はじめに
- 著者:Anwesan Pal (UC San Diego), Yiding Qiu (UC San Diego), Henrik Christensen (UC San Diego)
- 論文:https://drive.google.com/file/d/1SL_pL6DjHmRrYxpAR9wyZwydGXL2_iY_/view
以下、画像に関しては特に断りがない場合、論文中の図・表を引用しています。
概要
- ロボットのObject-goal navigationタスクにおいて,オブジェクト間の”階層関係”を利用するターゲット駆動型ナビゲーションアルゴリズム:MJOLNIRの提案
- 成功率(SR)とパス長重み付き成功率(SPL)において,既存手法よりそれぞれ82.9%, 93.5%向上した。
背景
- Object-goal Navigationタスク
- 視覚的情報を頼りに,事前に定義されたTarget objectを環境の中で検索し,ナビゲーションする
- 人間は普段,オブジェクト間の関係を無意識に記憶することで,そのタスクを効率的にこなしている.
- 従来の手法の問題点
- 自然環境におけるオブジェクト同士の関係について学習することなく,感覚入力を直接強化学習フレームワークに送信する傾向
ロボットも人間と同じように,オブジェクト間の関係性を学ばせることで,効率的にObject-goal Navigationタスクを実行させたい!
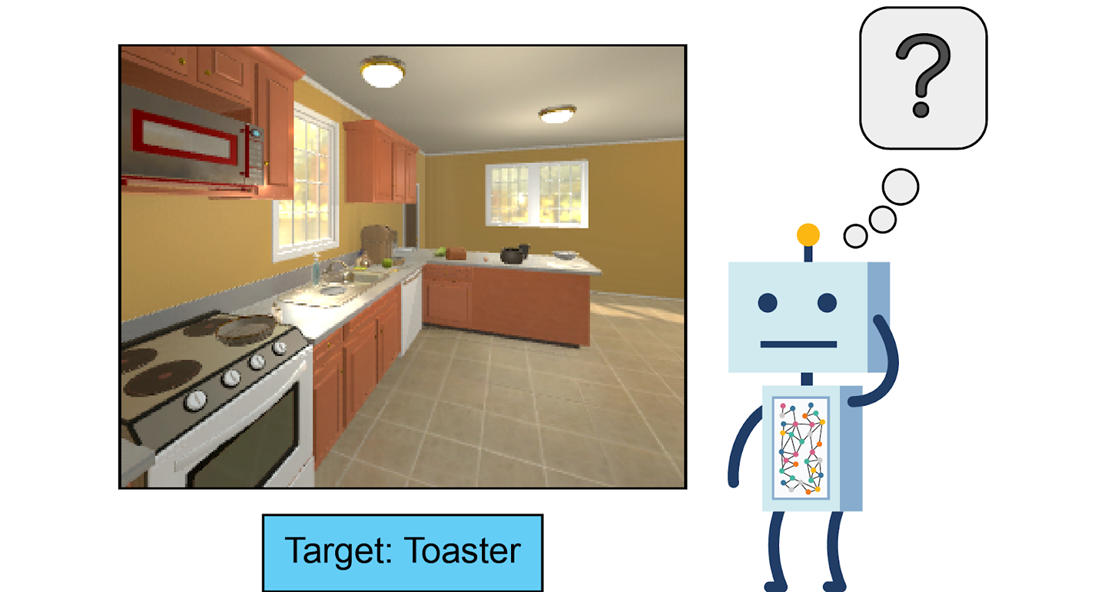
タスク定義
- 地図が与えられていない未知の環境で,Target object $t$を見つける
- Input
- 各時刻のフレームのRGB画像
- Target objectの単語埋め込み(word-embedding)
- Output
- アクション $a \in A = \{MoveAhead, RotateLeft, RotateRight, LookUp, LookDown and Done\}$
- 成功基準(終了条件)
- Target objectが現在のフレームで“見える”状態で,それが1.5m以内にあるときで,”Done“が選択されたとき
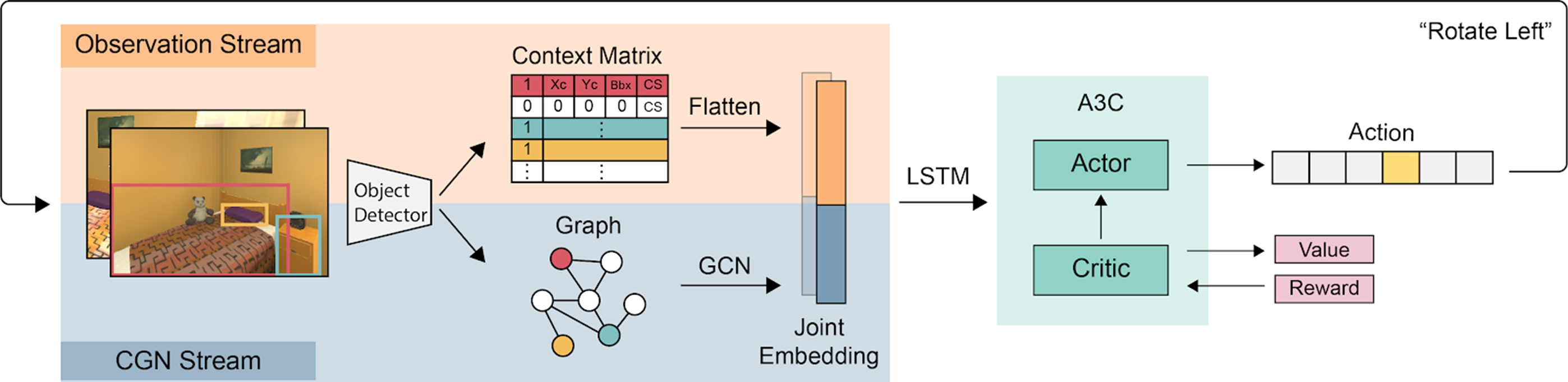
MJOLNIR
Memory-utilized Joint hierarchical Object Learning for Navigation in Indoor Rooms
- メモリを利用した屋内ナビゲーションのための共同階層オブジェクト学習
- 提案手法の特筆すべき点
- 階層的なオブジェクト間の関係を利用する
- Target objectと関係する,より大きなオブジェクト(=Parent object)
- 全体的なシーン表現より,マルチオブジェクト検出の役割を強調
- オブジェクト関係の堅牢な学習を促進するための報酬形成メカニズムの開発
- 階層的なオブジェクト間の関係を利用する
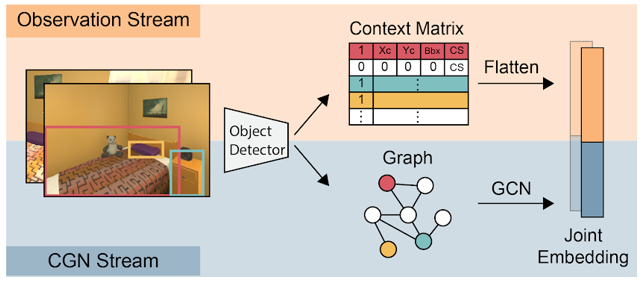
Observation Stream
-
Context vectorの作成
- $\boldsymbol{c}_{j} = [b, x_c, y_c, bbox, CS]^{T}$
- $b$:現在のフレームで検出できるかどうかを表すbinary vector
- $(x_c, y_c)$:bounding boxの中心座標
- $bbox$:bouding boxの領域
- $CS$:コサイン類似度
- $CS(\boldsymbol{g}_{o_j}, \boldsymbol{g}_t)=\frac{\boldsymbol{g}_o \cdot \boldsymbol{g}_t}{||\boldsymbol{g}_o|| \cdot ||\boldsymbol{g}_t||}$
- $\boldsymbol{g}$:Glove vector型のword embedding [Pennington+, EMNLP14]
- $CS(\boldsymbol{g}_{o_j}, \boldsymbol{g}_t)=\frac{\boldsymbol{g}_o \cdot \boldsymbol{g}_t}{||\boldsymbol{g}_o|| \cdot ||\boldsymbol{g}_t||}$
- $\boldsymbol{c}_{j} = [b, x_c, y_c, bbox, CS]^{T}$
-
Context Matrixの作成
-
1次元に平坦化し,observation vectorの生成
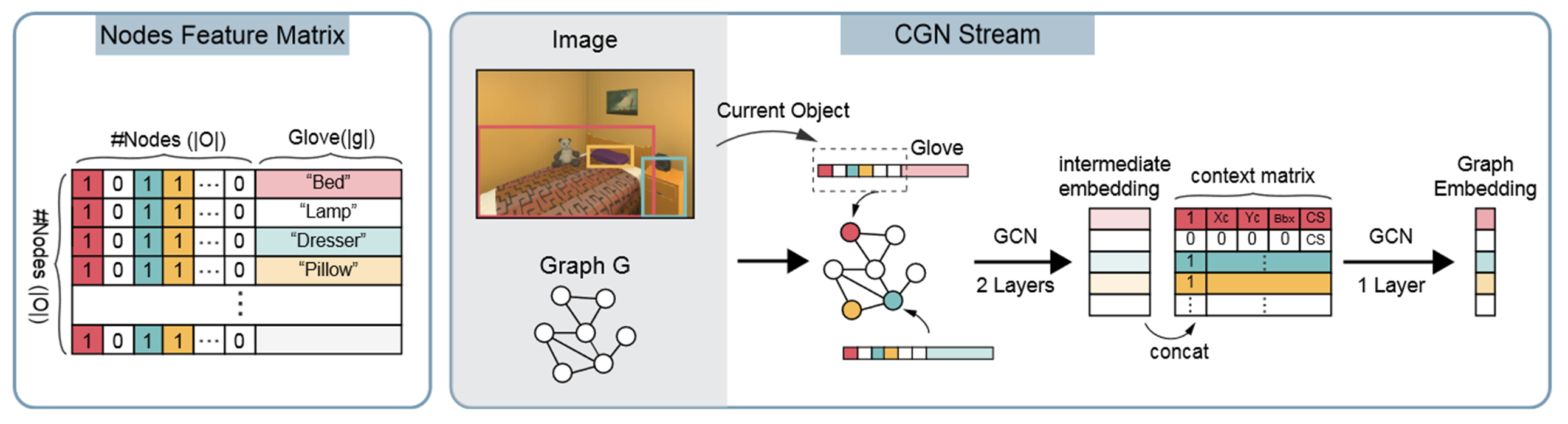
CGN Stream
Contextualized Graph Network stream
- 事前にVisual Genome (VG) datasetからknowledge graphを学習[Krishna+, IJCV17]
- 現在検出されているobject listと,objectのglove embeddingから各ノードの特徴量ベクトルの作成
- それらを結合し,2層のGraph Convolution Network (GCN) [Kipf+, 16]に通し,intermediate embeddigを生成
- context vectorと連結され,別のGCNを通過し,Graph Embeddingの生成
強化学習:A3Cモデル
- Observation vectorとGraph Embedding が連結されLSTMセルに送信.
- 最終的にA3Cモデル(強化学習手法)に送られる.
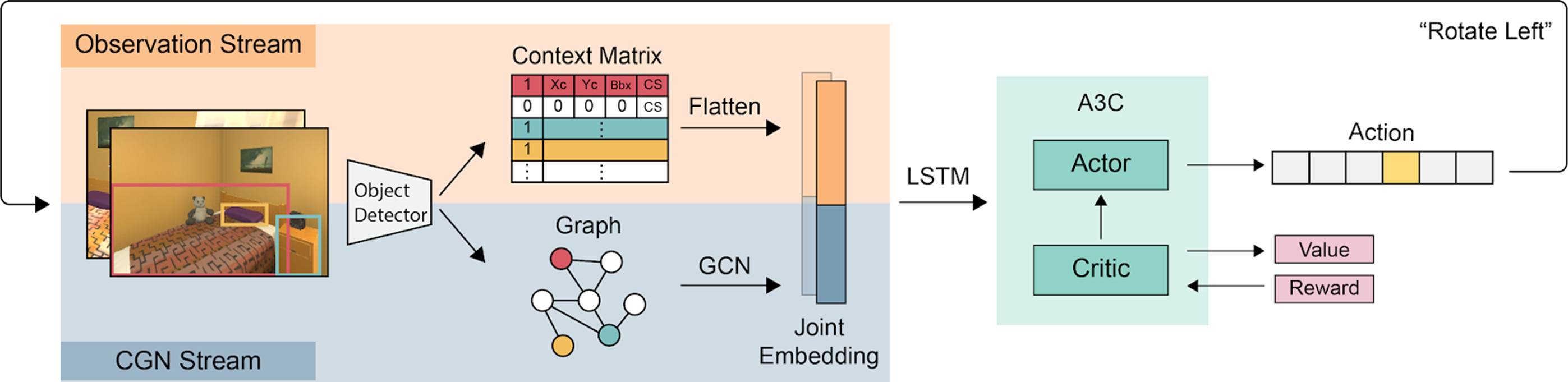
- 報酬
- ParentとTargetの関係を利用することを,正しく学習するように報酬関数を調整

- $R_p = R_t * Pr(t|p) * k$
- $Pr(t|p)$:相対的な空間距離の近さに基づく確率分布
- $k$:倍率
- ParentとTargetの関係を利用することを,正しく学習するように報酬関数を調整
実験設定
- AI2-The House Of inteRactions(AI2-THOR)[Kolve+, 17]
- 4部屋のレイアウト
- Kitchen, Livingroom, Bathroom, Bedroom
- それぞれに30部屋の環境
- Train:20,Test:10

(https://arxiv.org/pdf/1712.05474.pdf)
- Train:20,Test:10
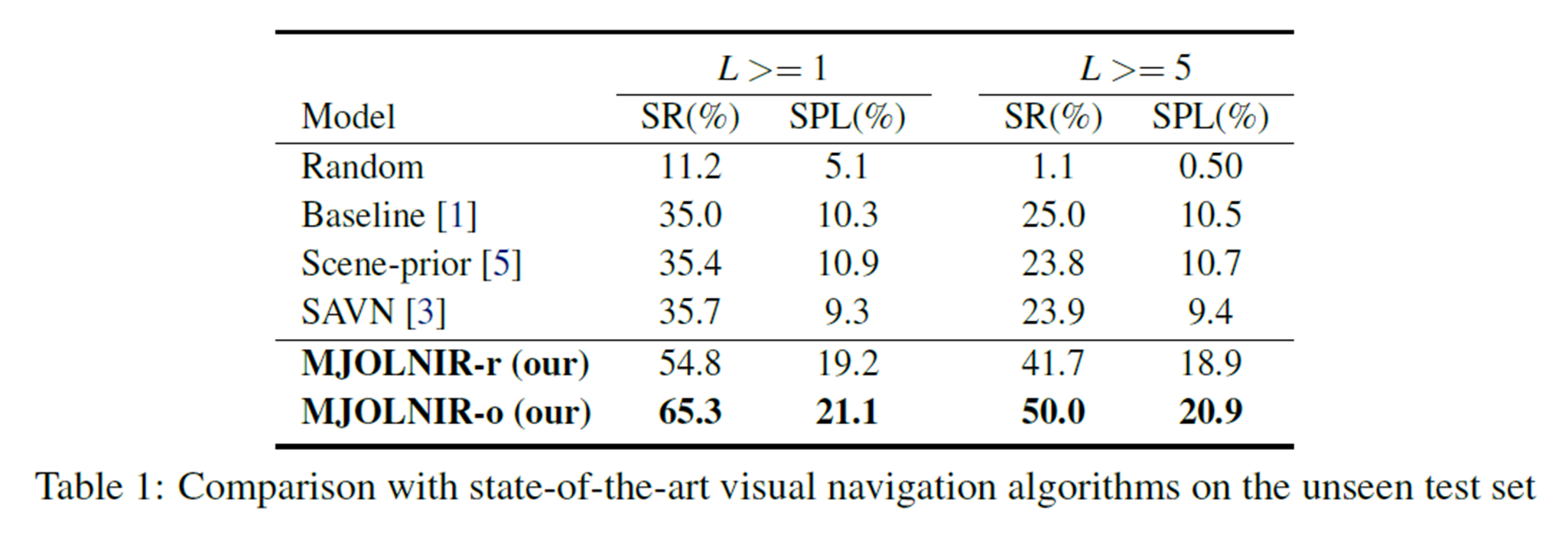
定量的評価
-
context vectorと,CGN Streamの導入の有用性
-
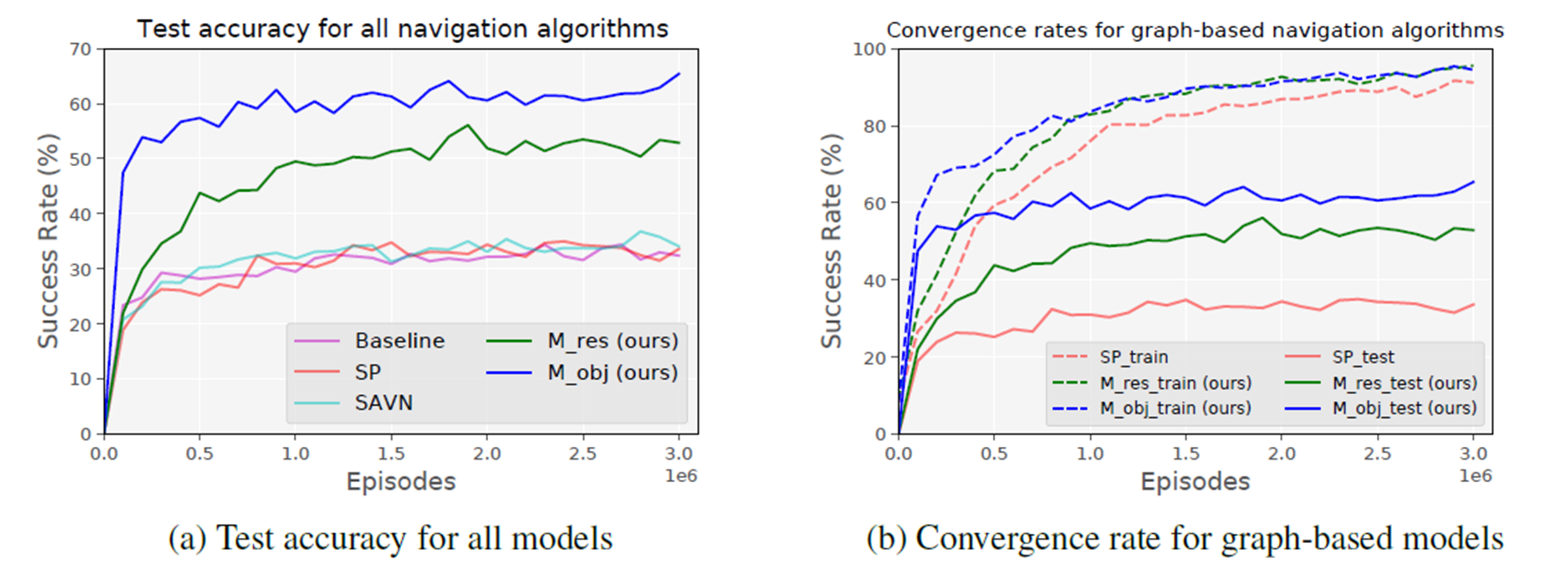
500万episodesまでで,testing SRは急速に増加.
- 他のモデルよりも,はるかに速くターゲットを正しく見つけられるように学習している
-
Scene-priorモデル(既存手法)と比べてOverfittingは改善
reference
[Pennington+, EMNLP14] J. Pennington, R. Socher, and C. D. Manning. GloVe: Global vectors for word representation. In EMNLP, pages 1532–1543, 2014.
[Krishna+, IJCV17] R. Krishna, Y. Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y. Kalantidis, L.-J. Li, D. A. Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. IJCV, 123(1):32–73, 2017.
[Kipf+, 16] T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
[Kolve+, 17] E. Kolve, R. Mottaghi, W. Han, E. VanderBilt, L. Weihs, A. Herrasti, D. Gordon, Y. Zhu, A. Gupta, and A. Farhadi. AI2-THOR: An interactive 3D environment for visual AI. arXiv preprint arXiv:1712.05474, 2017.