業務で機械学習のモデルを検討しており、手持ちのデータに対してどの様なモデルが有効なのか試行錯誤する目的でAutoMLの「PyCaret」を利用してみました。使い方は非常に簡単で僅か数行のコードをJupyter Notebook上で走らせるだけで、機械学習の各種モデルに対して手持ちのデータを使ってどれぐらいの性能(正答率等)のモデルが作れるか検証出来ました。しかし、AutoMLを使ってみて凄く良いなと感じる部分と、この点は不満という点が出てきました。本記事はあくまで筆者の個人的な意見として使ってみて感じたメリット・デメリットをまとめてみようと思います。
そもそもAutoML、PyCaretとは??
AutoMLとは?
参考より抜粋して記載します。
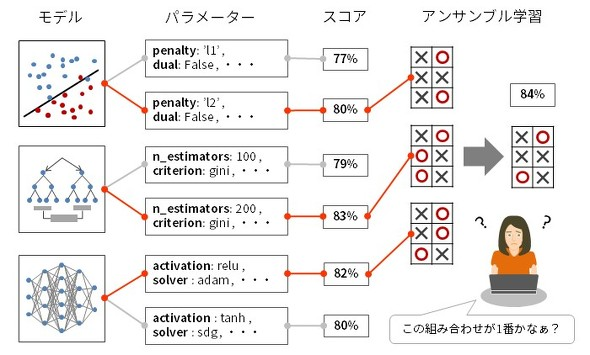
AutoMLとは、機械学習を用いたデータ分析のプロセスを自動化することやその技術全般を指す言葉で、「Automated Machine Learning(自動化された機械学習)」の略称です。データ分析のプロセスには試行錯誤を伴うような工程が幾つかあります。モデルを構築する工程では、まずロジスティック回帰で学習し、次にランダムフォレスト、多層パーセプトロン……というようにさまざまなモデルを試し、精度を比較します。それぞれに対して、さまざまなパラメーターを設定しては学習し直し、より良い結果が得られるものを抽出するといった作業を繰り返します。その後、複数のモデルを組み合わせて精度向上を目指すアンサンブル学習を試したり、組み合わせを変えてみたり手法を変更してみたりしながら、さらなる精度の向上を図っていきます。このような作業の中には人間がやるより機械的に実行した方が効率のよいものが多くあります。それらを自動化することがAutoMLの役割です。
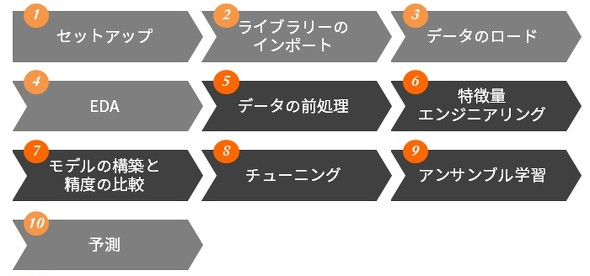
ML(機械学習)を用いた分析の流れは下図の1~10の通りです。AutoMLでは5~9の行程を自動化します。
PyCaretとは?
公式ドキュメントより抜粋(色付き部分は筆者が追加)
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows. It is an end-to-end machine learning and model management tool that exponentially speeds up the experiment cycle and makes you more productive.
Compared with the other open-source machine learning libraries, PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with a few lines only. This makes experiments exponentially fast and efficient. PyCaret is essentially a Python wrapper around several machine learning libraries and frameworks, such as scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, Ray, and a few more.
The design and simplicity of PyCaret are inspired by the emerging role of citizen data scientists, a term first used by Gartner. Citizen Data Scientists are power users who can perform both simple and moderately sophisticated analytical tasks that would previously have required more technical expertise.
赤文字にしている部分から分かる通りPyCaretには以下の特徴が有ります。
- MLのワークフローを自動化出来る
- 指数関数的に実行時間を高速化し、生産性を高める
- (他のライブラリでは)数100行にも及ぶ様なコードを僅か数行のコードで実現してしまう
- scikit-learnやXGBoost、OptunaなどのMLライブラリのラッパーである
- シンプルで程良く洗練された分析タスクを簡単に実現出来る
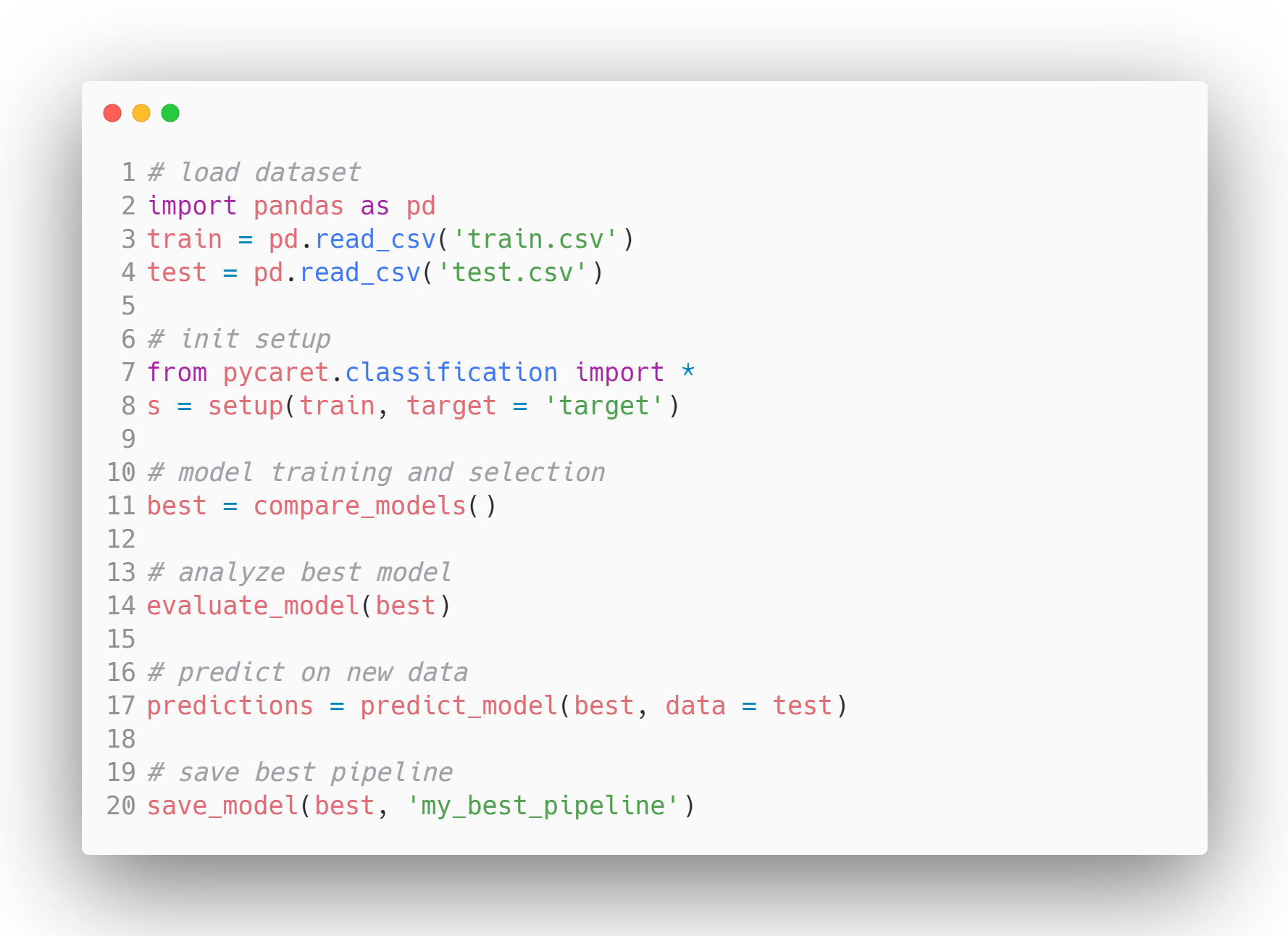
例えば分類(Classification)を実行する場合、下図の様に僅か数行のコードで実現できてしまいます。PyCaretの内部で動作しているscikit-learnど同様のことを実現しようとすると、恐らく必要なモジュールのimportだけで、PyCaretでの分析コードの総行数と同じぐらいの行数を消費するでしょう。
AutoMLのメリット・デメリット
実際にPyCaretを利用してみて感じたAutoMLのメリットデメリットを書いてみようと思います。
メリット
- 極端な言い方をするとデータを用意するだけでMLモデル構築の知識が皆無でも分析が出来る
- 手持ちのデータに対して有効なモデルが分からず、兎に角多くのモデルで試した結果を知りたい場合に最小限の労力で分析が出来る
- 最良の結果にはマーカ付きで表示され結果の比較・検討が容易になる
- 実行後の結果を可視化する機能まで含まれており、分析の結果を共有することも容易
- Jupyter Notebookと組み合わせて使用すれば分析レポートを作るのも容易となる
デメリット
- 利用のハードルを下げるために最小限の設定で動作する様になっているため、すぐに始められるが、少しパラメータを変化させて検証したいといった細かいチューニングは難しい
- 様々なモデルを一気に動作させることが出来るのは利点であると同時に、ブラックボックス化に拍車を掛けてしまう部分が有る
- feature_selection等のoptionを利用した時に、内部で何が起こっているのかよく分からない
- (PyCaretの場合)Deep Learningはそもそも対象外であり、比較対象に出来ない
- 柵のためか、アップデートのスピードが緩やかであり、最新の環境への対応に時間が掛かる
- (PyCaretの場合)Python3.10移行には非対応(Ver3.0から対応予定)
これらのメリット・デメリットには参考でも既に述べられているものも有ります。
まとめに代えて: 結局どう利用するのが良いのか
AutoMLはメリット・デメリットが有りますが、世の中にメリットだけのツールというのはあまり存在しないように思います。(時々デメリットに塗れたツールを見掛けることは有りますが。。。)よって、上記のメリット・デメリットを踏まえ筆者は以下のように利用することにしました。
- 一度に何種類ものモデルを手持ちのデータを使って回せるので、手持ちのデータにマッチするモデルを探索する時、つまり分析の導入部分での利用。
- 良いモデルが見つかったら保存し、それをscikit-lernなどを使って再学習させる等の使い方も出来る
-
PyCaret Cheet Sheetを研究して機能について詳しく理解する
- 但し、将来のアップデートで機能がガラリと変わる可能性が有ることも加味しておく
- 参考の各種AutoMLを使い比べてみる(この記事では9種類のAutoMLが紹介されている)
- 裏で起こっていることを理解出来る様に、MLの理論的知識のUpdateを日々怠らない
Reference