Redshiftのテーブル作成でよく忘れるポイントをまとめておこうと思います。
主に作成する際のポイントだけで、データ設計に関することは書きません。
レコード作成時間
使うかどうかはわからなけいけど、わりとつけ得なカラムだと思うのでよくつけます。
ただ、よくあるRDBで設定するdefault current_timestampとかは使えないので注意。
とりあえずこんな感じで設定しておきましょう。
create table hoge (
// なんか他のカラム
created_time timestamp encode DELTA default sysdate
)
ソートキー、分散キー
Redshiftのパフォーマンスを上げるために、なんなら一番重要とも言えるところ。
- ソートキー:レコードのソート順
- 分散キー:複数のノードに分散するためのキー
ソートキーの設定
特に理由がなければcreated_timeとかでいいと思います。
というのも、新しいデータだけを処理したい時に早くselect出来るためです。
ただ、特別に重いjoinなどをするときは考え直したほうがいいです。
複数設定できますが、ソートキーを複数設定するだけなので、こだわりがなければ一つでOKです。
複数設定する時は複合ソートキーと言いますが、あんまりソートキーを増やしすぎるとテーブルのディスク容量が増えます。なので、ちゃんとソートしておくべきものを設定しておきましょう。
create table hoge (
// カラム
)
sortkey(created_time)
分散キーの設定
ユーザーのログなどであればユーザーIDとか分散しやすいものがいいです。
変なのを設定するとノードごとにデータ量の偏りができます。
もちろん、特別に重いjoinなどをするときは考え直したほうがいいです。
create table hoge (
// カラム
)
distkey(created_time)
※ちなみに、distkeyはsortkeyより先に設定しないとクエリエラーになったりします
JOINするのがわかっている時
RedshiftのJOIN処理は、内部的に3種類あります。
細かいところは こちら(公式ヘルプ) を見てください。ただ、だいたい下記の覚え方でいいと思います。
1ノードで運用していたりすると、たまーにMerge JoinよりもHash Joinのが速い時もありますが、だいたいの場合Merge Joinのが速いです。
- Nested Loop Join: やべーやつ
- Hash Join: 普通のやつ
- Merge Join: 速いやつ
ただ、Merge Joinはかなり条件が厳しいです。
- 結合する列が、ソートキーと分散キーの両方に設定されている
- 両方のテーブルが、それぞれ80%以上ソートされている
このJoinをしようと思ったら、テーブルを作る際に狙って作るしか無いです。
圧縮形式
圧縮形式によってディスク使用量、パフォーマンスがかなり変わるので、設定し得です。
ただいっぱいあってよくわからないので、軽くまとめておきます。
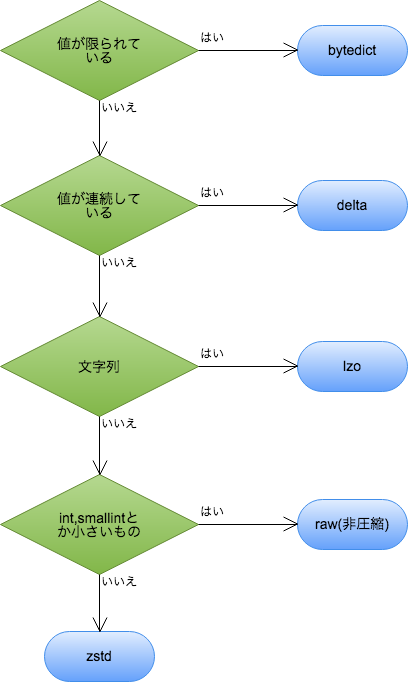
もちろん、突き詰めればもっと効率よく圧縮方式を選択することも出来ますが、あくまで雑にまとめてます。
(せめてこれくらい判断条件に入れたほうがいいよ、とかあれば教えてください、更新します)
設定方法
create table hoge (
// なんかカラム
columnName varchar(255) encode lzo,
// なんかカラム
)
これで幸せなRedshiftライフを送りましょう。