こんにちは、えんフォトでリードエンジニアをやっている莊です!
この記事はうるるAdvent Calendar 2022の23日目の記事です。
妻と良い気持ちでX'mas Eveを迎えたいので頑張って記事を書きました!!
是非ご覧ください〜
はじめに
SREを導入する企業が多くなってきている今では、「うちのサービスにもSREを導入したいけど、具体的にどう始めたらいいか?」と困っている方が結構いると思いますので、本記事で自分が今までのSRE導入経験を元にした具体的な実践方法についてお話したいと思います。
SREの概要を簡単に
SRE = Site Reliability Engineeringの略称で、文字通り、エンジニアリングでサイト信頼性を担保する仕組みのことを指します。
SREは2003年にGoogle社のエンジニアリングチームから生まれたもので、Ben Treynor Sloss氏がもたらしてくれた概念であり、高度なソフトウェアの技術を利用し、信頼性のあるサイトを構築する仕組みです。
SREをやるエンジニアはSite Reliability Engineerと呼びます。
SREエンジニアの役割は信頼性のあるサイトの構築に特化する役割なので、担当範囲が非常に広く、ソフトウェア・システムの全般工程、システム管理に対する知識が求められています。
SREエンジニアの業務は企業の考え方によって異なる部分がありますが、基本的に下記を担うことが多いです。
- 信頼性のあるサイトの構築、設計。(一般的にサイトのAvailability、Latency、Efficiencyの低減につながる設計・構築はメイン)
- 可観測性の構築。(定量的に維持基準・向上の目標を設定するため、サイトの信頼性を表す指標を可視化する)
- Toil作業の低減。(オーペーレターの重複的な手動作業を積極的にソフトウェアに書き換えて自動化する)
(引用元:https://en.wikipedia.org/wiki/Site_reliability_engineering)
本記事で話す内容
SREの仕組みとSREエンジニアの役割全般的な内容はかなり量が多く、1記事で包括的に話すことはできないのですが、
本記事では主に初めてSREの仕組みを導入する際に「最初に具体的にどう始めたらいいか」を軸にお話ししたいと思います。
SRE全般を体系的に理解したいお方に是非下記の本をご参考いただければと思います〜
本記事で話なさない内容
- SREと開発組織の体制について
- SLI、SLO向上周りの具体的なプラクティス(例:Availability、Latencyの低減など)
- SLAの策定について
- Toilの低減、自動化について
- 障害対応、ポストモーテムについて
上記についての内容はまた機会があれば、別記事でまとめて行きたいと思います。><
本記事で使用する専門用語
-
SLI(Service Level Indicator)
サービスレベル指標。サービスの信頼性を表す定量的な指標のこと。
(例:リクエスト成功率、レイテンシーが1秒未満のリクエスト数の割合...など) -
SLO(Service Level Objective)
サービスレベル目標。SLIに対する具体的な維持目標値のこと。
(例:リクエスト成功率99.9%以上、レイテンシーが1秒未満のリクエスト数の割合が99%以上...など) -
Error Budget
サービスレベル目標の達成度合いを示す指標のこと。クォータ、もしくは予算の意味を持ち、エラーバジェットを完全に使い切ると、サービスレベル目標を達成できないことを意味する。
SREの導入の流れ
組織の考え方によっては順番は異なることがあると思いますが、個人的に一番スムーズな順番は下記です。
1. SLIの策定 - サービスの信頼性を表す指標(SLI)を定義する
2. SLIの計測 - サービスの信頼性を表す指標の現状(SLI値)を計測する
3. SLOの設定 - 各SLIに対して期待のサービス信頼性レベル(SLO値)を設定する
4. SLOの維持 - 日々のSLO達成状況を確認しながら維持する
5. SLOの向上 - 品質とコストのトレードオフ
また、サービスが常に変化(更新)するもので、当然ながらSLI、SLOもそれに応じて変化します。
上記の順番は一回限りではなく、PDCAを回し、サービスの信頼性指標(SLI)を可視化し、各SLIをSLO値以上に維持、向上できる仕組みとして機能することがSREの導入に一番重要なことだと思います。
以下は順番1~5を逐一で詳しく実践方法について説明します。
1、SLIの策定 - サービスの信頼性を表す指標(SLI)を定義する
SREの実践に最初にやるべきなのは、サービスの信頼性を意味する指標を定義することです。
もっとわかりやす言葉で言うと、「なにをどのレベルで担保できていると、信頼性のあるサービスだといえるのか?」の「なにを」という部分の定義になります。
信頼性の定義はサービスによって異なりますが、えんフォトはWebサービスのため、一般的なWebサイトの信頼性のメジャー指標である可用性とレイテンシーが信頼性指標として採用しています。
しかし可用性とレイテンシーは「何の可用性なのか?」、「何のレイテンシーなのか?」という曖昧な部分があるので、可用性とレイテンシーそれぞれより具体的にブレイクダウンし、計測可能な指標に落とし込みます。以下はいくつ例を挙げます。
可用性
| 信頼性対象 | SLI | 定義詳細 |
|---|---|---|
| Webリクエスト処理の可用性 | Webリクエストの成功率 | HTTPリクエストのレスポンスコードが500~599以外のリクエスト数 / リクエスト総数 |
| Webサーバーの可用性 | 外形監視の成功率 | 死活監視対象URLのリクエスト成功数 / リクエスト総数 |
| 画像処理の可用性 | サムネール写真作成の成功率 | サムネ写真作成処理成功数 / 実行総数 |
レイテンシー
| 信頼性対象 | SLI | 定義詳細 |
|---|---|---|
| Webリクエストパフォーマンス | 十分に早いWebトランザクション数の割合 | ○秒以内実行完了のWeb Transaction数 / Web Transaction総数 |
| WebリクエストごとのDBの読み込みパフォーマンス | 十分に早いDBレスポンスタイムが満たす読み込み系Webトランザクション数の割合 | DBレスポンスタイムが○秒以内のGET系Web Transaction総数 / GET系Web Transaction総数 |
| WebリクエストごとのDBの書き込みパフォーマンス | 十分に早いDBレスポンスタイムが満たす書き込み系Webトランザクション数の割合 | DBレスポンスタイムが○秒以内のGET系以外のWeb Transaction総数 / GET系以外のWeb Transaction総数 |
| 画像処理パフォーマンス | 十分に早いサムネール作成を完了できた実行数の割合 | ○秒以内実行完了のサムネール作成処理実行数 / 実行総数 |
こうすることで、「なにをどのレベルで担保できていると、信頼性のあるサービスだといえるのか?」の「なにを」を指標化されていき、「サービスの信頼性」という「抽象的な言葉」を「具体的な言葉」に変えていきます。
2、SLIの計測 - サービスの信頼性を表す指標の現状(SLI値)を計測する
Step1で明確なSLI指標を定義できていたら、次は計測の段階に入ります。
システムの現状がタイムリーに変化するものです。信頼性を保ち続けるためには、各SLI値をリアルタイムで可視化する必要があります。
SLIの可視化にはモニタリング基盤の構築が必要になります。
計測対象によっては構築方法が異なりますが、えんフォトのSRE実践当初では下記の3つサービスで構築するのを考案しました。
(下記サービスはあくまでも参考例です。重要なのは計測したいSLIをリアルタイムで計測可能という点です、それが実現可能であれば、どの手段でも構いません。)
PrometheusはOpenSourceですが、学習コストが高いため、素早く構築可能 + 指標計測の柔軟性が高いNewRelicを採用しました。
ここからはNewRelicを例にSLIの計測方法について説明します。
(NewRelicの使用にはアカウント作成と各監視対象サーバーにAPMエージェントのインストールが必要です。)
NewRelicではNRQLという機能があり、SQLのような構文で簡単にほしいデータをクエリーしグラフィックで可視化できます。
以下は可用性とレイテンシーを一個ずつ例にして、SLI値をNRQLでクエリーを可視化します。
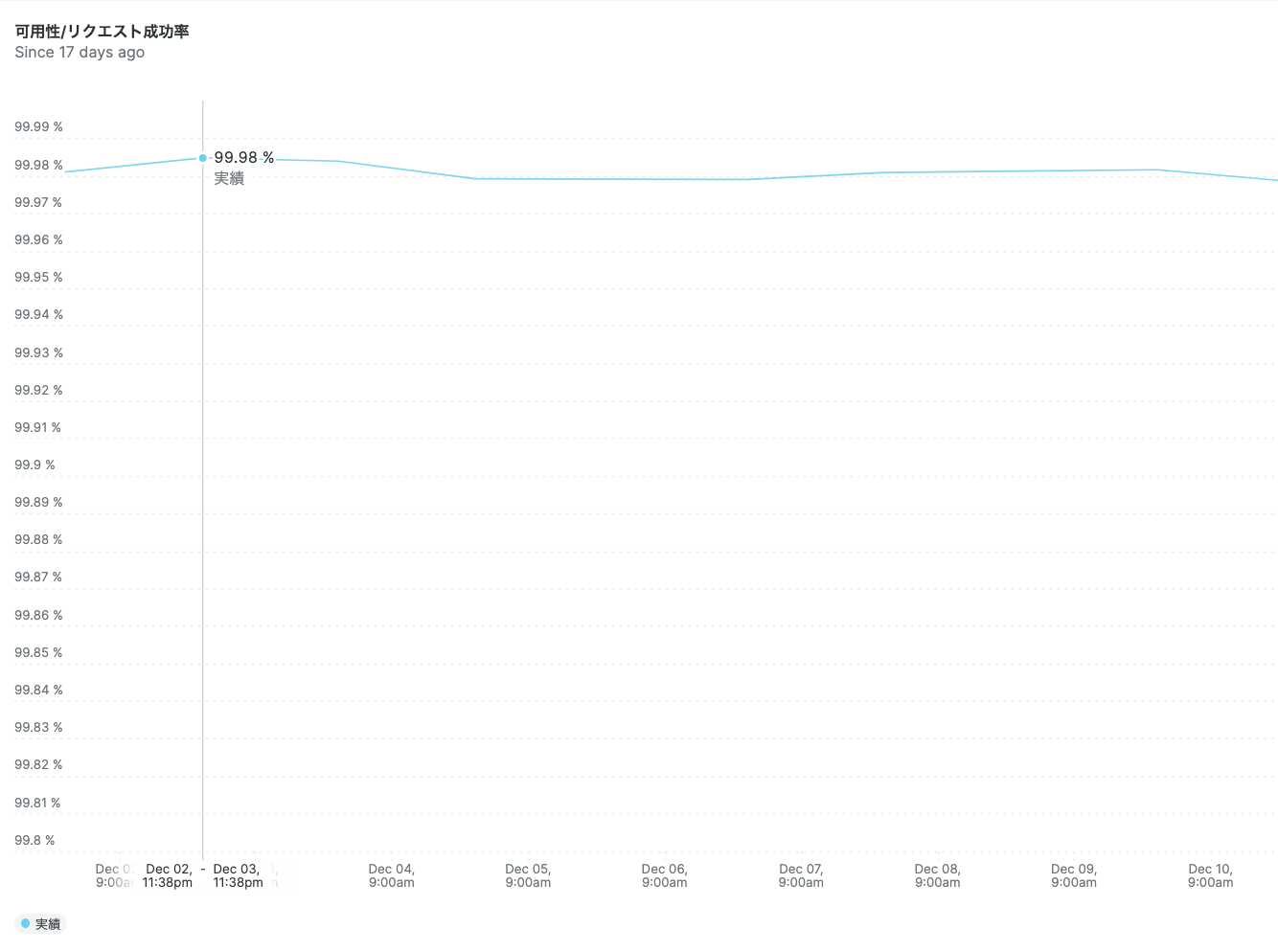
SLI: サービス可用性/Webリクエストの成功率
詳細な定義: HTTPリクエストのレスポンスコードが500~599以外のリクエスト数 / リクエスト総数
NRQL構文:
SELECT
100 - percentage(count(httpResponseCode), WHERE '500' <= httpResponseCode AND httpResponseCode <= '599') AS '実績'
FROM
Transaction
WHERE
appName = 'sample-app'
SINCE '2022-12-01 00:00:00'
WITH TIMEZONE 'Asia/Tokyo' TIMESERIES
可視化グラフ(日別):
SLI: レイテンシー/十分に早いWebトランザクション数の割合
詳細な定義: {秒数}秒以内実行完了のWeb Transaction数 / Web Transaction総数
NRQL構文:
SELECT
100 - percentage(count(httpResponseCode), WHERE {秒数} <= totalTime) AS '実績'
FROM
Transaction
WHERE
appName = 'sample-app'
SINCE '2022-12-01 00:00:00'
WITH TIMEZONE 'Asia/Tokyo' TIMESERIES
可視化グラフ(日別):
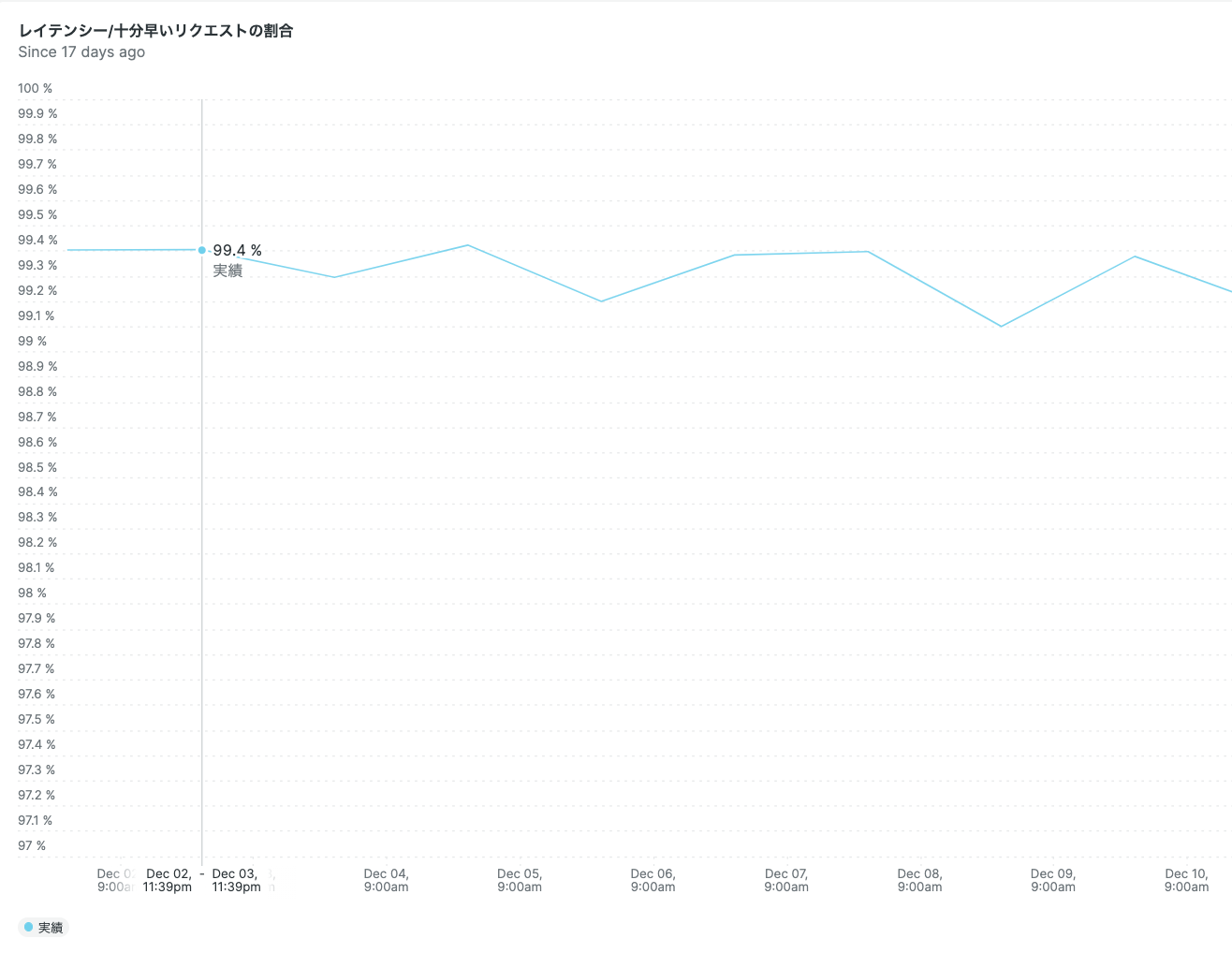
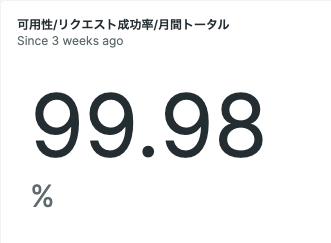
このように、SLI値の推移がリアルタイムで可視化できました!!
また、現在値の数字を可視化できると、素早く現状を把握できるので、おすすめです!
NRQL:
SELECT
100-filter(count(httpResponseCode), WHERE '500' <= httpResponseCode AND httpResponseCode <= '599') * 100 / (count(httpResponseCode)) as '%'
FROM
Transaction
WHERE
appName='sample-app'
SINCE '2022-12-01 00:00:00' WITH TIMEZONE 'Asia/Tokyo'
3、SLOの設定 - 各SLIに対して期待のサービス信頼性レベル(SLO値)を設定する
SLIを可視化できたら、SLO値を設定できるようになります。
SLO値の設定は実質的に品質とコストのトレイドオフですので、達成に不可能な数字を設定してもあまり意味がありません。
(壁が高すぎたらモチベーションも下がりますよねー。。。笑)
SREにおいて一番重要だと思っているのは、「サービスの利用者が十分に満足できる信頼性レベル以上に維持することです」
その十分に満足のラインはサービスによって異なりますが、最初は現状を踏まえてギリギリで達成できるラインの設定がおすすめです。
その後、現状開発組織の能力範囲内でSLOを維持しつつ、ユーザーの満足ラインを探りながら、品質とコストの間に最適なバランスを見つけて行きましょう!
以下は可用性とレイテンシーのSLIを一個ずつ例にして、それぞれのSLOをNRQLで可視化します。
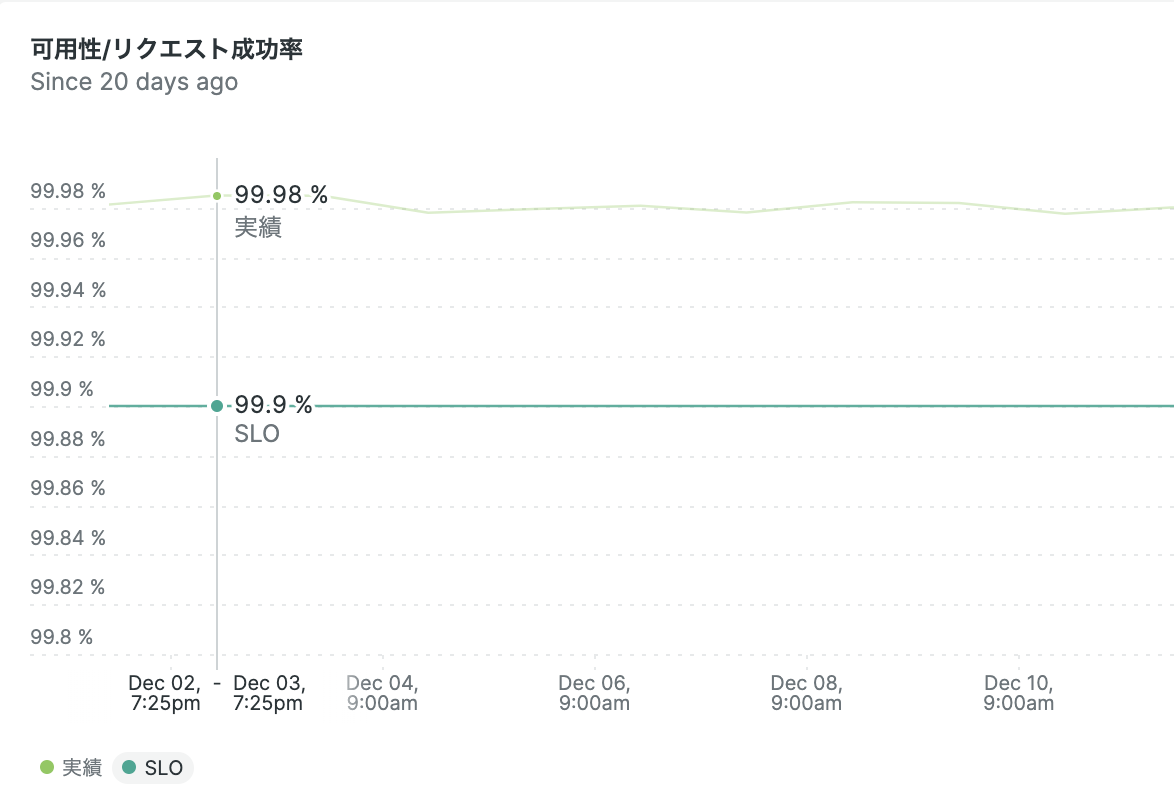
「SLI:サービス可用性/Webリクエストの成功率」のSLO設定
SLI: HTTPリクエストのレスポンスコードが500~599以外のリクエスト数 / リクエスト総数
SLO:99.9%以上
NRQL:
SELECT
100 - percentage(count(httpResponseCode), WHERE '500' <= httpResponseCode AND httpResponseCode <= '599') AS '実績'
,0.999 AS 'SLO'
FROM
Transaction
WHERE
appName = 'sample-app'
SINCE '2022-12-01 00:00:00'
WITH TIMEZONE 'Asia/Tokyo' TIMESERIES
「SLI:十分に早いWebトランザクション数の割合」のSLO設定
SLI定義: ○秒以内実行完了のWeb Transaction数 / Web Transaction総数
SLO:99%以上
NRQL:
SELECT
100 - percentage(count(httpResponseCode), WHERE {秒数} <= totalTime) AS '実績'
, 0.99 AS 'SLO'
FROM
Transaction
WHERE
appName = 'sample-app'
SINCE '2022-12-01 00:00:00'
WITH TIMEZONE 'Asia/Tokyo' TIMESERIES
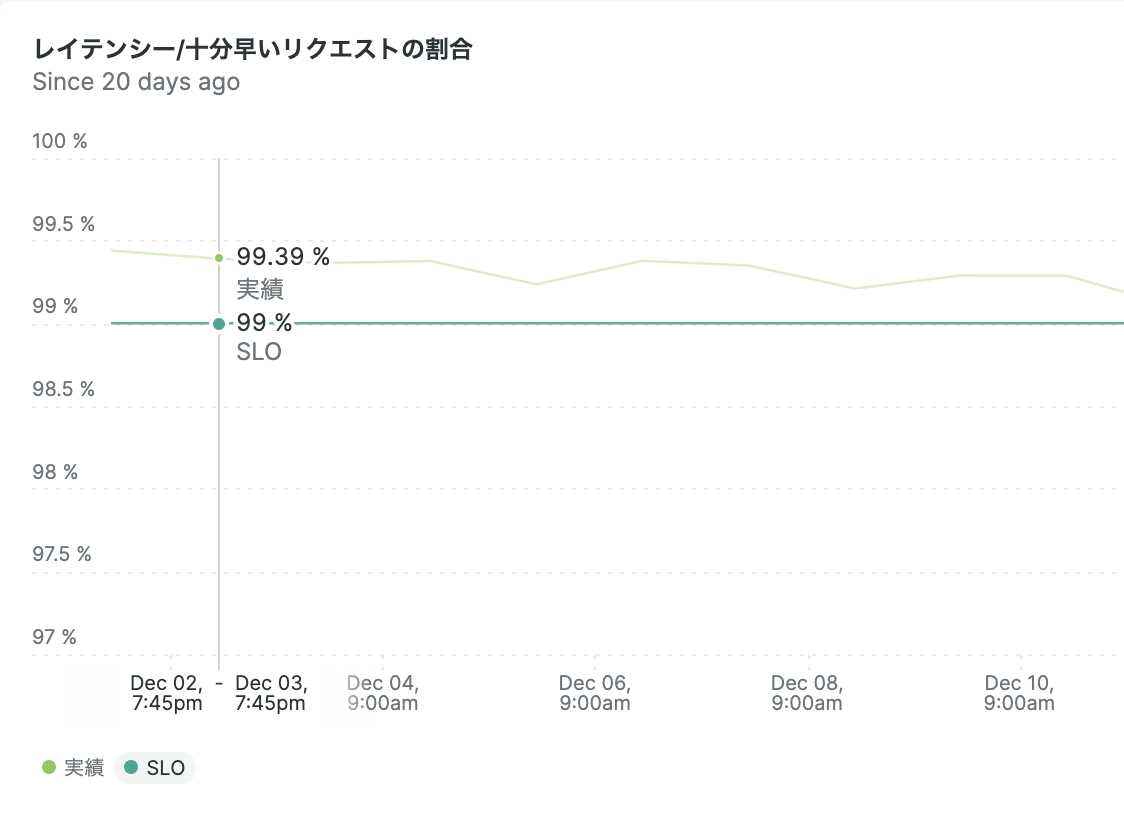
このように、タイムリーなSLI値の推移グラフで基準値となるSLO値を含めて可視化できました!
あとは、常にSLO値以上に維持し続けることを努めていきましょう。
4、SLOの維持 - 日々のSLO達成状況を確認しながら維持する
SREにおけるSLOの維持ではエラーバジェットという概念を用いて運用していくことになります。
エラーバジェットとは簡単に言うと、「SLI現在値とSLO目標値の差分を比較し、決まった期間内にSLO値より下回るまで、後どのぐらいクォータが残っているか」を表現するものです。なので、文字通り「予算」という言葉が使われていますね。
予算を使い切ったら = SLO目標を達成できなくなるということになります。
エラーバジェットの計算方法
エラーバジェットの算出方法は基本的に下記の通りです。
SLO値より下回る回数
------------------------------------ x 100 = エラーバジェット(%)
決まった期間内に許容可能な合計回数
SLOの維持難易度がエラーバジェットの集計Windowに関わっています。
集計Windowを短くすることで、より高い信頼性を求めることができますが、短くすればするほど、SLO維持する難易度が上がっていきます。
例えば、1分-Windowで合計アクセス数が1000回だとして、ちょうどその期間帯にアクセスエラーのSpikeが来た場合、1000件のリクエストに対して、10件がエラーとなったとしたら、SLO = 99.9%のエラーバジェットは下記になります。
SLO値より下回る回数 = 10回
決まった期間内に許容可能の合計回数 = 1000 * 0.001(0.1%) = 1回
エラーバジェットの消費率 = 10回 / 1回 * 100 = 1000%
つまりその期間中に予算の10倍を消費してしまうことになります。
しかし、1日-Windowを取る場合、その合計のアクセス数が1000000回がある中で合計エラー数が100回しかないとしたら、SLO = 99.9%のエラーバジェットは下記になります。
SLO値より下回る回数 = 100回
決まった期間内に許容可能の合計回数 = 1000000回 * 0.001(0.1%) = 1000回
エラーバジェットの消費率 = 100回 / 1000回 * 100 = 10%
結果として、1日でみたら一時的なエラーSpikeがあったけど、10%のエラーバジェットを消費しただけで、まだクォータが90%も残っているため、それほどやばい状況ではなかったと言えます。
Spikeをある程度許容してもいい場合、エラーバジェットのWindowを長め設定するのはおすすめです。
一般的に30日-Windowで設定するケースが多いらしいです。
これからは下記のSLIを例にしてエラーバジェットの具体的な算出方法を説明します。
・サービス可用性/Webリクエストの成功率
・レイテンシー/十分に早いWebトランザクション数の割合
サービス可用性/Webリクエストの成功率
SLI定義: HTTPリクエストのレスポンスコードが500~599以外のリクエスト数 / リクエスト総数
SLO: 99.9%以上
エラーバジェットWindow: 30日
NRQL:
SELECT
filter(count(httpResponseCode), WHERE '500' <= httpResponseCode AND httpResponseCode <= '599') * 100 / ((count(httpResponseCode)) * 0.001 * 30 / ceil((aggregationendtime() - 1669820400000) / (1000 * 60 * 60 * 24))) as '%'
FROM
Transaction
WHERE
appName='sample-app'
SINCE
'2022-12-01 00:00:00'
WITH TIMEZONE 'Asia/Tokyo'

これでエラーバジェットを可視化できました!
filter(count(httpResponseCode), WHERE '500' <= httpResponseCode AND httpResponseCode <= '599') * 100 / ((count(httpResponseCode)) * 0.001 * 30 / ceil((aggregationendtime() - 1669820400000) / (1000 * 60 * 60 * 24))) as '%'
ちょいまってや!!上記算式を理解できない!!と思う人が多いと思いますので、分かりやすく表現すると下記になります。
1、500系のエラー実数 = filter(count(httpResponseCode), WHERE '500' <= httpResponseCode AND httpResponseCode <= '599')
2、現時点までのリクエスト合計値によるエラー許容可能総数 = count(httpResponseCode)) * 0.001
3、経過日数:ceil((aggregationendtime() - 1669820400000) / (1000 * 60 * 60 * 24)
# 1669820400000は2022年12月1日のUNIX Time(単位:ミリ秒)
4、現時点まで一日の平均許容可能総数 = 現時点までのリクエスト合計値によるエラー許容可能総数 / 経過日数
5、当月30日までの予測許容可能エラー総数 = 現時点まで一日の平均許容可能総数 * 30
なので、上記1~5により、エラーバジェットは下記で算出することになります。
500系のエラー実数
------------------------------- x 100 = エラーバジェットの現在値(%)
当月30日までの予測許容可能エラー総数
エラーバジェットはタイムリーで変動するので、エラーバジェットのDaily Burnning Rate(日別燃焼速度)を可視化することがおすすめです。
NRQL:
# 昨日の500系エラー実数とリクエスト実数による30日後のエラーバジェットの予測値
SELECT
filter(count(httpResponseCode), WHERE '500' <= httpResponseCode AND httpResponseCode <= '599') * 100 / ((count(httpResponseCode)) * 0.001 * 30 ) as '%' FROM
Transaction
WHERE
appName = 'sample-app'
SINCE 1 day ago
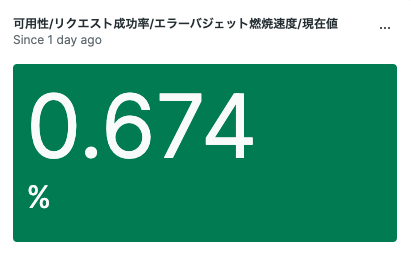
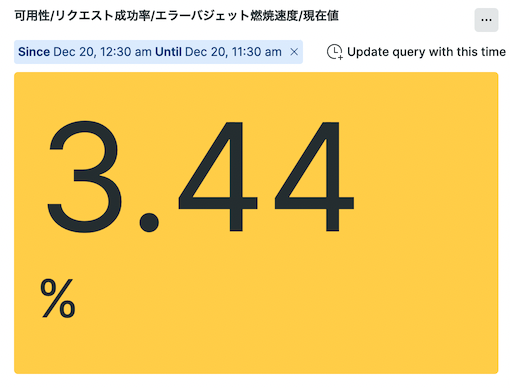
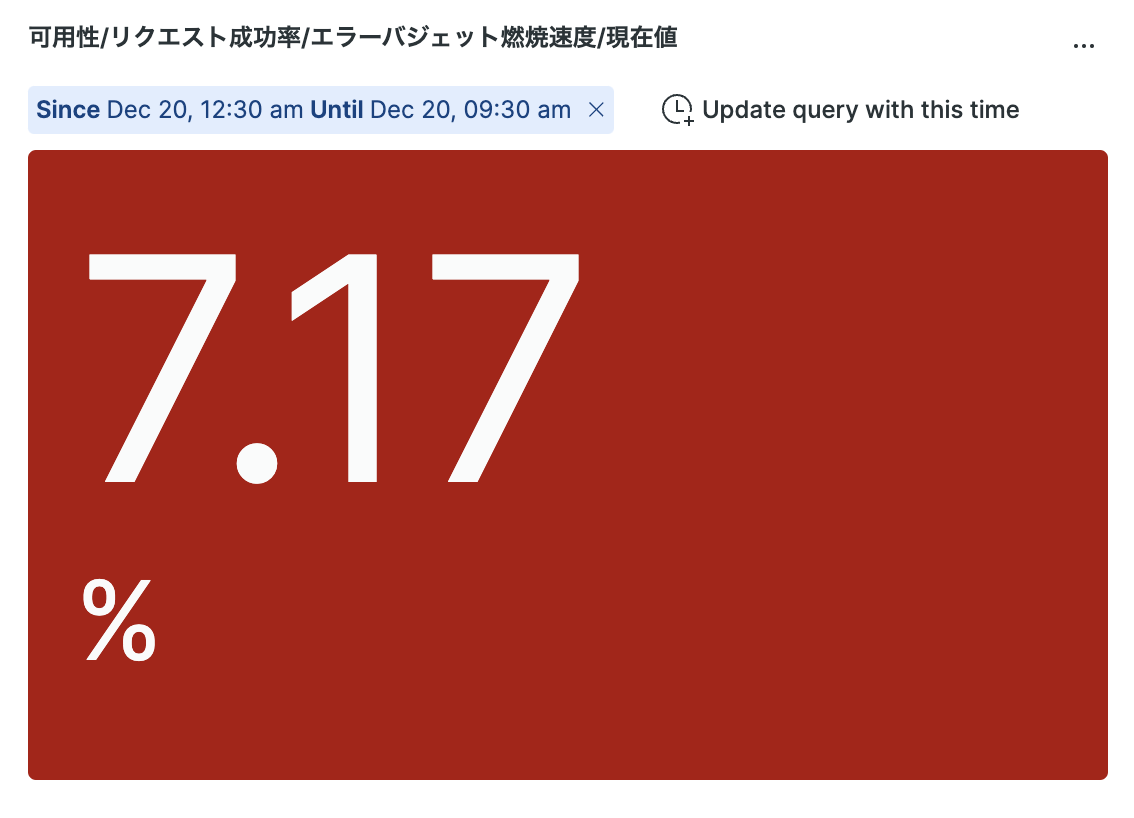
例えば、昨日のエラーバジェットのDaily Burnning Rateが3%超えが発覚し、この傾向続いたら月末時点でエラーバジェットを使い切るリスクが高くなるので、こうして色を変えたりすると緊急度が分かりやすくなりますね。
3.5%を超える状態が続くと月末時点でエラーバジェットを使い切る傾向になるので、いち早く原因究明〜改善に向けて行動する必要があります。
レイテンシー/十分に早いWebトランザクション数の割合
SLI定義: ○秒以内実行完了のWeb Transaction数 / Web Transaction総数
SLO:99%以上
エラーバジェットWindow: 30日
NRQL:
SELECT
filter(count(httpResponseCode), WHERE {秒数} <= totalTime) * 100 /((count(httpResponseCode)) * 0.01 * 30 / ceil((aggregationendtime() - 1669820400000) / (1000 * 60 * 60 * 24))) AS '%'
FROM
Transaction
WHERE
appName='sample-app'
SINCE '2022-12-01 00:00:00'
WITH TIMEZONE 'Asia/Tokyo'
また、必須ではないですが、エラーバジェットの消耗状況をTimeSeriesで取ると、より傾向を見やすくなりますので、おすすめです。
エラーバジェット燃焼速度の推移
NRQL:
SELECT
filter(count(httpResponseCode), WHERE '500' <= httpResponseCode AND httpResponseCode <= '599') * 100 / ((count(httpResponseCode)) * 0.001 * 30 ) as '実績'
,3.5 AS '危険水準'
FROM
Transaction
WHERE
appName = 'sample-app'
SINCE 1 day ago TIMESERIES
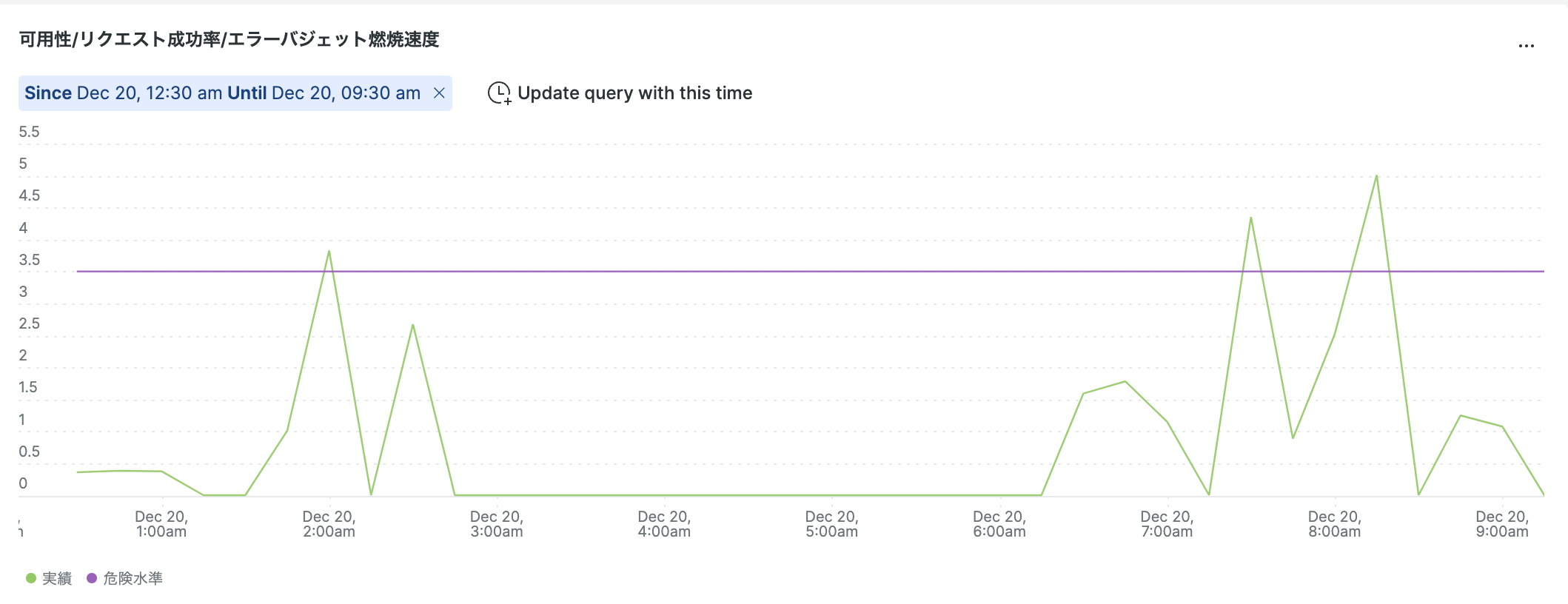
こうして、毎日の朝会でSLIのDashboardを開いて現時点までの各SLIのエラーバジェットの消耗状況と昨日のエラーバジェットの燃焼速度を元に、月末時点でSLOを達成できそうかを確認しながら改善活動を行うことができるようになります。
5、SLOの向上 - 品質とコストのトレードオフ
ここまではSREにおけるSLI、SLO、エラーバジェットの設定や可視化に対する具体的な実践例を挙げさせていただきましたが、ここからは本番になります。
サービスは常に変化するものです。SREの実践にはサービスの変化とともに、定期的にSLI、SLOを見直す必要があります。
見直す点としては下記が大事だと思います。
・現在定義しているサービスの信頼性を意味する各SLIは適切か?過不足はないか?
・顧客が快適にサービスを利用するのに適切なSLO値はどのぐらいか?
・現状の開発組織の能力はそのSLO値を達成可能か?
繰り返しにはなりますが、信頼性の維持は実質的に品質とコストのトレイドオフです。
SLOを高く設定すればするほど、維持するのに必要な労力とコストが指数関数的に跳ね上がります。
実際に、100%のSLOを維持するための労力とコストが無限大になるので、実現不可能になります。
SREの実践には、顧客満足度へのヒアリングとビジネスサイトの会話が一番重要だと私が考えています。
定期的に顧客とビジネスサイトへのヒアリングを行い、顧客が満足していただけるための適切なSLIを設定し、そして現状の労力で達成可能な合理的なSLOを設定し、必要があれば、より多くの労力やコストをかけて向上していくことがおすすめです。
最後に
えんフォトは0からSREを初めて1年半ぐらい経ちました。
まだまだたくさんの改善点があると思いながら、徐々に開発組織に定着しつつあります。
これから、顧客満足度へのヒアリングとビジネスサイトへの会話により注力し、SREの仕組みを成熟化させて行きたいと思います!
長文になってしまいましたが、ここまで見ていただいた方に少しでもSREの導入にお役に立てればと思って書きました。
明日はDoueKazunaさんの記事です!
是非お楽しみください!