はじめに
「Base64は、データを64種類の印字可能な英数字のみを用いて、それ以外の文字を扱うことの出来ない通信環境にてマルチバイト文字やバイナリデータを扱うためのエンコード方式」1ですが,Base64でエンコードされた文字列の末尾は大抵1~2個の=でパディングされています。
ある日ふと「パディングが3個以上になることはないのかしら」と思って調べてみたんですが,自明すぎるのか,その辺を解説している日本語の記事があまりなさそうだったので一応書き留めておきます。
前提
Base64のエンコード方式は以下の通りです1。
- 元データを6ビットずつに分割する。(6ビットに満たない分は後ろに0を追加して6ビットにする)
- 各6ビットの値を変換表を使って4文字ずつ変換する。
- 4文字に足りない分は = 記号を後ろに追加する。
また,自明かもしれませんが,元データはバイト列(8bitを単位としたデータの集合)とします。
RFCを読んでも明記はされていなかったんですが,恐らく8bit単位でないデータについては考慮していないと思います。
考え方
(以下,「整数xを整数yで割った余りがzである」ことをx ≡ z (mod y)と表します)
まず,元データのビット長を8nとします(nは1以上の自然数)。
Base64エンコードにおいては,元データを6bitずつに分割し,それぞれに文字を割り当てて4文字のまとまりを作っていくので,6bit × 4 = 24bitを1ブロックとして考えます。
ここにおいてパディングが生じるケースというのは,元データを24bitずつ区切って最後に余りが出た場合を指します。
当然8 * 3 ≡ 0 (mod 24)なので,n ≡ 0 (mod 3)の場合はパディングが不要であることがわかります。
次に,n ≡ 1 (mod 3)の場合は,mを0以上の整数とすると8n = 8(3m + 1) = 24m + 8なので,8n ≡ 8 (mod 24)となります。
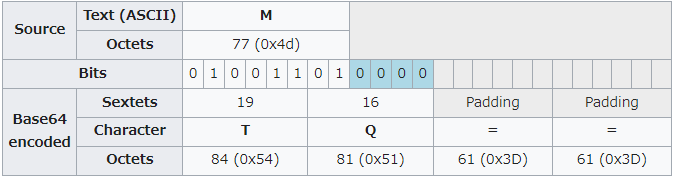
つまり,最後の1バイトは先頭6bitがそのまま1文字を割り当てられ,末尾2bitは04つで6bitに拡張されてから1文字を割り当てられますが,4文字のまとまりを作るにはあと2文字足りないため,==でパディングされます(下図参照2)。
最後にn ≡ 2 (mod 3)の場合は,mを0以上の整数とすると8n = 8(3m + 2) = 24m + 16なので,8n ≡ 16 (mod 24)となります。
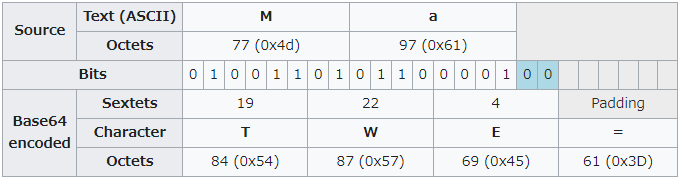
つまり,最後の2バイトは先頭12bitに2文字が割り当てられ,末尾4bitは02つで6bitに拡張されてから1文字を割り当てられますが,4文字のまとまりを作るにはあと1文字足りないため,=でパディングされます(下図参照2)。
以上で,全てのnについてパディングの長さが0~2個になることが示されました。
まとめ
数学って難しいですね(文系並感)。
最後までご覧いただきありがとうございました。
参考
RFC 4648 ベース64とベース32とベース16符号化:RFC 4648の日本語対訳
Base64 - Wikipedia:英語版
-
Base64 - Wikipediaより引用 ↩ ↩2
-
Base64 - Wikipedia(英語版)より引用 ↩ ↩2