※社内勉強会用に作ったものを公開しています
何がいいの?
- 性能が最大2倍※1
- 分析に使える嬉しい機能が盛りだくさん※2
※1 ほんとか?っていうくらいcount(*)の速度が遅いけど用途的には許容範囲かなと。
※2 個人の感想です
説明内容は大きく二点
・WITH句
・WINDOW関数
WITH句
これまで、例えば集計した結果を使ってさらに集計を行う場合、次のように書いていたと思います。
SELECT
q1.aaa,q2.bbb,...
FROM
orders q1
LEFT JOIN
#サブクエリ1
(SELECT aaa,bbb,ccc,ddd FROM orders WHERE aaa = .. AND bbb = ..)q2
ON
q1.aaa = q2.bbb
LEFT JOIN
#サブクエリ2
(aaa,bbb,ccc,ddd FROM orders WHERE aaa = .. AND bbb = ..)q3
ON
q2.aaa = q3.bbb;
SELECT
aaa,bbb,...
FROM
# サブクエリ
(SELECT
aaa,bbb,ccc,ddd
FROM
orders
WHERE
aaa = .. AND bbb = ..
)q1
WHERE
aaa = xxx AND bbb = yyy
サブクエリとJOINしたり、サブクエリの結果を元にさらに絞り込みを行ったり。
サブクエリが増えると読みにくくなりがち。
自分で書いたものさえしばらく時間が経てば、他人が書いたもの同様に読むのにコストを要します。
このサブクエリを書く場所を変えられるようになりました。
従来通りに書くことももちろん可能ですので、やりやすい方で利用してください。
WITH 結果 as
(SELECT ... FROM AAA WHERE ....)
SELECT
aaa,bbb
FROM
テーブル q1
LEFT JOIN
結果 q2
ON
q1.aaa = q2.bbb;
このようにサブクエリを外に出して名前をつけておき、それを利用することが可能です。(この機能をCTEと呼びます)
必要な部分だけを見ることに集中できるので可読性が上がります。
このSQLを実行するときだけ、一時的なテーブルを作るイメージ。
次の書き方のようにWITH句に書いたものはこの文章実行中であれば使い回しが可能です。
WITH 結果 as
(SELECT ... FROM AAA WHERE ....)
, 結果2 as #カンマで区切る必要がある
(SELECT * FROM BBB a INNER JOIN 結果 b ON a.aaa = b.bbb)
SELECT
q1.aaa, q2.bbb
FROM
orders q1
LEFT JOIN
結果2 q2
ON
q1.aaa = q2.bbb;
わかりにくいかもしれませんが、これまでだと上のように書くためには次のように書く必要がありました。
SELECT
q1.aaa, q2.bbb
FROM
orders q1
LEFT JOIN
(SELECT
*
FROM
BBB a
INNER JOIN
(SELECT
aaa
FROM
AAA
WHERE ....
)qi
b ON a.aaa = b.bbb
)q2
ON q1.aaa = q2.bbb;
こんな感じ。(少々極端な書き方してます)
シンプルなものでは恩恵を感じづらいかもしれませんが、複雑になればなるほど使い勝手がよくなります。
ただ、書き方は違えど見やすくするだけなら、これまででもTemporary Tableを作れば同じようなことはできました。
本来のこの機能の目玉は以下に記す再帰CTEです。
この機能はツリー構造になっている親子孫関係を扱っている時に効果を発揮します。
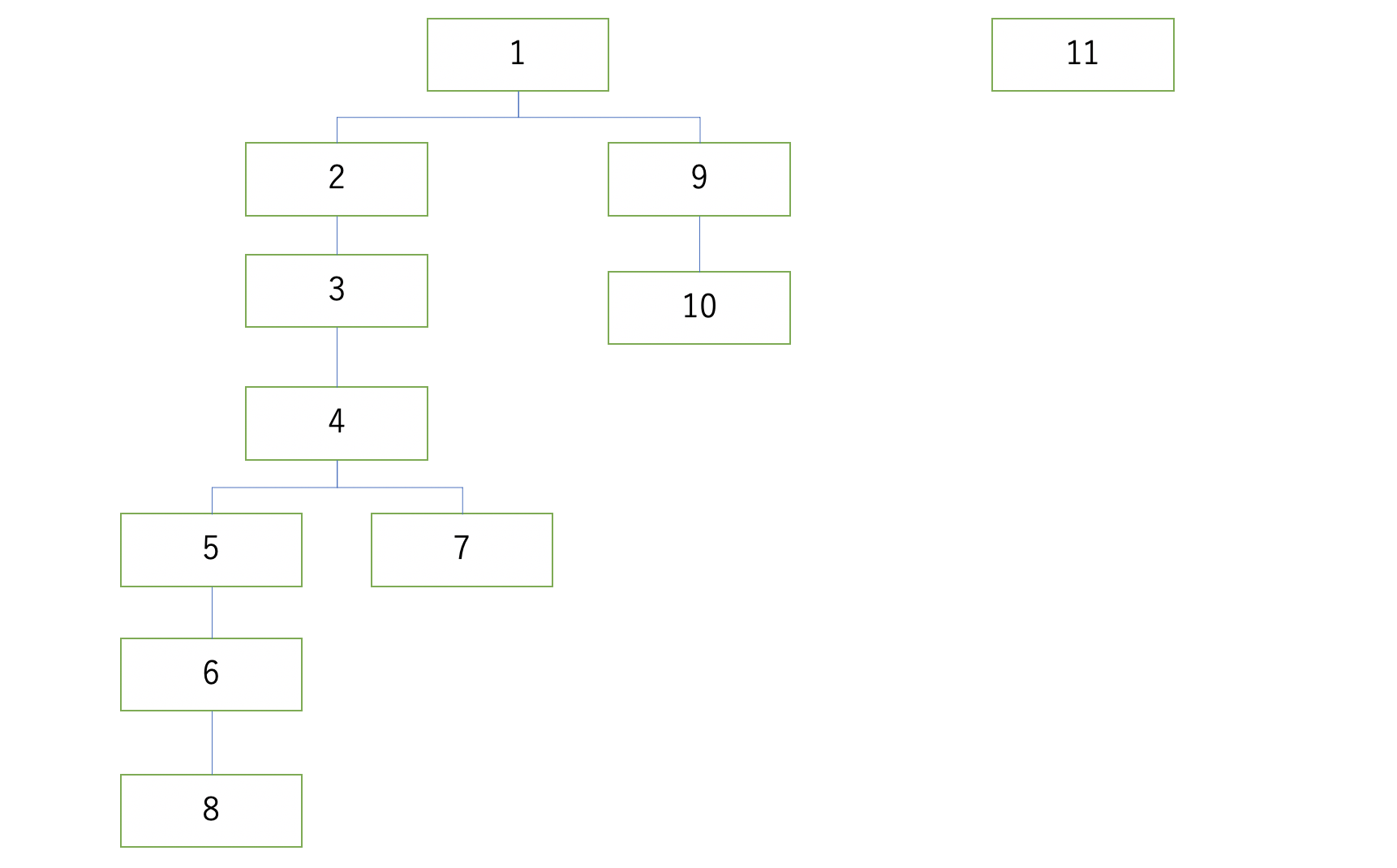
このツリー構造はある一族の家系図を示します。
データとしては次のようになります。
| id | name | parent_id |
|---|---|---|
| 1 | ジョージ | NULL |
| 2 | ジョナサン | 1 |
| 3 | ジョージ二世 | 2 |
| 4 | ジョセフ | 3 |
| 5 | ホリィ | 4 |
| 6 | 承太郎 | 5 |
| 7 | 仗助 | 4 |
| 8 | 徐倫 | 6 |
| 9 | ディオ | 1 |
| 10 | ジョルノ | 9 |
| 11 | ジョニィ | NULL |
この中からidが1のレコードの子レコードを取得するとき
SELECT *
FROM
j_tree
WHERE
id = 1
UNION ALL
SELECT a.*
FROM
j_tree a
JOIN
(SELECT *
FROM
j_tree
WHERE
id = 1) b
ON
a.parent_id = b.id
| id | name | parent_id |
|---|---|---|
| 1 | ジョージ | NULL |
| 2 | ジョナサン | 1 |
| 9 | ディオ | 1 |
| たった2世代までを表示するだけでも結構面倒で、 | ||
| 全ての子孫までを追うと何度もUNIONをする必要があります |
WITH recursive cte (depth,id,parent_id,name) AS (
SELECT 1,n.*
FROM
j_tree n
WHERE
id = 1
UNION ALL
SELECT
cte.depth + 1
,child_naive_tree.*
FROM
j_tree AS child_naive_tree, cte
WHERE
cte.id = child_naive_tree.parent_id AND (depth + 1) < 5
)
SELECT * FROM cte;
| id | name | parent_id | depth |
|---|---|---|---|
| 1 | 1 | ジョージ | NULL |
| 2 | 2 | ジョナサン | 1 |
| 2 | 9 | ディオ | 1 |
| 3 | 3 | ジョージ二世 | 2 |
| 3 | 10 | ジョルノ | 9 |
| 4 | 4 | ジョセフ | 3 |
whereのdepth部分を少し調整するだけでもっと深い親子関係のデータを取得できます。
使いみちとしてはURLの階層関係などを整理、分析するときなどでしょうか。
WINDOW関数
ユーザーごとにカウント振る時
相関サブクエリで書いて、処理も重たいので中間テーブルを作ったりしていましたが、シンプルに書けるようになりました。
CREATE TABLE repeat_count AS
SELECT
q2.user_id, q2.order_id, q2.date
,(SELECT count(*)+1
FROM
orders q1
WHERE
q1.order_id<q2.order_id AND q1.user_id = q2.user_id) AS rownum
FROM
orders q2
ORDER BY
user_id, date;
SELECT
user_id,order_id,date
,ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY date, order_id)AS rownum
FROM
orders o2;
| user_id | order_id | date | rownum |
|---|---|---|---|
| AAA | 1111 | 2021-03-01 | 1 |
| AAA | 2222 | 2021-03-02 | 2 |
| AAA | 3333 | 2021-03-03 | 3 |
| BBB | 1111 | 2021-03-01 | 1 |
| BBB | 2222 | 2021-03-02 | 2 |
| BBB | 3333 | 2021-03-03 | 3 |
一行前のレコードを参照できるようになりました
JOINしなくてもよくなり、何かしらの差分をとるときなどに使えます。
SELECT *
FROM
repeat_table a #カウントが振ってあるテーブル
LEFT JOIN
repeat_table b
ON
a.user_id = b.user_id AND a.rownum = b.rownum +1;
SELECT *
,LAG(date) OVER (PARTITION BY user_id ORDER BY date) l
FROM
orders;
| user_id | order_id | date | l |
|---|---|---|---|
| AAA | 1111 | 2021-03-01 | NULL |
| AAA | 2222 | 2021-03-02 | 2021-03-01 |
| AAA | 3333 | 2021-03-03 | 2021-03-02 |
| BBB | 1111 | 2021-03-01 | NULL |
| BBB | 2222 | 2021-03-02 | 2021-03-01 |
| BBB | 3333 | 2021-03-03 | 2021-03-02 |
「WINDOW関数」と呼ぶものの本体は
~OVER (PARTITION BY)~
の部分です。
例えばこのようなデータがあったとき
| user_id | date | money |
|---|---|---|
| AAA | 2021-03-01 | 1000 |
| AAA | 2021-03-02 | 2000 |
| AAA | 2021-03-03 | 3000 |
| BBB | 2021-03-01 | 2000 |
| BBB | 2021-03-02 | 4000 |
| BBB | 2021-03-03 | 8000 |
sum()のような集約関数は、
SELECT
user_id,date,money,SUM(money) AS sum_money
FROM
orders
| user_id | date | money | sum_money |
|---|---|---|---|
| AAA | 2021-03-01 | 1000 | 20000 |
このようにGROUP BYを書かないと意味のあるデータにならないことが多いのですが、
OVERと組み合わせるとこのような使い方ができます。
SELECT
user_id,date,money
,SUM(money) OVER (PARTITION BY user_id ORDER BY date ASC) money_over
FROM
orders
ORDER BY
user_id , date;
| user_id | date | money | money_over |
|---|---|---|---|
| AAA | 2021-03-01 | 1000 | 1000 |
| AAA | 2021-03-02 | 2000 | 3000 |
| AAA | 2021-03-03 | 3000 | 6000 |
| BBB | 2021-03-01 | 2000 | 2000 |
| BBB | 2021-03-02 | 4000 | 6000 |
| BBB | 2021-03-03 | 8000 | 14000 |
ユーザーの、ある一定の獲得金額に達するタイミングなどが分析できそうです。
ただし、この後に絞り込みを行う場合は
# こんなふうには書けない
SELECT
user_id,date,money
,SUM(money) OVER (PARTITION BY user_id ORDER BY date ASC) money_over
FROM
orders
HAVING money_over > 3000
ORDER BY
user_id , date
;
>You cannot use the alias 'money_over' of an expression containing a window function in this context.'
HAVINGで指定するとエラーになってしまうので、WITH句で書いてその後にWHEREで絞り込みしてあげれば良いと思います。
WITH money_table AS
(SELECT
user_id,date,money
,SUM(money) OVER (PARTITION BY user_id ORDER BY date ASC) money_over
FROM
orders
ORDER BY
user_id , date
)
SELECT * FROM money_table WHERE money_over > 3000
;
| user_id | date | money | money_over |
|---|---|---|---|
| AAA | 2021-03-03 | 3000 | 6000 |
| BBB | 2021-03-02 | 4000 | 6000 |
| BBB | 2021-03-03 | 8000 | 14000 |