ミクシィグループ Advent Calendar 2018 11日目の記事です
はじめに
「機械学習が適用できる部分はないか」と、世の中のどんなプロダクトも検討したのではと思いますが、実際にプロダクトへ組み込むとき、モデル更新など運用の面倒くささや、機械学習コードのメンテナンスを嫌って、導入を見送ったケースがあるかもしれません
今回は、そうした残る「面倒くささ」を引き取ってくれ、データセットの準備やモデル更新まで面倒を見てくれる丸投げサービスと、それによって効果の出るケースを考えてみたいと思います
不適切投稿をみつける、という課題
ブログや画像投稿サイトなど CGM (Consumer Generated Media:ユーザーの投稿で成り立つメディアサービス) を運営する場合、誹謗中傷や違法行為など、不適切な投稿の検知/対処は必須要件です
プロダクトの小さいうちは何人かのメンバーがときどきチェックするだけで済んでいたのが、規模拡大につれ専任のコンテンツ管理者が登場し、次第に24/365シフトを敷いた対応チームができる.. というのはよくある流れだと思います
不適切投稿への対処はメディアの信頼にかかわる仕事ですが、その発生パターンは「少ないけれど毎日確実に存在する」といったものになりがちです.たとえば 毎日 10 万件 の投稿があり、うち不適切投稿は 100 件(0.1%) といった具合ですが、残り 99.9% の問題ない投稿もチェックしなければならず、その作業は 重要 だが 多くの徒労 を強いられる ものといえます
課題の特徴
こうした人的資源の浪費は、機械で解決したい課題の有力候補でしょう
またこの課題の特徴は、「不適切さ」はサービス特性以前に 「一般的な社会通念」に依存している 点にあります.特定サービスに依存したデータより、世間一般のデータで学習してくれるほうが、より好ましく社会通念を含んだものになりそうです
過去の投稿群を学習データに分類モデルを作ることもできますが、この課題の場合、先に書いたような煩わしさを負わずに、かつより好ましいモデルを将来にわたって手に入れる方法があります
解決策の例
「不適切コンテンツ検出」といったまさに用途にフィットする便利サービスが、API の形でクラウドベンダーから提供されています.今回はこれを利用します
構成と処理フロー
もともと人間が監視して危険度判断/対処していたフローに、機械的な判断と判断に基づく対処を加えます(図の破線枠内)
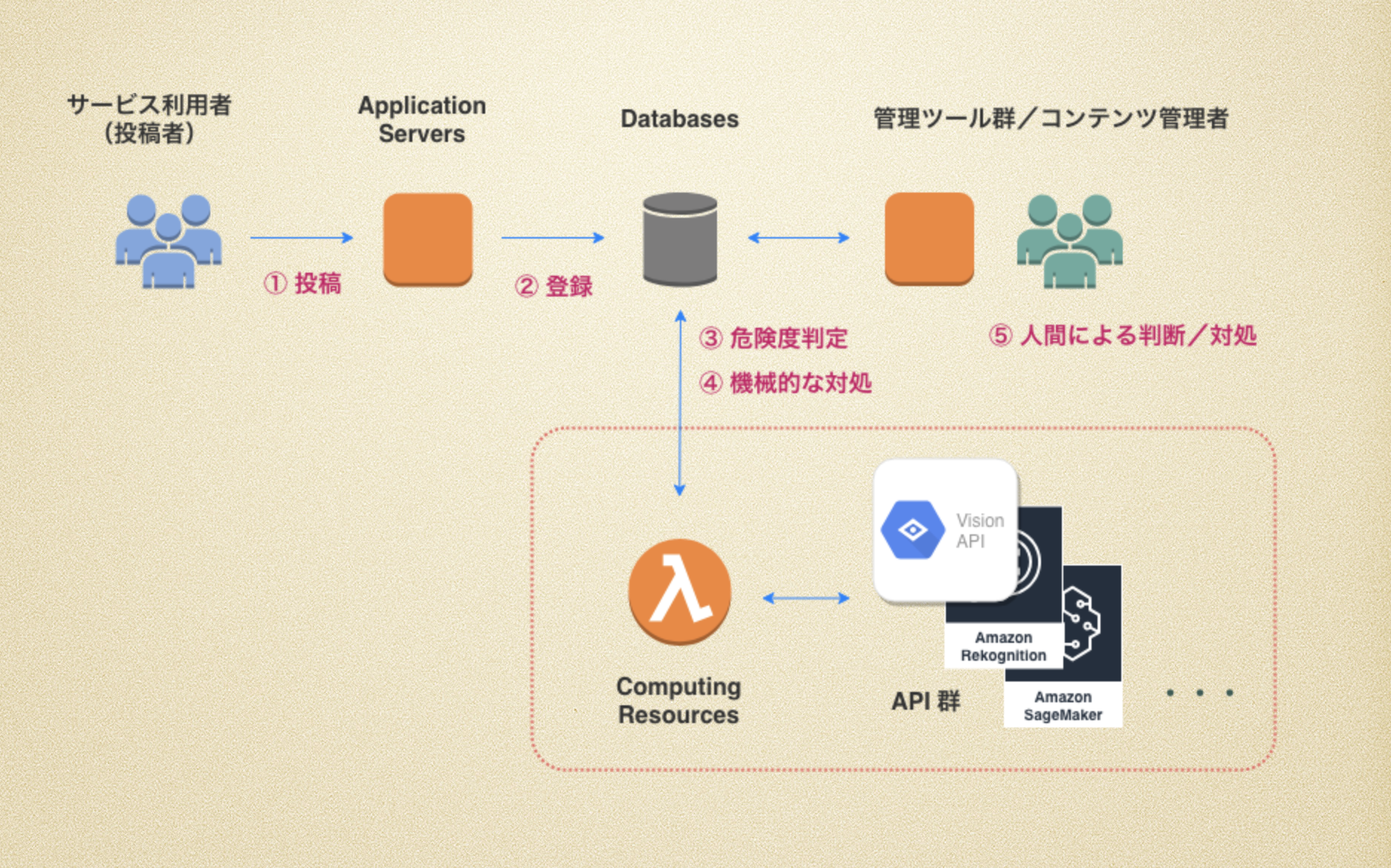
- ユーザによって投稿が登録される
- 投稿がデータベースに格納される
- データ格納されたことをトリガにして、1件ごとに投稿内容から不適切度を判定する
(安全 1 <-> 5 危険5 段階 など) - 不適切度に応じて、自動処理できるものは機械的に処理する
(レコードのステータス更新)- 「安全」と判断されれば監視対象から除外する
- 「危険」と判断されれば他ユーザから見えないようにする/投稿削除する など
- 機械的な判断の難しい投稿を監視チームが人力判断/対処する
(管理ツールを使って監視し、違反レコードに対してステータス更新)
適用する便利サービス
次のようなサービス群から、コンテンツの種類や既存システムへの導入のしやすさを考慮して選択します
-
Google Cloud Vision API
-
Amazon Rekognition
-
Azure Content Moderator
どれも API エンドポイントへリクエストを投げるだけなため、 アプリケーションコードの改変は少な く、インフラ不要で利用分のみ課金となるため、 運用コストもサービス規模にフィット したものにできます(規模に応じた課金になり、従量課金も非常に安価です)
しかもモデル精度の向上はベンダー側で自動的に行われ、メンテナンスコストも不要 です.潤沢な研究リソースと大量データをもつクラウドベンダーのほうが効率よく学習でき、最新アルゴリズムによる恩恵も期待できます
適用方法の概要
Google Cloud Vision API を例として、具体的な導入例をみてみましょう
(Vision API は画像コンテンツを対象とした API サービスです)
GCP のセットアップ
新規に利用する場合はアカウント作成や契約周りの作業が必要ですが、ドキュメントなどを参照してプロジェクト作成まで行います
https://cloud.google.com/resource-manager/docs/creating-managing-projects?hl=ja
API の有効化
所有しているプロジェクトについて、Cloud Vision API のリソースを有効化します
https://cloud.google.com/vision/docs/before-you-begin
認証情報の設定
API キー/サービスアカウント のどちらかをセットアップします
https://cloud.google.com/vision/docs/auth
(簡易に利用する場合は API キーが便利ですが、ドキュメントにそって不正使用防止設定をします)
最も単純な認証方式は API キーですが、API キーではサービスの承認を受けることができないため、使用の対象は公開データや、直接 RPC API に渡されるデータに限られます。対照的に、サービス アカウントは最も有用な認証方式といえます。この方式を使用すると、サービス アカウントの認証情報をサービスに送信するようにコードを構成することによって Cloud API にアクセスできるからです。
Google Cloud Platform API にアクセスするときは、テスト環境に API キーを設定し、本番環境にサービス アカウントを設定することをおすすめします。
API リクエストの送信
先に設定した認証情報をセットして、次のようにエンドポイントへリクエストを送信すれば、引き渡した画像に対するレスポンスが得られます
https://cloud.google.com/vision/docs/request
- 画像データの base64 エンコーディング
https://cloud.google.com/vision/docs/base64
$ base64 input.jpg > img_base64.txt
/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z
- リクエストJSON
image.contentに base64 エンコードしたテキストを入れます.またfeatures.typeにSAFE_SEARCH_DETECTIONを指定して、不適切コンテンツの検出をリクエストします
https://cloud.google.com/vision/docs/detecting-safe-search#vision-safe-search-detection-protocol
{
"requests": [
{
"image": {
"content": "/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z"
},
"features": [
{
"type": "SAFE_SEARCH_DETECTION"
}
]
}
]
}
- リクエスト送信と結果
上記JSON を指定して送信すると、不適切コンテンツとしての判定結果が得られます
$ curl -s -H 'Content-Type: application/json' 'https://vision.googleapis.com/v1/images:annotate?key=YOUR_API_KEY' -d @request.json
{
"responses": [
{
"safeSearchAnnotation": {
"adult": "VERY_UNLIKELY",
"racy": "VERY_UNLIKELY",
"spoof": "UNLIKELY",
"violence": "LIKELY",
"medical": "VERY_LIKELY",
}
}
]
}
結果例の場合、「アダルトコンテンツである可能性は低く、医療行為や暴力的な画像である可能性が高い」という判定であることを示しています
(セーフサーチプロパティに関する詳細は 不適切コンテンツのフィルタリング 記事を参照ください)
アプリケーションへの組み込み
REST API なため、どんな言語のどんなアプリケーションでも容易に組み込めます
データ発生をトリガにして危険度判定結果をレコード反映させたり、登録されたデータを定期的にチェックするスクリプトにしたり、運用しやすいようにするとよいでしょう
判定結果をもとに機械処理する場合は、危険度の低いものをチェック済みとしたり、逆に危険度の高いものを公開停止や削除するなどします.また危険度を管理ツールから参照し、危険度の高いものを優先対応したり、危険度別で監視できるようにします
(実装ここまで)
精度の評価
API の判断が妥当かどうかは、実データで人間の判断と照合して評価します
判断結果の記録
管理ツールがあれば投稿監視のためのデータベースがあると思いますが、次のようなテーブルを用意して「人間判断」と「機械判断」の違いが計測できるようにします(レコードごとに人間と機械の判断結果がわかればなんでもOKです)
| カラム | 概要 |
|---|---|
| 投稿 ID | レコードごとのユニークID |
| ・・・ | ・・・ |
| 人間による判断結果 | 未判定 /問題なし(安全) /問題あり(危険) |
| 機械による推論結果 (危険度) |
1 (安全:VERY_UNLIKELY) ~ 5 (危険:VERY_LIKELY) |
| ・・・ | ・・・ |
集計
「人間判断」を真の評価、「機械判断」を推論結果として表(件数)にまとめます.
(話を簡単にするため数字は単純化しています)
| 人間判断(真の危険度) | ||||
|---|---|---|---|---|
| 問題あり(危険) | 問題なし(安全) | 総計 | ||
| 機械判断 (推論値) (危険度) |
5 | 50 | 2950 | 3000 |
| 4 | 25 | 4975 | 5000 | |
| 3 | 15 | 11985 | 12000 | |
| 2 | 7 | 37993 | 38000 | |
| 1 | 3 | 41997 | 42000 | |
| 総計 | 100 | 99900 | 100000 | |
上記の集計例では、おおむね人間判断と機械判断が似通っていることが読み取れます(人間が危険と判断するものは機械も危険度が高い).
また大多数のレコードは危険度の低い判定( 危険度 1-2 で全件の 80% )であること、機械が危険と判断したうち、多くは人間判断で問題なしとなる(誤警報)ことなどがわかります
結果の評価
「機械判断」が「人間判断」と異なる部分が 誤り(False) ですが、誤りが小さいほど精度が高いといえます(表中の色文字が誤り)
参考:スレットスコア
| 人間判断 =真の評価 (Observation, Results) |
|||
|---|---|---|---|
| 問題あり | 問題なし | ||
| 機械判断 =稀事象の予報、推定 (Forecast, Estimate) |
問題あり (Positive, 陽性) |
TP 真陽性 (True Positive) 稀事象を適中した重要な正解 (hits) |
FP 偽陽性 (False Positive) 第一種過誤 (type-I error) 空振り,誤警報 (false alarms) |
| 問題なし (Negative, 陰性) |
FN 偽陰性 (False Negative) 第二種過誤 (type-II error) 見逃し (misses) |
TN 真陰性 (True Negative) ありふれた事象を適中した正解 |
|
今回の事例はいわゆる「間違いのコストが不均等なモデル」で、 「空振りによる損失」より「見逃しによる損失」のほうが大きいケース です.やや敏感に危険判定しても監視チームの負担が残るだけですが、見逃しを発生させればサービスの信頼を損ねてしまいます
そのため、 Recall を重視しつつ、人力作業をできるだけ削減 できることを評価します
(精度指標として Accuracy が一般的ですが、この事例では Recall を重視します)
- Accuracy
- 正解率:人間判断と機械判断の一致率
Accuracy = \frac{( TP+TN )}{( TP+FP+FN+TN )}
- Recall
- 網羅率:人間判断「問題あり」のうち、機械判断で「問題あり」と判断できた比率
-
1(100%)なら見逃しが一件もない理想的な状態
-
- 網羅率:人間判断「問題あり」のうち、機械判断で「問題あり」と判断できた比率
Recall = \frac{TP}{( TP+FN )}
上記表のような集計結果が得られるとき、「FN:見逃し」レコードについて手当てができれば、危険度 1-2 は「問題なし」と機械処理し、危険度 3-5 のみ人力監視/対処をする、などといった運用が検討できるでしょう
精度の改善
「FN:見逃し」に実際どういったデータがあるか詳しくみることで、精度改善のヒントを得ることができます
誤りレコードの分析と対処
「見逃し」データを詳細にみると、外部 API の苦手分野であったり、組み込んだアプリケーションと特性の合わない部分をみつけることができます.例えば次のようなケース(と対処法)があります
-
低画質の画像
- 前処理で画質を補正する
-
雑多な対象が含まれる画像
- 別のAPIで物体検出をして、物体ごとに分割して判定する
-
危険な外部サイトへの誘導(QR コードや URL)
- 画像としては危険でないので、QRコードを読み取るなどする
-
他人の電話番号を晒しているもの
- 画像としては危険でないので、OCR で文字を読み取り文字列を判断する
-
画像中に不適切なテキストを含んでいるもの
- 画像としては危険でないので、OCR で文字を読み取り文字列を判断する
APIとして提供されるサービスは使い勝手がよく、組み合わせることも容易です.
画質の補正や物体検出や OCR など、複数組み合わせることで対処できるかもしれません.また特定の問題に関しては、独自モデルを API として用意することでフィルタを重ねるように利用することもできます
単一のサービスに依存せず、「組み合わせの一つとして使う」というスタンスが、よい付き合い方ではないかと思います
適用の成果
誤りに対する対処を行った結果、次のような結果が継続して得られるようになりました
| 人間判断(真の危険度) | ||||
|---|---|---|---|---|
| 問題あり(危険) | 問題なし(安全) | 総計 | ||
| 機械判断 (推論値) (危険度) |
5 | 60 | 2940 | 3000 |
| 4 | 30 | 4970 | 5000 | |
| 3 | 10 | 11990 | 12000 | |
| 2 | 0 | 38000 | 38000 | |
| 1 | 0 | 42000 | 42000 | |
| 総計 | 100 | 99900 | 100000 | |
今後「見逃し」が発生するリスクはゼロではありませんが、得られる利益(作業量の削減)を勘案して十分検討できる水準といえます
どの程度リスクを負えるかはサービス運営者の判断ですが、危険度 1-2 は「問題なし」と機械処理し、危険度 3-5 のみ人力監視/対処をする といった運用に変えることで、人力労働を 80% 削減 することができるでしょう
精度のモニタリング
機械処理に運用を変更した場合、人間判断をしなくなったレコードは精度を測定することができなくなります(正解が得られなくなるため).
そのため、たとえば不適切投稿の通報機能を備えて通報数をモニタリングしたり、通報ののち人間判断「問題あり」となったレコードを機械判断させて判断の違いをみたりする仕組みが必要になるでしょう.あるいは、抜き打ちで危険度 1-2 レコードの人力チェックを不定期に行うなどという運用もあってよいかもしれません.
精度のモニタリングは必須ですが、外部 API に関しては外部でもモニタリングをしてくれるため、ある程度の品質を期待することができます
おわりに
今回のような事例は、実際に人力作業を削減する成果を挙げています.
文中の数字は単純化したものですが、精度調整など適用の流れは同様です.課題によってはいま世の中にある便利サービスで十分な成果を挙げられますし、今後多様な選択肢が提供されれば、より込み入った課題にも適用できるようになるでしょう
自前でモデル生成する場合は将来にわたって運用コストを負わなければいけませんが、外部サービスに移転できればその分リソースを節約できます.本質的な課題に集中して取り組むために、負う必要のないタスクは積極的になくしておくことが有益です
職種を問わずいろいろな人力労働がありますが、それを機械に代替させようとする場合にも、将来の徒労をつくらず、やりたいことに集中できるようにしていきたいですね