SRE Advent Calendar 2018 5日目の記事です。
https://qiita.com/advent-calendar/2018/sre
スタートアップのサービスの成長に伴うDB負荷問題と、その対策の歴史、および得たノウハウを書いていきたいと思います。
※具体的なノウハウというよりは、概要をざっと話していきます。
イントロダクション
スタートアップのサービスが順調に成長していくと、大抵はDBの負荷問題に悩まされることが多くなります。
以下が主な要因になると思います。
- アクセスの増加
- データ量の増加
- ソースコードの増加
- DB負荷がかかる処理の増加
これは、SREで常に闘っていかないといけないテーマであり、インフラ、ミドルウェア、アプリのあらゆる面から対応が必要になります。
データベースのチューニング
緊急でなければ、スケールアップをする前に検討しておきたい事項です。
上記の要因により、データーベースのレスポンスが悪くなってきたら、まずデータベースのパラメータを見直します。
MySQLであれば、my.ini、my.cnfの設定、AWSのRDSであればパラメータグループを設定することになります。
パラメータのチューニングを行うには普段からの計測が大事になります。
データベースサーバーのリソース消費量を常にウォッチしてサービスの特性を理解しておき、最適なパラメータを設定します。
※AWSのRDS等、クラウドのマネージドサービスは、インスタンスタイプに沿ったパラメータを予め設定してくれるので楽です。
インデックスチューニング
特定のテーブルのクエリが重くなってきたら、インデックスチューニングを検討します。
※具体的なインデックスチューニングの事例はエンジニアブログに記載予定。
MySQLであれば、スロークエリを出力するように設定しておき、閾値以上の時間がかかっているクエリを常に確認しておくと良いでしょう。
リアルタイムに監視するなら、Jet Profilerが便利です。
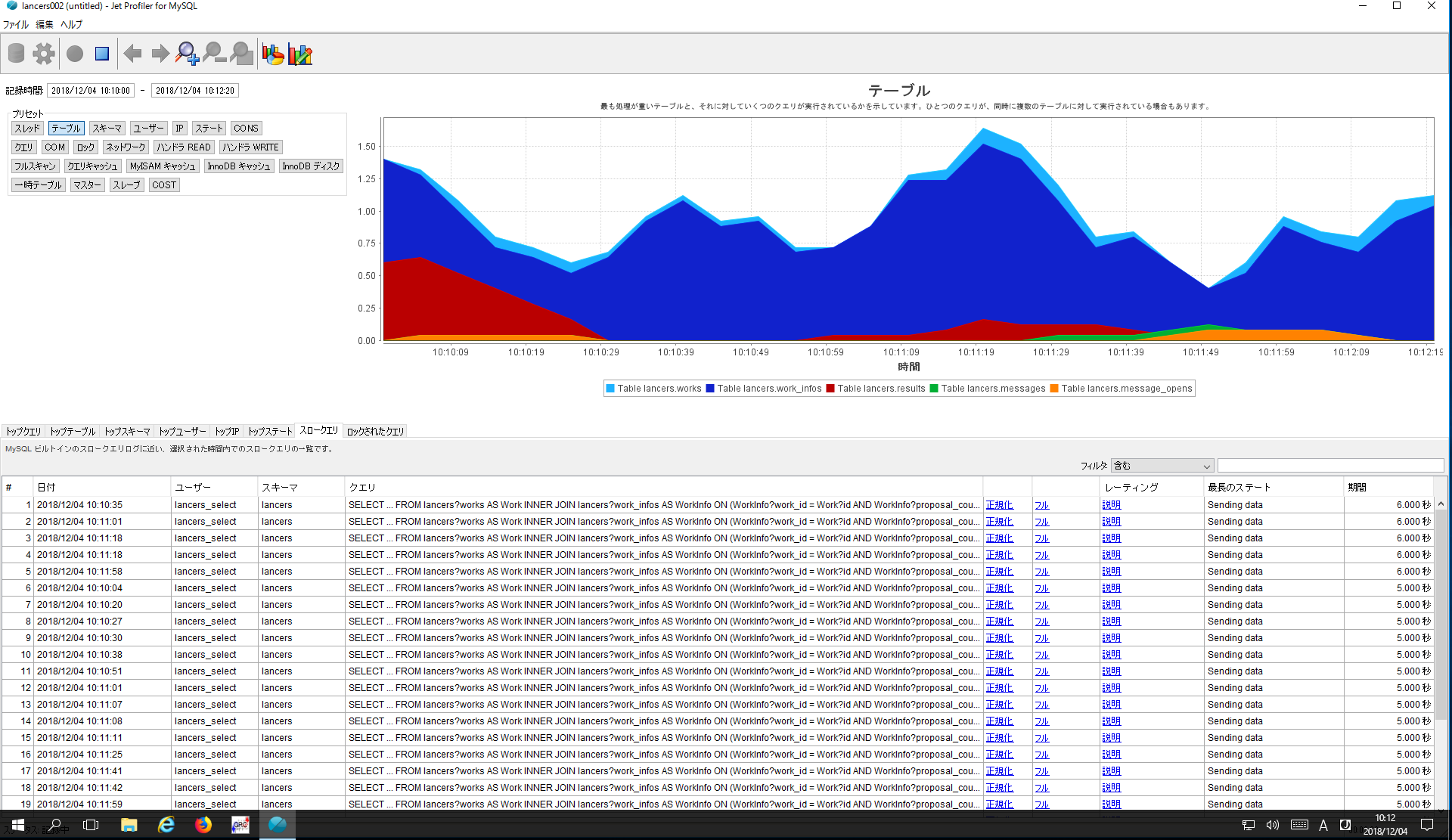
また、アプリ側でTimeOut系のエラーを吐いている場合もあるので、こちらも常にチェックしておくと良いでしょう。
スケールアップ
上記の対策を施した上で限界が来た場合はスケールアップを検討します。
スケールアップした際は、同時にDBパラメータ設定も変更します。
「データベースのチューニング」で設定したパラメータを基準としておき、DBをスケールアップしたときに、その基準に沿ってパラメータを拡張する感じです。
※AWSのRDS等、クラウドのマネージドサービスは、インスタンスタイプに合わせてある程度、パラメータを自動的に設定してくれるので楽です。
スケールアウト
大抵のサービスは、更新系のクエリよりも参照系のクエリの方が多いと思います。
なので、参照専用のレプリカを作り、スケールアウトする方法は特にDBのCPU負荷分散対策として有効です。
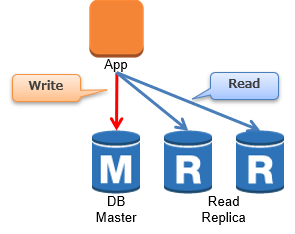
ただし、アプリケーションサーバーと違い、ロードバランサーは自前で用意する必要があるかも知れません。
定番の方法としては、アプリケーションサーバーにHAProxyやMySQL Proxy等をインストールし、ラウンドロビンの設定を行う方法があります。
※AWSのRDS AuroraはReader Endpointが用意されており、これを設定することで手軽に負荷分散が可能です。
更新系DB(1台)と参照系DB(複数台)にそれぞれクエリを振り分けるにはアプリケーション側のソース修正が必要になるでしょう。
このような負荷分散をサポートしているアプリケーションフレームワークはあまり多くないので、その場合は自前でDB切替処理を実装する必要があるでしょう。
※AuroraのMulti Master Endpointが正式にサポートされれば、この様な処理自体必要無くなりそうなので、期待したいところです。
クエリの改善
特定のクエリが重い場合は、いよいよクエリのチューニングが必要になります。
ここから、アプリケーションのソースコードに手を出していくことになります。
COUNT
WEBページを返す処理の間にSQLのCOUNT文を入れるのは基本的にNGです。
サービス開始当初はレコードが少なく、問題にならなくても、レコードが増えるにつれ、COUNT文の処理が重くのしかかってきます。
予めバッチで集計処理を行い、集計結果を別テーブル、もしくはキャッシュに格納しておくのが最もシンプルな回避方法かと思います。
全文検索エンジンのファセットを使うのも有力な手段となると思います。
ORDER BY
ソートは、全レコード、もしくは広範囲のレコードのを対象とすることが多いので、ソート対象のカラムにはインデックスがほぼ必須です。
MySQLのBTreeインデックスは、は原則1テーブルにつき1インデックスしか使えないので、ソート対象カラムにインデックスが適用されているかを確認しておきましょう。
FORCE INDEX(USE INDEX)
MySQLが適切なインデックスを選択してくれないときは、ワークアラウンド的に、FORCE INDEX(USE INDEX)で凌ぐ方法もあります。(でもいつかは根本対応が必要です)
フレームワークを利用している場合、ORMがFORCE INDEXをサポートしていない場合もあります。
この場合、ORMの関数を使わず、直接SQLを記述する必要が出て来たりします。
(なので、脆弱性を埋め込まない様に注意が必要です)
- 関連記事:CakePHP実装の隙をついてFORCE INDEXを書いていた話
- ※本日のCakePHP Advent Calendarの記事です
LIKE
サービスローンチ当初はデータが少ないため、キーワード検索をSQLのLIKE文で実行しているパターンも多いかと思います。
SQLのLIKE文は、前方一致でしかインデックスが効きません。
また、単純な文字列検索なので、検索ノイズも多くなります
(例:「京都」で検索すると「東京都」もヒットしてしまう等)
データが増えてくると、LIKE文での検索はどうしても限界が来ますので、特に日本語検索の場合は、形態素解析をサポートしている全文検索エンジンを使うことになります。
代表的な全文検索エンジンとしては、SolrやElasticsearchがあります。
自前でMySQLを構築している場合は、GroongaやMySQL5.7のmecabプラグイン等、MySQLにバインディングされている全文検索エンジンを利用する手もあります。
SQLで検索できるし、DB間とのタイムラグを考える必要がほぼないという点で手軽に導入できるので、複雑な条件で利用しないのであれば良い選択になるかと思います。
おまけ
社内用ドキュメント(SQLチューニングポリシー)をエンジニアブログに投稿しましたので、こちらも合わせてどうぞ。
https://engineer.blog.lancers.jp/2018/12/sql_tuning/