はじめに
Oracle Cloud Infrastructure(以降、OCI) Data Science は2020年2月にリリースされたデータ分析プラットフォームです。
さらっと触った印象では、特徴は以下だと思いました。
-
ノートブック・セッション(JupyterLab)の利用が可能
-
チームの分析環境集約により情報共有、意思決定が促進
(あの人どんな状況かなぁって環境をチラ見できる) -
Oracle Accelerated Data Science (ADS)SDKが利用可能
ADS SDKは、OCI Data Scienceサービスの一部としてプリインストールされているPythonライブラリです。
アルゴリズムの選択とチューニングを自動化してくれるAuto ML機能を有しています。 -
安価に利用可能
PaaSとしては無償であり、Data Science サービスを立てるさいにバインドするComputeインスタンスの料金のみ
(アクティブ化する度にComputeインスタンスのシェイプやブロックボリュームのサイズを変更可能)。
先ずは使ってみる
ノートブック・セッションの作成
以下の記事を参考に作成しました。
Oracle Cloud Infrastructure Data Scienceを使ってみよう
ノートブック・セッションの接続
クラウド・コンソールの「開く」から接続します。
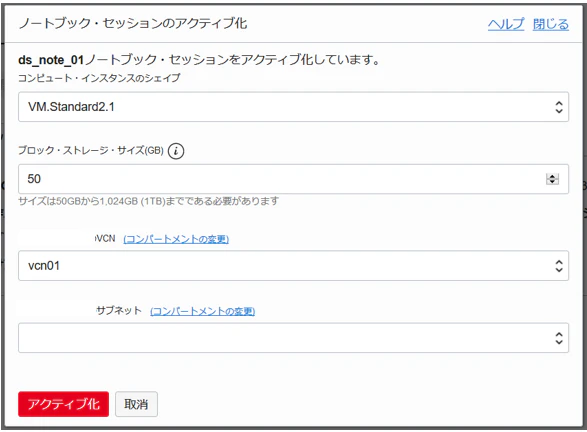
ノートブック・セッションのアクティブ化時にコンピュート・インスタンスのシェイプを指定できるので、必要なときに必要な分だけシェイプを上げて、課金を抑えることができます。
既存のOCI Database に接続
ライブラリのインポート
import pandas as pd
import cx_Oracle
import seaborn as sns
DB に接続しSELECT結果取得
connect=cx_Oracle.connect(user='<スキーマ名>', password='<PW>', dsn='<IPアドレス>:<ポート番号>/<サービス名>')
cursor = connect.cursor() # connect cursor
# SQL Execute
cursor.execute("select col_id, col1, col2, col3 from T_TEST")
# fetch
data = cursor.fetchall()
# データフレームに列名指定
headers = [ x[0] for x in cursor.description]
df = pd.DataFrame(data, columns=headers)
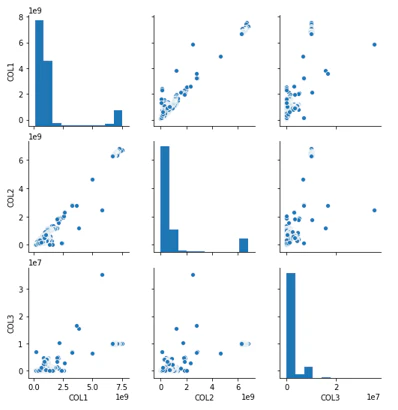
pairplotで散布図行列の可視化
sns.pairplot(df,vars=['COL1','COL2','COL3'])
ADS 使ってみる
seabornでおしゃれな図を得られてOCI Data Science の特徴の一つADSを忘れちゃいかん。
# ADS import
import ads
from ads.dataset.factory import DatasetFactory
# データフレームをADSDatasetに格納
ds = DatasetFactory.from_dataframe(df)
# データ分布概要取得
ds.show_in_notebook()
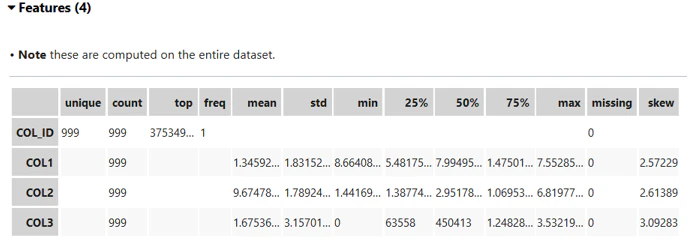

↑各列ごとの統計量をコマンド一つで取得可能
ADSのマニュアルでは以下のようにグラフも合わせて描画してくれている(グラフが出力されないときもある、原因は今のところ不明)。
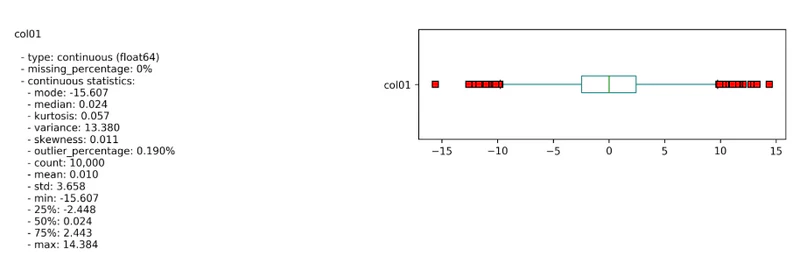
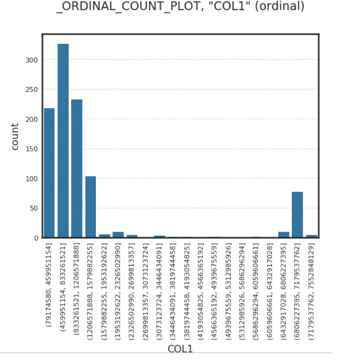
# To plot a single column
ds.plot("COL1").show_in_notebook()
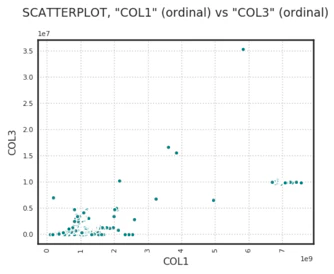
# To plot two columns against each other:
ds.plot("COL1", y="COL3").show_in_notebook()
ADSによるModel Training等は今後。
以上です。
リファレンス
Oracle Cloud Infrastructureドキュメント データ・サイエンス
https://docs.cloud.oracle.com/ja-jp/iaas/data-science/using/data-science.htm
Oracle Accelerated Data Science SDK (ADS)
https://docs.cloud.oracle.com/en-us/iaas/tools/ads-sdk/latest/index.html
Oracle Cloud Infrastructure Data Scienceを使ってみよう
https://community.oracle.com/docs/DOC-1036110