はじめに
私が自分のPCでGPU Learningしようとしてセットアップで四苦八苦していた際に、AWSからDeep Learning Base AMIなるものが昨年11月に出ていたと知り、試した所非常に簡単に学習まで行うことが出来たのでそのやり方についてまとめました。
Deep Learning Base AMI
Deep Learning Base AMIはセットアップやパスの設定がめんどい、NVIDIA driver, CUDA, CuDNN, Python, etc...が最初から入ってるAMIです。
UbuntuかLinux版があり、主要フレームワーク(MXNet, TensorFlow, Caffe2, PyTorch, Theano, CNTK, Keras)がプリインストールされてるAMIもあります。

料金
- EC2インスタンス稼働時の料金 + EBSの料金
- p2.xlargeが$0.900/hr(us-east)で、平均1日3時間程起動 + EBSの料金で1ヶ月3000円程でした。(300円/1dayくらい)
- 自分の場合はEIPを使用せず、こまめに停止させてたので参考までに。
どうしてUbuntu?
- UbuntuだとCUDA関連のパスも既に設定済みのため。
- Linuxだと自分で記述の必要あり。
- Linuxだと
pip install cupyでRuntimeError: maximum recursion depth exceeded while calling a Python objectとなり詰まる。- 色々調べたが解決できなかった
- (解決方法分かる方は教えて頂けると幸いです🙇)
環境構築
今回作成するインスタンスの設定は以下です。
| 設定項目 | 値 |
|---|---|
| リージョン | us-east(バージニア北部) |
| AMI | Deep Learning Base AMI (Ubuntu) - ami-10ef8d6a |
| インスタンスタイプ | p2.xlarge |
EC2インスタンスの作成
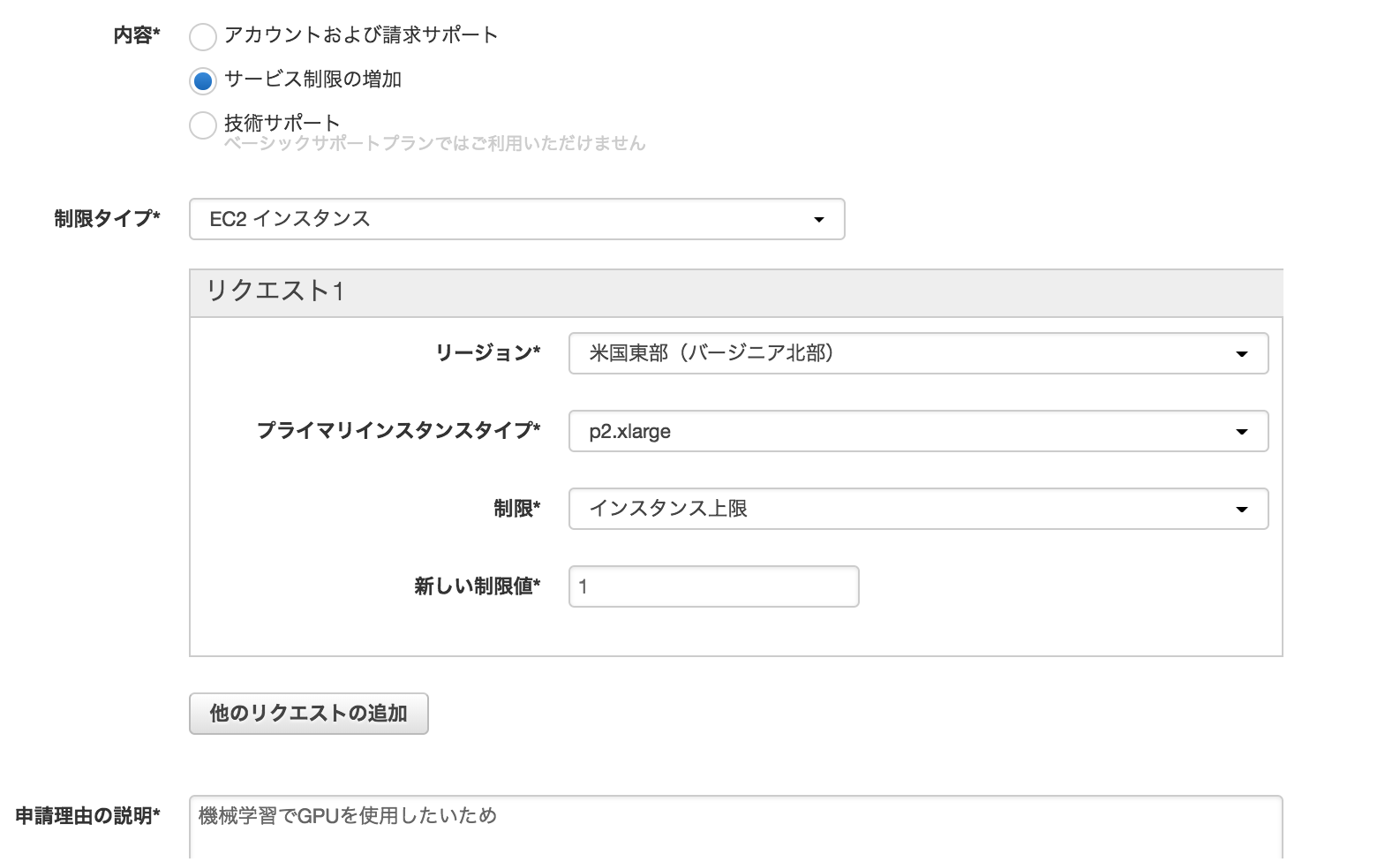
制限緩和リクエストを送る
おそらくデフォルトだと、p2, p3インスタンスの作成制限が「0」となっており、作成できません。
そのため作成するには、(https://console.aws.amazon.com/ec2/v2/home?region=us-east-1#Limits:) から制限緩和リクエストを送る必要があります。
制限緩和リクエストについては日本語大丈夫ですが、承認まで1~2日ほどかかりました。
EC2インスタンスを新規作成。
EC2のマネジメントコンソール画面(https://console.aws.amazon.com/ec2/) からインスタンスの作成を選択。

使用するAMIを選択。

インスタンスタイプを選択。
とりあえずGPU Learningがしたかったため、最も安いp2.xlargeを選択。

機械学習用途だと、p2かp3になりますが、p3の方が優れていてお高いです。
Amazon EC2 P2 インスタンス| AWS
P2 インスタンスでは、最大で 16 個の NVIDIA K80 GPU、64 個の vCPU、および 732 GiB のホストメモリを、192 GB の GPU メモリ、4 万件の並列処理コア、70 テラフロップの単精度浮動小数点数演算、および 23 テラフロップスを超える倍精度浮動小数点数演算と組み合わせて利用できます。
Amazon EC2 P3 (英語ページだったのでGoogle翻訳を載せます。)
最大8つのNVIDIA Tesla V100 GPUを搭載したP3インスタンスは、1ペタフロップの混在精度、125テラフロップの単精度、および62テラフロップの倍精度浮動小数点性能を提供します。P3インスタンスには、カスタムIntel Xeon E5(Broadwell)プロセッサーと488 GB DRAMをベースにして、最大64のvCPUが搭載されています。
他の設定はそのままで特に問題ないです。
キーペアの作成も行えば無事インスタンスが立ち上がるはずです。
接続
$ ssh -i /path/my-key-pair.pem user_name@public_ip
user_nameはLinuxだとec2-user、Ubuntuだとubuntuです。
public_ipはインスタンス画面下部の説明タブにある「IPv4 パブリック IP」です。
Are you sure you want to continue connecting (yes/no)? のようなメッセージがでたらyesで良いです。
CUDA関連のパスも既に設定済み!!
GPU学習環境を構築するには、PATHやLD_LIBRARY_PATHやCUDA_PATHやら設定する必要がありますが、すでにされているためこちらから弄る必要はありません。
デフォルトではCUDA 9環境のため、もしCUDA 8に切り替えたい場合はLD_LIBRARY_PATHを修正して下さい。
AWS Deep Learning Conda と Base AMI の利用開始について | Amazon Web Services ブログ - 新しい Deep Leaning Base AMI の設定
環境変数 LD_LIBRARY_PATH を再設定することで CUDA 8 環境に切り替えることも可能です。環境変数の文字列の CUDA 9 の箇所を CUDA 8 に相当するものに置換するだけです。
Chainer + Cupyのインストール
| 名前 | バージョン |
|---|---|
| Python | 2.7.12 or 3.5.2 |
| Chainer | 3.2.0 |
| Cupy | 2.2.0 |
コマンドは使いたいPythonのバージョンで適宜読み替えて下さい。
Python2系の場合はpython, pip、Python3系の場合はpython3, pip3になります。
ubuntu@ip-xx:$ sudo pip3 install chainer
Chainer v3からかインストールと一緒にcupyが入らなくなってます。なのでこちらからcupyをインストールしてあげます。(数分かかります)
ubuntu@ip-xx:$ sudo pip3 install cupy
MINSTサンプルで確認
GPU Learningが出来るかMINSTサンプルで確認して下さい。
ubuntu@ip-xx:$ wget https://raw.githubusercontent.com/chainer/chainer/v3/examples/mnist/train_mnist.py
このまま実行すると、ImportError: No module named '_tkinter', please install the python3-tk packageとなるので必要なmoduleをいれます。
ubuntu@ip-xx:$ sudo apt-get install python3-tk
matplotlib関係の設定が必要なため設定します。
ubuntu@ip-xx:$ vi .config/matplotlib/matplotlibrc
backend : Agg
これで実行してエラーなく動作すれば大丈夫です。
ubuntu@ip-xx:$ python3 train_mnist.py -g 0
うまくいかない場合はコメント等で指摘して頂けると助かります🙇