去年のAdvent CalendarでJupyter+Ansibleを使ったインフラ運用の下準備と書かせていただいたわけですが、今年も1年通してJupyterを使った運用をさせていただきつつ、組織外の方々もこのやり方に巻き込ませていただいたりしていました。
で、この巻き込ませていただく取り組みの中で、Jupyter+Ansibleを使ったインフラ運用の何が伝わりずらい/誤解を招きやすいのかがなんとなく識別できてきた気がするので、ここはあえて(懲りずに)今年も同じタイトルで書かせていただきたいと思った次第です。
何が問題なのか?
これまでの記事は道具から入ってしまっていて、問題意識がイマイチ伝わりづらい感じがしていました。ので、今年はまずは問題意識から。
Automation の罠
まず、あまり**たくさんの仕事はしたくありません。**人手も足りないし。そのくせなんだかクラウドが自然なものとして定着して、1人の運用者が管理すべきシステムの規模は大きくなりつつあるように思えます。
そこでDevOpsとかInfrastructure as Codeみたいな話が出てきてシステム運用をコードで自動化しようぜとなるわけですが、一方でコードは指示されたことしか実行できません。つまり、運用をやらせるコードというものを考えた場合に、そのコード作成主は、コードが実行できるくらいに運用作業というものを網羅的に・詳細に理解できている必要が出てくるわけです。
多人数で寄ってたかって作ったOSSの組み合わせや秘伝のタレのようなコードの組み合わせの中で、そんなの無理じゃないかと思うわけですが、そんな中で人間がとれるアプローチは以下のいずれかになりそうです。
- 自分がわからない範囲を最小化できるように、対象のシステムを整理した上で、コードを記述する
- 対象のシステムはとりあえずそのままで、自分がわかっていることの範囲内をコードで記述する(わかってないことについてはよく考えないことにする)
運用しているシステムへの理解
残念なことに、対象のシステムを整理するためには、十分にそのシステムを理解する必要があります。わからないまま手をいれようものならば、対象のシステムの取りうる状態はさらに多様化し、一層運用が困難なものになる、というのは言わずもがなかなと。
一方で、自分がわかっていることの範囲内をコードで記述すると、わかっている状況に対しては自分の手を煩わせないようになって一時的には嬉しいわけですが、わかっていない状況に対してはなお一層わからなくなる傾向があるように思います。例えばシステムに問題が起きたとき、システムの自動化のためのコードも、その問題に関与したファクターの一つとして(システムの一部として)疑わねばならなくなるためです。結局、わかっていないことに対する理解の困難さはさらに増大する・・・というつらいループが待っています。
結局、運用対象のシステムのことを理解することからは我々は逃げられないわけです。
Automation ではなくて Communication
とは言え、分散システム、たとえばそれなりに長大な歴史を積み重ねてしまっているHadoopのことをイチから網羅的に勉強するとか恐ろしい気持ちになるわけです。
習うより慣れろ、ということで、ネットに散らばるノウハウの断片を読み解きながら日々の運用をするしかないように思えますが、システム運用で発生する様々な事象は様々なスパンで発生します。開発に比べて運用は長期間に渡るケースが多いので、システム運用者は一人ということはなく、複数人で取り組むことになります。結局のところ、チーム全体で対象システムへの理解を深めるということをどう実現するか?ということになるのかなと。
- 体験の共有 ... どのような状況・経緯で / どのような結果を意図して / 何をしたところ / 結果何が起きたのか
- システム理解の共有 ... 対象システムはどのような振る舞いをしうるのか / どのような状況が異常なのか / 異常発生時にどのような損害が生じうるのか
- システム・運用手法の洗練 ... 運用しやすいシステムへの調整 / 運用のための手順の洗練
と、チームとして経験を積み重ねる先に、Automationに近い状況が待っているかもしれない・・・と(個人的には)捉えています。この経験の積み重ねと共有を効果的に行える状態を作り出すのがこの方法論のゴールなのかなと。
ゴールへの向かい方
では、チームは経験の積み重ねをどうおこなっていくべきか? - この方法論として、NIIのクラウド運用チームでは、Jupyter Notebookを活用したLiterate Computing for Reproducible Infrastructure(LC4RI)を提案しています。
ここでは、経験の積み重ねのレベルを3段階に設定し、各段階において何を目指すべきか、そのために提供しているツールと留意すべき点について説明していきます。
- 運用作業をとにかく残す
- 運用作業を単純にする
- 運用作業の適用範囲を広げる
段階1: とにかく残す
運用にまつわる体験をもれなく共有するためには、その体験をできるだけ人間が読み解ける形で残す必要があります。これはJupyter Notebookの助けを借りて実現します。
Jupyter Notebook環境(お試し)
この記事で紹介するツールを盛り込んだ「全部入り」DockerイメージをDocker Hubで配布しています。ぜひご興味ある方はコンテナを実行して試してみてください。Docker Engineがインストールされている環境でしたら、お試し環境を以下のように起動することができます。
docker run -it --rm -p 8888:8888 niicloudoperation/notebook:latest
上記のコマンドを実行すると、以下のようにtokenを含むURLが表示されますので、これをブラウザで開くことでLC4RI用ツール全部入りJupyter環境を試すことができます。
[C 22:57:50.715 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=24ce34ee9360160c1ecd7216a18f5b710d92bc5bxxxxxxxx
この環境はお試しですので、Jupyter Notebook中に作成したファイルは、コンテナの停止とともに削除されますので、ご注意ください。
この環境を使って運用作業をどうやって残していけばよいのか、NIIがサンプルコンテンツとして配布しているDocker EngineのインストールNotebookを例に説明します。
操作はすべてNotebookに残す
システムの運用作業は、システムに対する操作(パッケージのインストールや、サービスの停止・起動など)の積み重ねになります。
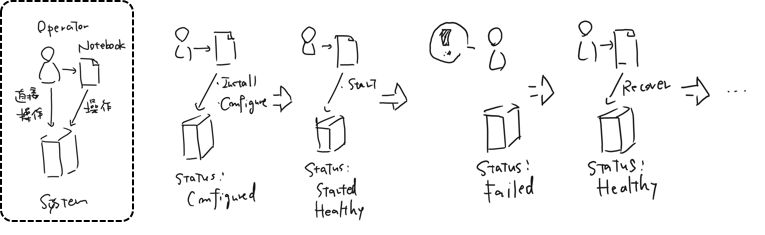
Docker Engineのインストールのように、対象システムに対するコマンド実行はすべてAnsibleを経由して実行する形でNotebookのセルに記述して実行しています。すると、実行結果も合わせてNotebookに保存されていきます。
ただし、すべての操作をコードの形で残す必要はありません。Docker Engineの動作確認に記載されているように、
Hello from Dockerのようなメッセージが表示されたらOK。
といった形で、自然言語で(人間が理解できる形式で)残しておいてもよいことが重要なポイントです。すべてコンピュータに実行させようとすると、先に述べたとおり対象システムのことを理解せねばならず、中途半端にしか動作しないコードは不明瞭な副作用を生じ、システムの振る舞いをよりわからないものに変貌させます。運用者の理解が曖昧な部分は、曖昧であることを明確に書いておくことを意識しています。Notebookは機械に与えるため(だけ)のコードではありません。人間とコミュニケーションする目的にあるわけですから、ゆるく記述してよいということを意識して、もれなく残すということが大事かなと思います。
(前提)Jupyter Notebook環境と対象システムの間のAnsible設定
Notebookから対象システムを操作するためには、Notebookと環境のBindingで示しているとおり、キーペアの設定やインベントリの設定などが必要です。
この前提条件を満たす作業自体はこの記事の目的から外れてしまうので割愛しますが、詳しくは Jupyter+Ansibleを使ったインフラ運用のはじめかた を参考にしてみてください。
確認作業もNotebookに残す
運用対象のシステムのOSやパッケージ構成がすべて統一されているという場合はまれなのではないかと思います。そのため、Ubuntuは16.04を想定の箇所のように、操作前に前提条件を決めて、確認するようにしています。この、前提条件の確認作業をセル上に残すことで、このNotebookがどのような前提で適用可能になるのか、明確にすることができます。
また、Docker Composeのインストールの手前にあるサービス状態確認やバージョンの確認セルで示しているように、インストールなどの操作を行ったら、その操作が適切にシステムに反映されているか確認をしています。これもセルの形で残すことで、意図が満たされたことをどのように確認したのかを残すことができます。
周辺の状況もNotebookに残す
あらゆる状況での操作を実現するNotebookを記述することは早々にあきらめましょう・・・なんですが、Notebookのセルに書かれたものの多くはプログラムコードの形態を持っているため、プログラマが本能的に持つ「解法を一般化したい欲」を刺激します。しかし相手としているシステムは様々な要因によって引き起こされた副作用の集積であり自分の理解は十分に及んでいないという現実を受け入れて、とにかく今やっている作業をNotebookに、わかりやすく残すことを目標とします。
わかりやすく残すためには、Operation Noteのように、このNotebookの作業を実施するに至った経緯を記述することも重要です。例えば、同じDocker Engineのインストールでも、Kubernetes用に使おうとするとインストールすべきDocker Engineのバージョンが変化したりします。このような点を一言二言でもNotebookに残すことは、他の人がNotebookの理解するときの助けになります。
段階2: 単純にする
段階1では作業を残すことが主眼ですから、Notebookは作業のたびに新規に作るか、過去の似た作業Notebookをコピーして今の作業を残すことに集中します。
そんな感じで行っている作業をとにかく残していくと、似た作業でも変わるところと、変わらないところがあることが見えてくるはずです。ここでは、Literate-computing-Elasticsearchを例に、いかにNotebookと対象システムへの理解を整理していくかを説明します。
システムの状態を整理する
Elasticsearch Notebookはお手本Notebookの一覧のように構築・診断・改善とフェーズを分けてNotebookの例を示しています。ここで重要なポイントは、01_05_Diagnosticsにより**「健康な状態」を定義(確認可能に)している**点です。
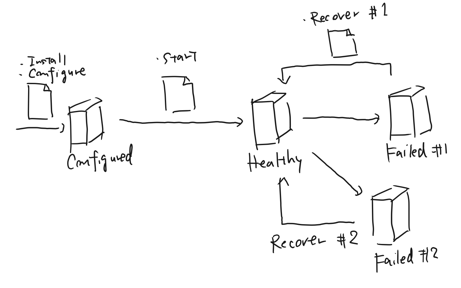
システム、特に分散システムは複数のサブシステムが高い自由度で連携するため、取りうる状態は膨大なものとなります。そんなものを一生懸命管理するのはつらいので、健康か否かというレベルに割り切ってしまうことで、健康でないときに取るべきアクションを単純化することができます。
- 考えうる症状と対処をまとめておき、先行事例があればNotebookに従って対処を行う
- 先行事例がない場合、調査して対処方法がわかれば、その対処方法をNotebookとして記録しながら実施する
- 調査しても対処方法がわからない、あるいは調査した対処方法に失敗した場合は、構築からやり直す
すべての操作をNotebookとして記録し、それぞれの状態との関連を明確化しておくことで、構築からやり直すという手段を気楽に実施できるようになります。やり直す間はサービスは止まることになりますが、状態を整理する中で各状態がユーザにどのようなインパクトを及ぼすかも整理されているはずです。計画停止であれば、意外と1日くらいのシステム停止をしても大丈夫だったりするものです。構築からやり直すのは乱暴のようにも思えますが、積み重ねられた副作用の一切を無視することができるというのは、かなり大きな安心感をもたらしてくれます。もちろん、Notebookから参照した資材をアーカイブしておくなどの前提はあるわけですが。
一連の操作をまとめて実行する
ところで、Notebookに操作を記録していく中で、「この一連のコマンドでは想定外のことはまず起きないだろう」という確信が出てくることがあります。このような一連の流れについては、関数化なりしたくなるのがプログラマの性というものです。しかし、まだまだ前提条件や人間が対処すべき部分があるかもしれません。
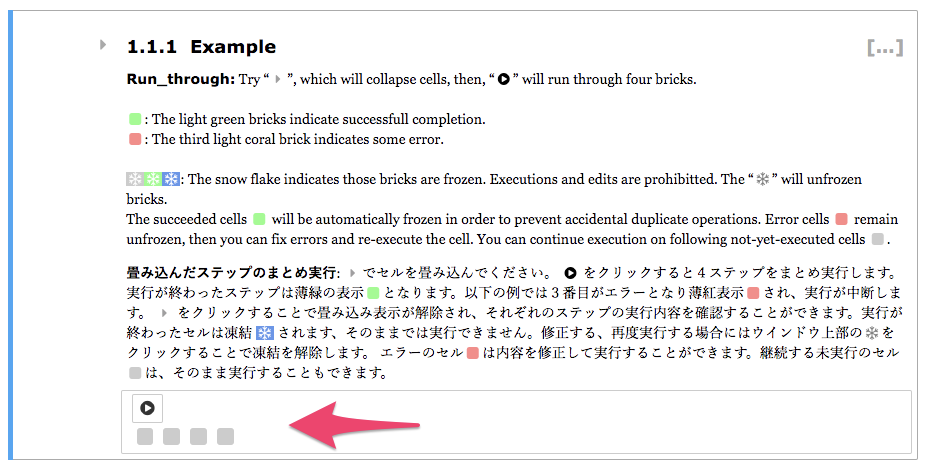
そこで、コード・説明セルを維持しつつ、まとめて実行する機能をrun_throughとして実装しています。
run_throughは、「全部入り」Dockerコンテナで試すことができます。
以下のように、複数のセルをまとめて実行することができます。実行に成功したセルは実行不可・編集不可にするFreezeという機能を組み合わせることで、エラー・未実行なセルのみを効果的にまとめ実行できるよう工夫しています。
段階3: 適用範囲を広げる
対象システムの状態への理解を整理して、これらの状態をコントロールできるようになると、この経験を別のシステムに対しても適用したくなります。
ここで悩ましいのが、Notebookは対象システムに対して強結合となる傾向があることです。ここまででは、人間がシステムに対してやっていることをNotebookに残すということをやっているので、一般化は考慮していません。単一のシステム(インスタンス)のことを十分に理解して制御可能になって、はじめて適切な形式で一般化できるのだろうという発想です。
一般化するためには、Notebookに記述された対象システムに依存する設定情報を切り離す必要が出てきます。この切り離し方の一例としてHadoop Notebookがあります。この辺はまだまだ試行錯誤というところではありますが、少し触れたいと思います。
設計から設定への関係性を明示する
対象システムに設定された項目にはそれぞれ可用性・性能など様々な理由があって、システムを運用しつづけるためには、それぞれの設定が持つ理由を意識する必要があります。SI業などでは環境定義書やパラメータシートは山ほどつくられるわけですが、構築における上流工程から下流工程へとのつなぎという観点であり、継続的に運用し続けるための情報としてまとめられているというケースは非常に少ないのではないかと思います。
収容設計の準備Notebookでは、これらの収容設計から設定への流れをNotebookとして明示することにチャレンジしています。このように設計から設定項目への流れをNotebookとして記録することで管理可能にしようとしています。
設定情報は運用環境の変化にともなって変化し続けるべきものです。設計との関係性を明示しつつも変更を可能にすることで、より柔軟な運用ができるのではないかと思います。
まとめ
そんな感じで、まだまだ試行錯誤の中というところではありますが、LC4RIに対する自分の理解をCommunicationという論点でまとめ、自分がおこなっているチャレンジについて言語化してみました。
今回はrun_throughについて紹介しましたが、NIIクラウドの中で試作しているツール類はDockerイメージ中に他にも入れ込んでありますので、ぜひ試してみてください!