MIT scene parsing論文のまとめです。
画像は全て論文から引っ張ってきました。
Scene Parsing through ADE20K Dataset. B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso and A. Torralba. Computer Vision and Pattern Recognition (CVPR), 2017. PDF
ある画像を見て、ここは木だここは空だここはソファーだ、と認識させることは極めて難しいことだ。
ましてや、画像を見てラベルやbounding boxを出力するだけでなく、1 pixelごとに1ラベルを出力するsegmentationについて紹介する。
ユースケース
- ロボットに空間を正しく認識させた上で、操作を行う
- 画像から人/車/etcを自動で消したい場合
- 画像の合成

課題: dataset & annotation
そもそも多様な画像(都市だけじゃない、家の中だけじゃない、etc)を集めたデータセットが貴重である。
また、1 pixelごとに1ラベルを出力するため、annotationは鬼のように面倒である。
- Cityscapes: City scenes only
- Pascal-Context: 20 object classes
- SUN database
- ADE20K: 150 object classes (論文で紹介されたデータセット)

論文から抜粋したfigure。めっちゃ細かい。
annotationがそもそも難しい件
Objectの間にヒエラルキーが存在する (例えばrimはwheelの一部で、ドアノブはドアの一部)が、ADE20Kの場合、3階層までのヒエラルキーを作りアノテーションさせているとか。すごい。
また、壁に絵がかかっている場合はどうラベルを作るか。ADE20KはCascade Segmentation Moduleを使い、今まで無視されてきたオブジェクト間の空間的関係性を踏まえてsegmentationを行なっている。以下の3つの大分類に分けている:
- stuff (sky, road, building, etc)
- foreground objects (car, tree, sofa, etc)
- object parts (car wheels and door, people head and torso, etc)
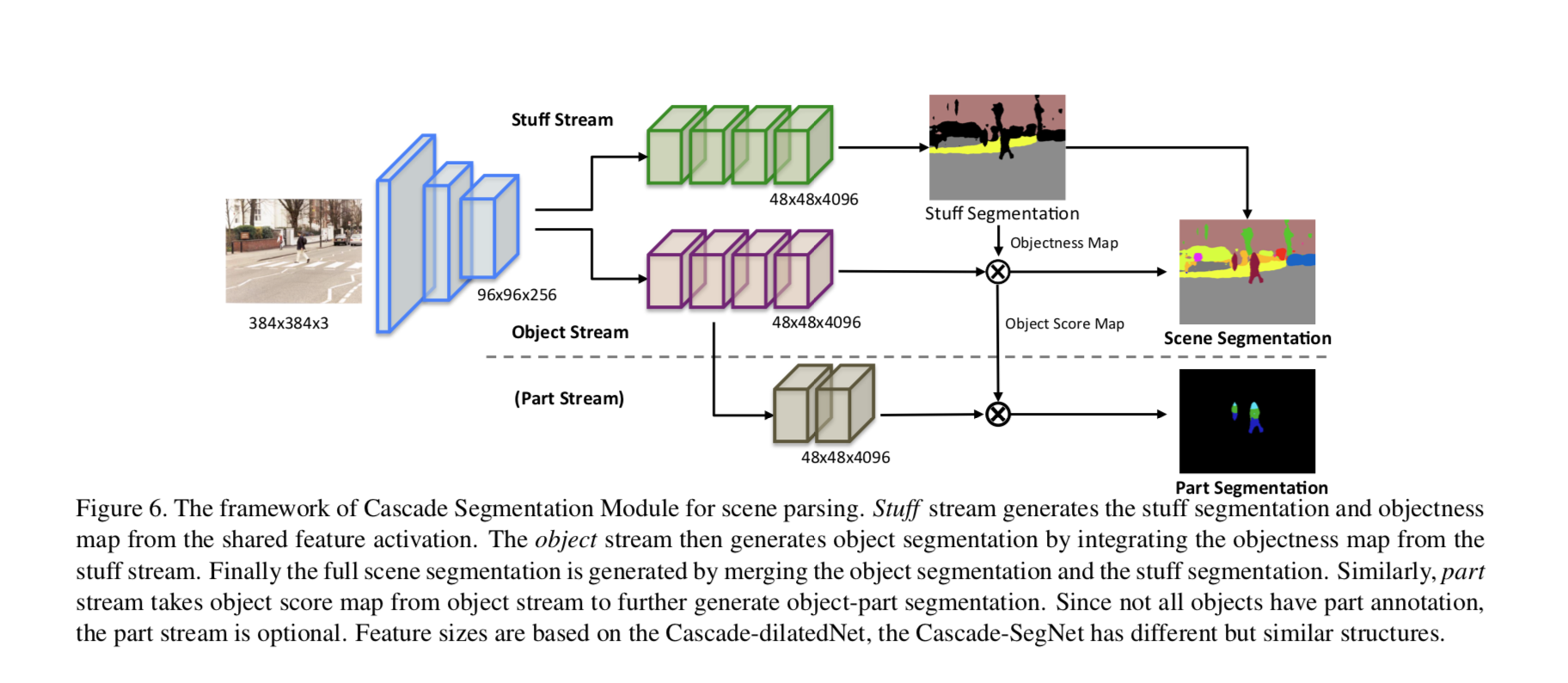
画像のように、3つの大分類に合わせて、3つのsegmentation streamを最終的に合わせる形でやっている。