■目的
ブロックチェーンのデータを抽出しながら、
SQLの操作方法の基本を身につける。
■SQLの文と種類
SQLには与える命令の種類により、次の3つに分類されます。
・DDL(Data Definition Language:データ定義言語)
データベースやデータを作成したりします。
例:
CREATE,DROP,ALTER
・DML(Data Manipulation Language:データ操作言語)
テーブルの行を検索、変更を行います。
例:
SELECT,INSERT,UPDATE,DELETE
・DCL(Data Control Language:データ制御言語)
データベースに対して行った変更を、確定、取り消しをします。
また、データベースを操作する権限の設定も行う。
例:
COMMIT,ROLLBACK,GRANT,REVOKE
今回、Duneアナリティクスのプラットフォーム内のデータベースから操作を行うので、
DMLのSELECTが中心になります。
■SQLの基本的記述ルール
・SQL分の最後に「;」(セミコロン)をつけて終わる。
プログラミング言語によっては、1命令ごと、関数ごとに「;」をつけますが、
SQLは最後のみに「;」をつけます。
・記述するキーワードは大文字・小文字は区別されない。
データベースを操作する命令は、大文字・小文字が区別されません。
「SELECT」と書いても、「select」と記述しても同じ解釈がされ、命令が実行されます。
ただし、データベースに登録されているデータは、大文字・小文字が区別されます。
例えば、「TOKYO」と「tokyo」、「HOKKAIDO」と「hokkaido」は別のデータとして区別されます。
・定数(ていすう or じょうすう)の書き方には決まりがある。
データベースの文字の検索、登録、更新するとき、
SQL文に直接文字列、日付などを記述します。
その時、文字列を「''」(シングルクォーテーション)で囲みます。
例えば、ブロックチェーンのblock_numberの列名に61151のデータを検索したい場合、
'61151'と書きます。
日付の場合、'2015-08-10'のように書きます。
文字列ではなく、数値を記述する場合は、シングルクォーテーションは使わず、数値のみの記述、
5000000000000000000のようになります。
・単語は半角スペースか改行で区切る。
例えば、
SELECT block_number FROM ethereum.transactions;
や
SELECT block_number
FROM ethereum.transactions;
と記述します。
■データベースの検索
・列の出力
テーブルからデータを取り出すとき、SELECT文を使います。
テーブルとは、行(レコード)と列(カラム)で構成されているもの。
EXCEL内に住所録など登録されている行、列に似ている構成のものをいいます。
SELECT文でデータを検索、取り出すことを「問い合わせ」や
「クエリ(query)」といいます。
基本的な構文
SELECT <列名>,・・・
FROM <テーブル名>;
SELECT句とFROM句を使って、テーブルのデータを取り出します。
具体的には、
取り出すテーブル名、
ethereum.blocks
から
列名、
time,number,gas_limit
を取り出す場合、
SELECT time,number,gas_limit
FROM ethereum.blocks;
と記述します。

すべての列を取り出す場合、
「*」(アスタリスク)を使います。
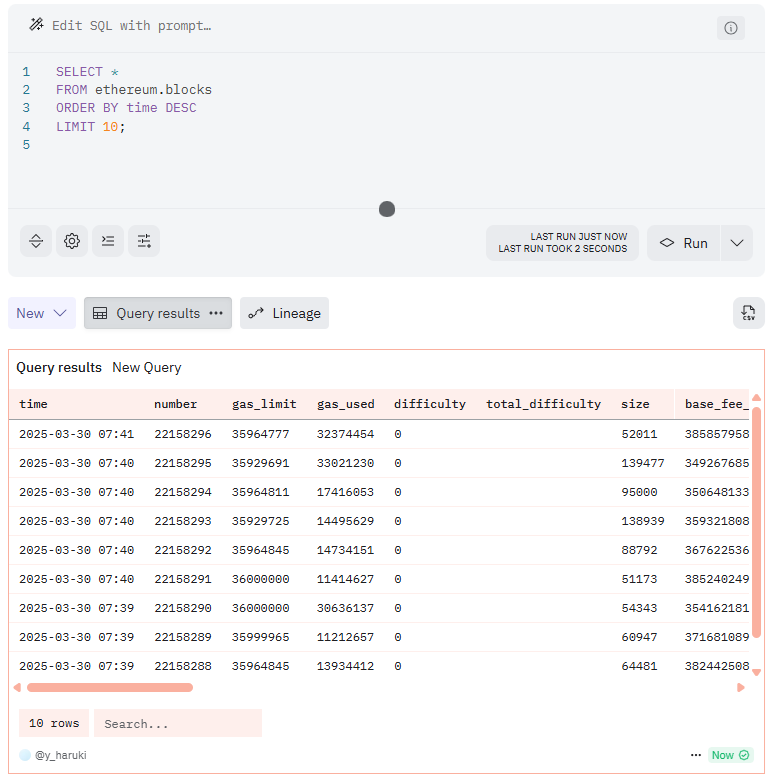
SELECT *
FROM ethereum.blocks;
また、ブロックチェーンのデータは大量にあるので、
上記のようにクエリを使うと、時間がかかります。
簡単にデータの中身を見るだけの場合、取り出す行数を指定します。
LIMIT句を使って、取り出す行数を指定します。
例えば、すべての列、10行表示させる場合、FROM句のあとに
以下のように記述します。
SELECT *
FROM ethereum.blocks
LIMIT 10;
・列に別名をつける場合
SELECT time,number,gas_limit
FROM ethereum.blocks;
にそれぞれ別の列名をつけるとき、
AS キーワードを使います。
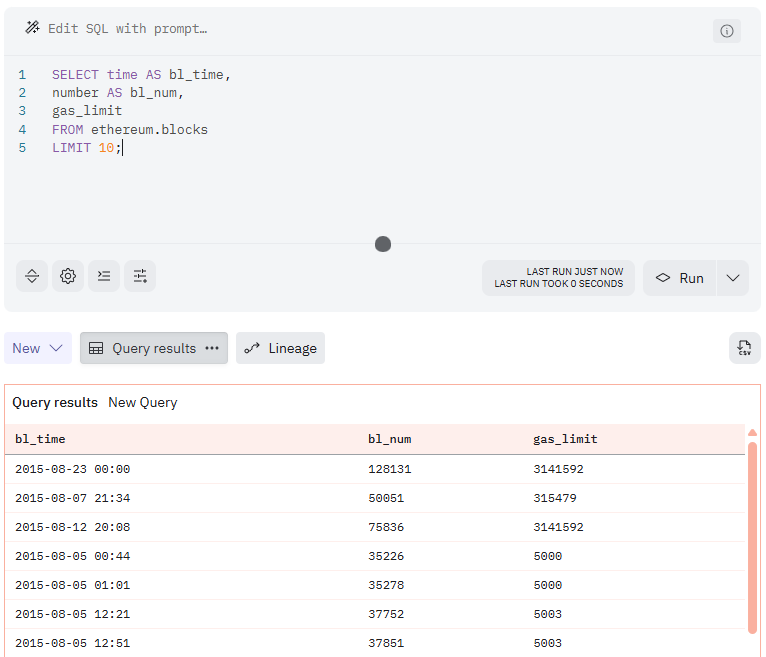
SELECT time AS bl_time,
number AS bl_num,
gas_limit
FROM ethereum.blocks
LIMIT 10;
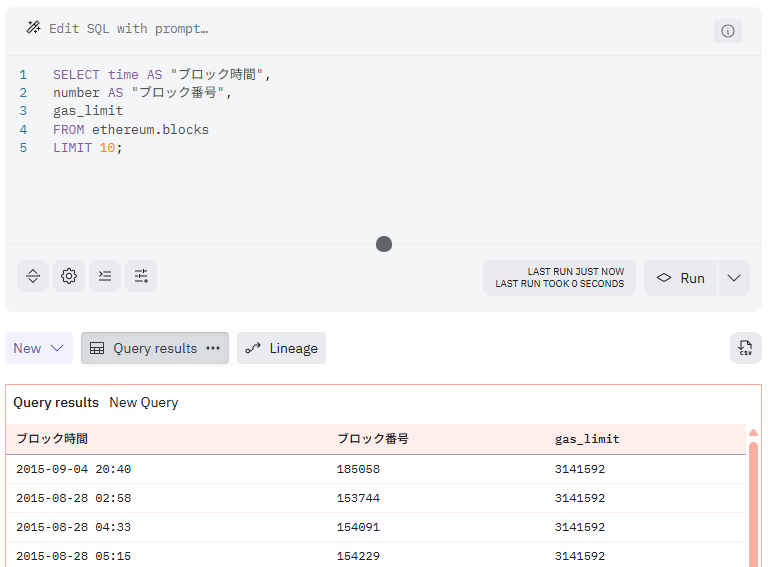
また、別名に日本語を使いたい場合、つけたい別名を
「""」(ダブルクォーテーション)で囲みます。
SELECT time AS "ブロック時間",
number AS "ブロック番号",
gas_limit
FROM ethereum.blocks
LIMIT 10;
・実行結果からデータの重複を除く
テーブル内のデータの重複を除いて出力したい場合、
DISTINCTを使います。
ここでテーブルを変えて、ethereum.logs_decodedを使います。
重複を削除したい列は、namespace列とします。
記述は以下になります。
SELECT DISTINCT namespace
FROM ethereum.logs_decoded;

・表示する行に条件をつけて出力する。
表示する行に条件を指定して問い合わせします。
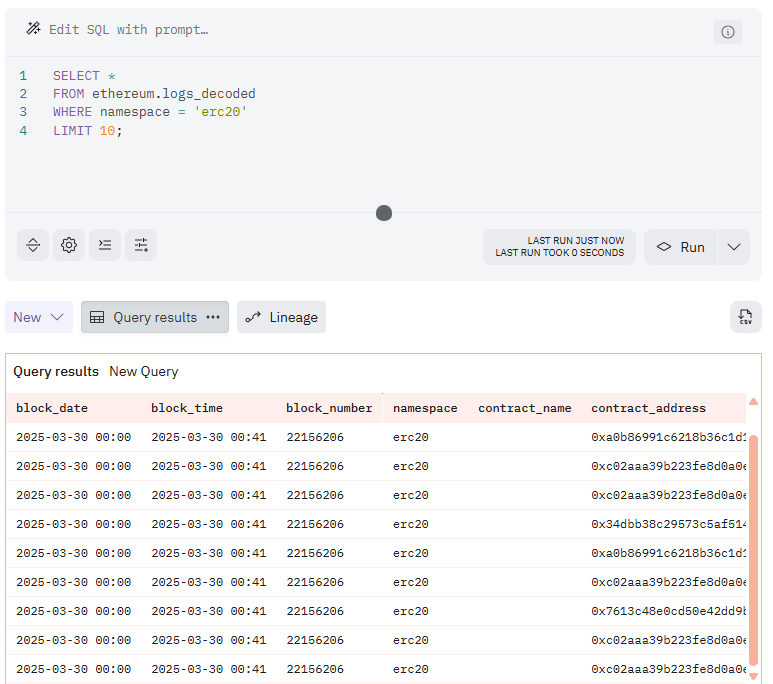
例えば、ethereum.logs_decodedテーブルの
namespace列の値が、erc20の行を表示させたい。
このとき、WHERE句を利用します。
記述は以下になります。
SELECT *
FROM ethereum.logs_decoded
WHERE namespace = 'erc20';
・NULL値を検索する
テーブルデータから特定の列に値が入っていない行を出力したい場合、
「WHERE 〇〇 = NULL」では条件が選択されません。
「WHERE 〇〇 IS NULL」のように記述します。
例えば、ethereum.logs_decodedテーブル、contract_addressの行のNULLを表示させる場合、
記述は以下になります。
SELECT *
FROM ethereum.logs_decoded
WHERE signature IS NULL
LIMIT 10;
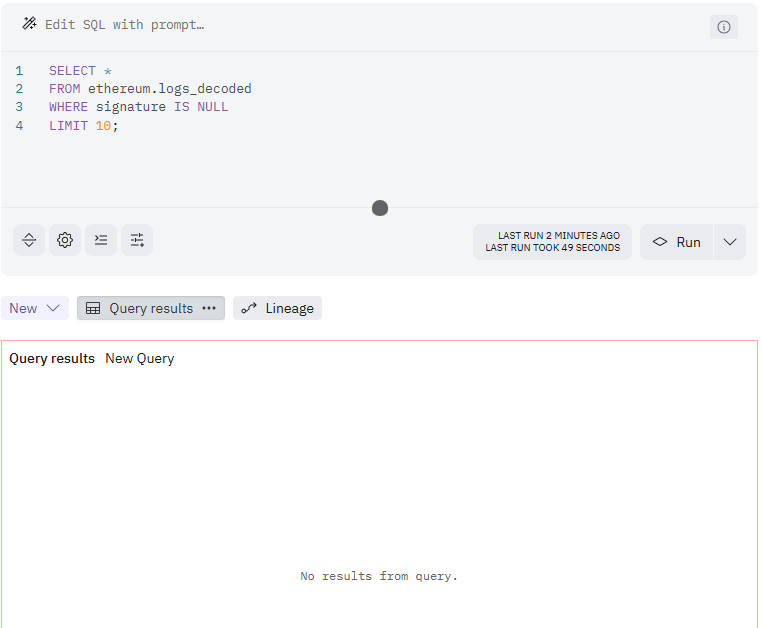
ethereum.logs_decodedテーブルではなかなかNULLがないので
他のテーブルで例を出します。
SELECT *
FROM ethereum.blocks
WHERE blob_gas_used IS NULL
LIMIT 10;
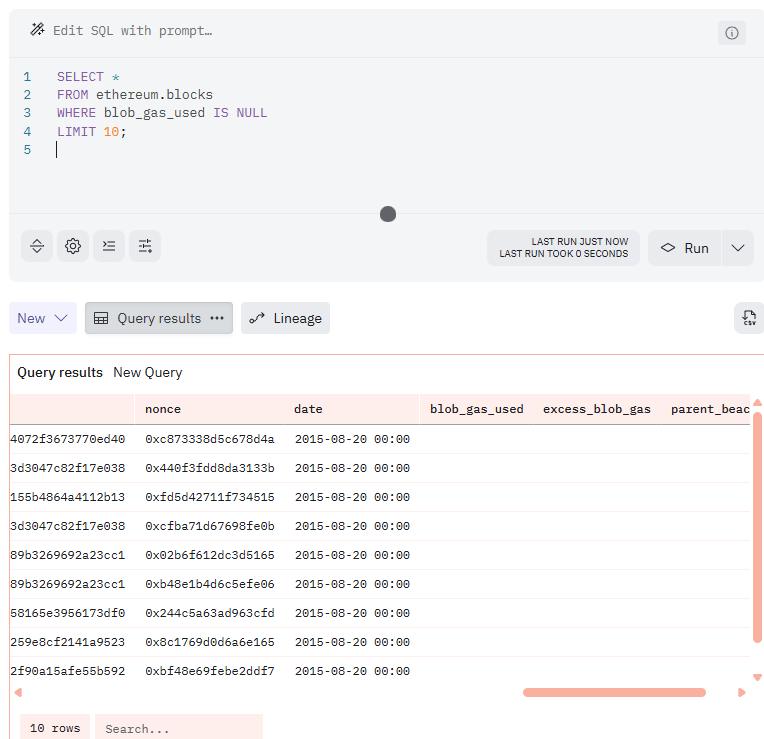
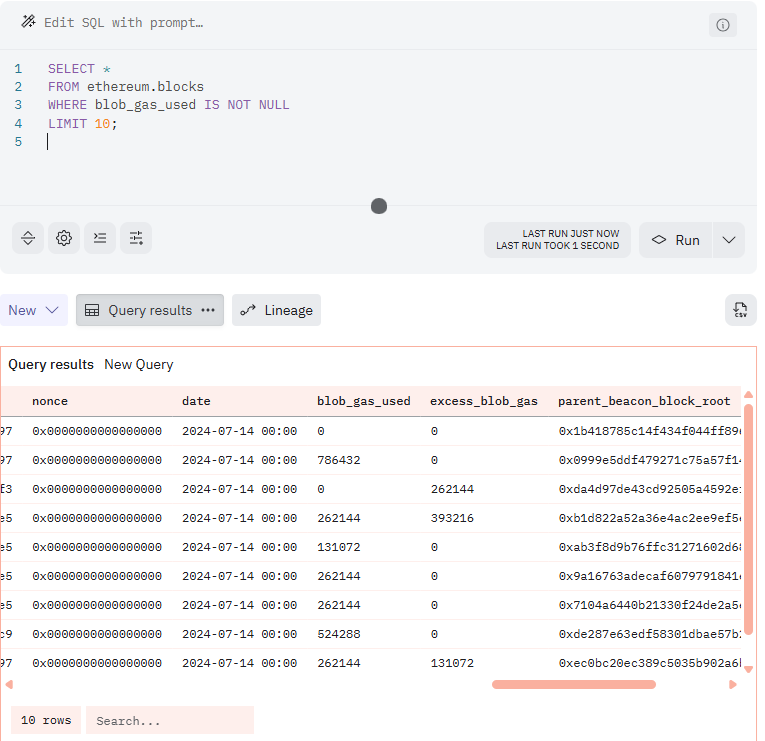
NULL 以外を抽出する場合は、 IS NOT NULL を使います。
SELECT *
FROM ethereum.blocks
WHERE blob_gas_used IS NOT NULL
LIMIT 10;
データを表示をソート(順)に表示する場合、
ORDER BY を使います。
例は、time列を昇順にソートする場合
SELECT *
FROM ethereum.blocks
ORDER BY time
LIMIT 10;

time列を降順に表示させる場合、ORDER BY 列名のあとにDESCをつけます。
SELECT *
FROM ethereum.blocks
ORDER BY time DESC
LIMIT 10;