- TF-IDFによるモデルを考えるとき、ドキュメントの単位をどのように設計するかが大切です。
- なぜなら、あるドキュメントを特徴づけるのは他のドキュメントとの異同であり、言い換えれば、複数のドキュメント間で相対化されてはじめてドキュメント毎の特徴が明確になります。
- 逆を言えば、かりに一つの小説の中の各文章をドキュメントの単位とした場合、同じ筆者、同じテーマについての文章ですからほとんど差異はなく分析するに値しないといえます。
- そこで試しに、小説3作品をドキュメントの単位として、scikit-learnを利用してTF-IDF分析を行ないます。
⑴ ライブラリのインポート
- まずドキュメントを取得するためのライブラリですが、青空文庫を利用する前提です。
import re
import zipfile
import urllib.request
import os.path
import glob
- 形態素解析エンジンMeCabをインストール、及びインポートします。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
import MeCab
- TF-IDF分析は、機械学習ライブラリscikit-learnの
TfidfVectorizerを利用します。
from sklearn.feature_extraction.text import TfidfVectorizer
- 分析結果をテーブルに整形する際にデータフレームを操作します。
import pandas as pd
⑵ ドキュメントを指定
- 夏目漱石の代表的な3作品を用いることとし、上から順に『吾輩は猫である』『三四郎』『こころ』のzipファイルのアドレスを指定します。
- 3. Pythonによる自然言語処理 1-2. コーパスの作成方法 : 青空文庫
URL = ['https://www.aozora.gr.jp/cards/000148/files/789_ruby_5639.zip',
'https://www.aozora.gr.jp/cards/000148/files/794_ruby_4237.zip',
'https://www.aozora.gr.jp/cards/000148/files/773_ruby_5968.zip']
⑶ 関数の定義
- TF-IDFの前段階として、➀ドキュメントを取得し、➁必要部分を抽出して整形し、➂分かち書きの分析用データを作成するという3ステップがあります。
- それぞれの処理について、あらかじめ関数として定義しておきます。
➊ドキュメントの取得
def download(URL):
# zipファイルのダウンロード
zip_file = re.split(r'/', URL)[-1]
urllib.request.urlretrieve(URL, zip_file)
dir = os.path.splitext(zip_file)[0]
# zipファイルの解凍と保存
with zipfile.ZipFile(zip_file) as zip_object:
zip_object.extractall(dir)
os.remove(zip_file)
# 保存したファイルのパスを取得
path = os.path.join(dir,'*.txt')
list = glob.glob(path)
return list[0]
➋本文の抽出・整形
def convert(download_text):
# ファイル読み込み
data = open(download_text, 'rb').read()
text = data.decode('shift_jis')
# 本文の抽出
text = re.split(r'\-{5,}', text)[2]
text = re.split(r'底本:', text)[0]
text = re.split(r'[#改ページ]', text)[0]
# ノイズ削除
text = re.sub(r'《.+?》', '', text)
text = re.sub(r'[#.+?]', '', text)
text = re.sub(r'|', '', text)
text = re.sub(r'\r\n', '', text)
text = re.sub(r'\u3000', '', text)
text = re.sub(r'「', '', text)
text = re.sub(r'」', '', text)
text = re.sub(r'、', '', text)
text = re.sub(r'。', '', text)
return text
➌品詞抽出・分かち書き
# Taggerオブジェクトを生成
tokenizer = MeCab.Tagger("-Ochasen")
tokenizer.parse("")
def extract(text):
words = []
# 単語の特徴リストを生成
node = tokenizer.parseToNode(text)
while node:
# 品詞情報(node.feature)が名詞ならば
if node.feature.split(",")[0] == u"名詞":
# 単語(node.surface)をwordsに追加
words.append(node.surface)
node = node.next
# 半角スペース区切りで文字列を結合
text_result = ' '.join(words)
return text_result
⑷ 分析用データの作成
- 3作品分のURLから一つ取り込んでは上記➊➋➌の処理を行うということをくり返し、次々に
docsに格納します。
docs = []
for i in URL:
download_file = download(i)
text = convert(download_file)
text = extract(text)
docs.append(text)
print(docs)

- 名詞だけが半角スペースで区切られたかたちで、3つのドキュメントのデータが生成されています。
⑸ TF-IDFの実行
- scikit-learnの
TfidfVectorizerを利用して $tfidf$ を求めます。
# モデルを生成
vectorizer = TfidfVectorizer(smooth_idf=False)
X = vectorizer.fit_transform(docs)
# データフレームに表現
values = X.toarray()
feature_names = vectorizer.get_feature_names()
df = pd.DataFrame(values, columns = feature_names,
index=["吾輩は猫である", "三四郎", "こころ"])
print(df)

- 3 rows × 8914 columns ですから、単語は「10」 「affect」 「agnodice」 から 「鼻筋」 「鼻緒」 「齷齪」 に至るまでの 8914 カラムとなっています。
- とはいえ、相当数のカラムが 0.000000 であることが予想されます。
⑹ 上位10語の抽出
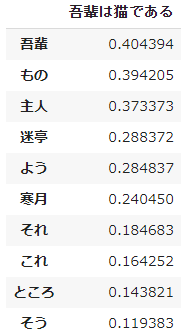
- 『吾輩は猫である』を対象に $tfidf$ 値による上位10語を示します。
# 行列を転置
df_0 = df[0:1].T
# 値で降順ソート
df_0 = df_0.sort_values(by="吾輩は猫である", ascending=False)
# 上位10語を取得
df_0.head(10)
⑺ 出現回数上位10語との比較
- では、単に出現回数による上位10語の方も取得して見比べてみましょう。
- Python標準ライブラリ
collectionsのCounterクラスで出現回数を取得し、同じくmost_commonメソッドで出現回数順に要素を取得します。
from collections import Counter
# 文字列を分割
docs_ = docs[0].split(" ")
# 出現回数の取得
cnt = Counter(docs_)
cnt.most_common(10) #上位10

- 「の」 「事」 「もの」 といった一般的に使用頻度が高く、具体的な何かを指していない語が上位を占めています。
- 以下に3作品の $tfidf$ 上位10語を一覧します。

- その作品ならではの語(固有語)、その作品らしい語(特徴語)が上位にあがっており、各ドキュメントの特徴を示しているといえます。
- 個性や特徴とは、相対化されることによって際立ってくるものです。人と話してみて、そこで自分の考え方やものの見方というものが意識されたりといった覚えはないでしょうか。
- どのようなドキュメントを対象とするか、それらをどのように構成するかによって TF-IDF はさまざまな目的に有効活用できるように思われます。