さて、前回のPart2では、main.py 内で完結して記載されていたAPIを、
- Frameworks & Drivers 層
- MemoHandler
に分割しました。
この記事では、前回の章で作成した下記のコードをベースとして解説を進めています。
1. 成果物に対して、仕様変更依頼を受ける
さて、今回は、
「『本日のメモ』機能を追加してほしい!!」
という仕様変更依頼を受けたとします。
詳しく仕様を聞いてみると、
-
memo_idが1~31のいづれかでメモを登録されている場合、 -
日付に応じてそのメモを返して欲しい
ex) X月21日に『本日のメモ』機能を利用した場合、
memo_idが21のメモを、『本日のメモ』として返す
とのことでした。
2. 現在の設計のままで仕様変更依頼に対応する際の懸念点
この依頼に対してですが、処理の流れとして、
- 本日の日付を取得する
- 取得した日付を
memo_idとして、DBから値を取得する
という流れが良いかと思います。
以下では、この要件で実装を進めていきましょう。
現状の設計で変更を加える場合のコーディング
今回の要件は、アプリケーションに期待する本来の処理として、日付に応じたメモを取得するエンドポイントを追加してほしいという依頼です。
なので、アプリケーションに期待する本来の処理を記載している memo_handler.py 内に、
- 本日の日付を取得する
- 取得した日付を
memo_idとして、DBから値を取得する
という処理を行う、get_by_day_number メソッド を記載してみましょう。
MemoHandler
memo_handler.py
-
今日の日付を取得します。
+ import datetime class MemoHandler: ... + def get_by_day_number(self) -> str: + # 日付を取得する + dt_now = datetime.datetime.now() + day_number: int = dt_now.day -
day_numberをmemo_idとして既存のgetメソッドを利用するimport datetime class MemoHandler: def get_by_day_number(self) -> str: # 日付を取得する dt_now = datetime.datetime.now() day_number = dt_now.day + try: + result: str = self.get(day_number) + except NotFound: + raise NotFound(f'本日 [{day_number}] 日のメモはまだ登録されていません。') + return f'本日のメモは [{result}] です!'
Frameworks & Drivers 層
frameworks_and_drivers/web/flask_router.py
-
この関数を、フレームワーク内のエンドポイントに追加します。
+ @app.route('/memo/day', methods=['GET']) + def get_by_day_number() -> str: + return jsonify( + { + "message": MemoHandler().get_by_day_number() + } + )
現状の設計で変更を加える場合のコーディングの懸念点
一見これで問題はないように見えます。
しかし、懸念点として
クラス内で、それぞれのメソッドの変更頻度が異なること
が挙げられます。
より具体的にいうと、クラス内で、
1. アプリケーションの仕様が変更になっても、汎用的に扱える、いわば原則的な処理
2. アプリケーションの使用が変更することによって、流動的に変化する処理
が混在しています。
少し聞いただけはわかりませんので、ここで 現状の設計のまま修正した MemoHandler を確認してみましょう。
memo_handler/py
class MemoHandler:
def exist(self, memo_id: int) -> bool:
# DBクライアントを作成する
conn = connector.connect(**config)
cursor = conn.cursor()
# memo_idがあるかどうか確認する
query = "SELECT EXISTS(SELECT * FROM test_table WHERE memo_id = %s)"
cursor.execute(query, [memo_id])
result: tuple = cursor.fetchone()
# DBクライアントをcloseする
cursor.close()
conn.close()
# 検索結果が1件あるかどうかで存在を確認する
if result[0] == 1:
return True
else:
return False
def get(self, memo_id: int) -> str:
# 指定されたidがあるかどうか確認する
is_exist: bool = self.exist(memo_id)
if not is_exist:
raise NotFound(f'memo_id [{memo_id}] is not registered yet.')
# DBクライアントを作成する
conn = connector.connect(**config)
cursor = conn.cursor()
# memo_idで検索を実行する
query = "SELECT * FROM test_table WHERE memo_id = %s"
cursor.execute(query, [memo_id])
result: tuple = cursor.fetchone()
# DBクライアントをcloseする
cursor.close()
conn.close()
return f'memo : [{result[1]}]'
def save(self, memo_id: int, memo: str) -> str:
# 指定されたidがあるかどうか確認する
is_exist: bool = self.exist(memo_id)
if is_exist:
raise Conflict(f'memo_id [{memo_id}] is already registered.')
# DBクライアントを作成する
conn = connector.connect(**config)
cursor = conn.cursor()
# memoを保存する
query = "INSERT INTO test_table (memo_id, memo) VALUES (%s, %s)"
cursor.execute(query, (memo_id, memo))
# DBクライアントをcloseする
cursor.close()
conn.close()
return "saved."
def get_by_day_number(self) -> str:
# 日付を取得する
dt_now = datetime.datetime.now()
day_number: int = dt_now.day
try:
result: str = self.get(day_number)
except NotFound:
raise NotFound(f'本日 [{day_number}] 日のメモはまだ登録されていません。')
return f'本日のメモは [{result}] です!'
これが現在の設計のまま修正した場合のファイルです。
では、
-
アプリケーションの仕様が変更になっても、汎用的に扱える、いわば原則的な処理
-
アプリケーションの使用が変更することによって、流動的に変化する処理
の変更頻度の違いについて説明していきます。
1. アプリケーションの仕様が変更になっても、汎用的に扱える、いわば原則的な処理
結論からいうと、MemoRepository内では、下記のメソッドが、今回のケースでいう アプリケーションの仕様が変更になっても、汎用的に扱える、いわば原則的な処理 です。
- メモを保存する
save - メモを取得する
get - メモの有無を確認する
exists
これらは、原則的な処理であり、仕様変更の影響を受けにくいです。
基本的に、アプリケーションの仕様変更・機能追加があっても、これらの処理は 1 つのパーツとして機能し、処理自体が変更になることはなさそうです。
例えば、今回新しく追加した get_by_day_number メソッドの中で、get メソッドは1つのパーツとして呼び出され、機能しています。
2. アプリケーションの仕様変更によって、流動的に変化する処理
一方で、今回用意した「日付によってメモを取得する」メソッドは、仕様変更によって流動的に修正を必要とするメソッドです。
今後、この機能に対して、下記のような仕様変更依頼を受ける可能性があります。
- 課金ユーザーしか『本日のメモ』機能を使用できないように変更
- 毎月15日は、メモではなく広告を返すように変更
その場合、この関数自体には、下記のような変更が適用されるでしょう。
def get_by_day_number(self) -> str:
...
+ if not 課金ユーザー:
+ raise Exception(`課金ユーザーではないので『本日のメモ』は使えません。`)
+ if day_number == 15 :
+ return ...
...
汎用的で、原則的な、get メソッド等は、これらの仕様変更依頼を受けた際、
その要求を解決するためのパーツとして機能します。
しかし
「日付によってメモを取得する」ための、get_by_day_number は、
仕様変更依頼を忠実に反映するため、
汎用的で、原則的な、get メソッド等に比べて、変更の頻度が高いです。
このように、アプリケーションに本来期待する処理をまとめていたMemoHandlerクラス内にも
- アプリケーションの仕様を満たす、汎用的で原則的な処理
と
- 汎用的で原則的な処理 を活用して、都度アプリケーションの仕様を満たすような、流動的な処理があります。
上記のように、とあるビジネスルールの変更に対して、2 の変更頻度と 1 の変更頻度は異なります。
それにも関わらず、これらを同じ class 内に配置していると、
- 変更の必要のない原則的な処理が記載されたclassを、流動的な処理の変更頻度で更新してしまうため、思わぬ変更を引き起こしてしまいそう
という懸念点が挙げられます。
また、汎用性のあるメソッドと、要求に答えるための限定的なメソッドが同一クラス内にあると、どれが再利用性のあるメソッドか判別しづらいという懸念点もあります。
3. 依頼に対して、どのような設計だったら、スムーズに仕様変更できたかを、CleanArchitecture ベースで考えてみる
i. 設計上の懸念点を再整理
- アプリケーションの要求を満たす、原則的な処理
- 上記を用いて構成された、アプリケーションの要求を満たす、流動的な処理
が同じ層に混在していることにより、
変更の頻度が異なる処理が同一層に存在するため、原則的な処理に対して思わぬ変更を引き起こしてしまいそう
という懸念点があります。
ⅱ. どのような設計になっていれば、懸念点を回避して仕様変更できたか
- アプリケーションの仕様を満たす、汎用的に扱える原則的な処理と
- それらの原則的な処理を用いて、アプリケーションの要求を満たす、流動的な処理
を層に分割できると良さそうです。
ⅲ. 理想の設計を、CleanArchitecture で解釈した場合
これを CleanArchitecture の下記の図で表すと、
それそれ下記のように表せるでしょう。
-
アプリケーションの仕様を満たす、汎用的に扱える原則的な処理 => Enterprise Business Rules
クリーンアーキテクチャ(The Clean Architecture翻訳): https://blog.tai2.net/the_clean_architecture.html
エンティティー: エンティティーは、大規模プロジェクトレベルのビジネスルールをカプセル化する。エンティティは、メソッドを持ったオブジェクトかもしれない、あるいは、データ構造と関数の集合かもしれない。(中略) それらは、もっとも一般的で高レベルなルールをカプセル化する。それらは、外側のなにかが変わっても、変わらなさそうなものだ。たとえば、それらのオブジェクトは、ページナビゲーションの変更やセキュリティからの影響を受けないことが期待できる。アプリケーションの動作への変更が、エンティティーレイヤーに影響を与えるべきではない。
-
原則的な処理を用いて、アプリケーションの要求を満たす、流動的な処理 => Application Business Rules
クリーンアーキテクチャ(The Clean Architecture翻訳): https://blog.tai2.net/the_clean_architecture.html
ユースケース: ユースケースのレイヤーのソフトウェアには、アプリケーション固有のビジネスルールが含まれている。ここには、システムのすべてのユースケースがカプセル化・実装されている。ユースケースは、エンティティに入出力するデータの流れを調整し、ユースケースの目標を達成できるように、エンティティに最重要ビジネスルールを使用するように指示を出す。
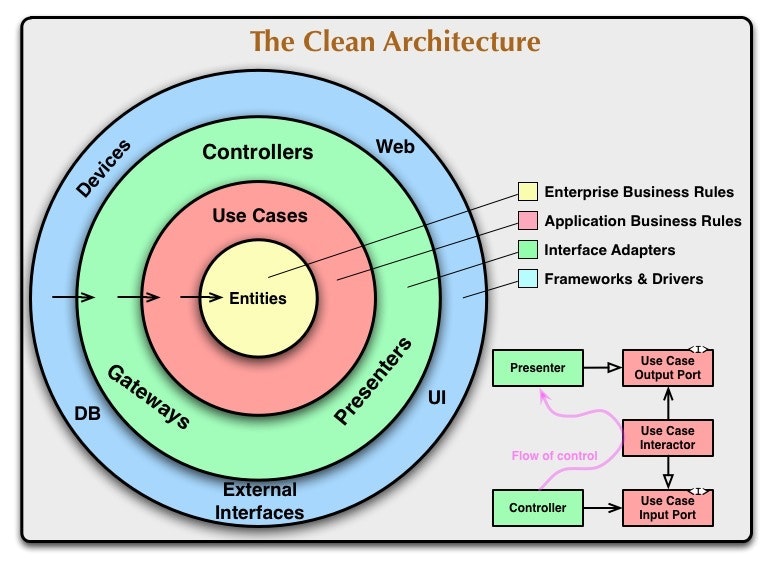
これらのレイヤーごとに、
Memo_Handler を切り出せると良さそうです。
ⅳ. 実際のコーディング
では実際に、MemoHandler を、
- Application Business Rules
- Enterprise Business Rules
に分けていきましょう。
Enterprise Business Rules 層
これまで MemoHandler 内で扱ってきたデータのやりとりに関して、
汎用的に使用する メソッド を memo_repository として切り出します。
enterprise_business_rules/memo_repository.py
from mysql import connector
from werkzeug.exceptions import Conflict, NotFound
config = {
'user': 'root',
'password': 'password',
'host': 'mysql',
'database': 'test_database',
'autocommit': True
}
class MemoRepository:
def exist(self, memo_id: int) -> bool:
...
# 検索結果が1件あるかどうかで存在を確認する
if result[0] == 1:
return True
else:
return False
def get(self, memo_id: int) -> str:
...
return f'memo : [{get_result}]'
def save(self, memo_id: int, memo: str) -> str:
...
return 'saved.'
Application Business Rules 層
次に、下記に、Application の要求を満たす処理を、Enterprise Business Rules 層の処理を組み合わせて記載します。
なお、この際、ファイル名を interactor.py とします。
Interactorについてですが、アプリケーションのビジネスルールをカプセル化したものというニュアンスをイメージすると良いかと思います。
Interactors in Ruby: https://goiabada.blog/interactors-in-ruby-easy-as-cake-simple-as-pie-33f66de2eb78
application_business_rules/memo_handle_interactor.py
from enterprise_business_rules.entity.memo import MemoRepository
class MemoHandleInteractor:
def get(self, memo_id: int) -> str:
return MemoRepository().get(memo_id: int)
def save(self, memo_id: int, memo: str) -> str:
return MemoRepository().save(memo_id: int, memo: str)
def get_by_day_number(self) -> str:
# 日付を取得する
dt_now = datetime.datetime.now()
day_number: int = dt_now.day
try:
result: str = MemoRepository().get(day_number)
except NotFound:
raise NotFound(f'本日 [{day_number}] 日のメモはまだ登録されていません。')
return f'本日のメモは [{result}] です!'
v. DTOの採用
Application Business Rules 層 と Enterprise Business Rules 層 に分けることで起きる問題とは?
さて、ここで、1 点問題が生じます。
現在 MemoHandleInteractor からは、MemoRepository内の関数を呼び出し、戻り値をそのまま返していますね。
enterprise_business_rules/memo_repository.py
class MemoRepository:
def get(self, memo_id: int) -> str:
...
return f'memo : [{get_result}]'
application_business_rules/memo_handle_interactor.py
class MemoHandleInteractor:
def get(self, memo_id: int) -> str:
return MemoRepository().get(memo_id)
この場合、原則的な処理である、MemoRepositoryの get メソッドを、処理の一部として採用しているMemoHandleInteractor の get_by_day_number メソッド側で、
MemoRepositoryの get メソッドの戻り値をそのまま扱うことができなさそうです。
なぜなら、本来は result には、取得した memo の値だけがほしいにも関わらず、
実際には、memo : [{get_result}] が含まれているからです。
class MemoHandleInteractor:
def get_by_day_number(self) -> str:
# 日付を取得する
dt_now = datetime.datetime.now()
day_number: int = dt_now.day
try:
result: str = self.get(day_number)
except NotFound:
raise NotFound(f'本日 [{day_number}] 日のメモはまだ登録されていません。')
return f'本日のメモは [{result}] です!'
# 期待する出力
=> '本日のメモは [りんご] です!'
# 実際の出力
=> '本日のメモは [memo : [りんご]] です!'
このように、現在は、原則的な処理のレスポンスが、汎用的に扱える形式になっていないです。
今後これらの原則的なメソッドを扱い、Application Business Rules 層 の流動的な処理を生成する際、
都度レスポンスの形式の加工に手間を取ってしまいそうです。
問題を整理
MemoRepository を Application Business Rules 層と Enterprise Business Rules 層に分割したとき、
Enterprise Business Rules 層(原則的な処理)内のレスポンスが、汎用的に扱える形式になっていないため、
Application Business Rules(呼び出し元)で、取得した結果を上手く扱うことができない。
どのように解決するか?
上記の課題を解決するために、この application で、汎用的に扱えるデータ構造の class を、DTOとして作成し、
Enterprise Business Rules 層と、Application Business Rules 層 の間でのデータのやりとりに関して、その class を用いると良さそうです。
DTOについて: https://www.deep-rain.com/programming/server-side/267
今回の Application では、memo_id と memo を汎用的に扱うかと思いますので、
レイヤー間で共有であつかうデータを扱う class を、MemoData とします。
実装
from dataclasses import dataclass
@dataclass
class MemoData:
memo_id: int
memo: str
memo_repository 内の get メソッドからは、
MemoObject を返します。
enterprise_business_rules/memo_repository.py
class MemoRepository:
def get(self, memo_id: int) -> MemoData:
...
return MemoData(memo_id=memo_id, memo=result[1])
これによって、get メソッドを呼び出す側は、
MemoObjectを通じて取得した値を活用するというルールに基づき、
get メソッドを汎用的に活用することができます。
では application_business_rules 層で活用してみましょう。
application_business_rules/memo_handle_interactor.py
class MemoHandleInteractor:
def get(self, memo_id: int) -> str:
result: MemoData = MemoRepository().get(memo_id)
return f'memo : [{result.memo}]'
...
最終的なコードは下記です。少し量が多いので、以降は github から確認していただければと思います。
Part3 : https://github.com/y-tomimoto/CleanArchitecture/tree/master/part3
MemoObject をどの層に配置するか?
以降の章でも実感できると思いますが、この MemoObjectは、先程紹介した Enterprise Business Rules層 と Application Business Rules層 間のやりとり以外にも、
様々な層で扱われるデータ構造です。
この汎用的に活用するデータ構造は、どうやらEnterprise Business Rules に記載すると良さそうです。
クリーンアーキテクチャ(The Clean Architecture翻訳): https://blog.tai2.net/the_clean_architecture.html
エンティティー: エンティティーは、大規模プロジェクトレベルのビジネスルールをカプセル化する。エンティティは、メソッドを持ったオブジェクトかもしれない、あるいは、データ構造と関数の集合かもしれない。(中略) それらは、もっとも一般的で高レベルなルールをカプセル化する。それらは、外側のなにかが変わっても、変わらなさそうなものだ。たとえば、それらのオブジェクトは、ページナビゲーションの変更やセキュリティからの影響を受けないことが期待できる。アプリケーションの動作への変更が、エンティティーレイヤーに影響を与えるべきではない。
ちなみに、 この MemoObject は、 DDD でいう Entity の役割も果たします。
Entity と DTO の違い: https://qiita.com/mtanabe/items/c879d233d297eda288d4
DDD と CleanArchitecture における、entity の違い : https://nrslib.com/clean-ddd-entity/
CleanArchitecture では Enterprise Business Rules層 の具体的な実装パターンについては明記していないのですが、
DDD におけるドメイン層の役割を等しいため、この記事では、DDD のドメイン層の実装パターンを、 Enterprise Business Rules層 で実践していこうと思います。
4. 設計の変化によって、どのような仕様変更に耐えうるようになったか?
最終的なコードはこちらです。: https://github.com/y-tomimoto/CleanArchitecture/blob/master/part3
この章では、アプリケーションに本来期待する処理が記載された memo_handler.pyを
- Enterprise Business Rules
- Application Business Rules
に分割しました。
これにより、memo_handler.py を、
- アプリケーションにおける原則的な処理と、
- それらを活用してアプリケーションの仕様を満たす流動的な処理
に分割することで、アプリケーションの仕様変更の際、既存の原則的な処理に影響を与えず、仕様を柔軟に修正・拡張できる設計としました。