はじめに
先日DjangoアプリケーションのPythonを2.7から3に上げるというタスクに携わったのですが、Python3化したソースをリリースした後、「Python2の時にアップロードした日本語名のファイルをダウンロードできない」というバグに直面しました。
アプリケーションの仕様では、アップロードされたファイルはZIP形式でストレージに保存され、ダウンロード時にzipfile.extract()にファイル名を渡して抽出するという挙動になっていたのですが、このextract()でKeyError: "There is no item named 'xxx.yyy' in the archive"というようなエラーが起きていました。
トラシューに際しては以下の記事が非常に参考になったのですが、これだけでは解決しない部分もあったため、補足という意味も含めて記事を書かせていただこうと思います。
Python で zip 展開(日本語ファイル名対応) - Qiita
原因1:zipfile の仕様変更
これは上で挙げた記事に書いてあることですが、Python2のzipfile.extract()ではファイル名がバイト列で返ってくるため文字コードを気にする必要がなかったのが、Python3ではZIPファイルのヘッダー情報を見てUTF-8フラグが立っていない場合はファイル名がすべてCP437でデコードされてしまうという仕様変更の問題があります。
......と言われても、ZIPの仕様やPythonの文字列の扱いについてよく知らない私のような人間はこれだけじゃいまいちピンときませんので、もう少し解像度を上げてみたいと思います。
zipfile.extract() 概観
まず、Pythonのzipfile.ZipFileオブジェクトは格納しているファイルごとにメタ情報(ZipInfoオブジェクト)を保持しています。zipfile.extract()はこのZipInfoに含まれるパスを利用して対象ファイルにアクセスしてデータの抽出を行います。
def extract(self, member, path=None, pwd=None):
...
if not isinstance(member, ZipInfo):
member = self.getinfo(member)
...
return self._extract_member(member, path, pwd)
ここでzipfile.extract()にファイル名が渡された場合、ZipFile.getinfo()が呼ばれ、getinfo()はZipFileオブジェクトのNameToInfo属性を参照して対象ファイルのZipInfoオブジェクトを取得します。NameToInfo属性は{ファイル名: ZipInfo}という辞書オブジェクトになっています。
class ZipFile(object):
...
def __init__(self, file, mode="r", compression=ZIP_STORED, allowZip64=False):
...
self.NameToInfo = {} # Find file info given name
...
def getinfo(self, name):
"""Return the instance of ZipInfo given 'name'."""
info = self.NameToInfo.get(name)
if info is None:
raise KeyError(
'There is no item named %r in the archive' % name)
return info
この流れはPython2,3共通です。
Python3での変更点
ではPython3になって何がどう変わったかというと、最初に説明したように、このZipInfoやNameToInfoに含まれるファイル名をセットする時にファイル名を勝手にデコードするようになりました。より具体的には、zipfile.ZipFile._RealGetContents()の仕様変更です。
Python2では以下のようにUTF-8フラグが立っている時のみUTF-8でデコードを行い、それ以外はバイト列をそのままセットしています。
class ZipFile(object):
...
def __init__(self, file, mode="r", compression=ZIP_STORED, allowZip64=False):
...
try:
if key == 'r':
self._RealGetContents()
...
def _RealGetContents(self):
"""Read in the table of contents for the ZIP file."""
...
filename = fp.read(centdir[_CD_FILENAME_LENGTH])
# Create ZipInfo instance to store file information
x = ZipInfo(filename)
...
x.filename = x._decodeFilename()
self.filelist.append(x)
self.NameToInfo[x.filename] = x
...
def _decodeFilename(self):
if self.flag_bits & 0x800:
return self.filename.decode('utf-8')
else:
return self.filename
一方Python3の_RealGetContents()は以下のようにファイル名をUTF-8かCP437の必ずどちらかでデコードします。
def _RealGetContents(self):
"""Read in the table of contents for the ZIP file."""
...
filename = fp.read(centdir[_CD_FILENAME_LENGTH])
flags = centdir[5]
if flags & 0x800:
# UTF-8 file names extension
filename = filename.decode('utf-8')
else:
# Historical ZIP filename encoding
filename = filename.decode('cp437')
この仕様変更により、Shift_JISなどZIPの仕様書に書かれていない文字コードでエンコードされたファイルはおろか、UTF-8でエンコードされていてもUTF-8フラグが立っていないファイルまでCP437で強制デコードされるため、抽出したファイルの名前が文字化けしたりエラーが発生したりしてしまいます。
原因2:extract() にファイル名を渡している
実はZIPファイルから抽出するファイルを指定するには、zipfile.extract()の第1引数としてファイル名とZipInfoオブジェクトのどちらを渡すこともできます。
ZipInfoオブジェクトを渡す場合には「はじめに」で紹介した記事の対処法(ZipInfo.filenameをデコードし直し、修正したZipInfoオブジェクトをextract()に渡す)で上手くいくのですが、ファイル名を渡す場合ではまだエラーが解消されません。具体例で確認しましょう。
python_zipというディレクトリにファイル名がShift_Jisでエンコードされたテスト用です.txtというファイルを作り、これを同じディレクトリにtest.zipとして圧縮します(LANGがUTF-8なのでlsすると文字化けします)。また、抽出したファイルの格納先としてextractedというディレクトリも作成しておきます。
~/python_zip$ ls
''$'\203''e'$'\203''X'$'\203''g'$'\227''p'$'\202''ł'$'\267''.txt' extracted test.zip
このtest.zipから以下のようにZipInfo.filenameを書き換えるコードでtxtファイルを抽出してみます。
import zipfile
zf = zipfile.ZipFile("test.zip", 'r')
for info in zf.infolist():
bad_filename = info.filename
info.filename = info.filename.encode('cp437').decode('shift_jis')
zf.extract("テスト用です.txt", "./extracted")
zf.close()
以下のようにKeyErrorとなってしまいます。
~/python_zip$ python extract_zip_py3.py
Traceback (most recent call last):
File "extract_zip_py3.py", line 24, in <module>
zf.extract("テスト用です.txt", "./extracted")
(中略)
KeyError: "There is no item named 'テスト用です.txt' in the archive"
「zipfile.extract() 概観」で述べたように、ファイル名で指定する場合はNameToInfo属性を参照するのでした。test.zipのNameToInfoをデバッグすると、ZipInfo.filenameを書き換えた後では以下のようになっています。
{'âeâXâgùpé┼é╖.txt': <ZipInfo filename='テスト用です.txt' filemode='-rw-r--r--' file_size=19>}
確かにfilenameは直せていますが、キーが依然として文字化けしたファイル名になっているためgetinfo()内のself.NameToInfo.get(name)でマッチできずエラーになってしまいます。
対処法1
ということは、この場合は更にNameToInfoも書き換えてしまえば上手くいくということです。先程のextract_zip_py3.pyを以下のように修正します。
import zipfile
zf = zipfile.ZipFile("test.zip", 'r')
for info in zf.infolist():
bad_filename = info.filename
info.filename = info.filename.encode('cp437').decode('shift_jis')
zf.NameToInfo[info.filename] = info
del zf.NameToInfo[bad_filename]
print(zf.NameToInfo) # デバッグ用
zf.extract("テスト用です.txt", "./extracted")
zf.close()
これを実行すると以下のようになります。
~/python_zip$ python extract_zip_py3.py
{'テスト用です.txt': <ZipInfo filename='テスト用です.txt' filemode='-rw-r--r--' file_size=19>}
~/python_zip$ ls extracted
テスト用です.txt
NameToInfoが書き換えられたことで対象ファイルのZipInfoが正しく取得でき、文字化けせずにファイルの抽出ができていることが確認できます。
対処法2(+エンコーディング判定)
DjangoアプリケーションのPython2 to 3の対応としては基本的には対処法1で十分だと思いますが、万が一のことを考えるとデコードし直す文字コードは決め打ちよりも自動で判定できた方が安全度が高いと言えます。
そこで、先程のShift_Jisのテスト用です.txtに加えてファイル名がUTF-8のテスト用2です.txtを作成してtest2.zipに圧縮しました。
~/python_zip$ ls
''$'\203''e'$'\203''X'$'\203''g'$'\227''p'$'\202''ł'$'\267''.txt' extracted test2.zip
extract_zip_py3.py test.zip テスト用2です.txt
そしてextract_zip_py3.pyを以下のように修正しました。
import sys
import zipfile
import chardet
args = sys.argv
zname = args[1] # ZIPファイル名
fname = args[2] # 抽出対象ファイル名
zf = zipfile.ZipFile(zname, 'r')
for info in zf.infolist():
bad_filename = info.filename
code = chardet.detect(info.filename.encode('cp437')) # 文字コード自動判定
print(code)
info.filename = info.filename.encode('cp437').decode(code['encoding'])
zf.NameToInfo[info.filename] = info
del zf.NameToInfo[bad_filename]
print(zf.NameToInfo)
zf.extract(fname, "./extracted")
zf.close()
こちらを実行してみます。
~/python_zip$ python extract_zip_py3.py test.zip テスト用です.txt
{'encoding': 'SHIFT_JIS', 'confidence': 0.99, 'language': 'Japanese'}
{'テスト用です.txt': <ZipInfo filename='テスト用です.txt' filemode='-rw-r--r--' file_size=19>}
~/python_zip$ python extract_zip_py3.py test2.zip テスト用2です.txt
{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
{'テスト用2です.txt': <ZipInfo filename='テスト用2です.txt' filemode='-rw-r--r--' file_size=28>}
~/python_zip$ ls extracted
テスト用です.txt テスト用2です.txt
意図したとおり、自動判定によって導出された文字コードでファイル名をデコードし直し、文字化けすることなくファイルの抽出を行うことができました。
一旦まとめ
今回はPythonの文字列の扱いにおける仕様変更とzipfileモジュールの仕様変更が重なっていて、自分なりに納得の行く説明ができるようになるまで比較的時間がかかりました。またPython2 to 3 関連で何か書きたいですね。
ひとまずここまでご覧いただきありがとうございました。ここから先は執筆中に気になった細々としたことについて書いていきますので、興味のある方はもう少しお付き合いください。
疑問①:抽出するファイルのパスはどこにある?
今回の対処法ではZipFileオブジェクトが持っているメタ情報を修正しているわけですが、filenameやNameToInfoを勝手に書き換えてもZIPアーカイブの対象ファイルを見つけ出せるというのがよくよく考えると不思議だぞと思ったんですね。
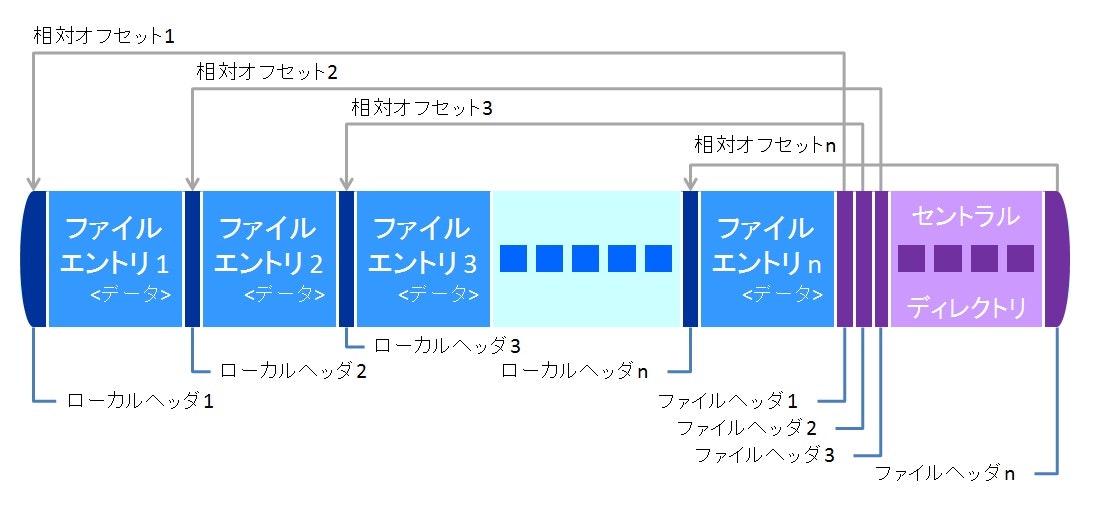
そこでソースをもう少し追いかけたら、ZipInfo.orig_filenameという属性値が別に用意されていて、これとZIPアーカイブのローカルヘッダ(ZIPに格納されているファイルごとのメタデータ。下図参照)に書かれているファイル名(をデコードした文字列)を比較して一致したらそのファイルをopen()するという仕様になっていました。
先程のextract_zip_py3.pyをハードコーディングでデバッグすると、NameToInfoを書き換えた後でもorig_filenameは文字化けしたままで、ローカルヘッダから取得したファイル名(fname)をCP437でデコードした文字列と一致しました。
~/python_zip$ python extract_zip_py3.py test.zip テスト用です.txt
{'テスト用です.txt': <ZipInfo filename='テスト用です.txt' filemode='-rw-r--r--' file_size=19>}
orig_filename: âeâXâgùpé┼é╖.txt
fname: b'\x83e\x83X\x83g\x97p\x82\xc5\x82\xb7.txt'
~/python_zip$ python
Python 3.7.5 (default, Nov 22 2020, 16:16:44)
[GCC 7.5.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> s = b'\x83e\x83X\x83g\x97p\x82\xc5\x82\xb7.txt'
>>> s.decode('cp437')
'âeâXâgùpé┼é╖.txt'
ファイルを探すための情報はorig_filenameとZIPのローカルヘッダに書かれているため影響を受けず、filenameは抽出したファイルの名前の方に利用されるので問題ないということですね。上手いことできています。
疑問②:UTF-8でエンコードされているのにフラグが立っていないのはなぜか?
今回記事を書くきっかけとなったバグは、もとを正せばPython2の時にUTF-8でエンコードされていたZIPアーカイブ内のファイルにUTF-8フラグが立っていなかったせいで起こったものでした。なぜそのようなことになったのでしょうか?
Python2のzipfileモジュールのソースを見ると、ファイル名がUnicode型且つACSIIでエンコードできなかった場合にのみUTF-8フラグを立てていることがわかりました。
class ZipInfo (object):
...
def FileHeader(self, zip64=None):
...
filename, flag_bits = self._encodeFilenameFlags()
...
def _encodeFilenameFlags(self):
if isinstance(self.filename, unicode):
try:
return self.filename.encode('ascii'), self.flag_bits
except UnicodeEncodeError:
return self.filename.encode('utf-8'), self.flag_bits | 0x800
else:
return self.filename, self.flag_bits
そこで、以下のようにファイル名がUnicode文字列のファイルを作成してZIPに圧縮しファイル抽出を行うPython2プログラムにデバッグコードを入れて実行してみました。
# -*- coding: utf-8 -*-
import zipfile
# ファイル作成、ZIPに格納、別ディレクトリに抽出
with open(u"テスト用です.txt", 'w') as f:
f.write("ファイルに書き込み\n")
zf = zipfile.ZipFile("test.zip", 'w')
zf.write(u"テスト用です.txt")
zf.close()
zf = zipfile.ZipFile("test.zip", 'r')
print zf.NameToInfo
print zf.infolist()[0].flag_bits
zf.extract(u"テスト用です.txt", "./extracted")
zf.close()
以下がその実行結果になります。0x800は10進数では2048なので、確かにUTF-8が立っています。
~/python_zip$ python --version
Python 2.7.17
~/python_zip$ python zip_py2.py
{u'\u30c6\u30b9\u30c8\u7528\u3067\u3059.txt': <zipfile.ZipInfo object at 0x7f68ec012940>}
2048
~/python_zip$ ls extracted
テスト用です.txt
めでたし。
参考文献
cpython/zipfile.py at 2.7 · python/cpython · GitHub
cpython/zipfile.py at 3.7 · python/cpython · GitHub
.ZIP ファイルフォーマット仕様書(英語)
ZIPの仕様を日本語でまとめる · GitHub:↑の日本語訳です。ありがたい。
ZIP (ファイルフォーマット) - Wikipedia
zipfile でのファイル名の扱いもまともになってしまったっぽい - つちのこ、のこのこ。(beta)