SQLServerのインデックスについて理解できていないところがあるので
学んだ内容をまとめてみました。
1.インデックスとは
インデックスとは本の索引のようなもので、検索したいデータがテーブルのどこにあるのかを示すものです。
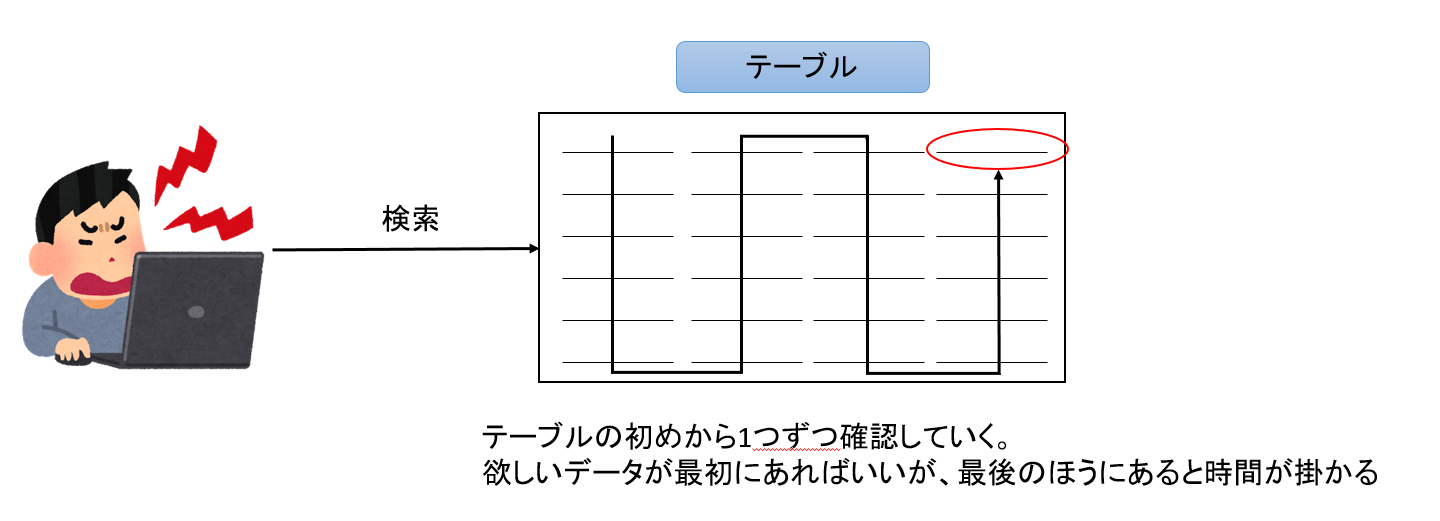
テーブルにインデックスが存在しないと検索したいデータが見つかるまでテーブルの端から端まで順に探す必要があります。このことをフルテーブルスキャンと言いますが、フルテーブルスキャンが発生すると多くの場合は検索に時間が掛かるので、インデックスを使用した検索が基本的には推奨されます。
- インデックスを使う場合
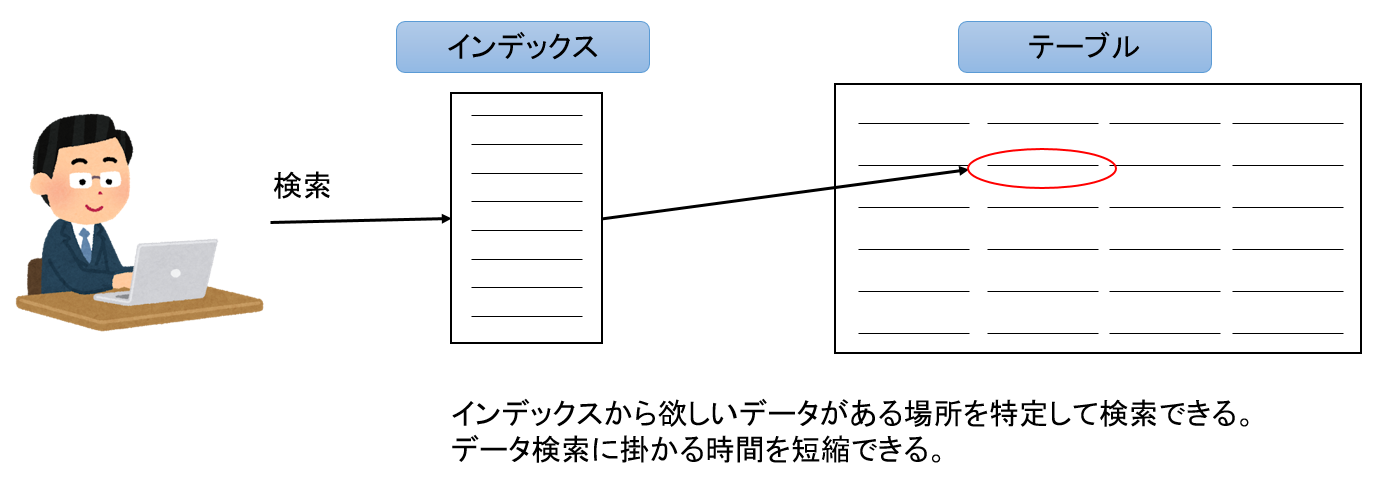
- インデックスを使わない場合(フルテーブルスキャン)
2.SQLServerにおけるインデックスの種類
インデックスは下の図のように大きく2つに分類することができます。
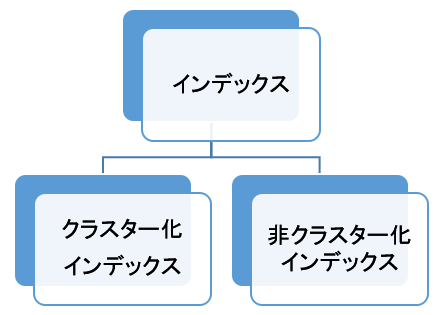
少し難しい単語が出てきましたが、それぞれの特徴を抑えればそれほど難しいものではありません。1つずつ説明していきます。
- クラスター化インデックス
テーブルに主キー(Primary Key制約)を作成した際に自動で作成されるインデックス。
特徴としては以下の2つが挙げられます。- 1つのテーブルに1つしか作成できない
- テーブルのデータはクラスターインデックスによって並び替えられる
- 非クラスター化インデックス
ユーザが任意に作成したインデックス、またはカラムに一意キー(Unique Key制約)を作成した際に自動で作成されるインデックス。
特徴として以下のものが挙げられます。- 1つのテーブルに999個まで作成可能
3.インデックスの構造
次に、インデックスは具体的にどのような構造になっているのか解説します。
クラスター化インデックスも非クラスター化インデックスも構造は同じでB-Tree構造をしていますが、データの持ち方は少し異なります。
B-Tree構造と言われると難しい話になってきたと思う方もいらっしゃると思うので
図を交えながらなるべく簡単に説明していきます。
例として以下のような社員ID,組織コード、名前を格納しているテーブルを考えます。
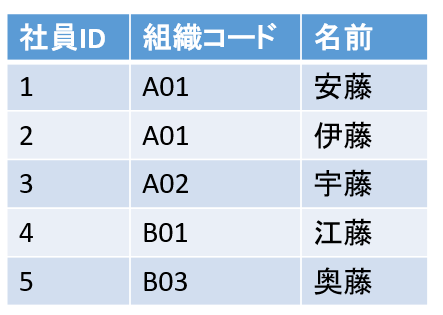
クラスター化インデックスの場合
社員ID列に対してクラスター化インデックスを作成するとインデックスはこのような構成になります。
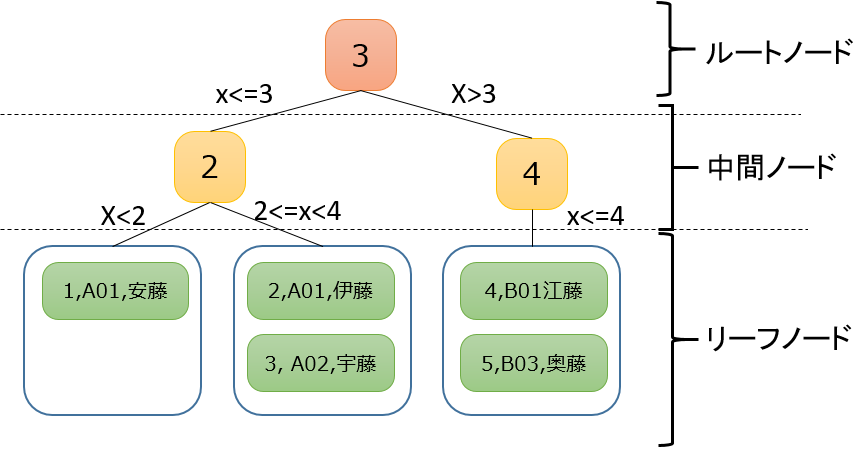
赤い四角がルートノード、黄色い四角が中間ノード、緑の資格がリーフノードと呼ばれます。
ルートノードを起点としてルートノードの数値より小さいものは左側、大きいものは右側に配置するように中間ノードを組み立てます。
特徴としては以下のものが挙げられます。
- ルートノードにテーブルの情報がすべて格納されている
(インデックス=テーブルとなっている) - インデックスの値(ここでは社員ID列)でソートされているのが特徴です。
例えば、IDが「2」の行の名前を検索する際には
1.ルートノードの「3」と「2」を比較する ⇒ 「2」は「3」より小さいので左に進む
2.中間ノードの「2」と「2」を比較する ⇒ 「2」は「2」に等しいので右に進む
3.リーフノードにたどり着いたのでその中で「2」に一致するデータを検索し、名前を取得する。
非クラスター化インデックスの場合
組織コード列に対して非クラスター化インデックスを作成するとインデックスはこのような構成になります。
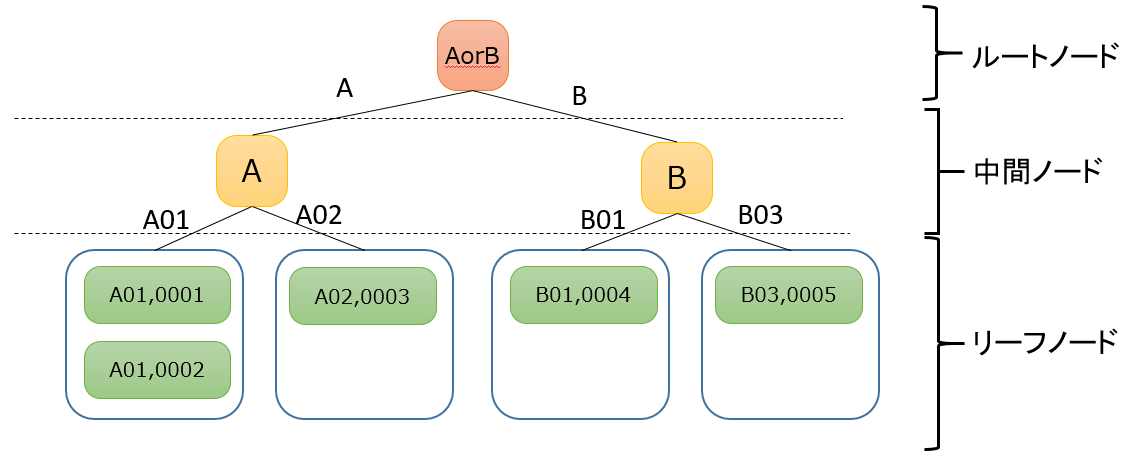
見た目はクラスター化インデックスとよく似ていますが、大きな違いがリーフノードに表れています。
非クラスター化インデックスではリーフノードにインデックスに設定されたカラム以外は持たずに、代わりにその列のデータが格納されている場所を示す識別子を保持します。
この状態で組織コードを検索キーに名前を取得する際にはリーフノードまでたどり着いたらその識別子を参照して名前を取得します。
つまり、ツリーの階層の深さは同じだとしても非クラスター化インデックスのほうが識別子から参照するという手順が増える分どうしてもクラスター化インデックスよりも時間が掛かってしまうこちが多くなります。
しかし、非クラスター化インデックスでも検索されるカラムが決まっている場合はリーフノードに特定のカラムの値を持たせることができます。この追加したカラムは「付加列」と呼ぶそうです。
クラスター化インデックス、非クラスター化インデックスの理解についてはコチラのサイトが参考になったので合わせて紹介しておきます。
【SQL Server】クラスター化インデックスと非クラスター化インデックス