルト:2,000
・ Max concurrent job runs per job (ジョブあたりの最大同時実行数)
※デフォルト:4,000
従来の挙動
DPUが同じ2つのジョブを用意して、前ジョブが動いているうちに後ジョブを動かしてみます。
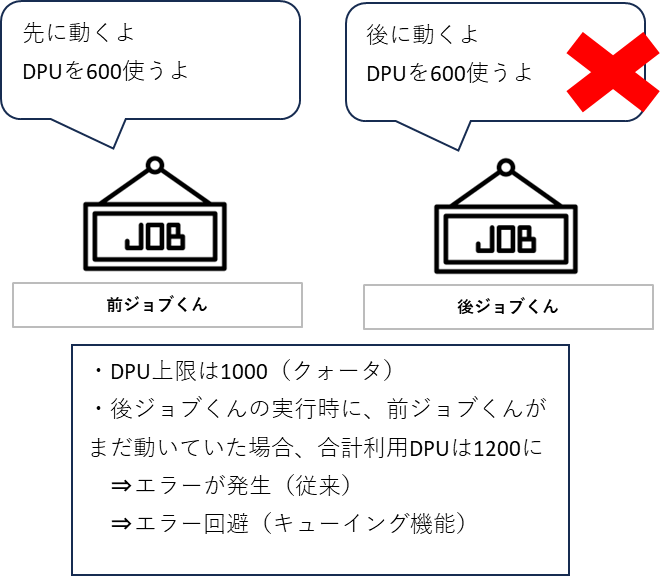
- 前ジョブくん(Job_Run_Queuing) / 後ジョブくん(Job_Run_Queuing_waiting)の作成
・Engine:Spark
・WorkerType:G.1X
・Number of workers:600
G.1X = 1DPUなので、1回の実行で600DPUを利用
-
前ジョブくん(Job_Run_Queuing)の実行
ここは普通に開始します。

-
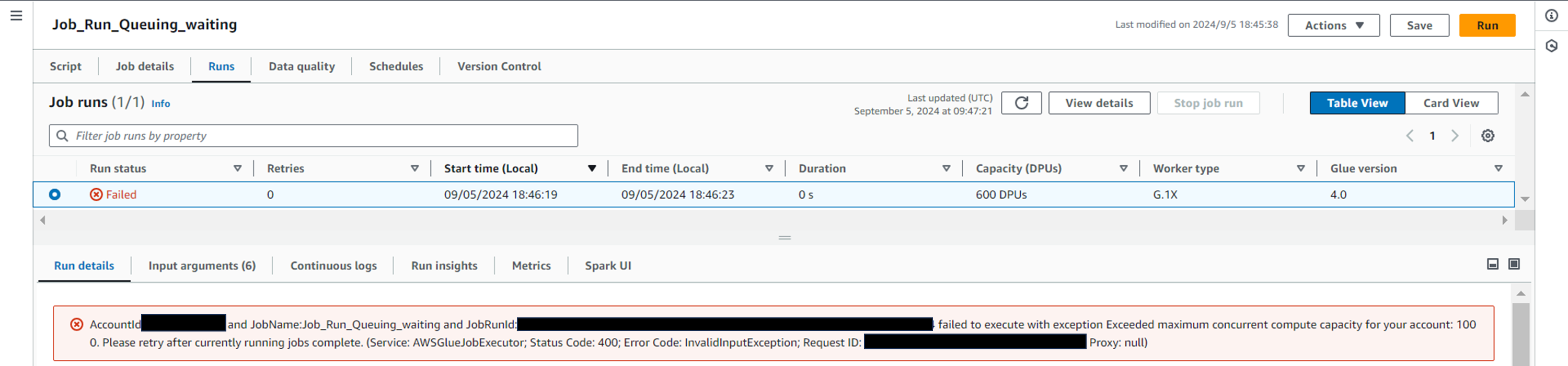
後ジョブくん(Job_Run_Queuing_waiting)の実行
前ジョブくんが実行中のうちに、後ジョブくんを実行開始します。

しばらくして、以下メッセージと共にエラーで終了します。
failed to execute with exception Exceeded maximum concurrent compute capacity for your account: 1000. Please retry after currently running jobs complete.
ここまでは、従来の挙動でした。
キューイング使用
後ジョブくんにキューイング機能を付けて実行してみます。
- 後ジョブくん(Job_Run_Queuing_waiting)の設定変更
・Job Run Queuing:✓
※キューイングを有効にすると、Flex execution(フレックスジョブ)、Number of retries(ジョブリトライ)が無効になります

- 前ジョブくん(Job_Run_Queuing)の実行
ここは普通に開始します。
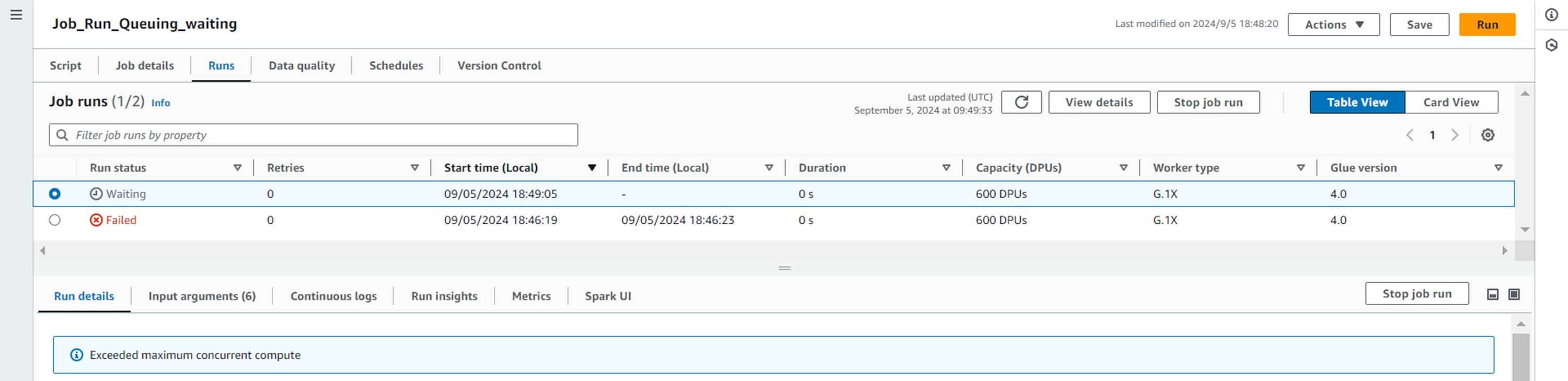
- 後ジョブくん(Job_Run_Queuing_waiting)の実行
・前回なら、ここでエラーになりましたが

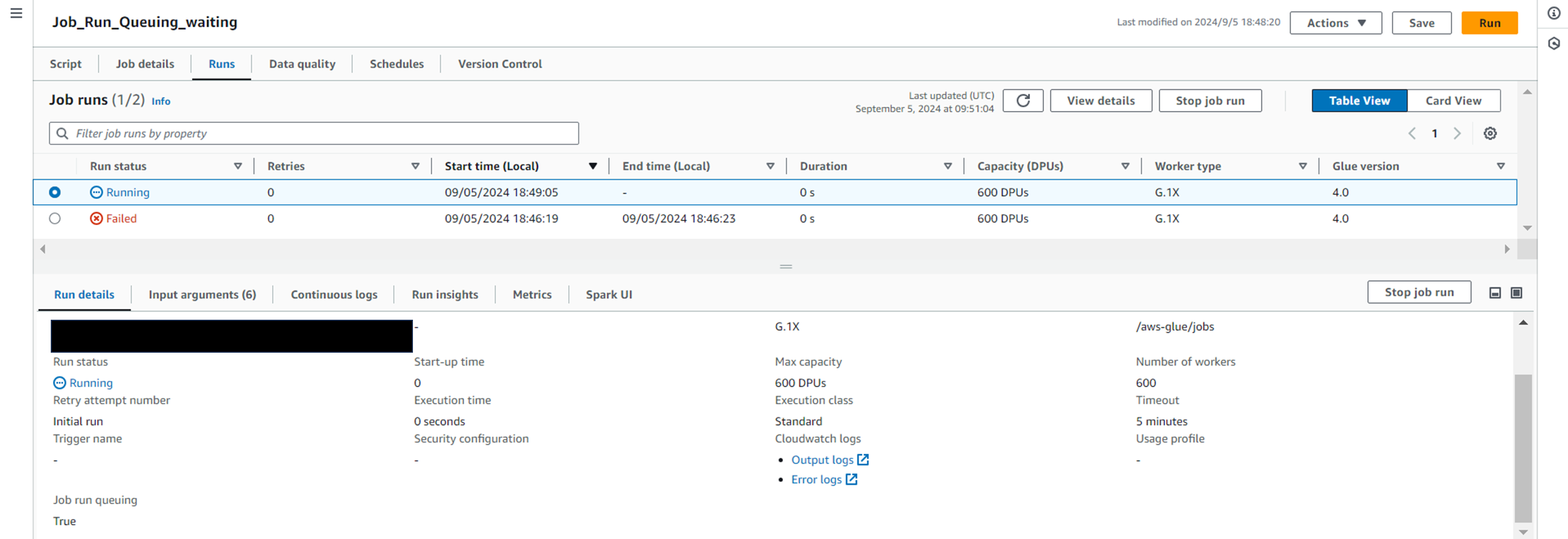
・今回はWaitingというステータスになっています!
理由も表示してくれています。
Exceeded maximum concurrent compute
・前ジョブくんの完了を待って、Runningに移行しました。
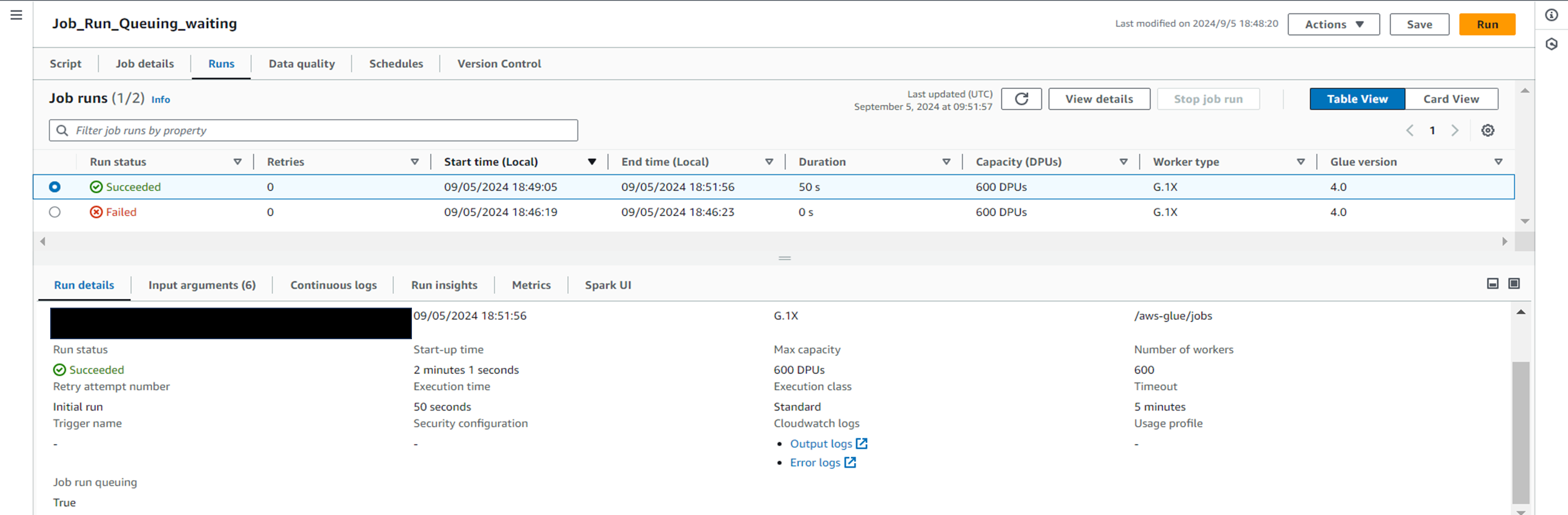
・何事もなかったかのように正常終了しました。
所感
- まとめ、ユースケース
今回のアップデートによって、従来サービスクォータやリソースの利用上限到達によって発生するジョブの異常終了を、回避できるようになりました。
これにより、想定外の「ジョブ同時実行」や「リソース使用」が発生した場合でも、処理を停止することなく、継続することができます。
私自身、サブネットのIPアドレス枯渇により、ジョブが失敗した事例は遭遇したことがあります。
ユースケースとして、
・恒久対応(サブネット拡張やクォータ緩和申請)にリードタイムがかかる場合を考慮して、その間の暫定対応として利用
・上記に関連して保険として設定
というケースが考えられると思います。
最大同時実行数やリソースのピークを測定し、ジョブ設計をしっかり行うことで上限に抵触するケースはほぼ避けられると思います。
ですので、キューイング機能に頼るのではなく、保険的に実装するのが良いと考えました。
- 気になる点
当然ですが、「キューイングされたジョブ」をトリガーとして動く
後続ジョブやイベントが待機していた場合、伴って後ろ倒しにはなるので、こちらの考慮は必要です。
また、Glue Trigger等で明確に前後関係が作られているジョブ間でしたら、問題ないですが、
「ジョブAの1時間後に、ジョブBを起動」等の実装がされている場合、実行順番が入れ替わる等の事象は発生するので注意が必要です。
本キューイング機能が、「どの程度のジョブを保持して待機させてくれるのか」は気になるポイントですが、今後発表される情報を追いつつ、確認していこうと思います。
参考
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください: