【gloops Advent Calendar 2016】17日目の記事になります。
はじめに
最近、機械学習(ロジスティック回帰やニューラルネットワーク)の勉強をしているんですが、機械学習では仮説関数やコスト関数(目的関数/損失関数)の計算を並列に計算すると効率が良いです。
関数を行列計算で表せることも多いので、3Dグラフィック処理(行列処理/並列処理)が得意なGPUが大きな効果を発揮します。
そこで、gloopsにとって中心的な言語であるC#でGPUプログラミングをやってみたくなり調べたところ、Alea GPUというライブラリがあったので試してみました。
この記事の元はこれなので、英語ですが詳しく正確に知りたい方をそちらを参照しましょう。
Alea GPUとは
Alea GPUはGPUの並列処理能力を活用したプログラミングができ、シンプルかつ効率的なライブラリです。Alea GPUランタイムはGPU上での実行とすべてのメモリ管理を効率的に処理してくれます。
GPUでの並列処理
GPUを利用した並列処理を行うのは簡単で、Gpu.Default.Forとして中身に処理を書くだけ。
var n = ...
Gpu.Default.For(0, n, i =>
{
...
});
注意しないといけないのは、ループ本体の処理は並列処理されるため、変数はお互いに独立していないといけません。
メモリ管理
GPUは独自のオンボードメモリを持っています。このメモリはGPUとCPU間のデータ入出力に利用され、両方からアクセスして変更することができます。
CPUとGPUのメモリは物理的に区別されているので、通常はプログラムによってGPUとCPUのメモリにコピーしなければならないんですが、Alea GPUでは自動で管理することができます。
自動でGPUメモリ管理をするためには[GpuManaged]アトリビュートをつける必要があります。
namespace Samples.CSharp
{
class ParallelForAutoMemMgtTest
{
[Test]
public static void Unmanaged()
{
.....
}
[GpuManaged, Test]
public static void Managed()
{
.....
}
}
}
[GpuManaged]をつけたManaged処理と、つけないUnmanaged処理では効率が違うので性能に大きく差がでます。
CUDAプログラミングモデル
Alea GPUではCUDAというNVIDIAが提供するGPU向けの開発環境を利用しているので、NVIDIA製のGPUでしか動作しません。
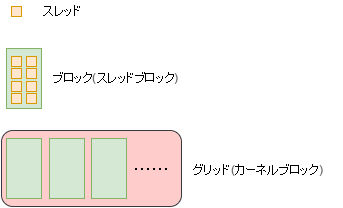
スレッド、ブロック、グリッド、カーネル
スレッドはプログラム実行の最小単位です。CPUでは1CPU(スレッド)につき1スレッドですが、GPUでは1つのコアにいくつものスレッドを実行して並列性を高めます。
スレッドをグループ化したものをブロックといいます。
さらにブロックをグループ化したものをグリッドといいます。
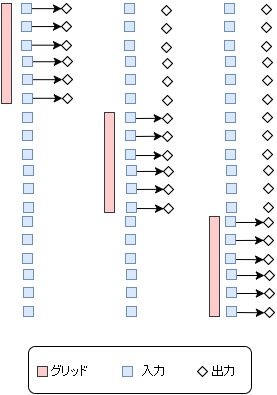
CUDAプログラミングモデルを利用してGPU上で並列変換を実装します。
以下の図は、スレッドブロックのグリッドが配列の要素をどのように処理するかの概略図です。
実際のカーネルはstaticメソッドとして記述します。以下の例では2つの要素を足すだけの処理です。
stride変数で1度にまとめて処理する数を設定して繰り返していきます。
private static void Kernel(int[] result, int[] arg1, int[] arg2)
{
var start = blockIdx.x*blockDim.x + threadIdx.x;
var stride = gridDim.x*blockDim.x;
for (var i = start; i < result.Length; i += stride)
{
result[i] = arg1[i] + arg2[i];
}
}
ジェネリクスやデリゲート、ラムダ式
ジェネリクスでカーネル関数を定義したり、ラムダ式でカーネルを記述することもできます。
private static double op(double v1, double v2)
{
...
}
Gpu.Default.For(0, result.Length, i => result[i] = op(arg1[i], arg2[i]););
////
gpu.Launch(TransformGeneric.Kernel, lp, result, arg1, arg2, (x, y) => x + y);
テストコード
テスト用のコードとして行列計算プログラムを実行しました1。
https://gist.github.com/ymiyoshi/6aa7af62d07051016db70792c4ee7fcc
テストでは (180 x 60000)の行列A と(60000 x 270)の行列Bを計算しています。
以下の3パターン実装しています。
A. シングルスレッドでシーケンシャルに処理
B. マルチスレッドでパラレルに処理
C. GPUでパラレルに処理
並列処理の差が出やすいように60000を並列処理しています。
Gpu.Default.For(0, matARows, i =>
{
for (int j = 0; j < matBCols; j++)
{
double temp = 0;
for (int k = 0; k < matACols; k++)
{
temp += matA[i, k] * matB[k, j];
}
result[i, j] = temp;
}
}); // Parallel.For
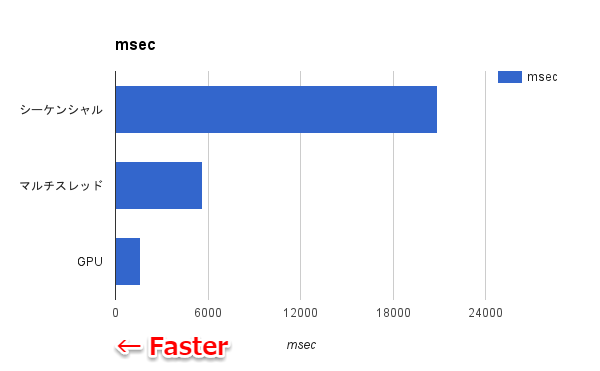
Executing sequential loop...
Sequential loop time in milliseconds: 20858
Executing parallel loop...
Parallel loop time in milliseconds: 5675
Executing GPU parallel loop...
Gpu Parallel loop time in milliseconds: 1642
Press any key to exit.
実行環境
CPU: Corei5-6500
GPU: GTX 1050
※行列のパターンによってはAのシーケンシャルが一番速かったり、Bのマルチスレッドが速かったりします。むしろGPUで性能が出るのは特殊な計算環境です。グラフィックボードへメモリを転送するオーバーヘッド以上にGPUでの並列処理による時間短縮が勝らないと効果は見られません。
デバッグ
GPUカーネル関数のデバッグはVisual Studioのデバッガではデバッグできません。
NVIDIA Nsight Visual Studio Editionを利用することでデバッグできます。
CUDA WarpWatchウィンドウを利用し、Name行に変数名(temp/i/j)を入れることで値を見ることができます。
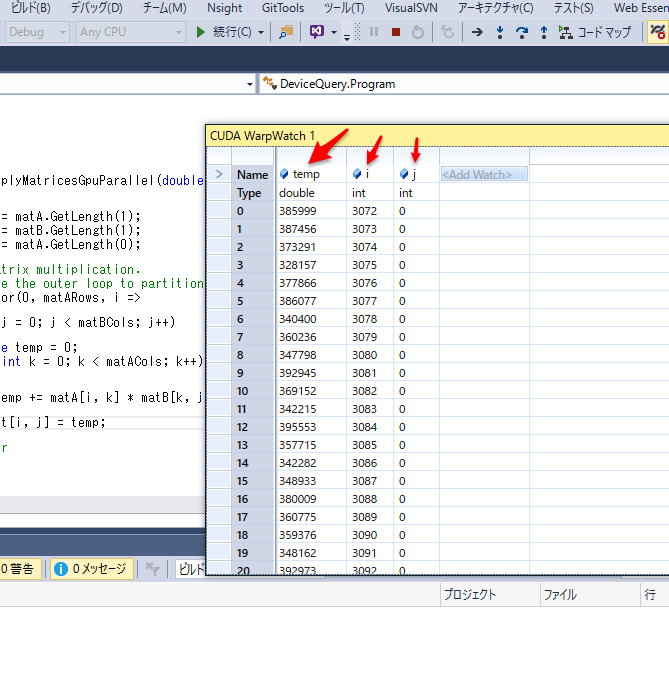
通常のデバッガに比べると大変使いづらいですが、並列処理の値がみれるだけでも良しとします。
今回はここまで
Alea GPUの紹介は以上にします。まだまだ触り始めたばかりなので使いこなすには程遠いですが、敷居が高そうなGPUプログラミングをAlea GPUを利用することで簡単に始められることは分かったんじゃないかと思います。
明日の【gloops Advent Calendar 2016】は@ys_yamadaさんです!ワクワク!
参照URL
Alea GPU C# Programing Overview
第6回 「CUDAプログラミングモデル①」
Extreme Optimization