スーパーのチラシを毎日見てチェックするのは大変なので、
OCRをかけて自分が狙っている商品が出たら通知が来るようにしたら便利でした。
仕組み
- スーパーの公式サイトからチラシPDFのリンク一覧を取得
- 新規のチラシかどうかチェック
- 新規のチラシのPDFをDLする
- PDFをJPGに変換する
- Google Cloudの Cloud Vision API
でOCRをかける - 指定したキーワードが存在するかチェック
- キーワードに引っかかればSlackに通知を送る
Pythonで作りました。
1. 公式サイトからリンク一覧を取得
BeautifulSoup4というHTMLを解析してくれるライブラリを用いました。
公式サイトのHTML構成を確認しながら実装すれば簡単にできます。
# 公式サイトからpdfリンク一覧取得
def get_urls():
import requests
from bs4 import BeautifulSoup
html = requests.get('★公式サイトURL')
soup = BeautifulSoup(html.text, 'html.parser')
# ★以下は実際のHTML構成に合わせて実装する
flyer_list = soup.find_all('table')
url_list = []
for flyer in flyer_list:
# 日付
date = flyer.find('div', {'class': 'sale'}).find('a').get_text(strip=True).replace(' ', '').replace('(', '(').replace(')', ')')
# PDF
url_info = {}
url_info['date'] = date
url_info['url'] = flyer.find('a', {'title': 'PDF'})['href']
url_list.append(url_info)
return url_list
2. 新規のチラシかどうかチェックする
チラシは何日かにわたって掲載されますが、同じチラシで通知しても意味がないため、
前日に確認したチラシのURL一覧の情報をurls.txtに保持しておいて新規のチラシかどうかチェックしています。
# 未解析のチラシURLを取得
def get_new_urls(url_list):
# urls.txt読込
old_url_list = []
with open('/urls.txt', 'r') as f:
old_url_list = f.read().splitlines()
new_url_list = []
urls_text = []
count = 0
for url_info in url_list:
urls_text.append(url_info['url'] + '\n')
if url_info['url'] not in old_url_list:
# 新規
url_info['number'] = count
new_url_list.append(url_info)
count += 1
# 今回のURL一覧をurls.txtに書込
f = open('/urls.txt', 'w')
f.writelines(urls_text)
f.close()
return new_url_list
3. 新規のチラシのPDFをDLする
公式サイトのサーバーに負荷がかからないように時間をおいてDLしています。
# 新規のチラシPDFをDL
def dl_pdfs(new_url_list):
import urllib.request
import time
pdf_list = []
for url_info in new_url_list:
file_name = f'./pdf/{url_info["number"]}.pdf'
urllib.request.urlretrieve(url_info['url'], file_name)
url_info['pdf_path'] = file_name
# サーバーに負荷がかからないように時間をおく
time.sleep(2)
pdf_list.append(url_info)
return pdf_list
4. PDFをJPGに変換
Vision APIでPDFをそのままOCRしてもうまくいかなかったので、
pdf2imageというライブラリを使用してJPGに変換かけました。
これはPopplerというフリーのPDFコマンドラインツールを背後で用いているため、
Popplerをlib/popplerにダウンロードしています。
こちらのブログ記事を参考にさせていただきました。
# PDFをJPGに変換
def pdf_to_jpeg(path):
import os
from pathlib import Path
from pdf2image import convert_from_path
# poppler/binを環境変数PATHに追加する
poppler_dir = '/lib/poppler/bin'
os.environ['PATH'] += os.pathsep + str(poppler_dir)
image_paths = []
pdf_path = Path(path)
# PDF -> Image に変換(150dpi)
pages = convert_from_path(str(pdf_path), 150)
# 画像ファイルを1ページずつ保存
image_dir = Path('./jpg')
for i, page in enumerate(pages):
file_name = pdf_path.stem + '_{:02d}'.format(i + 1) + '.jpeg'
image_path = image_dir / file_name
# JPEGで保存
page.save(str(image_path), 'JPEG')
image_paths.append(image_path)
return image_paths
5. Google Cloudの Cloud Vision APIでOCRをかける
Cloud Vision APIは毎月1000ユニットまでは無料なので
毎日チラシをOCRかけるくらいであれば無料で利用できます。
Vision APIを使うためには事前にいろいろと設定する必要があります。
- Google Cloudでプロジェクトを作成
- Vision APIを有効にする
- 認証の設定をする
詳しいやり方は調べればたくさん出てくるので、他のサイトを参考にしてください。
# OCR
def detect_text(image_paths):
from google.cloud import vision
import io
client = vision.ImageAnnotatorClient()
all_text = ''
for image_path in image_paths:
with io.open(image_path, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations
for text in texts:
all_text += str(text.description)
if response.error.message:
raise Exception(
'{}\nFor more info on error messages, check: '
'https://cloud.google.com/apis/design/errors'.format(
response.error.message))
return all_text
6. 指定したキーワードが存在するかチェック
# キーワード検索
def search_words(all_text):
hitwords = []
# ★任意のキーワード(商品名)を設定
keywords = ['ヨーグルト', '若鶏もも肉']
for keyword in keywords:
if keyword in all_text:
hitwords.append(keyword)
return hitwords
7. Slackに通知を送る
Incoming Webhookを用いてSlackに通知を送ります。
def slack_notice(results):
import slackweb
slack = slackweb.Slack(url='★WebhookのURL')
for result in results:
text = f'{result["date"]} チラシ掲載商品:{",".join(result["hitwords"])}\n<{result["url"]}|チラシを見る>'
slack.notify(text=text)
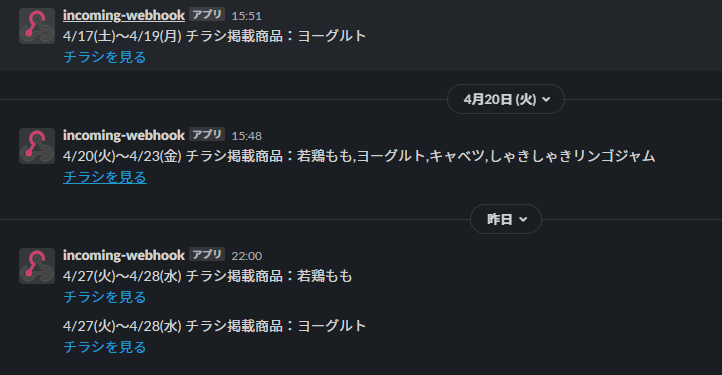
結果
こんな感じになりました。
毎日チラシをチェックしなくても通知してくれるのでとても便利です!
本当はキーワードごとに値段を記録して、閾値より安ければ通知するといった方法を取りたかったのですが、
チラシは文字の配置や配色が複雑すぎて商品名と値段を紐づけて取得することが難しかったので断念しました。
全ソースはこちらに置いてあります。
https://github.com/yakipudding/flyer-ocr