Truffleでブロックチェーンアプリを作ろうと思っていたのですが、アイデアがうまく練られず、いろいろと右往左往してしまいました。
結果的にブロックチェーンアプリ案はすべて、別にブロックチェーンで実装しなくても良いようなものばっかりになったので、めんどくさくなって考えるのをやめてしまいました。。。
その過程で手書き文字の筆跡をブロックチェーンに記録して、改ざん不可能な筆跡を溜め込むブロックチェーンアプリを作ろうと思ったのですが(その有用性はさておき)、この筆跡認証のためにAzureのCustomVisionを使ったので、せっかくだしその使い方を記録しておくことにしました![]()
Custom Vision Service
CustomVisionServiceとは、Azureが提供している画像識別サービスです。
私はコードを書いて実装しましたが、アカウントを作ればweb上でプロジェクトを作成し、画像分類器を構築することができます。
ここに書くのも主にコード側の実装についてです。
プロジェクトの作成
部分的にコードの説明をしていきますが、全体のコードも最後に載せておきます。
プロジェクト名とかは筆跡認識ように作ったものを参考にしているので、Handwriting Projectになっています。
あと、実行環境は、
- Python 3.6.4
- macOS Mojave version 10.14
です。![]()
import os
import time
from azure.cognitiveservices.vision.customvision.training import CustomVisionTrainingClient
from azure.cognitiveservices.vision.customvision.training.models import ImageFileCreateEntry
ENDPOINT = "https://southcentralus.api.cognitive.microsoft.com"
# あなたのものを入れてください。
training_key = "your_training_key"
prediction_key = "prediction_ley"
trainer = CustomVisionTrainingClient(training_key, endpoint=ENDPOINT)
# プロジェクトの作成
print ("Creating project...")
project = trainer.create_project("Handwriting Project")
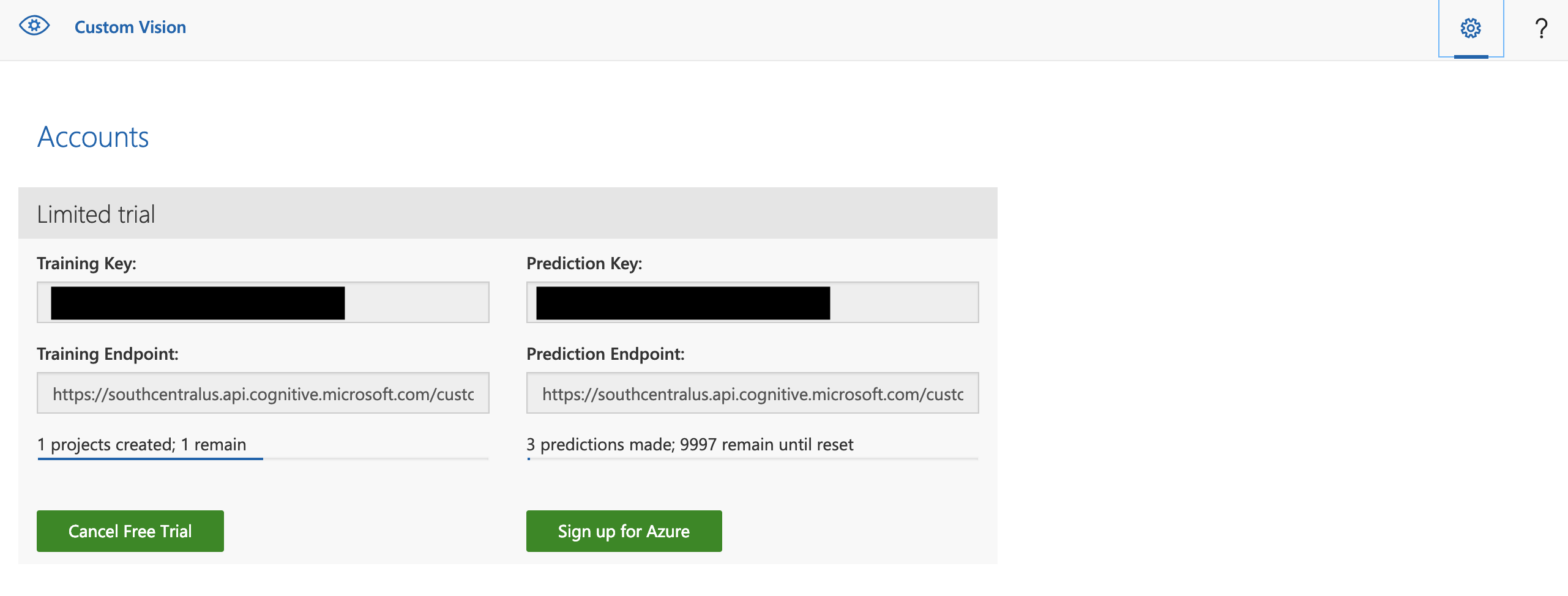
training_keyとprediction_keyは、プロジェクト画面上部の歯車ボタンを押すと出てきます。
プロジェクト内にタグを作成
プロジェクトに画像分類器のタグを作成します。
作成したタグに学習した内容を紐づけることで、ある画像を与えた時に、その画像がどのタグに属するか(その画像が何なのか)をCustomVisionServiceが返します。
bauhaus93_tag = trainer.create_tag(project.id, "bauhaus93")
bernardMT_tag = trainer.create_tag(project.id, "bernardMT")
century_tag = trainer.create_tag(project.id, "century")
engraversMT_tag = trainer.create_tag(project.id, "engraversMT")
hadassah_friedlaender_tag = trainer.create_tag(project.id, "hadassah_friedlaender")
knewave_tag = trainer.create_tag(project.id, "knewave")
typegoshi_tag = trainer.create_tag(project.id, "typegoshi")
kurei_tag = trainer.create_tag(project.id, "kurei")
bokugoshi_tag = trainer.create_tag(project.id, "bokugoshi")
totubangoshi_tag = trainer.create_tag(project.id, "totubanpgoshi")
yumin_regu_tag = trainer.create_tag(project.id, "yumin_regu")
yumin_36pokana_tag = trainer.create_tag(project.id, "yumin_36pokana")
今回私は、筆跡認識プロジェクトを使ったのですが、実際に筆跡を集めたわけではありません。
wordでフォントが異なる同一の内容の文字列を英語と日本語それぞれ6種類を作成し、各タグに5枚画像化したものを学習させました。
なので、ここではそれぞれのタグ名がフォント名になっています。
*各フォントに対応するフォントの画像を5枚にしたのは、1枚ではエラーになったからです。どこで読んだかは忘れてしまいましたが、学習時は5枚以上のデータが必要ということだったので、5枚にしています(結果エラーも解消されました)。
CostomVisionServiceに画像をインポート
それでは、上で作成したそれぞれのタグに、対応する画像を追加していきましょう。
ここで使ったプロジェクトのディレクトリは以下の通りです。
---index.py
|-prediction.py
|-training_img---en---Bauhaus---images...
| |-Bernerd MT---images...
| |-Century---images...
| |-Engravers MT---images...
| |-Hadassah FriedLaender---images...
| |-knewave---images...
|-ja---typegoshi---images...(以下省略)
上記のようにtraining_imgディレクトリ配下に画像フォルダが格納されています。
ディレクトリ構成は作る人がそれぞれ好きなようにしてくれれば良いですが、ここでは上記のようになっていることを理解した上で続きを読んでください。
# 画像が入っているディレクトリ群が存在するディレクトリ
en_base_image_url = "./training_img/en/"
ja_base_image_url = "./training_img/ja/"
# enの中のディレクトリそれぞれのパスを変数に格納
en_dir = os.listdir(en_base_image_url) # the directory list of "./training_img/en/"
bauhaus = os.listdir(en_base_image_url + "Bauhaus")
bernard = os.listdir(en_base_image_url + "Bernard MT")
century = os.listdir(en_base_image_url + "Century")
engravers = os.listdir(en_base_image_url + "Engravers MT")
hadassah = os.listdir(en_base_image_url + "Hadassah Friedlaender")
knewave = os.listdir(en_base_image_url + "Knewave")
# jaの中のディレクトリそれぞれのパスを変数に格納
ja_dir = os.listdir(ja_base_image_url) # the directory list of "./training_img/ja/"
typegoshi = os.listdir(ja_base_image_url + "typegoshi")
kurei = os.listdir(ja_base_image_url + "kurei")
bokugoshi = os.listdir(ja_base_image_url + "bokugoshi")
totubangoshi = os.listdir(ja_base_image_url + "totubangoshi")
yumin_regu = os.listdir(ja_base_image_url + "yumin_regu")
yumin_36pokana = os.listdir(ja_base_image_url + "yumin_36pokana")
def createImagesFromFiles(url, tag, dir, label):
file_name = url + dir + "/" + label
with open(file_name, mode="rb") as image_contents:
trainer.create_images_from_files(
project.id,
images=[ ImageFileCreateEntry(name=file_name, contents=image_contents.read(), tag_ids=[tag.id])])
print ("Adding images...")
# en配下のディレクトリ内の特定のフォントのディレクトリに入っている5枚の画像ををそれぞれのタグに追加
for dir in en_dir:
print(dir)
tag = None
if dir == "Bauhaus":
tag = bauhaus93_tag
for label in bauhaus:
createImagesFromFiles(en_base_image_url, tag, dir, label)
elif dir == "Bernard MT":
tag = bernardMT_tag
for label in bernard:
createImagesFromFiles(en_base_image_url, tag, dir, label)
elif dir == "Century":
tag = century_tag
for label in century:
createImagesFromFiles(en_base_image_url, tag, dir, label)
elif dir == "Engravers MT":
tag = engraversMT_tag
for label in engravers:
createImagesFromFiles(en_base_image_url, tag, dir, label)
elif dir == "Hadassah Friedlaender":
tag = hadassah_friedlaender_tag
for label in hadassah:
createImagesFromFiles(en_base_image_url, tag, dir, label)
elif dir == "Knewave":
tag = knewave_tag
for label in knewave:
createImagesFromFiles(en_base_image_url, tag, dir, label)
# ja配下のディレクトリ内の特定のフォントのディレクトリに入っている5枚の画像ををそれぞれのタグに追加
for dir in ja_dir:
print(dir)
tag = None
if dir == "typegoshi":
tag = typegoshi_tag
for label in typegoshi:
createImagesFromFiles(ja_base_image_url, tag, dir, label)
elif dir == "kurei":
tag = kurei_tag
for label in kurei:
createImagesFromFiles(ja_base_image_url, tag, dir, label)
elif dir == "bokugoshi":
tag = bokugoshi_tag
for label in bokugoshi:
createImagesFromFiles(ja_base_image_url, tag, dir, label)
elif dir == "totubangoshi":
tag = totubangoshi_tag
for label in totubangoshi:
createImagesFromFiles(ja_base_image_url, tag, dir, label)
elif dir == "yumin_regu":
tag = yumin_regu_tag
for label in yumin_regu:
createImagesFromFiles(ja_base_image_url, tag, dir, label)
elif dir == "yumin_36pokana":
tag = yumin_36pokana_tag
for label in yumin_36pokana:
createImagesFromFiles(ja_base_image_url, tag, dir, label)
それぞれのタグの画像を学習
print ("Training...")
iteration = trainer.train_project(project.id)
while (iteration.status != "Completed"):
iteration = trainer.get_iteration(project.id, iteration.id)
print ("Training status: " + iteration.status)
time.sleep(1)
# 学習完了と学習した内容の適用
trainer.update_iteration(project.id, iteration.id, is_default=True)
print ("Done!")
学習がCompletedになるまで学習を実施し続けます。
Done! が表示されれば終了です。
画像を識別させる
上記のコードたちを記述したindex.pyと同じディレクトリ内に、prediction.pyを作成して、以下のコードを書きます。
from azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient
import time
import os
ENDPOINT = "https://southcentralus.api.cognitive.microsoft.com"
training_key = "your_training_key"
prediction_key = "your_prediction_key"
project_id = "your_project_id"
predictor = CustomVisionPredictionClient(prediction_key, endpoint=ENDPOINT)
# 識別させたい画像のURL
test_img_url = "http://www.jiyu-kobo.co.jp/wp@test/wp-content/uploads/2016/02/ym_l_Pr6N_y.gif"
results = predictor.predict_image_url(project_id, url=test_img_url)
# 結果を表示
for prediction in results.predictions:
print ("\t" + prediction.tag_name + ": {0:.2f}%".format(prediction.probability * 100))
project_idは、プロジェクト画面からプロジェクトを選択して入ったページの上部にある歯車ボタンからみることができます(ページの左側に出てくると思います)。
これを実行すると、
yumin_regu: 9.26%
typegoshi: 6.53%
century: 3.89%
kurei: 2.94%
totubangoshi: 1.96%
bauhaus93: 1.55%
engraversMT: 1.44%
hadassah_friedlaender: 0.91%
yumin_36pokana: 0.80%
bokugoshi: 0.32%
knewave: 0.05%
bernardMT: 0.01%
こんな感じで結果が表示されます。
あんまり精度はよろしくない様子です。。。
もっと画像を学習させればうまくなるのかもしれませんが、私はもうこの辺でやめておきます〜![]()
web上でもこれらのプロジェクト作成から予測までを行うことができます。
qiitaで使い方を書いている人もいるのでそちらを参考にどうぞ![]()
Custom Vision Serviceを使ってみた
これも参考になりました。
クイック スタート:Custom Vision Python SDK を使用して画像分類プロジェクトを作成する
すべてのコード
改めてディレクトリ構造を載せておきます。
---index.py
|-prediction.py
|-training_img---en---Bauhaus---images...
| |-Bernerd MT---images...
| |-Century---images...
| |-Engravers MT---images...
| |-Hadassah FriedLaender---images...
| |-knewave---images...
|-ja---typegoshi---images...(以下省略)
# index.py
import os
import time
from azure.cognitiveservices.vision.customvision.training import CustomVisionTrainingClient
from azure.cognitiveservices.vision.customvision.training.models import ImageFileCreateEntry
ENDPOINT = "https://southcentralus.api.cognitive.microsoft.com"
training_key = "your_training_key"
prediction_key = "your_prediction_key"
trainer = CustomVisionTrainingClient(training_key, endpoint=ENDPOINT)
print ("Creating project...")
project = trainer.create_project("Handwriting Project")
bauhaus93_tag = trainer.create_tag(project.id, "bauhaus93")
bernardMT_tag = trainer.create_tag(project.id, "bernardMT")
century_tag = trainer.create_tag(project.id, "century")
engraversMT_tag = trainer.create_tag(project.id, "engraversMT")
hadassah_friedlaender_tag = trainer.create_tag(project.id, "hadassah_friedlaender")
knewave_tag = trainer.create_tag(project.id, "knewave")
typegoshi_tag = trainer.create_tag(project.id, "typegoshi")
kurei_tag = trainer.create_tag(project.id, "kurei")
bokugoshi_tag = trainer.create_tag(project.id, "bokugoshi")
totubangoshi_tag = trainer.create_tag(project.id, "totubangoshi")
yumin_regu_tag = trainer.create_tag(project.id, "yumin_regu")
yumin_36pokana_tag = trainer.create_tag(project.id, "yumin_36pokana")
en_base_image_url = "./training_img/en/"
ja_base_image_url = "./training_img/ja/"
# en
en_dir = os.listdir(en_base_image_url) # the directory list of "./training_img/en/"
bauhaus = os.listdir(en_base_image_url + "Bauhaus")
bernard = os.listdir(en_base_image_url + "Bernard MT")
century = os.listdir(en_base_image_url + "Century")
engravers = os.listdir(en_base_image_url + "Engravers MT")
hadassah = os.listdir(en_base_image_url + "Hadassah Friedlaender")
knewave = os.listdir(en_base_image_url + "Knewave")
# ja
ja_dir = os.listdir(ja_base_image_url) # the directory list of "./training_img/ja/"
typegoshi = os.listdir(ja_base_image_url + "typegoshi")
kurei = os.listdir(ja_base_image_url + "kurei")
bokugoshi = os.listdir(ja_base_image_url + "bokugoshi")
totubangoshi = os.listdir(ja_base_image_url + "totubangoshi")
yumin_regu = os.listdir(ja_base_image_url + "yumin_regu")
yumin_36pokana = os.listdir(ja_base_image_url + "yumin_36pokana")
def createImagesFromFiles(url, tag, dir, label):
file_name = url + dir + "/" + label
with open(file_name, mode="rb") as image_contents:
trainer.create_images_from_files(
project.id,
images=[ ImageFileCreateEntry(name=file_name, contents=image_contents.read(), tag_ids=[tag.id])])
print ("Adding images...")
for dir in en_dir:
print(dir)
tag = None
if dir == "Bauhaus":
tag = bauhaus93_tag
for label in bauhaus:
createImagesFromFiles(en_base_image_url, tag, dir, label)
elif dir == "Bernard MT":
tag = bernardMT_tag
for label in bernard:
createImagesFromFiles(en_base_image_url, tag, dir, label)
elif dir == "Century":
tag = century_tag
for label in century:
createImagesFromFiles(en_base_image_url, tag, dir, label)
elif dir == "Engravers MT":
tag = engraversMT_tag
for label in engravers:
createImagesFromFiles(en_base_image_url, tag, dir, label)
elif dir == "Hadassah Friedlaender":
tag = hadassah_friedlaender_tag
for label in hadassah:
createImagesFromFiles(en_base_image_url, tag, dir, label)
elif dir == "Knewave":
tag = knewave_tag
for label in knewave:
createImagesFromFiles(en_base_image_url, tag, dir, label)
for dir in ja_dir:
print(dir)
tag = None
if dir == "typegoshi":
tag = typegoshi_tag
for label in typegoshi:
createImagesFromFiles(ja_base_image_url, tag, dir, label)
elif dir == "kurei":
tag = kurei_tag
for label in kurei:
createImagesFromFiles(ja_base_image_url, tag, dir, label)
elif dir == "bokugoshi":
tag = bokugoshi_tag
for label in bokugoshi:
createImagesFromFiles(ja_base_image_url, tag, dir, label)
elif dir == "totubangoshi":
tag = totubangoshi_tag
for label in totubangoshi:
createImagesFromFiles(ja_base_image_url, tag, dir, label)
elif dir == "yumin_regu":
tag = yumin_regu_tag
for label in yumin_regu:
createImagesFromFiles(ja_base_image_url, tag, dir, label)
elif dir == "yumin_36pokana":
tag = yumin_36pokana_tag
for label in yumin_36pokana:
createImagesFromFiles(ja_base_image_url, tag, dir, label)
print ("Training...")
iteration = trainer.train_project(project.id)
while (iteration.status != "Completed"):
iteration = trainer.get_iteration(project.id, iteration.id)
print ("Training status: " + iteration.status)
time.sleep(1)
trainer.update_iteration(project.id, iteration.id, is_default=True)
print ("Done!")
# prediction.py
from azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient
import time
import os
ENDPOINT = "https://southcentralus.api.cognitive.microsoft.com"
training_key = "your_training_key"
prediction_key = "your_prediction_key"
project_id = "your_project_id"
predictor = CustomVisionPredictionClient(prediction_key, endpoint=ENDPOINT)
test_img_url = "image_url"
results = predictor.predict_image_url(project_id, url=test_img_url)
for prediction in results.predictions:
print ("\t" + prediction.tag_name + ": {0:.2f}%".format(prediction.probability * 100))
興味があったら使ってみてください、簡単なので![]()