- 決定木のもう一つの側面、目的変数を数値データとする回帰木を行ないます。
- 目的変数がカテゴリデータの分類木は、scikit-learn.treeモジュールのDecisionTreeClassifierを使いますが、回帰木モデルにはDecisionTreeRegressorを使います。
⑴ ライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor # 回帰木モデルを作成するクラス
⑵ データの取得と読み込み
from sklearn.datasets import load_boston
boston_dataset = load_boston()
- データは、scikit-learnに付属の「Boston house prices dataset」を使います。
- アメリカ北東部の大都市ボストンの住宅事情に関する特徴量が13個、サンプル数は506個です。
- このデータセットの狙いは、与えられた特徴量を使って住宅価格を予測することです。
- 変数名 MEDV(Median valueの略) という住宅の価格がターゲットであり、13個の特徴量は住宅の価格を予測するための説明変数です。
- 説明変数の内容などの詳細はこちら https://qiita.com/y_itoh/items/aaa2056aac0c270ba7d2
住宅を特徴づける13の説明変数を使って、住宅の価格を予測する回帰木モデルを構築します。
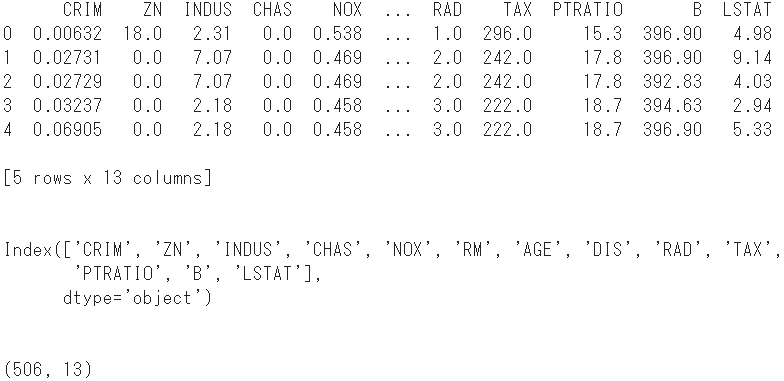
- まず、13の説明変数をデータフレームに変換します。
# 説明変数をDataFrameに格納
boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names)
print(boston.head()) # 先頭5行を表示
print(boston.columns) # カラム名を表示
print(boston.shape) # 形状を確認
- そこへ、目的変数をカラム名
MEDVとして追加します。
# 目的変数を追加
boston['MEDV'] = boston_dataset.target
print(boston.head()) # 先頭5行を表示
print(boston.shape) # 形状を再確認
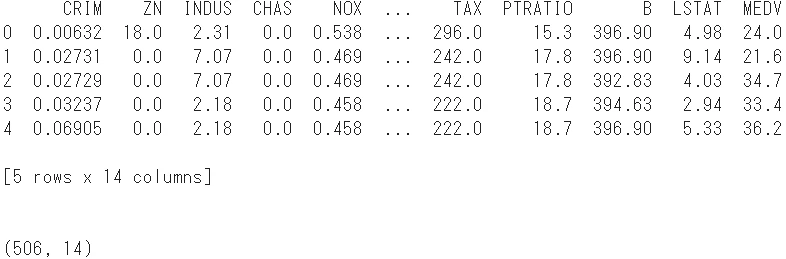
- サンプル数は506、13の説明変数に目的変数を加えて14列になっています。
- このデータセットをランダムに学習用データセットとテスト用データセットの2つのグループに分割します。
⑶ データの分割
# データセットをNumpy配列に変換
array = boston.values
# 説明変数と目的変数に分ける
X = array[:,0:13]
Y = array[:,13]
- 70%のデータを学習用データ、残りの30%のデータをテストデータとします。
# データを分割するモジュールをインポート
from sklearn.model_selection import train_test_split
# データを分割
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=1234)
⑷ 回帰木モデルの構築
- 分類木の場合と同じく、
fitメソッドに配列 X と Y を渡して学習させますが、この場合 Y は数値型です。 - オプションの
max_leaf_nodesで木をどのくらい成長させるかを指定します。ここでは葉ノードの数を最も多くて 20 までとします。
# モデルのインスタンス生成
reg = DecisionTreeRegressor(max_leaf_nodes = 20)
# 学習によりモデル生成
model = reg.fit(X_train, Y_train)
print(model)

⑸ 回帰木モデルの評価
- 得られた回帰木モデルを、予測の妥当性(➀)、モデル自体の汎用性(➁)という2つの方向からテストします。
- まず、予測の妥当性を確認するため、サンプル506個の中からランダムに1個を抽出し、その特徴量から予測される価格と実際に観測された価格を比較します。
➀予測の妥当性を確認する
- 元のデータセットXからランダムにidを1個だけ取り出します。
# Python標準の疑似乱数モジュールをインポート
import random
random.seed(1)
# ランダムにidを選定
id = random.randrange(0, X.shape[0], 1)
print(id)

# 元のデータセットから該当サンプルを抽出
x = X[id]
x = x.reshape(1,13)
# 説明変数から住宅価格を予測
YHat = model.predict(x)
# 当該idの説明変数をDataFrameに変換
df = pd.DataFrame(x, columns = boston_dataset.feature_names)
# 予測値yを追加
df["Predicted Price"] = YHat

- 実際に観測された住宅価格を取得し、比較してみます。
boston.iloc[id]
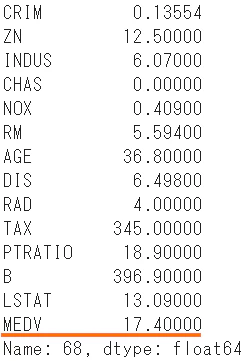
- 実際の価格17.40に対して、予想価格は20.45という結果となりました。
- 次の検証は、モデルの予測値がどのくらい観測値の情報量を説明できているか。
➁汎用性の指標として決定係数を確認する
- 決定係数$R^2$は、回帰分析において観測値$y$に対する予測値$\hat{y}$の説明力を表す指標で、寄与率ともいいます。
- 0から1までの値をとり、$R^2$が1に近いほどモデルが有効であることを意味します。
# 決定係数を算出する関数をインポート
from sklearn.metrics import r2_score
- テスト用の説明変数(X_test)をモデルに渡して予測値を算出します。
YHat = model.predict(X_test)

- これらの予測値とテスト用の目的変数(Y_test)を渡して決定係数を算出します。
r2 = r2_score(Y_test, YHat)
print("R^2 = ", r2)
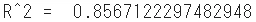
- テスト用データにおけるモデルの適合度は0.86、上々の結果となっています。
⑹ 回帰木モデルの可視化
# sklearnのtreeモジュールをインポート
from sklearn import tree
# Notebook内に画像を表示させるモジュール
from IPython.display import Image
# 決定木モデルを可視化するためのモジュール
import pydotplus
# 決定木モデルをDOTデータに変換
dot_data = tree.export_graphviz(model,
out_file = None,
feature_names = boston_dataset.feature_names,
class_names = 'MEDV',
filled = True)
# ダイアグラムを描画
graph = pydotplus.graph_from_dot_data(dot_data)
# ダイアグラムを表示
Image(graph.create_png())
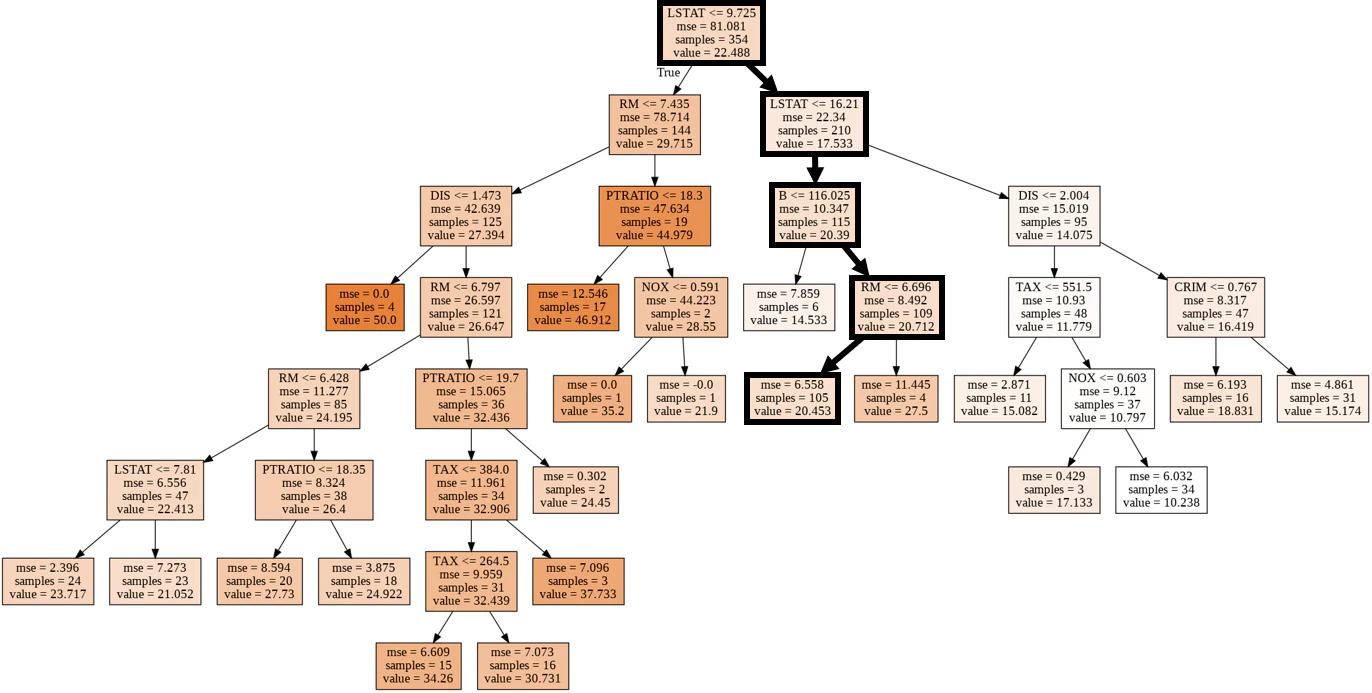
- 先のランダムに抽出されたサンプル(ID:68)のルートを太線で示しました。
- ちなみに、親ノードおよび第1階層の子ノードの特徴量「LSTAT」は「lower status」の略で、人口に占める下層階級の割合を意味しています。