ここ数年来 AI やビッグデータへの関心の高まりに伴い、機械学習のためのアプローチ法として、例えばk-meansといった分析手法を耳目にするようになりました。それらは、いずれも昭和の昔から何十年とビジネスや学術分野で活用されてきた多変量解析の手法です。
その中でも特にポピュラーな手法の一つが回帰分析です。
そこで、まず機械学習ライブラリの scikit-learn(サイキット・ラーン)を利用して単回帰分析を実装してみます。
(原則として Google Colaboratory 上でコードの記述や結果の確認をおこないます)
単回帰分析
回帰分析は、2つの変量を対象とする単回帰分析と、3つ以上の変量を対象とする重回帰分析に分けられます。
まず、単回帰分析を考えます。
単回帰分析とは、データ(現象)の中に線形ないし非線形の法則性を導くもの・・・・・・、平たく言えば、$x$が増えると$y$も一定の比率で増える/減るというような法則性を明らかにするものです。
ごくシンプルな線形の単回帰分析は、次の式で表わされます。
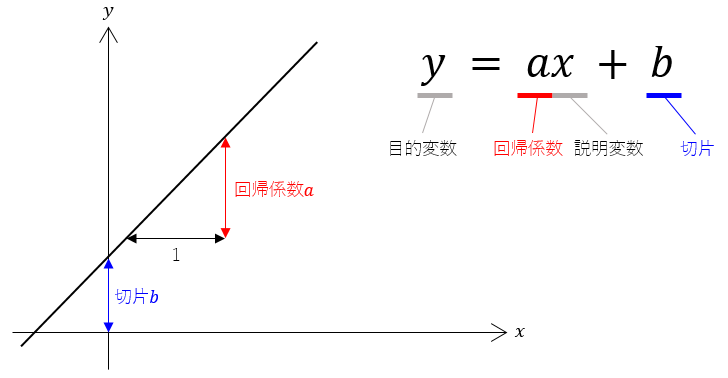
この方程式を回帰式(単回帰式)といいます。
この$a$と$b$さえ決まってしまえば自ずと直線は引けます。すると、$x$で$y$を説明することができる、あるいは$x$から$y$を予測することができる。
変数$y$ を変数$x$ によって説明するということから、ターゲットとなる $y$ を目的変数(従属変数)、これを説明する $x$ を説明変数(独立変数)と呼びます。
また、回帰直線の傾きを示す$a$を回帰係数、$y$軸との交点を示す$b$を切片といいます。
すなわち回帰係数aと切片bを求めることが、単回帰分析の目標です。
⑴ ライブラリをインポートする
# 数値計算に必要なライブラリ
import numpy as np
import pandas as pd
# グラフを描画するパッケージ
import matplotlib.pyplot as plt
# scikit-learnの線形モデル
from sklearn import linear_model
⑵ データを読み込み、中身を確認する
df = pd.read_csv("https://raw.githubusercontent.com/karaage0703/machine-learning-study/master/data/karaage_data.csv")
df

⑶ 変量x, yをNumpyのArray型に変換する
データが格納された変数dfは、Pandasのデータフレームの形式になっています。これを後々の計算のために、NumpyのArray型に変換するなどして変数x, yにそれぞれ格納します。
x = df.loc[:, ['x']].values
y = df['y'].values

変量$x$は、pandasのloc関数で [全行, x列] の要素を切り出してvaluesでNumpy配列に変換し、2次元データとして格納しました。また変量$y$は、列名$y$を指定して1次元データとして取り出し、同様にNumpy配列に変換しています。
⑷ 散布図にデータをプロットしてみる
描画パッケージ matplotlib を利用して、plot関数の引数に(変数x, 変数y, ''マーカーの種類'')を指定します。
plt.plot(x, y, "o")
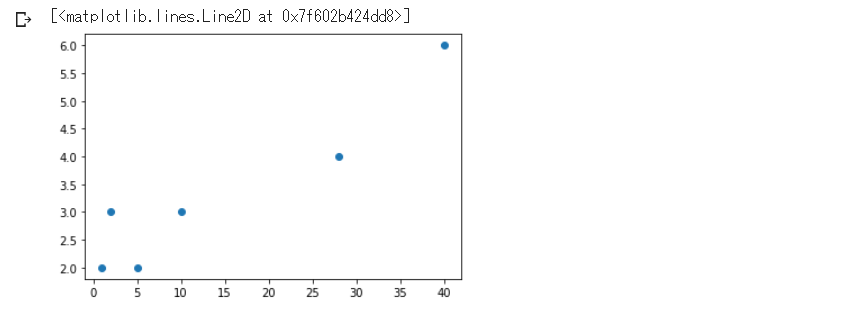
ここから機械学習ライブラリscikit-learn の線形回帰モデルを利用して、回帰係数$a$ と切片$b$ を計算していきます。
⑸ 線形回帰モデルに変量x, yを適用する
# 線形回帰モデルを読み込み、関数clfとする
clf = linear_model.LinearRegression()
# 関数clfに対して変量x, yをあてはめる
clf.fit(x, y)
⑹ 回帰係数・切片を算出する
回帰係数はcoef_、切片はintercept_で取得できます。
# 回帰係数
a = clf.coef_
# 切片
b = clf.intercept_

⑺ 決定係数を算出する
次いで、決定係数をscore(変数x, 変数y)として取得します。
# 決定係数
r = clf.score(x, y)

決定係数
決定係数は、得られた回帰式の精度をあらわす指標です。
精度とはこの場合、「回帰式がデータの分布をどの程度よく説明できているか」ということです。
決定係数は、次のように定義されます。
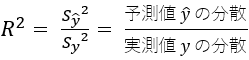
実際に観測されたデータのことを実測値と呼びます。散布図を見て明らかなように実測値は座標上に散らばっています。
これを一本の直線に要約するわけですから、もとの分散の持っている情報をいくらか棄却することになります。
この棄却した部分、すなわち回帰式に伴う誤差のことを残差といい、次のような分数の形に表わすことができます。

分母は実測値である目的変数$y$の分散で、分子は回帰式による予測値$\hat{y}$の分散と、残差という目減り分を置いて上下は均衡します。
つまり決定係数とは、実測値の分散のうち予測値の分散が何割を占めるかということです。
割合ですから、決定係数$R^2$は必ず0以上1以下の値をとり、1に近いほど回帰式の精度がよいと解釈されます。
⑻ 回帰直線を描くためのx値を設定する
まず回帰直線の元となる$x$値を、Numpyのlinspace関数をつかって生成します。
引数には (始点, 終点, 区切る数) を指定します。
fig_x = np.linspace(0, 40, 40)

⑼ 回帰係数、切片、x値の形状を確認する
print(a.shape) # 回帰係数
print(b.shape) # 切片
print(fig_x.shape) # x値

Tips
このまま $y = ax + b$ に代入するとエラーになってしまいます。
なぜなら、回帰係数$a$ は1行×1列のarray型、$x$値は40行×1列のarray型なので、配列同士を乗算するときのルールに合っていないからです。
そこで、回帰係数$a$ を単一の値に変換し、$x$値のすべてに等しく乗算されるようにしておく必要があります。
⑽ 変量yを定義する
y値すなわち変数 fig_y の計算式を定義するに際し、Numpyのreshape関数をつかって回帰係数$a$ の形状を変換します。
fig_y = a.reshape(1)*fig_x + b

⑾ 回帰直線を描画する
# 散布図
plt.plot(x, y, "o")
# 回帰直線
plt.plot(fig_x, fig_y, "r") # 第3引数で線の色を"r"に指定
plt.show()
以上のように、機械学習ライブラリを利用することで、複雑な計算をしなくとも分析結果を得ることはできます。
しかし、回帰分析に限ったことではありませんが、計算結果に対していかにそれを適切に解釈するか、あるいは手法を運用する上で微妙なチューニングを行なうとなると、やはり計算の仕組み(アルゴリズム)を知っておくことが望ましいといえます。
そこで次は、scikit-learn を利用しないで、すべて自前で単回帰分析を学びます。