この記事は リクルートライフスタイル Advent Calendar 2017 の12日目の記事です。
1.はじめに
ホットペッパービューティーで基盤や運用の改善を行っているy_kabutoyaです。
本記事はRecruit Engineers Advent Calendar 2017に投稿したシステムリリースの話の中から、Jenkinsの利用についてもう少し掘り下げた内容を書きたいと思います。
2.リリース作業で実施したいこと
「リリース作業」と一言で言ってもアプリケーションをビルドし、実行する対象環境にリリースし、実行(可能)状態にする必要があります。
ビルド対象が1つ(例えばWebアプリケーションのみ)であればリリース作業は非常にシンプルで自動化の難易度も低いです。

しかし、一般的なWeb/ApシステムであってもDBに代表されるデータストア層との接続が必須だと思います。そうなると、テーブル定義やマスタデータ投入といったリリースに対する依存関係が増えていきます1。
そこにKVSや検索エンジンなども必要になってくるとリリース作業の自動化の難易度が上がっていきます。
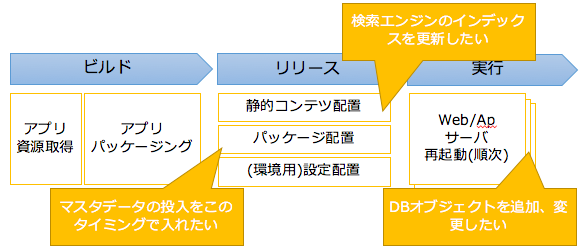
上記のように依存関係のあるビルド対象が増加しても柔軟にリリース作業を実施可能とするためにJenkins 2.0を利用しています。
想定している要件は以下の様なものです。
3.Jenkins Pileline
上記を実現するために、Jenkins Pileline(Scripted Pipeline)を利用してリリース作業のジョブ化(コード化)しリポジトリ管理しています。
なお、リリース作業自体を独立した機能と位置付けているためJenkinsfile自体の構成はデフォルトと異なる指定にしています。(Jobの定義画面のScript Pathにてファイルを変更)
構成は以下としています。
<repository root>
├── tools #- リリース用各種ツールを配置
└── buildpipeline #- JenkinsPipelineのルート
├── assembly #- 依存関係を含むリリース作業の一気通貫ジョブを配置
├── component #- リリース作業の個別のジョブを配置
├── script #- 各ジョブの実態(実処理)スクリプトを配置
└── vars #- 環境固有情報(設定値)を配置
実態(実処理)スクリプト
今回の構成では変更発生頻度が高いジョブ(=assemblyとcomponent)をインターフェースとして扱い、処理の実態は共通化した上でscript配下に配置しています。
また、script配下に配置した処理の関数には和名を使うこととしています。
これは利用する側(=assemblyとcomponent)での処理の追加、変更等を行う際に直感的に操作できるようにするためです。
def DBリリース(ticket, dbVersion, schema, opt="") {
// 実行時の環境変数定義
withEnv(["LANG=XXX","PATH+MAVEN=${ENV.m2Home}/bin"]) {
workdir = pwd()
// 別のリリース用ツール呼び出し
sh "${workdir}/tools/dbrelase.py ${schema} ${ticket} ${cmd} ${opt}"
}
}
def init(targetEnv) {
// script配下の定数や他処理を呼び出し、1つのオブジェクトに集約するための処理
ENV = ....
CONST = ....
}
// 外部のジョブから呼び出すためにthisをリターン
return this
定義した実態スクリプトは利用する側で以下のように定義しています。
# !/usr/bin/env groovy
node ('master') {
workdir = pwd()
task = load "${workdir}@script/buildpipeline/script/entrypoint.groovy"
task.init(TARGET_ENV)
}
一気通貫ジョブ
依存関係を含むリリース作業を一斉に実施するジョブのスクリプトをassemblyに配置しています。
上記、実態スクリプトを実行すべきノードで実施するように実装しています。
# !/usr/bin/env groovy
node (task.ENV.web) {
stage('Webデプロイ') {
task.静的コンテンツ配置(TARGET_VERSION)
task.Webアプリデプロイ(TARGET_VERSION)
}
stage('DBオブジェクトデプロイ') {
task.DBリリース(TICKET_NO, TARGET_VERSION, SHEMA_NAME)
}
}
前述のように処理内容はリリースタイミングによって変わる想定です。そのため、本スクリプトは極力シンプルにする(可読性を上げる)ことに注力しています。
また変更については、リポジトリ管理(ブランチ管理)することで柔軟なリリースの自動化、可視化を行っています。
個別のジョブ
assembly配下と同様に実態スクリプトをloadしジョブを定義したスクリプトをcomponentに配置しています。
個別のジョブはassemblyが途中で失敗した場合のリカバリの意味合いと、テストの意味合いの2つのために実態スクリプトを最小単位のリリース単位でスクリプト化し、配置しています。
環境固有情報
リリース作業の対象は本番環境だけではなく、開発環境やステージング環境も存在します。そして環境毎に異なる値が存在します。
このような環境毎に異なる情報はvars配下にjson形式の設定値として格納しています。
Build Agent情報
環境毎に異なる情報で最も大きいものは接続先となるBuildAgent情報です。
本記事ではリリース作業を各環境にログインして行うための手段としてビルドエージェントの利用を想定しています。
(「ビルド」の負荷分散のための利用ではなく、「ジョブ」を実行する先として利用するイメージ)
BuildAgentはAgentの名前に一位制約があるため、環境固有情報として抽象化して利用しています。

{
"production" : {
"web" : "web_production",
"db" : "db_production",
"..." : "その他設定"
},
"staging" : {
"web" : "web_staging",
"db" : "db_staging",
"..." : "その他設定"
},
"develop" : {
"web" : "web_develop",
"db" : "db_develop",
"..." : "その他設定"
}
}
実行する環境はビルドパラメータとして定義しておき、実行時に指定する形式としています。
(Jenkins Pipeline側は前述のtask.init(TARGET_ENV)にて環境情報を取り出しています。)
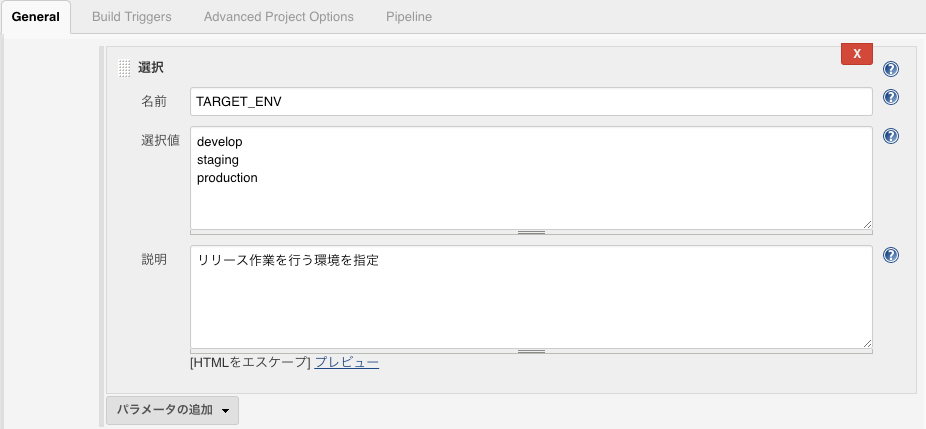
クレデンシャル情報
ID/PWDと言ったクレデンシャル情報も環境固有情報の一部として扱うことが出来ますが、気密性の高い情報であるため、コード化は行わずJenkinsの認証情報として管理しています。
またJenkinsのアクセス制御で特定メンバーしかアクセスしないようにしています。
定義したクレデンシャル情報はwithCredentials を利用してスクリプト側でアクセスしています。
withCredentials([string(credentialsId: 'my-acconut', variable:
'token')]) {
// クレデンシャル情報を必要とするリリース関連処理
}
4.その他の連携
本記事でのJenkins用途はアプリのビルド以外も含まれるため、Jenkins Pipelineだけでリリース作業の自動化は完結しません。
以下のようなJenkins Pipeline以外のものとの連携を行っています。
(Jenkinsでは外部コマンドの実行や各種プラグインが豊富にあるので簡単に実現できます。)
リリース用各種ツール
「3.Jenkins Pileline」で紹介した構成のtools配下にPythonを利用した各種ツールを集約しています。
コンセプトとしては「リポジトリをclone/pullしたらそのまま使える。」としています。
リリース作業に関連するツールは極力利用すると冒頭で書きつつシェルからPythonへの置き換えを勧めています。
理由としては2つ「YAMLを利用た環境固有情報の管理がし易い」点と「コード自体の可読性が上がる」です。
環境依存情報を以下のようにYAML定義し
production:
mailaddr: mailinglist@sample.come
user: produser
...
staging:
...
呼び出し側で(Jenkinsから引き継いだ)対象環境を指定することで設定値を取得しています。
with io.open(file_path) as rf:
env = yaml.load(rf)
return env[target_env]
なお、Jenkins側でも環境固有情報を持っていますが、Jenkins側は「接続先(≒BuildAgent)情報」に特化しツール側では「接続先内部の固有情報(環境変数に近い値)」を保持することとして住み分けています。
Slack
リリース作業について作業者だけでなく開発関係者全員が把握できるようにするためにSlackを多用しています。
INFO,WARN,ERRORを定義しておき、開始と終了だけでなくペンディング(ユーザのインプット待ち)状態も実態スクリプト側に実装しています。
task.通知("XXXを開始します。") // 通常の情報
task.通知("XXXを確認して下さい。", MY_MENTION, WARN) // 警告の情報
task.通知("XXXエラーが発生しました。", ALL_MENTION, ERROR) // エラー情報

Ansible
こちらにも記載したとおりM/WのリリースにはAnsibleを利用しています。
(Jenkinsサーバと同居する形で利用しています。)
基本的にJenkins経由でAnsibleをplayしていますが、「アプリレイヤはJenkins+各種ツール」で「インフラレイヤはAnsible」で自動化を勧めています。

ただ、JenkinsもAnsibleも接続先情報を保つ必要があり、一部重複した情報をそれぞれが持つ形になってしまっているので、接続先情報を共通管理について別途課題と感じています。
最後に
Jenkins Pilelineを利用することで、リリース作業に柔軟性を残しつつ自動化することがある程度できてきています。
ただ、以下項目について「コード化」が実現できておらず、さらなる改善の対象として対応していきたいと考えています。
(なにか良い方法をご存じの方がいればご指摘いただけるとうれしいです。)
- ビルドパラメータのコード化
コードに柔軟性をもたせつつも、人が行う操作(例えばリリース環境の指定)はパラメータ定義を行っています。
複数個のジョブを作成する際にパラメータ自体は似た構成になる場合が多いのでパラメータ自体もコード化していきたいと考えています。 - Jenkinsノードのコード化
本記事のような利用方法の場合、Build Agent数は多くなりがちです。
Build Agentの定義自体は一度しか行わないもののジョブの実行内容自体が1箇所に集約されていないこと全体の見通しが悪くなります。
その為、ノードの管理もコード化していきたいと考えています。
(締めがお願いな感じになってしまいましたが、)最後までお読みいただいた皆さん、ありがとうございました!
参考記事
http://arasio.hatenablog.com/entry/2016/10/08/220843
https://qiita.com/miyasakura_/items/9d9a8873c333cb9e9f43