重回帰分析によって一体どういうことが分かるのかということを、もっと具体的に見ておきたいと思います。
そこで、身近な統計データからサンプルデータを作って、それで重回帰分析をやって解釈を試みます。今回サンプルデータを作成するにあたって、次の2つのデータソースを利用しました。
➀政府統計ポータルサイト「政府統計の総合窓口e-Stat」都道府県データ
https://www.e-stat.go.jp/regional-statistics/ssdsview/prefectures
➁厚生労働省「新型コロナウイルス感染症」各都道府県の検査陽性者の状況
https://www.mhlw.go.jp/content/10906000/000646813.pdf
まず目的変数を、新型コロナウイルス感染者率とします。これを左右しているかも知れない説明変数には、いわゆる「3つの密」および感染拡大につながると考えられる「人々のアクティビティ」に関する指標として次の7つの変数を用意しました。
| 指標名 | 指標計算式 | 調査年 |
|---|---|---|
| 人口集中地区人口比率(%) | 人口集中地区人口(人) / 総人口(人) | 2015年度 |
| 昼夜間人口比率(%) | 昼間人口 / 夜間人口 | 2015年度 |
| 就業者比率(%) | 就業者数(人) / 総人口(人) | 2015年度 |
| 飲食店・宿泊業就業者比率(%) | 就業者数(飲食店・宿泊業)(人) / 就業者数(人) | 2005年度 |
| 旅行行動者率(%) | 旅行行動者率 10歳以上(%) | 2016年度 |
| 外国人宿泊者比率(%) | 外国人延べ宿泊者数(人) / 延べ宿泊者数(人) | 2018年度 |
| 単独世帯比率(%) | 単独世帯数(世帯) / 世帯数(世帯) | 2018年度 |
| 人口10万人当たり感染者率(%) | 感染者数 陽性日(人) / 総人口(人) | 2020年7月5日現在 |
⑴ ライブラリをインポートする
import numpy as np # 数値計算
import pandas as pd # データフレーム操作
from sklearn import linear_model # 機械学習の線形モデル
⑵ サンプルデータを読み込む
# URLを指定して、csvファイルを読み込み
url = 'https://raw.githubusercontent.com/yumi-ito/sample_data/master/covid19_factors_prefecture.csv'
df = pd.read_csv(url)
# データの冒頭5行を表示して中身を確認
df.head()
サンプルデータ(covid19_factors_prefecture.csv)をGitHubに置いてあるので、そこから読み込んでいます。
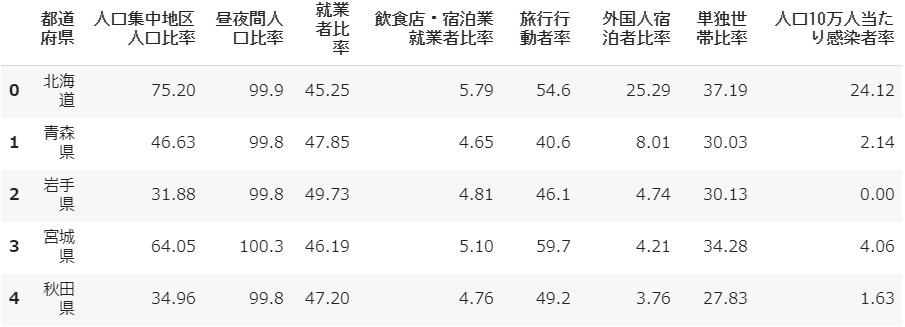
「人口集中地区人口比率」とありますが、この人口集中地区(DID:Densely Inhabited Districtの略)とは統計データに基づいて一定の基準により都市的地域を定めたものです。では都市的地域とは何なのかというと、特に人口密度の高い地域のことで、広い意味での市街地を指します。ざっくりいうと、ある県の人口が市街地にどの程度集中しているか。たとえば北海道、単に人口密度としてしまうと面積が広いだけにばらけてしまいますが、人口集中地区人口比率は75.2%で4人に3人が市街地に住んでおり、粗密が著しいことがわかります。
⑶ データを概観する
# 各列の要約統計量を取得
df.describe()
pandasのdescribe関数を使います。
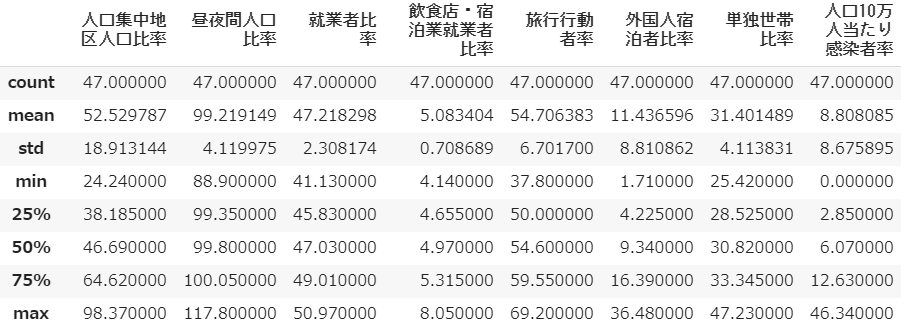
「人口10万人当たり感染者率」ですが、いうまでもなく最大値は東京都の46.34%、最小値は岩手県の0.00%です。
せっかくなので各変数のトップ5を見ておきたいと思います。

東京都が概してトップというのは当然ですが、感染者率で石川県・富山県という北陸2県がランクインしているのが気になります。感染者数としてみると目立たない両県ですが、県人口に対する感染者の比率となると高い。ちなみに実数は石川県300人、富山県228人となっています。
また石川県は、県内の全就業者に占める飲食店・宿泊業従事者の割合が、長野県と同率5.8%で全国5番目となっています。この変数を採用した意図は、やや拡大解釈ぎみなのですが、宿泊やそれに伴う飲食といった観光関連の経済活動が活発で、それだけに人的接触の機会が多いという考え方です。沖縄県の突出ぶりはその意味でうなずけます。
なお、北海道についてはその感染者数の多さと相俟って、マスコミなどで盛んに観光面の打撃が報じられていましたが、確かに一年間の延べ宿泊者数全体に占める外国人比率は25.3%で京都府に次ぐ第4位となっています。
では、重回帰分析をやっていきます。
⑷ 説明変数・目的変数をそれぞれ格納する
# 説明変数のみ抽出して変数Xに格納
X = df.loc[:, '人口集中地区人口比率':'単独世帯比率']
# 目的変数のみ抽出して変数Yに格納
Y = df["人口10万人当たり感染者率"]
⑸ モデルを生成する
# 線形モデルのインスタンスを生成
model = linear_model.LinearRegression()
# データを渡してモデルを生成
model.fit(X,Y)
⑹ 偏回帰係数を取得する
# 係数の値を取得し、変数coefficientに格納
coefficient = model.coef_
# カラム名とインデックス名を付与してデータフレームに変換
df_coefficient = pd.DataFrame(coefficient, columns=["偏回帰係数"], index=[X.columns])
df_coefficient
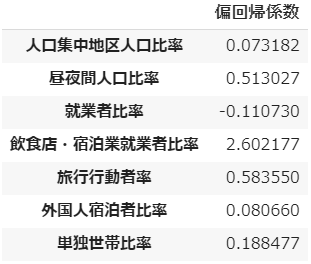
偏回帰係数は、説明変数それぞれが目的変数に与える影響の大きさを表します。
まず、「飲食店・宿泊業就業者比率」がずば抜けて大きく、次いで「旅行行動者率」と「昼夜間人口比率」が大きいですね。
宿泊を伴うとすれば、おおかた観光かビジネスのいずれかでしょう。つまり県外から入って来て一定期間滞留する人が多く、そのため飲食店や宿泊業に従事する人の割合も多いということが、感染者率に大いに影響しているといえそうです。
さらに、旅行や通勤通学のために県の内外を出入りする人が多いと感染者もまた増えるということで、要するに「移動の制限」が感染防止に有効であるということでしょう。
⑺ 切片を取得する
# 切片を取得
model.intercept_
切片(Y軸との交点)はintercept_関数で求められ、これで重回帰式が明らかになりました。
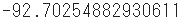
⑻ モデルの精度を確認する
# 決定係数を取得
model.score(X, Y)
最後に、重回帰式の“当てはまりの良さ”を確認するためにscore関数で決定係数$R^2$を算出します。
すなわち、この重回帰式が、実際の因果関係をどの程度説明できているか。
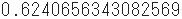
正直なところ 0.8 を超えていて欲しかったなぁと思いつつ・・・、説明変数の構成について(手っ取り早く作っただけに)検討が必要ということなのでしょう。