スクレイプ対象
英語の学習にも役立てたいのでスクレイプ対象は購読しているThe Economist。
The EconomistのPuppeteerによるスクレイピングなので、作ったライブラリの名前はPuppenomist。良いもじりだと思っている。
学び
-
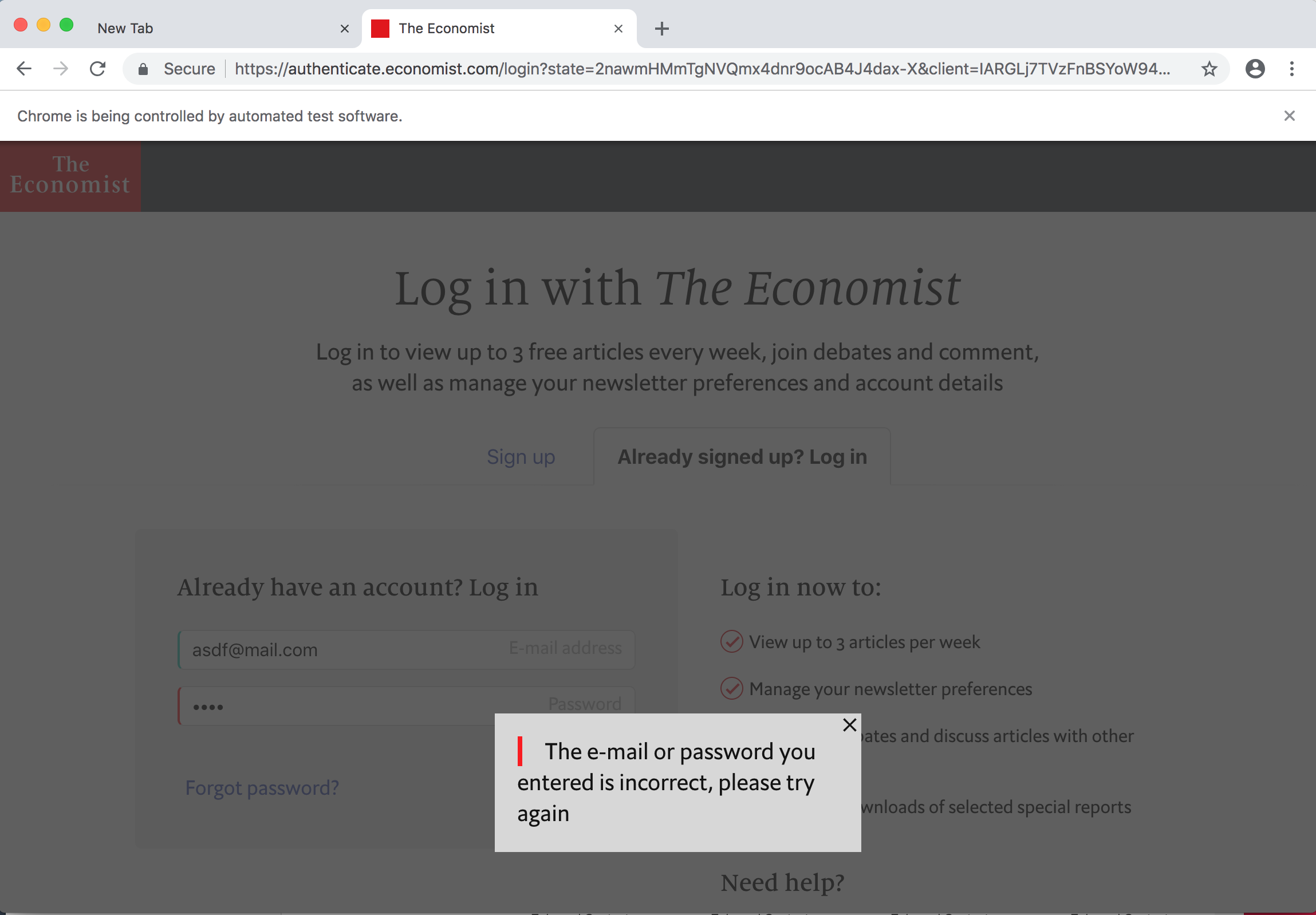
ログイン処理
ログイン処理を行なっているPuppeteerの例は少ないので実例として参考になるのでは。 -
マナーを守ったスクレイピング
The Economistのrobots.txtに「5秒ごとのアクセス」とあるので、割りに時間がかかる。1冊分で5,6分、一年分だと数時間になる。数時間だと1回では無理なので、ログを残して途中から再開できるようにした。 -
RECAPTCHA
サイト側ではgoogleのRECAPTCHAが設置されている。
詳しくは書かないけど、RECAPTCHAに引っかかりやすいページや挙動というものがある。
挙動に関しては、ランダムな秒数かかるようにしてみたけどそこまで効果は出ず。クライアントやIPアドレス偽装は宜しくないので特に何もせず。
キャプチャ
こんな感じで動く。
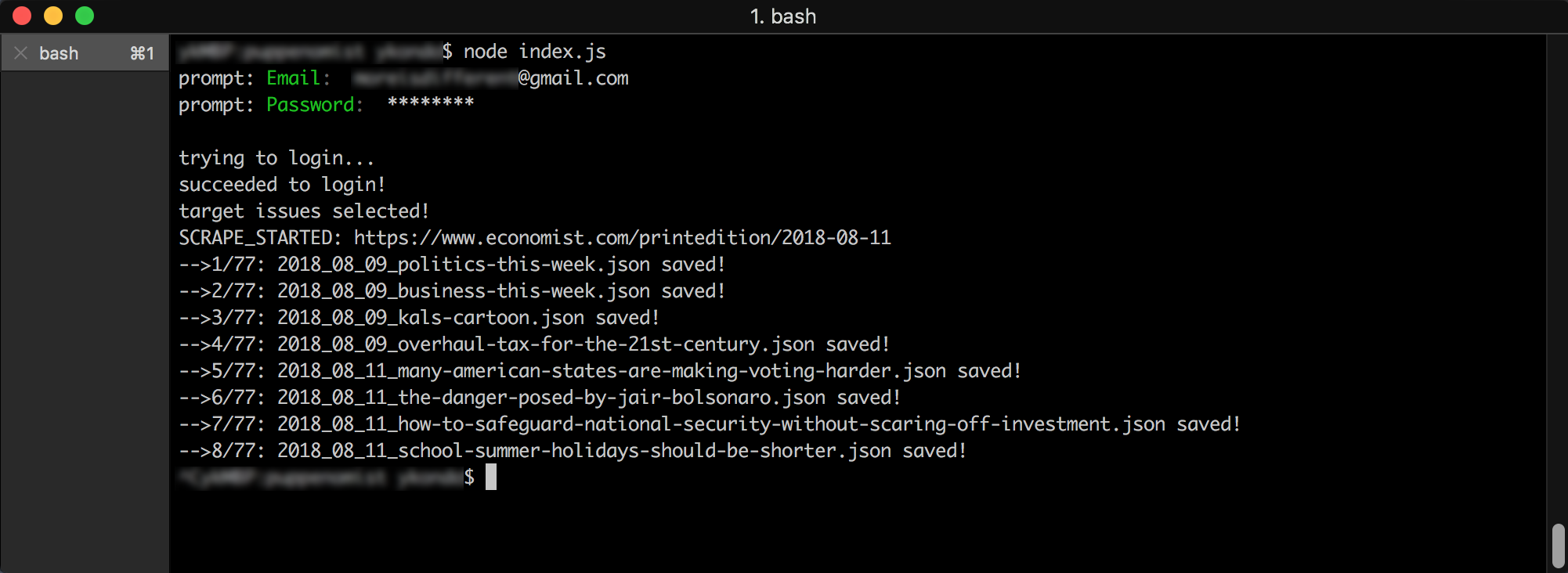
The Economistのアカウントを持ってない人でも適当なアカウントとパスワードを打てば、ログイン試行までは試せます。もちろんログイン失敗してそれ以上進まないけど。
-vオプションでHeadlessでなくChromiumが立ち上がるので動きが分かり易いと思います。

TODO
- ランダムで出てくるポップアップの検知
何度かやっているとランダムでポップアップが出てきてログイン処理が動かない時がある。検知して再ロードとかエラー処理が必要。 - OSSに自分のアカウント情報を教えたくない
このライブラリでスクレイプするにはThe Economistの実際のアカウント情報が必要になる。自分で作って自分で使う分には良いけど、誰か別の人が使う時には自分のアカウント情報を信頼できないOSSには教えたくないハズ。
ログイン処理だけは信頼できる別のライブラリに任せる、とか外だしに出来ると嬉しいけど、何か方法があるのかな? - スクレイプしたデータで遊ぶ
2017年の全冊をスクレイプしたのでそのデータで遊びたい。とりあえずBag of Wordsで各記事の特徴語検索を出来るようにした。
http://economistsearch.herokuapp.com
別のQiita記事を書く。
ソース
https://github.com/ya9do/puppenomist
実際にスクレイプするにはThe Economistのサブスクリプションアカウントが必要です。