- 決定木(けってい-ぎ)はデシジョン・ツリー(Decision Tree)の名でも知られています。
- ある目的に到達するために、データの各属性(説明変数)を条件として、分岐をくり返してクラス分けをする方法です。そのプロセスが全体として樹形図に示されることにちなんで、意思決定(decision)のための木(tree)という名がついています。
- クラス分けのターゲットとなる目的変数が、カテゴリデータの場合を分類木(classification tree)、数値データの場合を回帰木(regression tree)といいます。
ここでは、まず分類木の例を一通りやってみます。
⑴ ライブラリのインポート
# 決定木モデルを構築するクラス
from sklearn.tree import DecisionTreeClassifier
# 決定木モデルをベースとするモジュール
from sklearn import tree
# 機械学習用データセットのパッケージ
from sklearn import datasets
# データを分割するためのユーティリティ
from sklearn.model_selection import train_test_split
# Notebook内に画像を表示させるモジュール
from IPython.display import Image
# 決定木モデルを可視化するためのモジュール
import pydotplus
⑵ データの取得と読み込み
iris = datasets.load_iris()
- あまりに有名なデータセットで今更のようですが、3種類の花菖蒲(アイリス)の「花びら」と「がく」の長さ・幅をそれぞれ計測した4つの特徴量が格納されたデータセットです。
- 3種類は、セトーサ(Setosa)、ヴァーシカーラ(Versicolour)、ヴァジーニカ(Virginica)というカテゴリデータで、種類ごとに50サンプルずつ、計150サンプルとなっています。
- scikit-learn公式の解説はこちら、https://scikit-learn.org/stable/auto_examples/datasets/plot_iris_dataset.html
| 変数名 | 意味 | 注記 | データ型 | |
|---|---|---|---|---|
| 1 | sepal length | がく片の長さ | 連続量(cm) | float64 |
| 2 | sepal width | がく片の幅 | 連続量(cm) | float64 |
| 3 | petal length | 花びらの長さ | 連連続量(cm) | float64 |
| 4 | petal width | 花びらの幅 | 連続量(cm) | float64 |
| 5 | species | 種別 | Setosa=1, Versicolour=2, Virginica=3 | int64 |
- irisデータセットの内容は、説明変数(特徴量)のラベルとデータ、目的変数(種別)のラベルとデータ、さらにデータの概要という5つの部分から構成されています。
- 念の為、データがどのように入っているかを確認しておきます。
# 説明変数のラベル
print(iris.feature_names)
# 説明変数の形状
print(iris.data.shape)
# 説明変数の先頭5行を表示
iris.data[0:5, :]
- 4つの計測値を説明変数として、全部で150サンプルとなっています。

- 次いで目的変数は、3種類が[0, 1, 2]というカテゴリ変数として格納されています。
# 目的変数のラベル
print(iris.target_names)
# 目的変数の形状
print(iris.target.shape)
# 目的変数を表示
iris.target

⑶ データの前処理
# 説明変数・目的変数をそれぞれ格納
X = iris.data
y = iris.target
# 訓練用・テスト用にそれぞれ分割
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
- 特に配分比を指定しなければ、デフォルトで訓練用75%、テスト用25%の比率でランダムに分割されます。
- 引数に
random_state=0を指定することで、分割を何度くり返しても最初に分割した状態が再現されます。
⑷ 決定木のモデル構築と評価
# 決定木モデルを構築するクラスを初期化
clf = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=0)
# 決定木モデルを生成
model = clf.fit(X_train, y_train)
# 訓練・テストそれぞれの正解率を算出
print('正解率(train):{:.3f}'.format(model.score(X_train, y_train)))
print('正解率(test):{:.3f}'.format(model.score(X_test, y_test)))

- 決定木が生成される過程でその基準となるのは、カテゴリ識別の不純度という指標です。どれだけ不純物が混じっているか、それが 0.0 であれば純粋に分類できていることになります。
- 引数に
criterion='gini'とあるのがそれで、ここでは明示的に**ジニ不純度(Gini impurity)**を指定しています。(デフォルトがジニ不純度なので特に記述の必要はありません) - また、条件分岐の階層の深さは、この例では
max_depth=3として多くとも3階層までと指定しています。階層数を増やして「深い木」にすると、正解率は高くなりますが、過学習のリスクも増すことになり得ます。 - 生成されたモデルに対し、
score()関数で訓練・テストそれぞれの正解率を算出します。訓練データでは 0.982 と非常に高く、テストデータでは若干それを下回りますが、いずれも 1.0 に近く高い水準となっています。
⑸ 樹形図(tree diagram)の描画
- ダイアグラムの描画は、次の3ステップです。
- 決定木モデルをDOTデータに変換
- DOTデータからダイアグラムを描画
pngに変換してNotebook内に表示
# 決定木モデルをDOTデータに変換
dot_data = tree.export_graphviz(model, # 決定木モデルを指定
out_file = None, # 出力ファイルではなく文字列を返すように指定
feature_names = iris.feature_names, # 特徴量の表示名を指定
class_names = iris.target_names, # クラス分類の表示名を指定
filled = True) # 多数派クラスでノードを色付け
# ダイアグラムを描画
graph = pydotplus.graph_from_dot_data(dot_data)
# ダイアグラムを表示
Image(graph.create_png())
- DOTデータとは、DOT言語で記述されたデータのことです。DOT言語は、グラフ構造(ノードとエッジから成るネットワーク構造)を記述するための言語です。ノードは結節部(□)、エッジは連結線(↓)を意味します。
- そのようなグラフ構造を描画するためのツールがGraphvizです。sklearnのtreeモジュールに属する
export_graphviz()関数が、決定木モデルをDOT形式に変換してくれます。その際に引数として、描画の仕様や表示名などの細かな指定をしています。 - 次いで、PythonでDOT言語を扱うためのモジュールpydotplusの
graph_from_dot_data()関数をつかってグラフを描画します。 - さらに、Notebook内にグラフを表示させるために、グラフを
pngに変換してIPython.displayモジュールのImage()メソッドを実行しています。
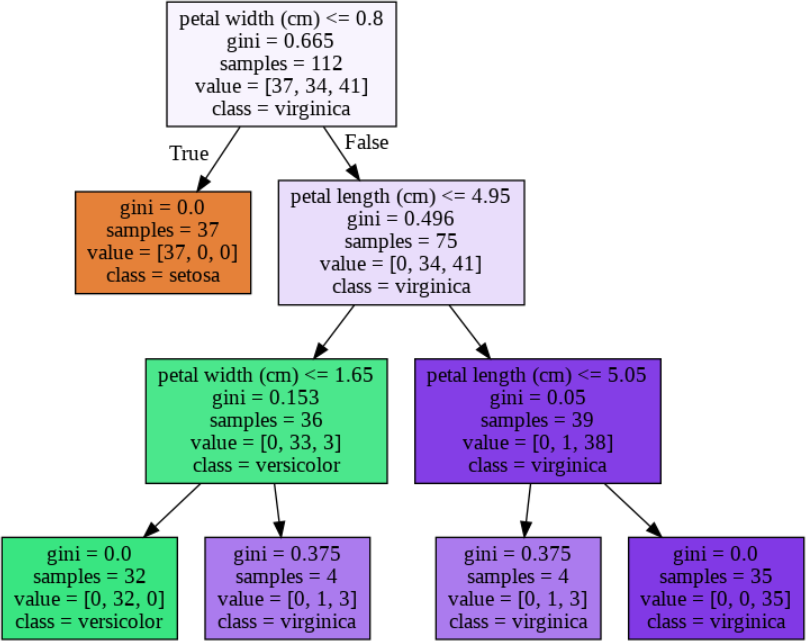
樹形図(tree diagram)の見方
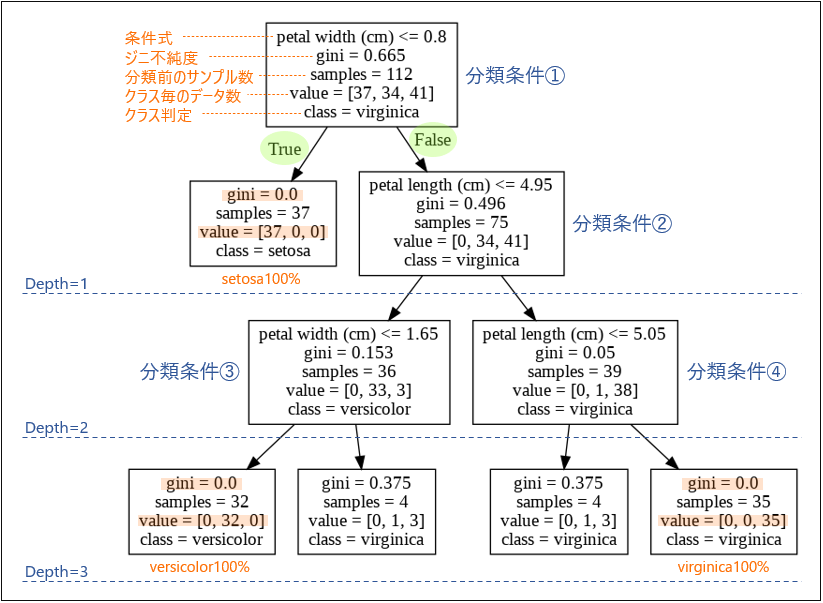
- 決定木は、上から見ていきます。まず第一に有効とされた分類条件➀、ここからスタートします。
- 条件式の
petal width (cm) <= 0.8は「花びらの幅が0.8以下」を意味し、あてはまるならTrue、それ以外はFalseの矢印を進みます。 -
Trueの矢印を下りてきたノードは、ジニ不純度が 0.0 を示し、37サンプル全てがsetosa種ということで純粋に分類できています。これが一つ目のゴールです。 - かたや
False側のノードは、新たな分類条件➁によって、さらにTrueかFalseに分岐します。このようにジニ不純度が 0.0 となるゴールを目指して、分岐しながら階層を下りていくことになります。
補記
- 以上、google colaboratory上に実装していますので、樹形図をローカルPCに取り込むには次のように行います。
# pngファイルに書き出す
graph.write_png("iris.png")
# google colaboratoryからダウンロード
from google.colab import files
files.download('iris.png')
