0.はじめに
初めまして、中国から参りましたポンです。
今は野村総合研究所で働いている新人エンジニアです。
日本語がまだ下手ですから、もし変な日本語が入りましたらご容赦ください。
どうぞよろしくお願いいたします。
コロナ時期の旅行写真には、白いマスクが多すぎで、
もう我慢できないですよね?
ちょうど今は新人開発研修があって、これを研修の課題にしました。
これを解決するため、写真中の白いマスクを怪人マスクに変換するアプリケーションを開発しました。
「できるだけ作業量を減らす」というコンセプトに基づいて、
AWSの色々なサービスを活用してサーバレスLINE写真処理アプリとして開発しました。
マスクだらけの写真にうんざりした方も、サーバレスに興味ある方も、
ぜひ、この開発記をお楽しみください。
1.なぜこのアプリを開発?

筆者は夏休みの時に、彼女と千葉の銚子に旅行しました。
海で遊んだり、灯台を登ったり記念写真をいっぱい撮りました。
でも残念ですけど、写真の主役は人間または景色ではなく、白いマスクでした。
コロナ時代(時期)の写真は、白いマスクの出現率が一番高くて、どこでも登場しています。
こんな写真を見た彼女は、「もう白いマスクを見たくない」の文句が出てきた、じゃ写真中の白いマスクをほかのものに変換すればどうでしょう?
ちょうど筆者も彼女も、スーパーヒーロー映画が好きで、その中の怪人マスク(e.g. バットマンの怪人Bane)が大好きです。
もし白いマスクが怪人マスクになればいいんじゃないですか?
 ※This work is a derivative of "[Bane](https://www.flickr.com/photos/istolethetv/30216006787/)" by [istolethetv](https://www.flickr.com/people/istolethetv/), used under [CC BY 2.0](https://creativecommons.org/licenses/by/2.0/)
※This work is a derivative of "[Bane](https://www.flickr.com/photos/istolethetv/30216006787/)" by [istolethetv](https://www.flickr.com/people/istolethetv/), used under [CC BY 2.0](https://creativecommons.org/licenses/by/2.0/)
そういうことから、アイデアが生まれてきて、この写真処理アプリを開発することを決めました。
でも目の前に3つの問題が存在しています。
- どんなアプリケーション形態にする?
- どこでサーバーを立てる?
- どうやって画像認識システムを作る?
まず、アプリケーション形態について、色々な選択肢が存在しています。
WebページとしてのWebアプリ?スマホ専用のiosまたはandroidアプリ?
バックエンドの処理だけではなく、フロントエンドのインタフェースも設計しなければなりませんね。
色々考えて、やはりLINEアプリが一番適切だと思います。
理由が3つあります:
- 使いやすい:ほぼ誰でもLINE持っていて、LINEアプリ(bot)なら送信受信だけですごく簡単で、だれでも使えます。
- 作業量は少ない:Webアプリやiosアプリなら、インターフェースのデザインなども入って、正直言ってめんどくさいです。でもLINEアプリならそれらを考えなくてもいい、楽になります。
- シェアしやすい:SNSの特徴といえば共有しやすいですね。変換した写真だけではなく、このアプリもシェアされやすくなれます。
そこで、アプリケーション形態はLINEアプリと決めました!
そして次の課題は、どこでサーバーを立てるかです
Raspberry piなどの物理マシンで構築するか?AWS EC2などのクラウドサーバーを利用するか?
また、サーバーは構築だけではなく、後の保守管理も必要です。
「できるだけ作業量を減らす」という理念を持っているlazyな私は、それをしたくないですね。。。
じゃ、サーバーを要らなく、サーバレスで開発すればいいじゃないですか?
調べると、AWS API GatewayとLambdaを使ったら、サーバレスを実現でき、サーバー構築と保守管理は一切なし!
よーし、君に決めた!!
最後、今回は顔写真を処理するため、顔認識AIが必要です。
それで、「どんなAIモデル構造を使う?」、「訓練データどこから入手する?」や「データにどんなラベルを付ける?」などの問題がどんどん出てきました。
「すぐ使える顔認識AIがあればいいなぁ」と思ってAWSで調べてみて、結果は本当に出てきました!
Rekognition(recognitionではない)という画像または動画を分析するAWSサービスが存在します。
AIを作る必要がなく、Rekognitionをコールだけで、写真の顔の認識と分析ができます。
これで、「できるだけ作業量を減らす」が達成できます。

こういうことで、AWSでサーバレスLINE写真処理アプリを開発と決めました!
2.システム全体像
アプリケーション形態などはすでに決めましたので、これからシステムを構築しましょう!
今回作ったシステムの全体像は以下です:
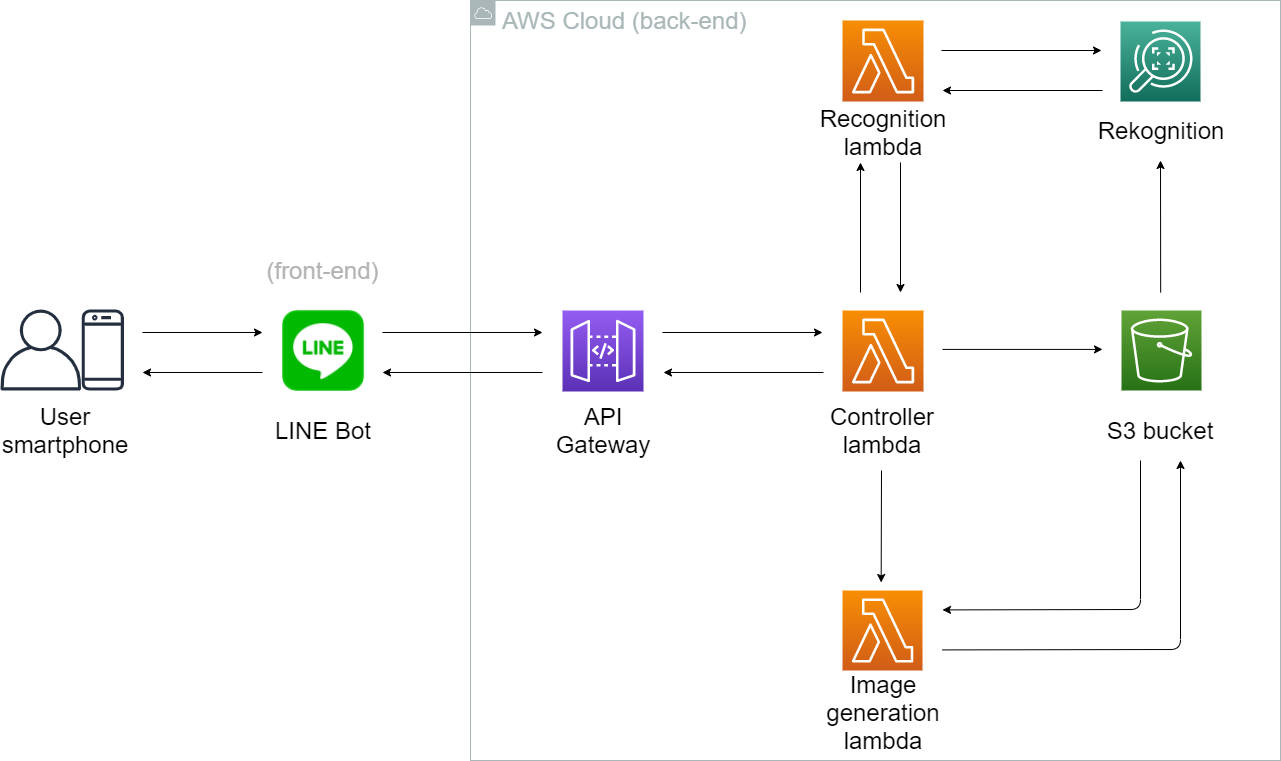
ここでユーザとのやり取りはスマホと想定しています。(PC版LINEもできます)
フロントエンドはLINE Botです。
バックエンドは全部AWS Cloudで処理を行っています。
サーバレスを実現するため、処理は「コントローラー」、「顔認識」と「新画像生成」3つのLambda に実行されています。
処理の流れから考えると、このシステムは以下の図のように5つ部分に分けられます:
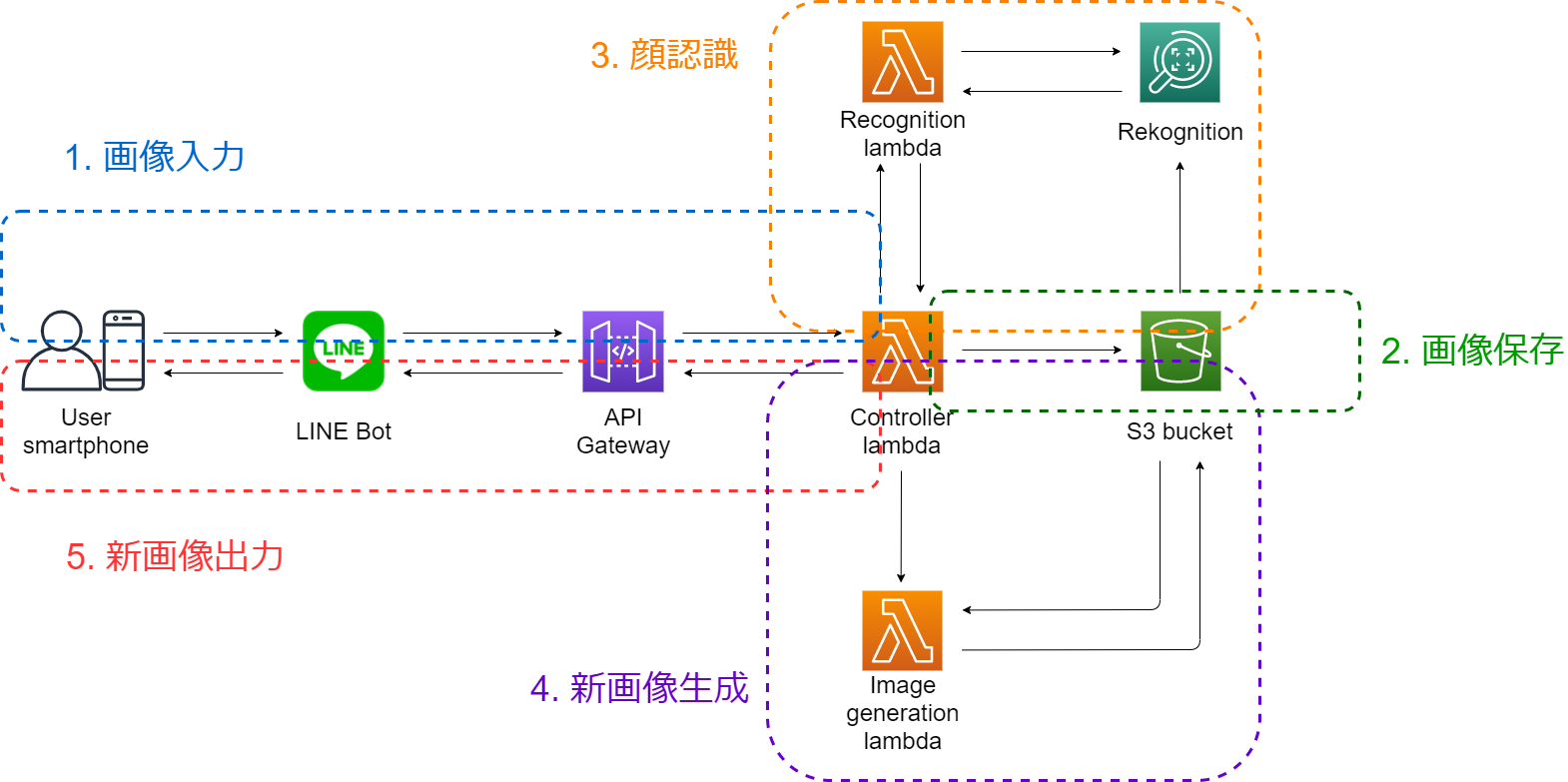
それでは、処理の流れから、この5つ部分を説明いたします。
3.部分ごとの説明
3-1 画像入力部分
処理の流れ
第1部分は入力部分です。
機能は文字通りで、ユーザがLINE Bot に送信した画像を読み込むことです。
この部分に関するエンティティは「LINE Bot」、「API Gateway」および「コントローラーLambda 」です。
処理の流れは以下となっております:

まず、ユーザが写真画像をLINE Botに送信します。
そしてLINE Botが画像をline_eventにラッピングして、API Gatewayに送ります。
API Gatewayは何も変更せずに、eventをコントローラーLambdaに送ります。
LINE Bot作成
この部分を作るために、まず玄関としてのLINE Bot(messagingApi)を作成。
作り方はこちらをご参照ください:
LINE公式ドキュメント:Messaging APIを始めよう
チャンネルを作成した後に、必要な設定はまだ2つあります。
1つ目はLambdaでの認証のため、「チャンネルアクセストークン」を発行することです。
2つ目はmessaging apiの応答機能をoff、webhook機能をonすることです。
webhook URLは今入力しなくて、API Gatewayの設定が終わった後に入力します。
コントローラーLambdaを作成
次はLambdaなどのサービスを実行するIAMロールの作成です。
ダッシュボードからIAMサービスを入って、新しいロールを作ります。
新しいIAMロールはserverless-linebotなどをネーミングして、使うサービスはLambdaです。
ポリシーは「AmazonS3FullAccess」、「AmazonRekognitionFullAccess」、「CloudWatchLogsFullAccess」です。
またコントローラーLambdaがほかのLambdaを呼び出すのため、以下のポリシーも追加します:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction",
"lambda:InvokeAsync"
],
"Resource": [
"顔認識Lambdaのarn",
"新画像生成Lambdaのarn"
]
}
]
}
ここの「顔認識Lambdaのarn」と「新画像生成Lambdaのarn」はまだないですから、Lambda関数を作成した後に書き換えを忘れないでください。
今回の処理は全部このロールで実行します。
コントローラーLambda関数を作成
API Gatewayは「繋がり」ですから、それを作る前に両端のLINE BotとコントローラーLambda関数を作らなければないので、次はコントローラーLambda関数を作成します。
関数作成に、今回はpythonを使うため、ランタイムをpython3.x(3.6~3.8)を選択します。
実行するIAMロールは先ほど作ったロールです。
作成した後に、まずは「基本設定」で、メモリを512MBで、タイムアウトを1minのように設定します。
そして以下の環境変数を設定します:
| キー | 値 |
|---|---|
| LINE_CHANNEL_ACCESS_TOKEN | LINE Botのチャンネルアクセストークン |
| LINE_CHANNEL_SECRET | LINE Botのチャンネルシークレット |
Lambda関数の中身について、コントローラーLambdaはLINE Botとのやり取りが行いますので、「line-bot-sdk」パッケージが必要です。
Lambdaに導入するため、まずローカルで以下のコマンドを用いて、新フォルダにline-bot-sdkをインストールします:
python -m pip install line-bot-sdk -t <new_folder>
後同じフォルダにlambda_function.py(Lambdaはこの名前で「これがメインファンクション」と認識するので、必ずこの名前)ファイルを作って、以下のコードを記入ます:
import os
import sys
import logging
import boto3
import json
from linebot import LineBotApi, WebhookHandler
from linebot.models import MessageEvent, TextMessage, TextSendMessage, ImageMessage, ImageSendMessage
from linebot.exceptions import LineBotApiError, InvalidSignatureError
logger = logging.getLogger()
logger.setLevel(logging.ERROR)
# 環境変数からline botのチャンネルアクセストークンとシークレットを読み込む
channel_secret = os.getenv('LINE_CHANNEL_SECRET', None)
channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None)
if channel_secret is None:
logger.error('Specify LINE_CHANNEL_SECRET as environment variable.')
sys.exit(1)
if channel_access_token is None:
logger.error('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.')
sys.exit(1)
# api&handlerを生成
line_bot_api = LineBotApi(channel_access_token)
handler = WebhookHandler(channel_secret)
# S3バケットとつながる
s3 = boto3.client("s3")
bucket = "<S3バケット名>"
# Lambdaのメインファンクション
def lambda_handler(event, context):
# 認証用のX-Line-Signatureヘッダー
signature = event["headers"]["X-Line-Signature"]
body = event["body"]
# リターン値の設定
ok_json = {"isBase64Encoded": False,
"statusCode": 200,
"headers": {},
"body": ""}
error_json = {"isBase64Encoded": False,
"statusCode": 403,
"headers": {},
"body": "Error"}
@handler.add(MessageEvent, message=ImageMessage)
def message(line_event):
# ユーザのプロフィール
profile = line_bot_api.get_profile(line_event.source.user_id)
# 送信したユーザのIDを抽出(push_messageなら使う, replyなら必要ない)
# user_id = profile.user_id
# メッセージIDを抽出
message_id = line_event.message.id
# 画像ファイルを抽出
message_content = line_bot_api.get_message_content(message_id)
content = bytes()
for chunk in message_content.iter_content():
content += chunk
# 画像ファイルを保存
key = "origin_photo/" + message_id
new_key = message_id[-3:]
s3.put_object(Bucket=bucket, Key=key, Body=content)
# 顔認識lambdaを呼び出し
lambdaRekognitionName = "<ここは顔認識lambdaのarn>"
params = {"Bucket": bucket, "Key": key} # 画像ファイルのパス情報
payload = json.dumps(params)
response = boto3.client("lambda").invoke(
FunctionName=lambdaRekognitionName, InvocationType="RequestResponse", Payload=payload)
response = json.load(response["Payload"])
# 新画像生成lambdaを呼び出し
lambdaNewMaskName = "<ここは新画像生成lambdaのarn>"
params = {"landmarks": str(response),
"bucket": bucket,
"photo_key": key,
"new_photo_key": new_key}
payload = json.dumps(params)
boto3.client("lambda").invoke(FunctionName=lambdaNewMaskName,
InvocationType="RequestResponse", Payload=payload)
# 署名付きURL生成
presigned_url = s3.generate_presigned_url(ClientMethod="get_object", Params={
"Bucket": bucket, "Key": new_key}, ExpiresIn=600)
# 新画像メッセージの返信
line_bot_api.reply_message(line_event.reply_token, ImageSendMessage(
original_content_url=presigned_url, preview_image_url=presigned_url))
try:
handler.handle(body, signature)
except LineBotApiError as e:
logger.error("Got exception from LINE Messaging API: %s\n" % e.message)
for m in e.error.details:
logger.error(" %s: %s" % (m.property, m.message))
return error_json
except InvalidSignatureError:
return error_json
return ok_json
上のはコントローラーLambda関数の全体で、すべての5つ部分と関連しています。
この第1部分に関するパートは以下です:
- LINE Botと繋がり
# 環境変数からline botのチャンネルアクセストークンとシークレットを読み込む
channel_secret = os.getenv('LINE_CHANNEL_SECRET', None)
channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None)
if channel_secret is None:
logger.error('Specify LINE_CHANNEL_SECRET as environment variable.')
sys.exit(1)
if channel_access_token is None:
logger.error('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.')
sys.exit(1)
# api&handlerを生成
line_bot_api = LineBotApi(channel_access_token)
handler = WebhookHandler(channel_secret)
- イベントからlinebot署名とbody内容を受け取る
# 認証用のX-Line-Signatureヘッダー
signature = event["headers"]["X-Line-Signature"]
body = event["body"]
これで、LINE Botの認証とイベント内容の受け取るができました。
後はそのフォルダの内容をzipに圧縮して、
Lambdaの「関数コード」→「アクション」→「.zipファイルをアップロード」でアップロードします。
API Gatewayを作成
最後は繋がりとしてのAPI Gatewayの作成です。
ここ作成するAPI Gatewayの種類はREST APIです。
APIを作成した後に、リソースとメソッドを作成します。
メソッドはPOST方式で、統合タイプはLambda関数で、Lambdaプロキシ統合の使用も有効化にします。
Lambda関数はコントローラーLambda関数を選択します。
あと、POSTメソッドリクエストの設定について、
まずリクエストの認証は「クエリ文字列パラメータおよびヘッダーの検証」を選択します。
そしてHTTPリクエストヘッダーには以下のヘッダーを追加します:
| 名前 | 必須 | キャッシュ |
|---|---|---|
| X-Line-Signature | ☑ | ☐ |
設定できたらデプロイしましょう。
デプロイ完了したら、ステージでメソッドの呼び出しURLをコピーして、
LINE Botのwebhook URLに貼り付けます。
これで第1部分が完了します。
3-2 画像保存部分
処理の流れ
第2部分は画像保存部分です。
この部分はすごく簡単で、ただコントローラーLambda読み込んだ画像をS3バケットに保存するだけです。
処理の流れは以下です:

S3バケットを作成
作業内容について、まずはS3バケットを作成します。
今回のプロジェクトにおいて、バケット名が長すぎると「署名付きURL長さ問題」が起きるため(詳細は3-5)、
バケット名はできれば短くします(私の場合は英4文字)。
また、自分の写真を他人に見られたくないですよね?
プライバシーを保護するため、
アクセス許可の設定に「パブリックアクセスをすべてブロック」をチェックして、バケットを作成します。
作成した後に、「origin_photo」というユーザがアップした写真を保存するフォルダと、
「masks」というマスク画像を保存するフォルダを作成します。
これで、S3側の作業が終わります。
コントローラーLambda関数
コントローラーLambda関数は第1部分に記入したため、ここでの作業は特にありません。
ただこの部分に関するコード説明して、内容は以下です:
- バケットを指定
# S3バケットとつながる
s3 = boto3.client("s3")
bucket = "<S3バケット名>"
- イベントから画像ファイルを抽出して保存する
# メッセージIDを抽出
message_id = line_event.message.id
# 画像ファイルを抽出
message_content = line_bot_api.get_message_content(message_id)
content = bytes()
for chunk in message_content.iter_content():
content += chunk
# 画像ファイルを保存
key = "origin_photo/" + message_id
new_key = message_id[-3:]
s3.put_object(Bucket=bucket, Key=key, Body=content)
ここはLINEメッセージIDで画像ファイルをリネームして、
複数ユーザが区別できるようになります。
3-3 顔認識部分
第3部分は保存した写真の認識です。
具体的には顔の輪郭や目と鼻の位置を認識して、後のマスク画像と結合に使います。
「できるだけ作業量を減らす」というコンセプトを持って、
自分でゼロから顔認識AIを訓練したくないですから、
AWSの「Rekognition」というサービスを使って顔を認識します。
Rekognitionとは
Rekognitionは「機械学習を使用して画像と動画の分析を自動化する」サービスであり、
簡単に言うと「訓練されたAIをそのまま使う」感じです。
Rekognitionについての紹介はこちらです:
Amazon Rekognition
Rekognitionはオブジェクトとシーンの検出や顔の比較などいろいろな機能があって、画像だけでなくビデオも処理できます。
今回は顔の位置を得るため、「顔の分析(face-detection)」機能を使います。
取得したい位置情報は「ランドマーク」と呼ばれます。
下の図はランドマークのイメージです:

※出典:https://docs.aws.amazon.com/ja_jp/rekognition/latest/dg/faces-detect-images.html
この図の分析結果:
Rekognition認識結果
{
"FaceDetails": [
{
"AgeRange": {
"High": 43,
"Low": 26
},
"Beard": {
"Confidence": 97.48941802978516,
"Value": true
},
"BoundingBox": {
"Height": 0.6968063116073608,
"Left": 0.26937249302864075,
"Top": 0.11424895375967026,
"Width": 0.42325547337532043
},
"Confidence": 99.99995422363281,
"Emotions": [
{
"Confidence": 0.042965151369571686,
"Type": "DISGUSTED"
},
{
"Confidence": 0.002022328320890665,
"Type": "HAPPY"
},
{
"Confidence": 0.4482877850532532,
"Type": "SURPRISED"
},
{
"Confidence": 0.007082826923578978,
"Type": "ANGRY"
},
{
"Confidence": 0,
"Type": "CONFUSED"
},
{
"Confidence": 99.47616577148438,
"Type": "CALM"
},
{
"Confidence": 0.017732391133904457,
"Type": "SAD"
}
],
"Eyeglasses": {
"Confidence": 99.42405700683594,
"Value": false
},
"EyesOpen": {
"Confidence": 99.99604797363281,
"Value": true
},
"Gender": {
"Confidence": 99.722412109375,
"Value": "Male"
},
"Landmarks": [
{
"Type": "eyeLeft",
"X": 0.38549351692199707,
"Y": 0.3959200084209442
},
{
"Type": "eyeRight",
"X": 0.5773905515670776,
"Y": 0.394561767578125
},
{
"Type": "mouthLeft",
"X": 0.40410104393959045,
"Y": 0.6479480862617493
},
{
"Type": "mouthRight",
"X": 0.5623446702957153,
"Y": 0.647117555141449
},
{
"Type": "nose",
"X": 0.47763553261756897,
"Y": 0.5337067246437073
},
{
"Type": "leftEyeBrowLeft",
"X": 0.3114689588546753,
"Y": 0.3376390337944031
},
{
"Type": "leftEyeBrowRight",
"X": 0.4224424660205841,
"Y": 0.3232649564743042
},
{
"Type": "leftEyeBrowUp",
"X": 0.36654090881347656,
"Y": 0.3104579746723175
},
{
"Type": "rightEyeBrowLeft",
"X": 0.5353175401687622,
"Y": 0.3223199248313904
},
{
"Type": "rightEyeBrowRight",
"X": 0.6546239852905273,
"Y": 0.3348073363304138
},
{
"Type": "rightEyeBrowUp",
"X": 0.5936762094497681,
"Y": 0.3080498278141022
},
{
"Type": "leftEyeLeft",
"X": 0.3524211347103119,
"Y": 0.3936865031719208
},
{
"Type": "leftEyeRight",
"X": 0.4229775369167328,
"Y": 0.3973258435726166
},
{
"Type": "leftEyeUp",
"X": 0.38467878103256226,
"Y": 0.3836822807788849
},
{
"Type": "leftEyeDown",
"X": 0.38629674911499023,
"Y": 0.40618783235549927
},
{
"Type": "rightEyeLeft",
"X": 0.5374732613563538,
"Y": 0.39637991786003113
},
{
"Type": "rightEyeRight",
"X": 0.609208345413208,
"Y": 0.391626238822937
},
{
"Type": "rightEyeUp",
"X": 0.5750962495803833,
"Y": 0.3821527063846588
},
{
"Type": "rightEyeDown",
"X": 0.5740782618522644,
"Y": 0.40471214056015015
},
{
"Type": "noseLeft",
"X": 0.4441811740398407,
"Y": 0.5608476400375366
},
{
"Type": "noseRight",
"X": 0.5155643820762634,
"Y": 0.5569332242012024
},
{
"Type": "mouthUp",
"X": 0.47968366742134094,
"Y": 0.6176465749740601
},
{
"Type": "mouthDown",
"X": 0.4807897210121155,
"Y": 0.690782368183136
},
{
"Type": "leftPupil",
"X": 0.38549351692199707,
"Y": 0.3959200084209442
},
{
"Type": "rightPupil",
"X": 0.5773905515670776,
"Y": 0.394561767578125
},
{
"Type": "upperJawlineLeft",
"X": 0.27245330810546875,
"Y": 0.3902156949043274
},
{
"Type": "midJawlineLeft",
"X": 0.31561678647994995,
"Y": 0.6596118807792664
},
{
"Type": "chinBottom",
"X": 0.48385748267173767,
"Y": 0.8160444498062134
},
{
"Type": "midJawlineRight",
"X": 0.6625112891197205,
"Y": 0.656606137752533
},
{
"Type": "upperJawlineRight",
"X": 0.7042999863624573,
"Y": 0.3863988518714905
}
],
"MouthOpen": {
"Confidence": 99.83820343017578,
"Value": false
},
"Mustache": {
"Confidence": 72.20288848876953,
"Value": false
},
"Pose": {
"Pitch": -4.970901966094971,
"Roll": -1.4911699295043945,
"Yaw": -10.983647346496582
},
"Quality": {
"Brightness": 73.81391906738281,
"Sharpness": 86.86019134521484
},
"Smile": {
"Confidence": 99.93638610839844,
"Value": false
},
"Sunglasses": {
"Confidence": 99.81478881835938,
"Value": false
}
}
]
}
今回取得したいのはこの中の「landmarks」項目です。
「Type」は点の名前です(上のイメージ図を参照)。
ただし、xとyは具体的なピクセル点の座標ではなく、
画像の幅に対する比率を表しています。
処理の流れ
第3部分の処理の流れは以下となっています:
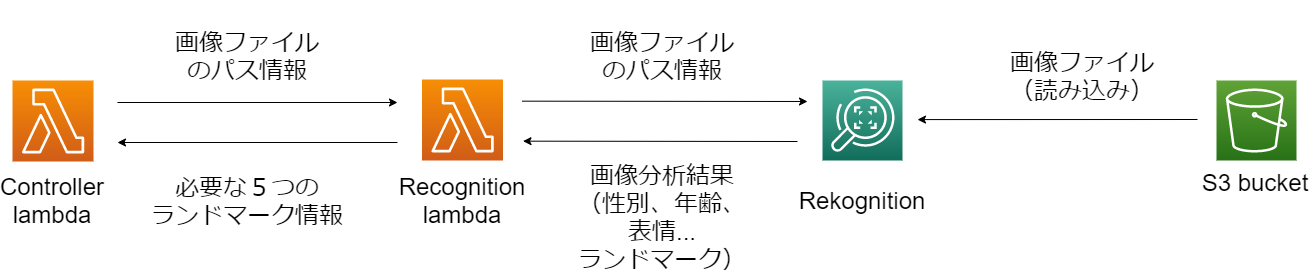
Rekognitionは画像を読み込む仕組みが2つあります。
1つ目はS3バケット又はインターネット上の画像URLを用いて読み込みます。
2つ目はファイルを送って直接読み込みます。
今回は1つ目のURL方法を使います。
そのため、コントローラーLambdaから顔認識Lambdaに渡すのは画像ではなく、ファイルの保存位置情報です。
顔認識LambdaがRekognitionに渡すのも同じです。
ここで顔認識Lambdaを実行するIAMロールは第1部分に作ったロールです。
S3とRekognitionを使う権限が持ってますので、
S3バケットが非公開でも、Rekognitionがその中の画像を読み込めて問題ないです。
そして、Rekognitionからリターンされる結果は上の結果の例みたいです。
その中に「年齢」や「性別」など色々入ってますが、
今回使いたいのは「ランドマーク」だけです。
そのため、顔認識Lambdaがその結果からランドマークを抽出します。
また、ランドマークもいっぱいありまして、
マスクのせいでうまく認識できない点(口など)もあるし、細かすぎてちょっと余計な点(瞳など)も存在します。
そのため、ここはただ以下の5つランドマークを抽出して、コントローラーLambdaにリターンします。
| ランドマーク名 | 位置 |
|---|---|
| eyeLeft | 左目 |
| eyeRight | 右目 |
| upperJawlineLeft | 左こめかみ |
| upperJawlineRight | 右こめかみ |
| chinBottom | あご |
※ランドマークの翻訳はちょっと変かもしれませんので、図を参考してください。
顔認識Lambda関数を作成
役割を分けるために、コントローラーLambda関数以外に別の顔認識Lambda関数を作ります。
作成する時に、コントローラーLambda関数と同じように、
python3.xを選んで、実行ロールも同じです。
また「基本設定」で同じように、1minのタイムアウトと512MBのメモリを設定します。
作成した後に、ここで導入するパッケージがないですから、
zipをアップロードはいらなく、
以下のコードを自動生成されたLambda_function.pyに記入するだけで完了です。
※顔認識LambdaのarnリンクをIAMロールのinvokeポリシーに追加することを忘れないでください。
import json
import boto3
rekognition = boto3.client("rekognition")
def lambda_handler(event, context):
# イベントから画像ファイルのパスをゲット
bucket = event["Bucket"]
key = event["Key"]
# Rekognitionをコールして顔認識を行う
response = rekognition.detect_faces(
Image={'S3Object': {'Bucket': bucket, 'Name': key}}, Attributes=['ALL'])
# 写真に何人いる
number_of_people = len(response["FaceDetails"])
# 全部の必要なランドマークのリストを作成
all_needed_landmarks = []
# 人数分で処理
for i in range(number_of_people):
# これは辞書のリストである
all_landmarks_of_one_person = response["FaceDetails"][i]["Landmarks"]
# 今回は eyeLeft, eyeRight, upperJawlineLeft, upperJawlineRight, chinBottom だけを使って
# needed_landmarks に抽出する
needed_landmarks = []
for type in ["eyeLeft", "eyeRight", "upperJawlineLeft", "upperJawlineRight", "chinBottom"]:
landmark = next(
item for item in all_landmarks_of_one_person if item["Type"] == type)
needed_landmarks.append(landmark)
all_needed_landmarks.append(needed_landmarks)
return all_needed_landmarks
コントローラーLambda関数
コントローラーLambda関数はすでに記入したので、
ここは第3部分に関するコードの説明だけです。
- 顔認識Lambdaを呼び出し
responseは取得した5つのランドマークです。
lambdaRekognitionName = "<ここは顔認識lambdaのarn>"
params = {"Bucket": bucket, "Key": key} # 画像ファイルのパス情報
payload = json.dumps(params)
response = boto3.client("lambda").invoke(
FunctionName=lambdaRekognitionName, InvocationType="RequestResponse", Payload=payload)
response = json.load(response["Payload"])
3-4 新画像生成部分
処理の流れ
第4部分は新画像生成部分です。
つまり写真画像と以下の新マスク画像を結合する部分です:
| 名前 | Bane | Joker | Immortan Joe |
|---|---|---|---|
| マスク画像 |
 ※1 |
 ※2 |
 ※3 |
| 出典 | ダークナイト ライジング | ダークナイト | マッドマックス 怒りのデス・ロード |
| ※1:This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0. | |||
| ※2:This work is a derivative of this photo, used under CC0 1.0. | |||
| ※3:This work, "joe's mask" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0. "joe's mask" is licensed CC BY-SA 2.0 by y2-peng. |
AWSでの処理の流れは以下です:

-
まず、コントローラーLambdaは「写真画像の保存情報(S3バケット名とファイルパス)」、「5つのランドマーク情報」と「新画像ファイル名」を新画像生成Lambdaに渡します。
-
次、新画像生成Lambdaがファイル保存情報を用いて、S3バケットから写真画像とマスク画像を読み込みます。
なお、マスク画像を事前にS3バケットに保存して、ファイルパスを新画像生成Lambdaに保存する必要があります。
(ファイルパスなどの詳細設定はコードを参照してください) -
そして、人数分の回数で写真画像とマスク画像を結合します。
毎回ランダムに1つマスク画像を選択して使用します。
結合作業の順番は以下です:
 ※This work is a derivative of "[Bane](https://www.flickr.com/photos/istolethetv/30216006787/)" by [istolethetv](https://www.flickr.com/people/istolethetv/), used under [CC BY 2.0](https://creativecommons.org/licenses/by/2.0/).
※This work is a derivative of "[Bane](https://www.flickr.com/photos/istolethetv/30216006787/)" by [istolethetv](https://www.flickr.com/people/istolethetv/), used under [CC BY 2.0](https://creativecommons.org/licenses/by/2.0/).
- 最後、新画像を「新画像ファイル名」でネーミングしてS3バケットに保存します。
処理は以上です。
新画像生成Lambdaを作成
まず、AWS Lambdaで新しいLambda関数を作成します。
ランタイムと実行ロールは先ほどと同じです。
あと、先ほどと同じように、「基本設定」からメモリとタイムアウトを設定します。
今回は画像結合は、「pillow」と「numpy」2つのpythonパッケージが必要です。
そのため、まずは1つ新しいフォルダを生成して、以下のコマンドを用いてパッケージをインストールします。
python -m pip install pillow numpy -t <new_folder>
そして、そのフォルダに「lambda_function.py」を作って、以下のコードを記入します。
import json
import boto3
import numpy as np
from PIL import Image, ImageFile
from operator import sub
from io import BytesIO
from random import choice
s3 = boto3.client("s3")
class NewPhotoMaker:
def __init__(self, all_landmarks, bucket, photo_key, new_photo_key):
self.all_landmarks = eval(all_landmarks)
self.bucket = bucket
self.photo_key = photo_key
self.new_photo_key = new_photo_key
# 写真画像を読み込む
def load_photo_image(self):
s3.download_file(self.bucket, self.photo_key, "/tmp/photo_file")
self.photo_image = Image.open("/tmp/photo_file")
# マスク画像を読み込み
def load_mask_image(self):
# bane(バットマン), joker(バットマン), immortan joe(マッドマックス)からランダム選択
mask_key = "masks/" + choice(["bane", "joker", "joe"]) + ".png"
s3.download_file(self.bucket, mask_key, "/tmp/mask_file")
self.mask_image = Image.open("/tmp/mask_file")
# ランドマーク(比率)から具体的なポイントに変更する
def landmarks_to_points(self):
upperJawlineLeft_landmark = next(
item for item in self.landmarks if item["Type"] == "upperJawlineLeft")
upperJawlineRight_landmark = next(
item for item in self.landmarks if item["Type"] == "upperJawlineRight")
eyeLeft_landmark = next(
item for item in self.landmarks if item["Type"] == "eyeLeft")
eyeRight_landmark = next(
item for item in self.landmarks if item["Type"] == "eyeRight")
self.upperJawlineLeft_point = [int(self.photo_image.size[0] * upperJawlineLeft_landmark["X"]),
int(self.photo_image.size[1] * upperJawlineLeft_landmark["Y"])]
self.upperJawlineRight_point = [int(self.photo_image.size[0] * upperJawlineRight_landmark["X"]),
int(self.photo_image.size[1] * upperJawlineRight_landmark["Y"])]
self.eyeLeft_point = [int(self.photo_image.size[0] * eyeLeft_landmark["X"]),
int(self.photo_image.size[1] * eyeLeft_landmark["Y"])]
self.eyeRight_point = [int(self.photo_image.size[0] * eyeRight_landmark["X"]),
int(self.photo_image.size[1] * eyeRight_landmark["Y"])]
# 顔幅に合わせてマスク画像をリサイズする
def resize_mask(self):
face_width = int(np.linalg.norm(list(map(sub, self.upperJawlineLeft_point, self.upperJawlineRight_point))))
new_hight = int(self.mask_image.size[1]*face_width/self.mask_image.size[0])
self.mask_image = self.mask_image.resize((face_width, new_hight))
# 顔の角度(首回転による斜め顔ではない)に合わせてマスク画像を回転する
def rotate_mask(self):
angle = np.arctan2(self.upperJawlineRight_point[1] - self.upperJawlineLeft_point[1],
self.upperJawlineRight_point[0] - self.upperJawlineLeft_point[0])
angle = -np.degrees(angle) # radian to dgree
self.mask_image = self.mask_image.rotate(angle, expand=True)
# 写真画像とマスク画像を結合
def match_mask_position(self):
# 目の位置を用いてマッチング
face_center = [int((self.eyeLeft_point[0] + self.eyeRight_point[0])/2),
int((self.eyeLeft_point[1] + self.eyeRight_point[1])/2)]
mask_center = [int(self.mask_image.size[0]/2),
int(self.mask_image.size[1]/2)]
x = face_center[0] - mask_center[0]
y = face_center[1] - mask_center[1]
self.photo_image.paste(self.mask_image, (x, y), self.mask_image)
# 新画像ファイルをS3に保存
def save_new_photo(self):
new_photo_byte_arr = BytesIO()
self.photo_image.save(new_photo_byte_arr, format="JPEG")
new_photo_byte_arr = new_photo_byte_arr.getvalue()
s3.put_object(Bucket=self.bucket, Key=self.new_photo_key,
Body=new_photo_byte_arr)
# 実行
def run(self):
self.load_photo_image()
# 人数分の処理
for i in range(len(self.all_landmarks)):
self.load_mask_image() # 毎回1つ新しいマスクをロード
self.landmarks = self.all_landmarks[i]
self.landmarks_to_points()
self.resize_mask()
self.rotate_mask()
self.match_mask_position()
self.save_new_photo()
# lambdaメインファンクション
def lambda_handler(event, context):
landmarks = event["landmarks"]
bucket = event["bucket"]
photo_key = event["photo_key"]
new_photo_key = event["new_photo_key"]
photo_maker = NewPhotoMaker(landmarks, bucket, photo_key, new_photo_key)
photo_maker.run()
最後、フォルダのすべての内容をzipにして、Lambdaにアップロードします。
これで、新画像生成の作成が完了します。
※新画像生成LambdaのarnリンクをIAMロールのinvokeポリシーに追加することを忘れないでください。
コントローラーLambda関数
この部分に関するコントローラーLambdaのコードは以下です:
# 新画像生成lambdaを呼び出し
lambdaNewMaskName = "<ここは新画像生成lambdaのarn>"
params = {"landmarks": str(response),
"bucket": bucket,
"photo_key": key,
"new_photo_key": new_key}
payload = json.dumps(params)
boto3.client("lambda").invoke(FunctionName=lambdaNewMaskName,
InvocationType="RequestResponse", Payload=payload)
3-5 新画像出力部分
LINE Botにおける画像出力
最後の部分は新画像の出力部分です。
このアプリはLINE Botで画像を入出力で、入力するときは直接的に画像ファイルを渡しますが、
出力は画像ファイルを直接的に送信できません。
LINE Bot MessageingApiにおけるImage message(画像メッセージ)のドキュメントにはユーザへの画像送信方式を規定しています。
それAPIが受けられるのは画像ファイルではなく、画像のURLです。
ドキュメントに見ると、ユーザとLINE Botの通信はLINE platformに経由しています。
つまりこの送信過程は
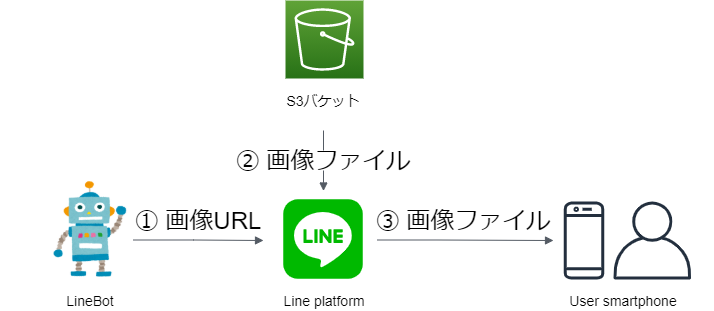
- 「LINE Botから画像URLをLINE platformに送る」
- 「LINE platformがS3バケットに保存されている画像を読み込む」
- 「LINE platformがユーザに画像を送信する」
となっています。
でもこの過程によって、S3バケットのアクセス権限が問題になります。
アクセス権限が「非公開」にすると、LINE platformが画像を読み込めなくて、ユーザがもらった画像がこうなります:

アクセス権限が「公開」にすると、画像のS3オブジェクトURLを分かればで誰でもアクセスできます。
つまり自分の写真が他の人に見られちゃう可能性があり、プライバシーの問題があります。
一応DynamoDBなどを使って、LINEユーザ認証を行うことを考えましたが、
作業量が結構増やしまして、「できるだけ作業量を減らす」のコンセプトと衝突、
正直、やりたくないです。
色々調べて、最後にいい方法を見つけました。
それは「署名付きURL」です。
署名付きURL
プライバシーを保護するために、S3バケットへのアクセス権限は「非公開」にします。
画像のS3オブジェクトURL知ってもアクセスできません。
でもIAMロールの権限で発行した署名付きURLを使ったら、非公開的なS3バケットの特定オブジェクトへのアクセスは可能になります。
ちょっとzoomのパスワード付き会議URLみたいですね。
また、この署名付きURLは有効期限も設定できます。
有効期限が切れるとURLを使えなくなり、安全性がもう一歩上げます:
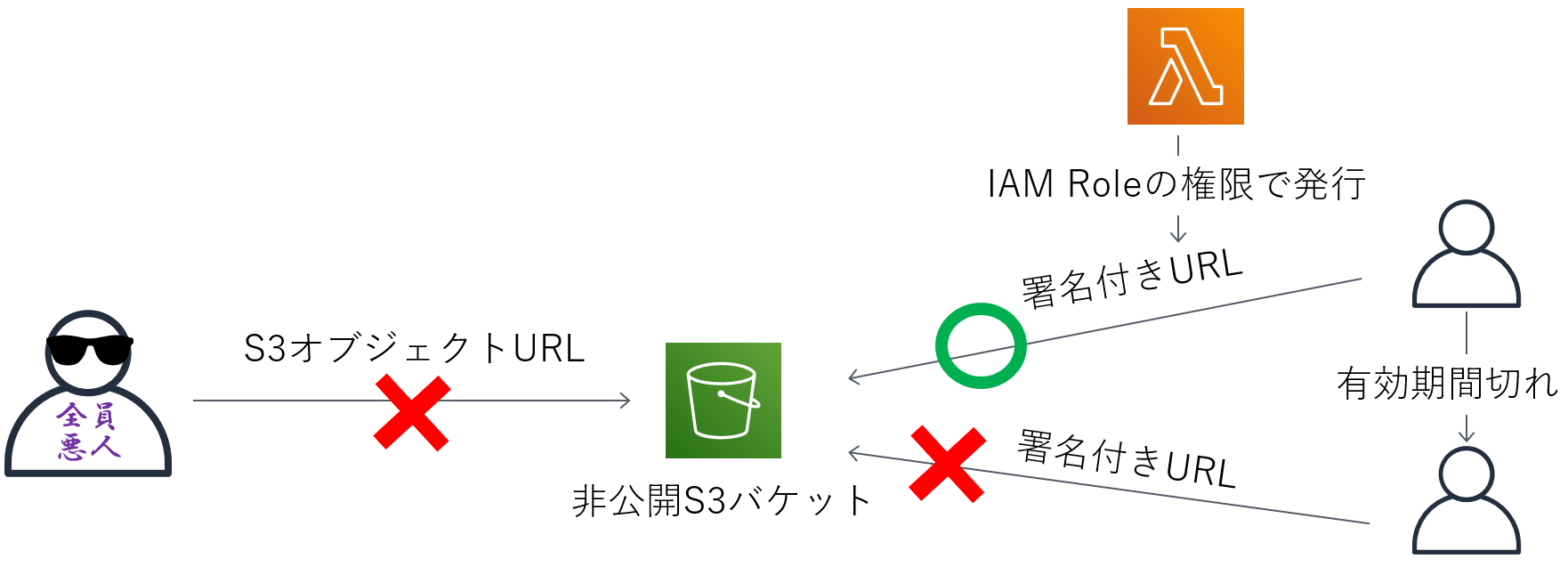
でも1つ注意すべきことがあって、それは署名付きURLの長さ問題です。
IAMロールの権限で発行された署名付きURLには一時アクセスためのトークン情報が入ったため、URLが結構長くなります。
しかし、LINE BotのImage message APIの規定により、受け取れるURLの長さ上限が1000文字です。
そのため、S3バケット名、画像ファイルパスと画像ファイル名が長すぎると、URLが1000文字を超えて、送信できなくなります。
なので第2部分のS3バケットを作成する時に、「バケット名はできれば短く」ということがありました。
同じ理由で、新画像ファイル名はメッセージIDの最後3文字(ファイル名を短縮)することと、
新画像ファイルをS3バケットのロールフォルダに保存する(ファイルパスを短縮)こともしています。
これで署名付きURLの長さ問題が解決できました。
補足:
署名付きURLの長さ問題について、実はもう1つ解決策が存在しています。
それはIAMロールではなく、IAMユーザの権限でURLを発行することです。
IAMユーザで発行したURLはトークンいらなく、URLを短くできますが、
IAMユーザの「アクセスキー ID」と「シークレットアクセスキー」を使う必要があります。
安全性から考えると、IAMユーザでURLを発行する方法をお勧めしません。
処理の流れ
さあ、S3バケットの権限問題を解決できましたので、この部分を実装しましょう。
この部分の流れは以下です:

まず、コントローラーLambda関数が新画像の署名付きURLをLINE Botに渡します。
そして、LINE BotがS3バケットから画像ファイルを読み込んで(実際の読み込みはLINE platformで行う)、
最後ユーザに送信します。
これで、処理は終了です。
コントローラーLambda関数
上の部分と同じように、この部分に関するコントローラーLambda関数コードを解説します。
- 署名付きURLを生成
有効期間は600秒と設定しています。
# 署名付きURL生成
presigned_url = s3.generate_presigned_url(ClientMethod="get_object", Params={
"Bucket": bucket, "Key": new_key}, ExpiresIn=600)
- 新画像を送信
# 新画像メッセージの返信
line_bot_api.reply_message(line_event.reply_token, ImageSendMessage(
original_content_url=presigned_url, preview_image_url=presigned_url))
4.実際の結果
早速ですが、作ったアプリを試してみましょう!
インターフェース
まずはLINEインターフェースでの受送信です。
LINE Botの「Messaging API設定」からBotのQRコードがあり、それを使って自分の友達に追加できます。
後に送信してみたら。。。
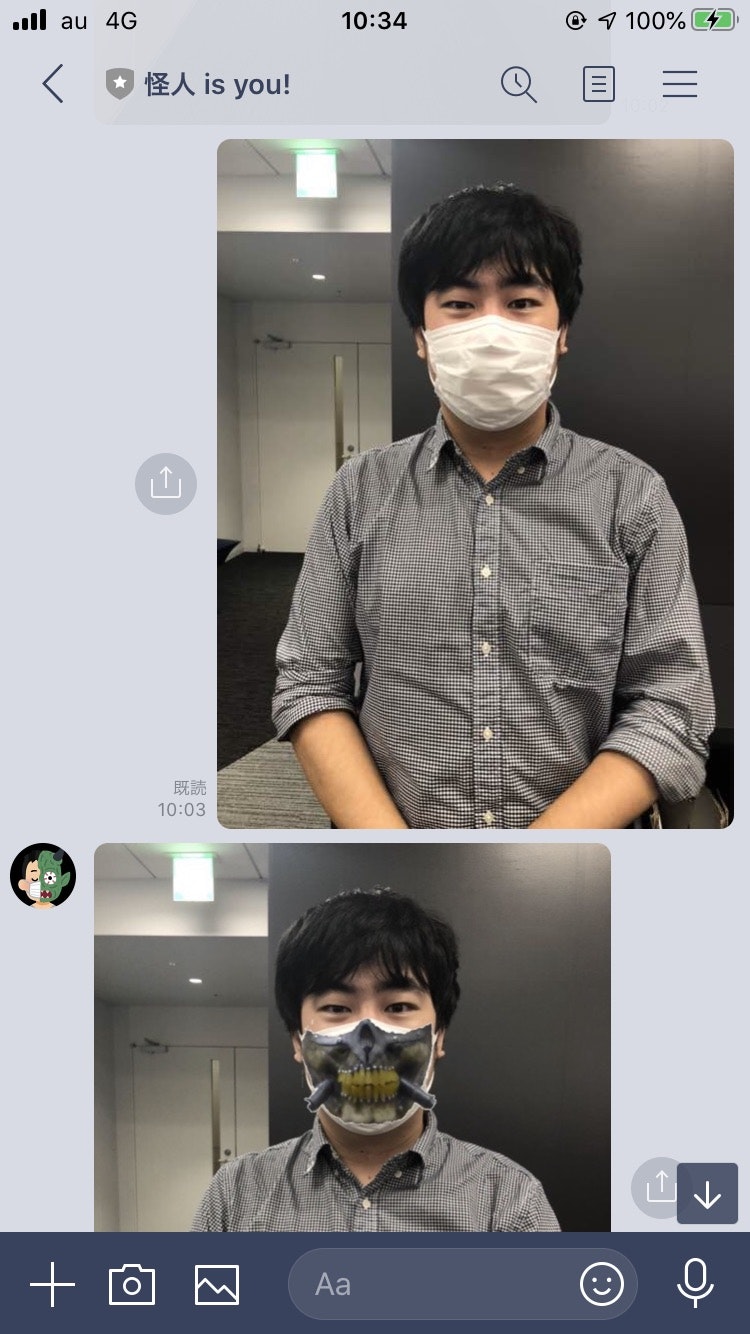
※This work, "wearing joe's mask" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0. "wearing joe's mask" is licensed CC BY-SA 2.0 by y2-peng.
ちゃんとできましたね!
それでは、どんなパターンがちゃんと行けるか、どんなパターンがうまくいかないか調べましょう!
うまくいったパターン
| description | before | after |
|---|---|---|
| 1人正面 |
 |
 ※1 ※1 |
| 1人正面(回転あり) |
 |
 ※2 ※2 |
| 複数人正面 |
 |
 ※3 ※3 |
| 顔大きすぎでも |
 |
 ※4 ※4 |
| ※1:This work is a derivative of this photo, used under CC0 1.0. | ||
| ※2:This work, "result 2" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0. "result 2" is licensed CC BY-SA 2.0 by y2-peng. | ||
| ※3:This work, "masked 4" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0, "Bane" by istolethetv, used under CC BY 2.0, and this photo, used under CC0 1.0. "masked 4" is licensed CC BY-SA 2.0 by y2-peng. | ||
| ※4:This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0. |
うまくいかないパターン
| description | before | after |
|---|---|---|
| 斜め顔 |
 |
 ※1 ※1 |
| 顔小さすぎ(一番後ろの人) |
 |
 ※2 ※2 |
| ぼかし(後ろの人) |
 |
 ※3 ※3 |
※1:This work, "standing 2" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0 and "Bane" by istolethetv, used under CC BY 2.0. "standing 2" is licensed CC BY-SA 2.0 by y2-peng.
※2:This work, "standing 4" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0 and "Bane" by istolethetv, used under CC BY 2.0. "standing 4" is licensed CC BY-SA 2.0 by y2-peng.
※3:This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0.
分析
結果によって、正面及びクリアであれば、処理は大体できます。
ぼかしがある場合は、顔認識できなくて、処理が行いません。
斜め顔または顔が小さすぎる場合、処理は行いますが、正しい結果ではありません。
5.まとめと所感
まとめ
今回は写真中の白いマスクを怪人マスクに変更するLINEアプリケーションを開発しました。
AWSのサービスを活用して、サーバレスで実現でき、「できるだけ作業量を減らす」というコンセプトを徹底できました。
正面でクリアな写真であれば、変換処理が大体大丈夫です。
ただ、斜め顔やぼかし顔の処理は今後の課題になります。
今後の課題
- 斜め顔:
現在、斜め顔の処理は正しくないです。理由としてはマスクは正面だけで、斜め顔用のがありません。今後の解決策として、2Dマスクを3D座標系に回転してから結合を行い、または斜め顔専用マスク画像を用意することを考えています。 - 顔小さすぎまたはぼかし:
現在の顔認識はAWS Rekognitionを使って、そちらの性能がこのアプリの性能の上限を決めています。もし自分でもっと精度高い顔認識システムを開発できたら、この問題を解決できると思います。(でも「できるだけ作業量を減らす」と衝突ですね:() - マスクの選択:
現在、怪人マスクは3つの中にランダムに使ってますが、今後はもっと増やしたいと思います。また、ランダム選択だけでなく、ユーザが選べるようにしたいです。マスクにタグをつけて、ユーザからの「○○のマスクをつけたい」や「かわいいマスクほしい」などの要求を全部満たせるようにします。
ほかの所感
- サーバレスの便利さ:今回最も感じたのはサーバレスの魅力です。サーバーがある場合は環境構築だけでなく、保守管理も必要で、かなり時間かかります。でもサーバレスでの開発はこれらをスキップでき、時間をセーブできました。アジャイル開発に使えますね。ただ、Lambdでのサーバレス処理が性能上の制限があり、複雑な処理があればやはりサーバーを立ちましょう。
- AWS一年間の無料最高!!:AWSの新規アカウントは1年間の「無料枠」があり、ある範囲内の使用はすべて無料です。今回の開発に使ったLambda、API Gateway、S3、RekognitionやCloudwatchは全部0円でできて、お得でした。残った数か月の無料期間には、いろいろ試したいと思います。皆様もし興味があればぜひ!無料ですよ!

6.全コード
lambda_function_for_controller.py
import os
import sys
import logging
import boto3
import json
from linebot import LineBotApi, WebhookHandler
from linebot.models import MessageEvent, TextMessage, TextSendMessage, ImageMessage, ImageSendMessage
from linebot.exceptions import LineBotApiError, InvalidSignatureError
logger = logging.getLogger()
logger.setLevel(logging.ERROR)
# 環境変数からline botのチャンネルアクセストークンとシークレットを読み込む
channel_secret = os.getenv('LINE_CHANNEL_SECRET', None)
channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None)
if channel_secret is None:
logger.error('Specify LINE_CHANNEL_SECRET as environment variable.')
sys.exit(1)
if channel_access_token is None:
logger.error('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.')
sys.exit(1)
# api&handlerを生成
line_bot_api = LineBotApi(channel_access_token)
handler = WebhookHandler(channel_secret)
# S3バケットとつながる
s3 = boto3.client("s3")
bucket = "<S3バケット名>"
# Lambdaのメインファンクション
def lambda_handler(event, context):
# 認証用のX-Line-Signatureヘッダー
signature = event["headers"]["X-Line-Signature"]
body = event["body"]
# リターン値の設定
ok_json = {"isBase64Encoded": False,
"statusCode": 200,
"headers": {},
"body": ""}
error_json = {"isBase64Encoded": False,
"statusCode": 403,
"headers": {},
"body": "Error"}
@handler.add(MessageEvent, message=ImageMessage)
def message(line_event):
# ユーザのプロフィール
profile = line_bot_api.get_profile(line_event.source.user_id)
# 送信したユーザのIDを抽出(push_messageなら使う, replyなら必要ない)
# user_id = profile.user_id
# メッセージIDを抽出
message_id = line_event.message.id
# 画像ファイルを抽出
message_content = line_bot_api.get_message_content(message_id)
content = bytes()
for chunk in message_content.iter_content():
content += chunk
# 画像ファイルを保存
key = "origin_photo/" + message_id
new_key = message_id[-3:]
s3.put_object(Bucket=bucket, Key=key, Body=content)
# 顔認識lambdaを呼び出し
lambdaRekognitionName = "<ここは顔認識lambdaのarn>"
params = {"Bucket": bucket, "Key": key} # 画像ファイルのパス情報
payload = json.dumps(params)
response = boto3.client("lambda").invoke(
FunctionName=lambdaRekognitionName, InvocationType="RequestResponse", Payload=payload)
response = json.load(response["Payload"])
# 新画像生成lambdaを呼び出し
lambdaNewMaskName = "<ここは新画像生成lambdaのarn>"
params = {"landmarks": str(response),
"bucket": bucket,
"photo_key": key,
"new_photo_key": new_key}
payload = json.dumps(params)
boto3.client("lambda").invoke(FunctionName=lambdaNewMaskName,
InvocationType="RequestResponse", Payload=payload)
# 署名付きURL生成
presigned_url = s3.generate_presigned_url(ClientMethod="get_object", Params={
"Bucket": bucket, "Key": new_key}, ExpiresIn=600)
# 新画像メッセージの返信
line_bot_api.reply_message(line_event.reply_token, ImageSendMessage(
original_content_url=presigned_url, preview_image_url=presigned_url))
try:
handler.handle(body, signature)
except LineBotApiError as e:
logger.error("Got exception from LINE Messaging API: %s\n" % e.message)
for m in e.error.details:
logger.error(" %s: %s" % (m.property, m.message))
return error_json
except InvalidSignatureError:
return error_json
return ok_json
lambda_function_for_rekognition.py
import json
import boto3
rekognition = boto3.client("rekognition")
def lambda_handler(event, context):
# イベントから画像ファイルのパスをゲット
bucket = event["Bucket"]
key = event["Key"]
# Rekognitionをコールして顔認識を行う
response = rekognition.detect_faces(
Image={'S3Object': {'Bucket': bucket, 'Name': key}}, Attributes=['ALL'])
# 写真に何人いる
number_of_people = len(response["FaceDetails"])
# 全部の必要なランドマークのリストを作成
all_needed_landmarks = []
# 人数分で処理
for i in range(number_of_people):
# これは辞書のリストである
all_landmarks_of_one_person = response["FaceDetails"][i]["Landmarks"]
# 今回は eyeLeft, eyeRight, upperJawlineLeft, upperJawlineRight, chinBottom だけを使って
# needed_landmarks に抽出する
needed_landmarks = []
for type in ["eyeLeft", "eyeRight", "upperJawlineLeft", "upperJawlineRight", "chinBottom"]:
landmark = next(
item for item in all_landmarks_of_one_person if item["Type"] == type)
needed_landmarks.append(landmark)
all_needed_landmarks.append(needed_landmarks)
return all_needed_landmarks
lambda_function_for_new_image_gengeration.py
import json
import boto3
import numpy as np
from PIL import Image, ImageFile
from operator import sub
from io import BytesIO
from random import choice
s3 = boto3.client("s3")
class NewPhotoMaker:
def __init__(self, all_landmarks, bucket, photo_key, new_photo_key):
self.all_landmarks = eval(all_landmarks)
self.bucket = bucket
self.photo_key = photo_key
self.new_photo_key = new_photo_key
# 写真画像を読み込む
def load_photo_image(self):
s3.download_file(self.bucket, self.photo_key, "/tmp/photo_file")
self.photo_image = Image.open("/tmp/photo_file")
# マスク画像を読み込み
def load_mask_image(self):
# bane(バットマン), joker(バットマン), immortan joe(マッドマックス)からランダム選択
mask_key = "masks/" + choice(["bane", "joker", "joe"]) + ".png"
s3.download_file(self.bucket, mask_key, "/tmp/mask_file")
self.mask_image = Image.open("/tmp/mask_file")
# ランドマーク(比率)から具体的なポイントに変更する
def landmarks_to_points(self):
upperJawlineLeft_landmark = next(
item for item in self.landmarks if item["Type"] == "upperJawlineLeft")
upperJawlineRight_landmark = next(
item for item in self.landmarks if item["Type"] == "upperJawlineRight")
eyeLeft_landmark = next(
item for item in self.landmarks if item["Type"] == "eyeLeft")
eyeRight_landmark = next(
item for item in self.landmarks if item["Type"] == "eyeRight")
self.upperJawlineLeft_point = [int(self.photo_image.size[0] * upperJawlineLeft_landmark["X"]),
int(self.photo_image.size[1] * upperJawlineLeft_landmark["Y"])]
self.upperJawlineRight_point = [int(self.photo_image.size[0] * upperJawlineRight_landmark["X"]),
int(self.photo_image.size[1] * upperJawlineRight_landmark["Y"])]
self.eyeLeft_point = [int(self.photo_image.size[0] * eyeLeft_landmark["X"]),
int(self.photo_image.size[1] * eyeLeft_landmark["Y"])]
self.eyeRight_point = [int(self.photo_image.size[0] * eyeRight_landmark["X"]),
int(self.photo_image.size[1] * eyeRight_landmark["Y"])]
# 顔幅に合わせてマスク画像をリサイズする
def resize_mask(self):
face_width = int(np.linalg.norm(list(map(sub, self.upperJawlineLeft_point, self.upperJawlineRight_point))))
new_hight = int(self.mask_image.size[1]*face_width/self.mask_image.size[0])
self.mask_image = self.mask_image.resize((face_width, new_hight))
# 顔の角度(首回転による斜め顔ではない)に合わせてマスク画像を回転する
def rotate_mask(self):
angle = np.arctan2(self.upperJawlineRight_point[1] - self.upperJawlineLeft_point[1],
self.upperJawlineRight_point[0] - self.upperJawlineLeft_point[0])
angle = -np.degrees(angle) # radian to dgree
self.mask_image = self.mask_image.rotate(angle, expand=True)
# 写真画像とマスク画像を結合
def match_mask_position(self):
# 目の位置を用いてマッチング
face_center = [int((self.eyeLeft_point[0] + self.eyeRight_point[0])/2),
int((self.eyeLeft_point[1] + self.eyeRight_point[1])/2)]
mask_center = [int(self.mask_image.size[0]/2),
int(self.mask_image.size[1]/2)]
x = face_center[0] - mask_center[0]
y = face_center[1] - mask_center[1]
self.photo_image.paste(self.mask_image, (x, y), self.mask_image)
# 新画像ファイルをS3に保存
def save_new_photo(self):
new_photo_byte_arr = BytesIO()
self.photo_image.save(new_photo_byte_arr, format="JPEG")
new_photo_byte_arr = new_photo_byte_arr.getvalue()
s3.put_object(Bucket=self.bucket, Key=self.new_photo_key,
Body=new_photo_byte_arr)
# 実行
def run(self):
self.load_photo_image()
# 人数分の処理
for i in range(len(self.all_landmarks)):
self.load_mask_image() # 毎回1つ新しいマスクをロード
self.landmarks = self.all_landmarks[i]
self.landmarks_to_points()
self.resize_mask()
self.rotate_mask()
self.match_mask_position()
self.save_new_photo()
# lambdaメインファンクション
def lambda_handler(event, context):
landmarks = event["landmarks"]
bucket = event["bucket"]
photo_key = event["photo_key"]
new_photo_key = event["new_photo_key"]
photo_maker = NewPhotoMaker(landmarks, bucket, photo_key, new_photo_key)
photo_maker.run()