発端
自作でTwitterのbot作りたいな〜
せやニコニコのプリチャンBBシリーズとプリパラBBシリーズのタグの動画だけを抽出してランダムにつぶやくbotを作ろう
環境
- 言語:Ruby 2.6.3
- データ保存:Redis
- 動作環境:Heroku
構成はこんな感じ
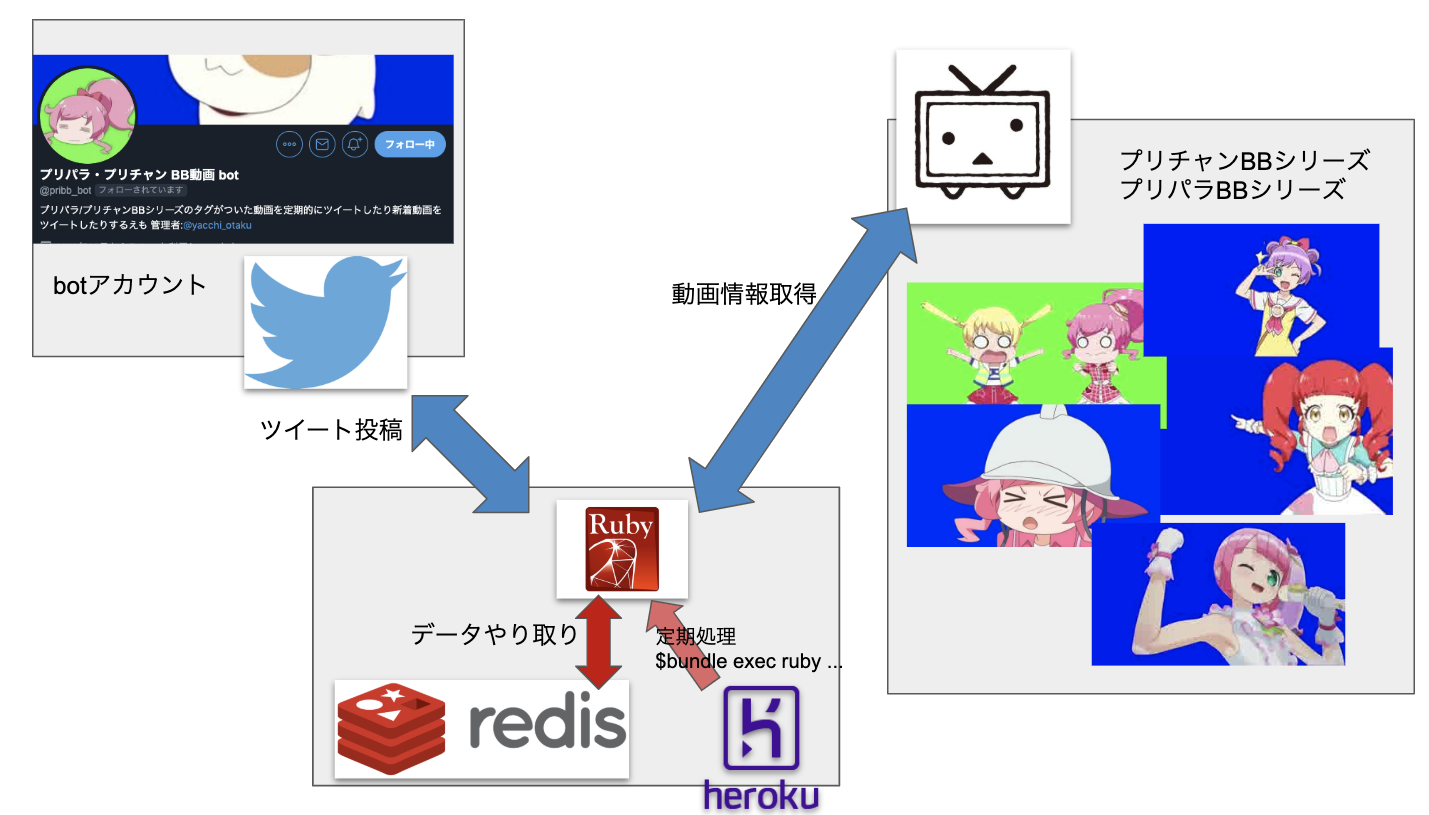
heroku
- gitで簡単にコードがデプロイできて色々勝手にやってくれる便利なやつ
- heroku schedulerを用いると定期的な処理ができる
- redisやpostgresなんかにも対応してる
- 個人的にはElixirのデプロイにも対応してるのが感動してる
- 今回のように簡単なアプリケーションからそれなりに大きなアプリケーションまで扱える
詳しくは公式サイトを見てください https://jp.heroku.com/
Ruby
- 日本人大好きオブジェクト指向プログラミング言語
- 書きやすくて個人的に好き
- がんばRuby
source 'https://rubygems.org'
ruby '2.6.3'
gem 'twitter'
gem 'redis'
gem 'activesupport'
gem 'rest-client'
Redis
- Key Value Storeとして扱います
以下wikiより
ネットワーク接続された永続化可能なインメモリデータベース
連想配列、リスト、セットなどのデータ構造を扱える
いわゆるNoSQLデータベースの一つ
簡単なデータを扱う際に楽そうですね
Rubyで扱う
-
require 'redis'するだけ - 今回は'contents'というkeyにリストとしてデータを放り込む
- リストの中身はハッシュをjsonにして保存してます
require 'redis'
require 'json'
class ContentsStore
def initialize
redis_url = ENV['REDIS_URL']
# Redisに接続.ローカルとherokuでコード変えるのだるかったのでこうしました
@redis = redis_url.nil? ? Redis.new(host: 'localhost', port: '6379') : Redis.new(url: redis_url)
@redis.ping # Redisとの疎通確認(Redis.newだと接続失敗時にエラー吐かないので一応)
end
def all_contents
# これで'contents'をkeyとしたデータをすべて引っこ抜ける.jsonとして保存してるのでもとに戻って頂く
@redis.lrange('contents', 0, -1).map { |c| JSON.parse(c) }
end
# すべてのidだけ引っこ抜くメソッド
def content_ids
all_contents.map { |a| a['id'] }
end
# Redisにcontentのハッシュを突っ込むメソッド
def push_content(content)
ids = content_ids
return if content['id'].nil? || content['title'].nil? || ids.include?(content['id'])
@redis.rpush('contents', content.to_json) # リストの末尾に追加
end
def reset_contents(contents)
@redis.del('contents') # contentsのkeyのデータをすべて削除
contents.each { |content| push_content(content) } # 1こずつリストに突っ込む(速いから大丈夫やろ)
end
end
Twitter API
- 言わずとしれたTwitterアカウントの機能を外部アプリケーションからゴニョゴニョするやつ
- 導入について多数の記事があるので今回は説明を省略します
- 各種キーを入手して使用
- 今回は投稿のみ
Twitterというgemを使って簡単導入
クラス自体は↓みたく簡単実装
require 'twitter'
class TweetClient
def initialize(text)
@text = text
@client = Twitter::REST::Client.new do |config|
config.consumer_key = ENV['CONSUMER_KEY']
config.consumer_secret = ENV['CONSUMER_SECRET']
config.access_token = ENV['ACCESS_TOKEN']
config.access_token_secret = ENV['ACCESS_TOKEN_SECRET']
end
end
def send_tweet
begin
@client.update(@text)
rescue => e
p e
end
end
end
ENV['CONSUMER_KEY']などはherokuで変数の設定できるのでAPIキーなどの外部にgithubに公開したくない値を扱う際には使うようにする
この変数はコードの変更なしに変えられるため定数に変更があった場合とかでも便利
ニコニコAPI
キーワードやフィルタ条件を指定して、niconicoのコンテンツを検索できます
できるだけ以下のヘッダーを指定してください。
User-Agent: サービスまたはアプリケーション名が分かる値。最大:40文字。
なくても大丈夫そうですが一応入れて上げましょう
クエリパラメータ
GETメソッドのパラメータとして指定できる(URLの末尾に?とか&とか使うやつ)
| パラメータ名 | 型 | 省略可能か | デフォルト値 | 例 | 説明 |
|---|---|---|---|---|---|
| q | string | no | - | ゲーム | 検索キーワードです。 書式の詳細は*1を参照してください。 |
| targets | string | no | - | title,description,tags | 検索対象のフィールド(複数可、カンマ区切り)です。キーワード検索の場合、title,description,tagsを指定してください。タグ検索(キーワードに完全一致するタグがあるコンテンツをヒット)の場合、tagsExactを指定してください。 |
| fields | string | yes | - | contentId,title,description,tags | レスポンスに含みたいヒットしたコンテンツのフィールド(複数可、カンマ区切り)です。フィールド名は*2を参照してください。 |
| filters | string | yes | - | - | 検索結果をフィルタの条件にマッチするコンテンツだけに絞ります。フィルタの書式には*3を参照してください。空文字はnull扱いになります。 |
| jsonFilter | string | yes | - | - | OR や AND の入れ子など複雑なフィルター条件を使う場合のみに使用します。 OR / AND / NOT 単体で使用する場合は filters を使ってください。フィルタの書式には*4を参照してください。 |
| _sort | string | no | - | -viewCounter | ソート順をソートの方向の記号とフィールド名を連結したもので指定します。ソートの方向は昇順または降順かを'+'か'-'で指定し、ない場合はデフォルトとして'-'となります。使用できるフィールドは*2を参考にしてください。nullになっているコンテンツはソートの方向に関わらず最後になります。 |
| _offset | integer | yes | 0 | 10 | 返ってくるコンテンツの取得オフセット。最大:1600 |
| _limit | integer | yes | 10 | 10 | 返ってくるコンテンツの最大数。最大:100 |
| _context | string | no | - | apiguide | サービスまたはアプリケーション名。できるだけ指定してください。最大:40文字 |
必須項目
- q:検索文字列.今回はタグの名前なので
q=プリチャンBBシリーズってな感じで使用 - targets:qで指定した項目を動画の何で検索をかけるか.今回はタグの完全一致にしたので
targets=tagExact - _sort:表示順.必須なので項目は公式のドキュメントで調べてください.今回は投稿順で使ったので
_sort=startTime
省略可能項目
- fields:検索後のAPIの表示項目.contentId:動画のID(smxxxxってやつ),title:タイトル,description:動画説明,tags:動画のタグという感じ.今回は
targets=contentID,titleで使用.これ指定しないと何も返ってこないので実質必須だと思う. - filters:再生数とかマイリスの数とか投稿日時で絞り込めるので使いこなせたら便利そう(今回は未使用)
- jsonFilter:↑のjsonで指定できるやつ(未使用)
- _offset:コンテンツの取得オフセット→ページ番号的なやつ.今回は全動画取得のために使用.デフォは1.最大1600.
- _limit:レスポンスのコンテンツの数.デフォは10.最大100.
- _context:サービス名.なるべく入れてとのこと
実際に使ってみる
GET https://api.search.nicovideo.jp/api/v2/video/contents/search?q=プリパラBBシリーズ&targets=tags&_sort=startTime&fields=contentId,title&_context=hoge&_limit=3&_offset=1
レスポンス↓.totalCountで動画の総数が取得できるのでこれと_limitの値を使って_offsetの値を操作する
{
"meta": {
"status": 200,
"totalCount": 149,
"id": "f51c8259-f365-45aa-8299-0a1e1f1da682"
},
"data": [
{
"title": "高橋くんGB",
"contentId": "sm35739855"
},
{
"title": "かわいいえもちゃんGB他おまけ.mp4",
"contentId": "sm35239977"
},
{
"title": "ノンシュガーカフェ宣伝+ミニキャラBB",
"contentId": "sm35147653"
}
]
}
Rubyで書いた感じ
require 'uri'
require 'rest-client'
@niconico_url = 'https://api.search.nicovideo.jp/api/v2/video/contents/search'
@header = { 'User-Agent': ENV['USER-AGENT'] }
@params = {
'q': '',
'_offset': '1',
'targets': 'tagsExact',
'_sort': 'startTime',
'fields': 'contentId,title',
'_context': ENV['_CONTEXT'],
'_limit': '100'
}
uri = URI(@niconico_url)
uri.query = @params.to_param
res = JSON.parse(RestClient.get(uri.to_s, @header))
定期的につぶやく処理
heroku schedulerを用いて毎時間ごとに↓を実行して毎時間つぶやいてます
$ bundle exec ruby lib/tweet_random_content_job.rb
require_relative 'contents_store.rb'
require_relative 'tweet_client.rb'
require_relative 'tweet_content.rb'
class TweetRandomContentJob
include TweetContent # ニコニコのURLとかをくっつけるコードが書いてあったりする
def perform # performって名前はsidekiqを意識してた
# Redisからコンテンツの抽出
contents = ::ContentsStore.new.all_contents
return if contents.size <= 0
random_tweet(contents.sample)
end
private
def random_tweet(content)
text = "#{content['title']}\n#{@url}#{content['id']}"
tweet_content(text) # つぶやく
end
end
TweetRandomContentJob.new.perform
インスタンス生成するコードがクラスと一緒に書かれていて気持ち悪いとかいわないでください
すべての動画の情報を取得する処理
同様に毎日0時に実行して動画の情報をすべて取得して差分をチェックします
今回はredisを信じて変更がある場合はすべて消して再びすべて挿入します
require_relative 'contents_store.rb'
require_relative 'tweet_client.rb'
require_relative 'tweet_content.rb'
require_relative 'niconico_pribb_extractor.rb'
class TweetNewContentsJob
include TweetContent
def perform
# APIからすべての動画を取得
new_contents = NiconicoPribbExtractor.new.all_contents
# Redisを参照して差分を確認
store = ContentsStore.new
old_contents = store.all_contents
# 追加された動画
add_contents = content_diff(new_contents, old_contents)
# 消えた・タグが外された動画
deleted_contents = content_diff(old_contents, new_contents)
# 差分があったものをツイート
new_contents_tweet(add_contents) if add_contents.size > 0
# Redisに新規保存
store.reset_contents(new_contents) if add_contents.size > 0 || deleted_contents.size > 0
end
private
def new_contents_tweet(contents)
new_content_text = "新たに動画が追加されました\n"
# 文字数に制限あるので最大で10までにしておく
tweet_text = contents[0..9].each_with_object(new_content_text) do |content, text|
text += "#{content['title']}:#{@url}#{content['id']}\n"
end
tweet_content(tweet_text)
end
def content_diff(content_list_1, content_list_2)
content_list_2_ids = content_list_2.map { |content| content['id'] }
content_list_1.each_with_object([]) do |content, arr|
arr << content unless content_list_2_ids.include?(content['id'])
end
end
end
TweetNewContentsJob.new.perform
そんな感じでできたもの
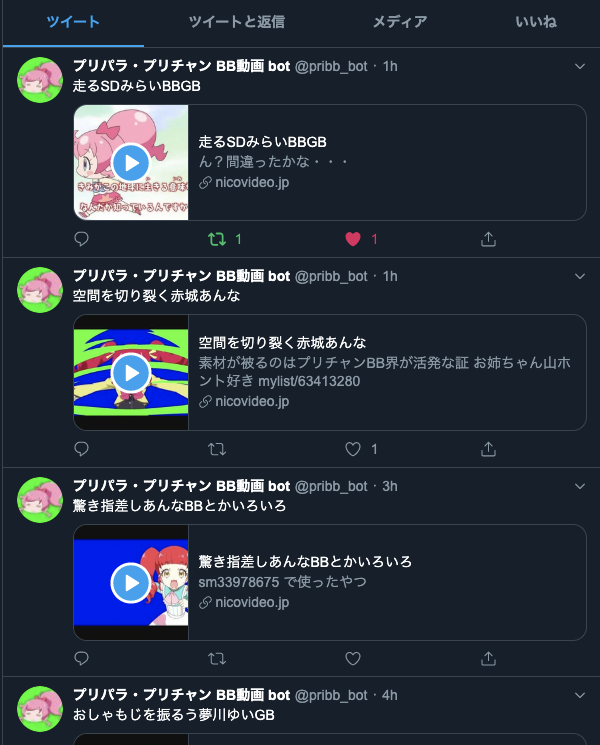
みんなフォローしてね♡