どうも、投稿日が誕生日の @ya-man です。
皆様に本記事を読んでいただけることが最高のプレゼントになります。
ぜひご一読いただけますと幸いです!
はじめに
みなさま、インフラに携わるエンジニアが日々どのようなことに気をつけて仕事をしているかご存知でしょうか。サービスを安定的に動かすお仕事にスポットライトが当たることは少ないです。それは、ユーザにとってはサービスがいつでも使えることが当たり前ですし、開発者としてもいつでもサービスが動かせる状態が当たり前だからです。
今からご紹介する内容は、ベテランのエンジニアやインフラに携わるエンジニアにとっては当たり前の内容です。当たり前だからこそ、言語化されていなかったりしますし、新米エンジニアがハマるポイントでもあります。そんなサービスを守るために行われている当たり前をいくつかご紹介できればと思います。
昨今、インフラの抽象化や製品の成熟が進み、インフラを意識しなくても良かったり、トラブルに見舞われることも少なくなってきていることから、新米エンジニアが当たり前を知らないケースが増えてくると考えています。
地雷を踏む経験からではなく、本記事で知識として当たり前を知ることで、爆発するエンジニアが減れば良いなという思いで投稿しました。また、本記事を通じて、なぜインフラに対する変更に対して慎重になったり、時間がかかってしまうのかという点を少しでも開発者にも知っていただければ幸いです。
1. OSやミドルウェアだってソフトウェアであることを認識する
ソフトウェアであり、継続開発されている以上、バグが潜り込む可能性を秘めています。
私は新米エンジニアのときに以下のように考えていました。
- 有名なソフトウェアだから細かいところを意識しなくても安全に動くだろう。
- 素晴らしい開発者によって作られているので不具合が出る可能性は低いだろう。
- 製品ドキュメントは信頼できるもので、間違いはない。
このような考えのもと行動することで、いつかは地雷を踏むことになります。
その経験から、当時の私の考えが浅はかであったことを思い知らされます。
間違った考え①: 有名なソフトウェアだから細かいところを意識しなくても安全に動くだろう。

細かな設定を理解していなくても動かすことはできるでしょう。
しかし、障害が発生した際に、あなたが設定したOSやミドルウェアが原因でないと胸を張って言えるでしょうか。
障害が発生している緊急事態に1つ1つパラメータを精査していくわけにはいきませんし、パラメータではなく製品のバグである可能性もあります。
迅速にトラブルに対応できるように、自身が担当する製品についてはしっかりとパラメータを理解しておきましょう。
間違った考え②: 素晴らしい開発者によって作られているので不具合が出る可能性は低いだろう。

ソフトウェアである以上、バグは必ず出ます。
製品のChangeLogを確認すると一目瞭然ですが、複数のBugFixが行われていることがわかると思います。
(参考): MySQL5.7.32のChangeLog
バグはあるものと理解したうえで、利用するバージョンの選定を行います。
当然ですが、リリースから日数が経過しているほうがバグが改修された製品がリリースされています。
以下を確認していただいてもわかるように、MySQL5.7.32よりもMySQL5.7.2のほうがBugFixが多いことがわかります。
(参考): MySQL5.7.2のChangeLog
リリース日から日数が十分に経過し、マイナーバージョンアップが複数行われている状態を 枯れている(※) と言ったりします。
基本的には、枯れているほど、重大なバグが潜んでいるリスクは低くなるため、信頼性が求められる場合は十分に枯れたバージョンを選定しましょう。
ただし、新しいバージョンほど新機能があったりパフォーマンスが向上していることがありますので、「バグが潜んでいるリスク」と「新機能を利用した場合のメリット」を鑑みて選択します。
※ ミドルウェアによってバージョニングが異なります。「マイナーバージョンが高い = 枯れている」ではない場合があります。バージョニングをまず確認しましょう。
間違った考え③:製品ドキュメントは信頼できるもので、間違いはない。

人間が作成するものである以上、誤りは発生します。
製品ドキュメントがどの程度信頼できるかは製品にもよりますが、100%信じられるドキュメントはないと肝に銘じましょう。実際に製品を動作させて、検証し、意図した挙動になることを確認することをおすすめします。
前職での体験談を1つご紹介します。
- あるストレージ製品においてボリュームの拡張作業を実施することになりました。
- ドキュメントには無停止でボリューム拡張可能と思われる記載がありました。
- 念のため、製品のプロフェッショナルであるサポートにも問い合わせ、無停止でボリューム拡張可能であることがわかりました。
- また、過去事例からバグ等がないかも調査いただいていました。
- 作業当日、ボリューム拡張作業を実施したところ、該当ボリュームへの書き込み/読み込みすべてが停止し、大量のアプリケーションエラーが発生しました。
- 原因は製品のバグで、特定バージョンのストレージOS、ドライバでのみ発生するものだとわかりました。
このような話は、インフラに携わるエンジニアからすれば "よくあること" かと思います。
こういった体験から先輩エンジニアは「動作検証したの?」などと確認します。
若かりし私は、「ドキュメントでは問題なさそうだから大丈夫でしょう...」なんてことを思いながら、嫌々動作検証を行うことがありました。
痛みを知った今なら言えます。実際に動かして、目で見たものだけを信じましょう。
2. インフラに対する変更作業は影響範囲が大きいことを認識する
サービスを長期間運用していると、OS、ミドルウェアの保守期限切れなどで、移行やバージョンアップ作業を実施する機会があります。
下図に示すように、アプリケーションはハードウェア、OS、ミドルウェアなど複数の要素の上で稼働しています。
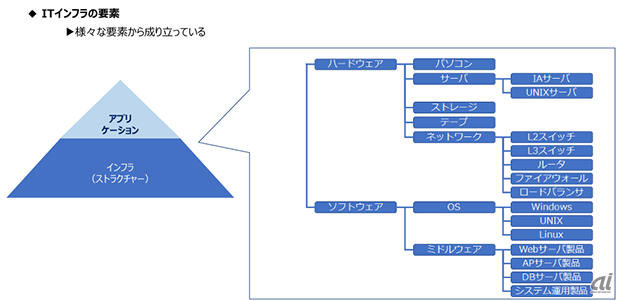
インフラはアプリケーションを稼働するために利用されていますので、**インフラ部分に問題があると広範囲のアプリケーションのエラーとなって問題が表面化します。**ただし、アプリケーションは常に開発され続けていますから、インフラが原因でないエラーも発生するため、エラーがでたタイミングではアプリケーションかインフラか見分けがつきません。
○ インフラ起因の障害は切り分けが大変、迷わないように地図を持とう
例えば、あるインフラの要素(インフラA)に設定変更をかけた数日後に、原因不明のアプリケーションエラーが発生したとしましょう。また、その原因がインフラAの設定変更作業によるものであったとします。
その場合、以下のように調査が進んでいくでしょう。
- アプリケーションの改修が原因かどうか切り分ける。
→ アプリケーションが原因ではなさそう - どのインフラ要素がアプリケーションエラーの原因になっているか調査する。
→ 各種エラーの特徴から、インフラAが怪しいとわかる - エラーの原因となっているインフラ要素の、どの部分が原因になっているか調査する。
パターンA: あるパラメータが原因で、アプリケーションのエラーが出ているとわかる → 調査終了
パターンB: 原因不明 → 4へ - 該当製品のバグがないかを調査する。(商用製品の場合、サポートに問い合わせを実施する)
このように、インフラが原因の障害(特に製品のバグによるもの)は、いくつもの切り分け作業が必要で時間がかかります。それぞれのポイントで迅速かつ適切に切り分けができるように、パラメータを把握しておきましょう。
パラメータを把握せずに障害調査することは、地図やスマホを持たずに海外旅行に行くようなものです。
○ パラメータを1つ変更することに慎重になる理由を知る
新米エンジニア時代の私は、**「パラメータ1つ変えるだけなのになんでこんなに慎重なんだろう」**と疑問に感じていました。
その答えとしては、インフラ起因の障害はアプリケーション全体に及ぶだけでなく、障害調査範囲も多岐に渡るためでした。
**設定を熟知していても、「製品のバグ」や「各種コンポーネントの互換性の問題」が障害原因となることもあります。**そんなリスクを抱えているのですから、「パラメータを1つ変更して挙動を変える」ことに慎重になるのもわかりますね。未知の障害リスクを背負っているのですから、せめて自身が変更するパラメータの挙動ぐらいは把握することが必要です。
3. 作業の準備は入念にする
インフラに係る作業は、作業の都合上アプリケーションを停止させたり、一部機能制限を行う場合があります。そういった作業の場合は、関係各所との調整をしたのち、限られた時間帯で行うことが多いです。
作業にはトラブルがつきものですので、再調整が伴わないように入念な準備を行いましょう。
-
作業内容について十分に理解する。
- 例えば、バージョンアップ作業を行う場合は、ChangeLogを読み込み、影響のある設定値を把握しましょう。
- 作業によって起きうるリスクを想定し、事前に対策を検討しておきます。
-
作業手順書とタイムスケジュールを作る。
- 限られた時間内に作業を終えるために、作業手順書とタイムスケジュールを作成しましょう。
- 作成することで、未検討であった項目が洗い出されるかもしれません。
-
作業手順書と変更内容について十分に検証する。
- 作業手順書や変更内容は机上で確認するだけでなく、検証しましょう。
- 「実際に実行してみると意図したものと違った」ということはよくあります。
-
作業時の体制を整える。
- 大きめの作業を実施する際は、作業体制を整えましょう。
- 作業実施者、連絡係を最低限用意し、製品に精通している人に連絡がつくようにしておきます。
-
リハーサルを実施する。
- 可能な限り、本番に近い状態でリハーサルを実施しましょう。
- 実行環境や対象機器の設定差異などで意図せぬことが発生するかもしれません。
-
予備日を設ける。
- 万全な準備をしたと思っていても思わぬところで躓くものです。
- 何かあった際に急いで別日で再調整をしなくても良いように、予備日を設けておきましょう。
まとめ
-
OSやミドルウェアだってソフトウェアで、人間が作ったものです。
- どれだけ素晴らしい開発者が作ったとしてもバグは発生します。
- バグがあるものと思って、動作検証を実施しましょう。
- また、バグ以外の要因での失敗を無くすために、パラメータは把握しておきましょう。
-
インフラに対する変更作業は、影響が広範囲にわたり、調査が困難です。
- 影響が大きいことを認識したうえで準備しましょう。
- もしもの場合に備えて、変更する内容について検証し、発生しうる影響を想定しておきましょう。
-
どれだけ準備していても、想定外は起こるものです。入念な準備をしましょう。
- できる限り想定外を減らす対応と、想定外が起きた場合の対応を検討しておきましょう。
Q1. なぜインフラに対する変更に対してそこまで慎重なのか
過去にバグを踏んだ経験から、OSやミドルウェアもソフトウェアであり、バグがあるものだと認識しているからです。
ChangeLogやBugFixなどの情報を収集し、検証することこそがサービスを守るために必要な要素であることから慎重に精査します。
Q2. なぜそんなに作業時間がかかるのか
上述の調査や検証などを実施し、変更作業の障害リスクを限りなく減らす努力をしているからです。
おわりに
非常に当たり前な内容を改めて言語化してみました。
記載した内容について100%実施することが望ましいですが、現実はそうもいかないこともあります。(例えばChangeLogを全て読むなど)
経験とともに勘所がわかってきますので、こういった当たり前があるのだなと意識したうえで、プロジェクト規模や環境に合わせて対応していくことが良いかと思います。
(無警戒のときに顔面にパンチを受けたら失神するかもしれませんが、パンチがくることがわかっていれば対策は考えることができますし、失神することはないでしょう。)
過去の私のような新米エンジニアさんにとって、新たな気付きがありましたら幸いです。
明日は、 @yzusa さんの「Opsgenie を使って 障害対応の負担を軽くする取り組み」です。お楽しみに!!